数据挖掘入门实验二
实验2:基于Weka的数据挖掘程序设计
学号:
姓名:
XXXXXXX
专业:
计算机
班级:
实验目标
在掌握基于Weka工具的数据挖掘(分类、回归、聚类、关联规则分析)应用的基础上,实现基于Weka API的数据挖掘程序设计。
实验内容
- 下载并安装JDK 7.0 64位版,Weka 3.7版,Eclipse IDE for Java Developers 4.0以上版本。
- 基于Weka API的数据分类。
- 基于Weka API的数据回归。
- 基于Weka API的数据聚类。
- 基于Weka API的关联规则分析。
实验步骤
- 下载并安装JDK 7.0 64位版,Weka 3.7版,Eclipse IDE for Java Developers 4.0以上版本
- JDK与Weka的安装方法与实验1中相同。
- 从http://www.eclipse.org/home/index.php 下载并安装Eclipse。
- 在Eclipse中建立一个新的Java工程,用于放置实验程序的源代码。
- 编程请遵循Java编程规范。规范中文版参见:
http://www.hawstein.com/posts/google-java-style.html
。
- 基于Weka API的数据分类
- 读取“电费回收数据.csv”。
Weka支持多种数据导入方式,由于要处理的数据存储的方式为“.csv”, 而CSVLoader是能从csv文件加载数据集,因此采用CSVLoader来加载文件。
读取完数据还需要删除一些无用的属性列,为了实现该目标,在TestClassifier类中增加一个成员函数deleteUnusedAttributes(Instances ins, ListdeletedAttributes)来完成该过程。
- 数据预处理:
- 将数值型字段规范化至[0,1]区间。
对数据进行规范化就需要用到Normalize类,而该类存在于weka.filters.unsupervised.attribute.Normalize,需要引入该包,之后再对数据进行
规范化
b. 调用特征选择算法(Select attributes),选择关键特征。
特征选择算法如下:
CfsSubsetEval: 根据属性子集中每一个特征的预测能力以及它们之间的关联性进行 评估CorrelationAttributeEval:根据单个属性和类别的相关性进行选择GainRatioAttributeEval:根据与分类有关的每一个属性的增益比进行评估。InfoGainAttributeEval:根据与分类有关的每一个属性的信息增益进行评估。OneRAttributeEval:根据OneR分类器评估属性。PrincipalComponent:主成分分析(PCA)ReliefFAttributeEval:根据ReliefF值评估属性SysmetricalUncerAttributeEval:根据属性的对称不确定性评估属性WrapperSubsetEval:使用一种学习模式对属性集进行评估。
InfoGainAttributeEval根据属性增益大小来选择关键属性,该方法较为简
单,操作方便,选出的关键特征有较好的代表性,因此在上述的几个方法 中选择了InfoGainAttributeEval,用InfoGainAttributeEval方法结果如下:
根据结果的话,应选取TQSC(欠费时长)、PAY_MODE(缴费方式)两个关键属性。
实验结果:

- 分别调用决策树(J48)、随机森林(RandomForest)、神经网络(MultilayerPerceptron)、朴素贝叶斯(NaiveBayes)等算法的API,完成对预处理后数据的分类,取60%作为训练集。输出各算法的查准率(precision)、查全率(recall)、混淆矩阵与运行时间。
A.决策树(J48)

B.随机森林(RandomForest)

C.神经网络(MultilayerPerceptron)

D.朴素贝叶斯(NaiveBayes)

- 基于Weka API的回归分析
- 读取“配网抢修数据.csv”。
Weka支持多种数据导入方式,由于要处理的数据存储的方式为“.csv”, 而CSVLoader
是能从csv文件加载数据集,因此采用CSVLoader来加载文件。
- 数据预处理:
- 将数值型字段规范化至[0,1]区间。
- 调用特征选择算法(Select attributes),选择关键特征。
需要先对数据处理后才能进行关键特征的选取
处理的过程:
先剔除无关属性(如年月日、地区编号)
再将属性FAULT_COUNT_TOTAL(总故障量)列为标签
将所有的数据离散化处理
在这次的关键特征选择中,使用了CfsSubsetEval,该方法是根据属性子集中每一个特征的预测能力以及它们之间的关联性进行评估,实验选择结果如下:

- 分别调用随机森林(RandomForest)、神经网络(MultilayerPerceptron)、线性回归(LinearRegression)等算法的API对数据进行回归分析,取60%作为训练集。输出各算法的均方根误差(RMSE,Root Mean Squared Error)、相对误差(relative absolute error)与运行时间。
A.随机森林(RandomForest)

B.神经网络(MultilayerPerceptron)

C.线性回归(LinearRegression)

- 基于Weka API的数据聚类
- 读取“移动客户数据.tsv”(TAB符分隔列)。
- 数据预处理:
- 将数值型字段规范化至[0,1]区间。
- 调用特征选择算法(Select attributes),选择关键特征。

- 分别调用K均值(SimpleKMeans)、期望值最大化(EM)、层次聚类(HierarchicalClusterer)等算法的API对数据进行聚类,输出各算法的聚类质量与运行时间。聚类质量根据以下2个指标计算:
- Silhouette指标
- S_Dbw指标


- 基于Weka API的关联规则分析
- 读取“配网抢修数据.csv”。
- 数据预处理:
- 将数值型字段规范化至[0,1]区间。
- 调用特征选择算法(Select attributes),选择关键特征。
- 调用Apriori算法对数值型字段进行关联规则分析,输出不同置信度(confidence)下算法生成的规则集。
预备知识
置信度度量通过规则进行推理具有的可靠性。对于给定的规则X→Y ,置信度越高,Y在包含X的事务中出现的可能性就越高。
metricType 度量类型。设置对规则进行排序的度量依据。可以是:置信度(类关联规则只能用置信度挖掘),提升度(lift),杠杆率(leverage),确信度(conviction)。
在 Weka中设置了几个类似置信度(confidence)的度量来衡量规则的关联程度,它们分别是:
a) Lift : P(A,B)/(P(A)P(B)) Lift=1时表示A和B独立。这个数越大(>1),越表明A
和B存在于一个购物篮中不是偶然现象,有较强的关联度.
b) Leverage :P(A,B)-P(A)P(B)
Leverage=0时A和B独立,Leverage越大A和B的关系越密切
c) Conviction:P(A)P(!B)/P(A,!B) (!B表示B没有发生) Conviction也是用来衡量A
和B的独立性。从它和lift的关系(对B取反,代入Lift公式后求倒数)可以看出,
这个值越大, A、B越关联。
置信度confidence=0.9
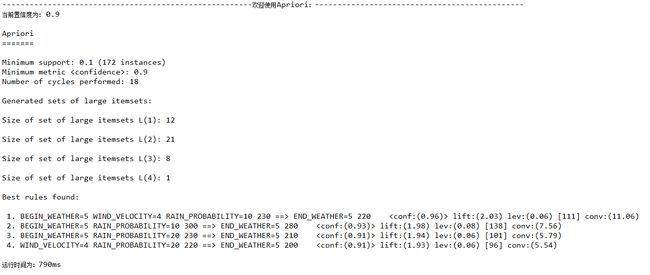
以置信度为0.9的作为例子分析结果:
这里除了置信度为设置的,其余变量均是系统默认的。
Minimum support: 0.1 (172 instances)
//最小支持度为0.1
Minimum metric : 0.9
//设置的置信度为0.9
Number of cycles performed: 18
//进行18轮搜索
Generated sets of large itemsets:
// 这是满足支持度进行搜索的结果
Size of set of large itemsets L(1): 12
//
频繁1项集:12个
Size of set of large itemsets L(2): 21
//
频繁2项集:21个
Size of set of large itemsets L(3): 8
//
频繁3项集:8个
Size of set of large itemsets L(4): 1
//
频繁4项集:1个
Best rules found:
1. BEGIN_WEATHER=5 WIND_VELOCITY=4 RAIN_PROBABILITY=10 230 ==> END_WEATHER=5 220 lift:(2.03) lev:(0.06) [111] conv:(11.06)
//若BEGIN_WEATHER取值为5,RAIN_PROBABILITY取值10且WIND_VELOCITY取值4可以推出END_WEATHER的取值为5,该关联规则置信度为96%
2. BEGIN_WEATHER=5 RAIN_PROBABILITY=10 300 ==> END_WEATHER=5 280 lift:(1.98) lev:(0.08) [138] conv:(7.56)
3. BEGIN_WEATHER=5 RAIN_PROBABILITY=20 230 ==> END_WEATHER=5 210 lift:(1.94) lev:(0.06) [101] conv:(5.79)
4. WIND_VELOCITY=4 RAIN_PROBABILITY=20 220 ==> END_WEATHER=5 200 lift:(1.93) lev:(0.06) [96] conv:(5.54)
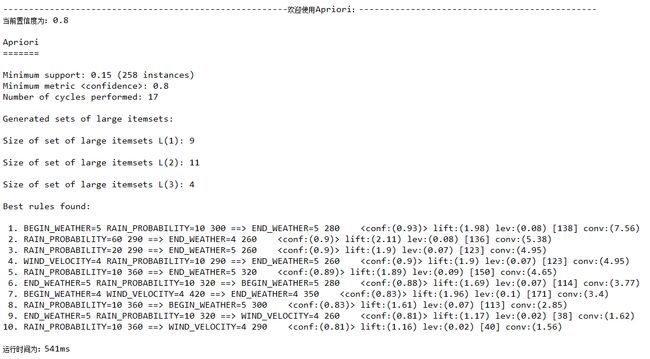
置信度confidence=0.8
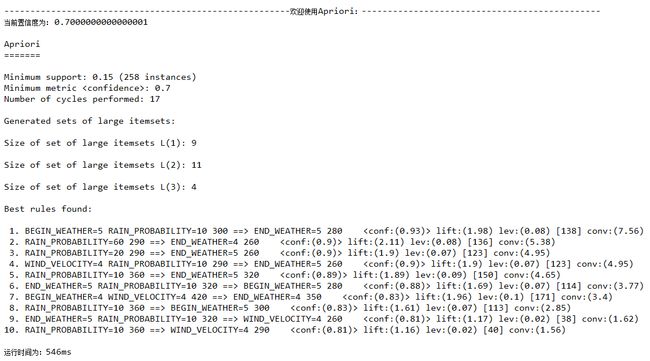
置信度confidence=0.7
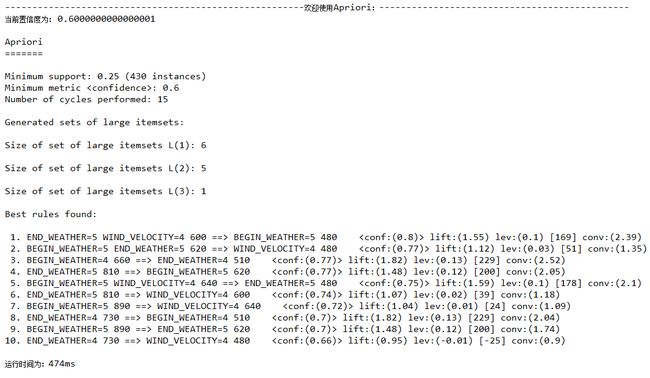
置信度confidence=0.6
置信度confidence=0.5
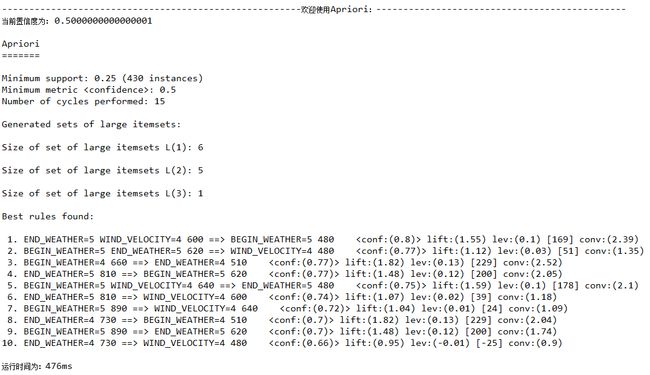
置信度confidence=0.4
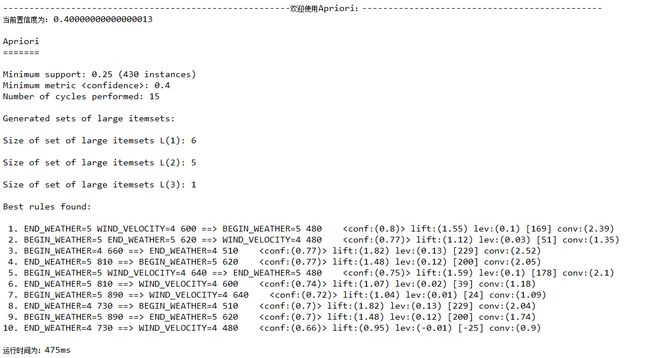
置信度confidence=0.3
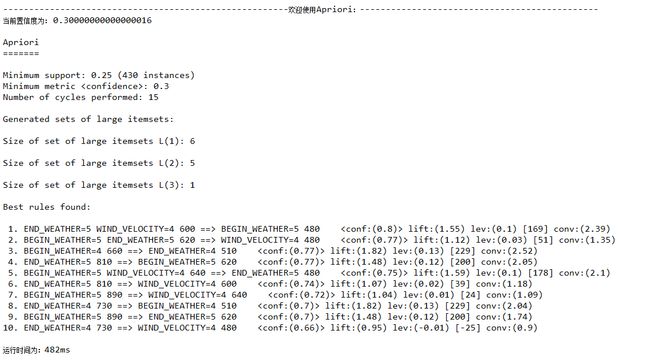
置信度confidence=0.2
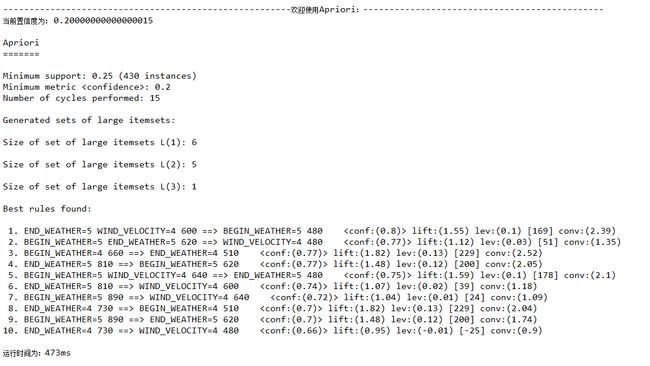
置信度confidence=0.1
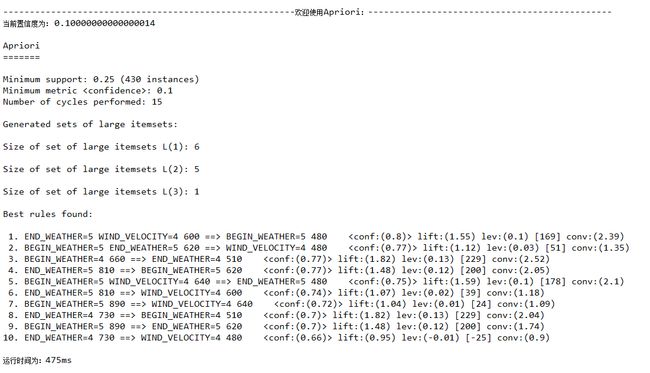
四、实验结果提交
将实验代码放在一个Eclipse工程中,用不同包名和类名区分不同任务的实验,提交工程的压缩包。
注意:压缩包中不应包含编译生成的.class文件
。