MySQL总结(二)—— Mysql怎么存储的之真正的BTree
本节专注于讨论BTree的结构。 其他如BTree裂变、查找、插入流程、undolog、redolog各种执行顺序等后面讨论。
还是先抛问题。
1.数据结构是什么?代码怎么写的?
2.这个BTree是在内存还是在磁盘里;内存是不是有一部分BTree的结构?
3.联合索引BTree是怎么存储的,多字段查询是怎么检索的?
4.为什么用BTree结构,而不用其他存储结构 比如红黑树?
1.简要介绍背景知识

借用一副常见的图,mysql一次查询会经过这么多步骤,BTree位于存储引擎层,是Innodb特有的结构。
以此表结构为例。
create table t1 (
`id` int AUTO_INCREMENT;
`a` varchar(255),
`b` varchar(255),
`c` int
primary key (`id`),
key `idx_a_b_c` (`a`,`b`,`c`)
) ENGINE=InnoDB;
select * from t1 where id = 55; 整个sql语句经过各种流程后,到达存储引擎层 就会被翻译为一个数据结构 [table=t1, id=55]
2.通过ibdata文件分析BTree结构
我们先不抛概念,直接看结构。当前表里有两条记录,利用mysql分析神器(https://github.com/jeremycole/innodb_ruby/wiki 后续文章讲解怎么使用)查看文件内容。


这个表有两个索引 聚簇索引(Index 489)和普通索引(Index 490)数据。
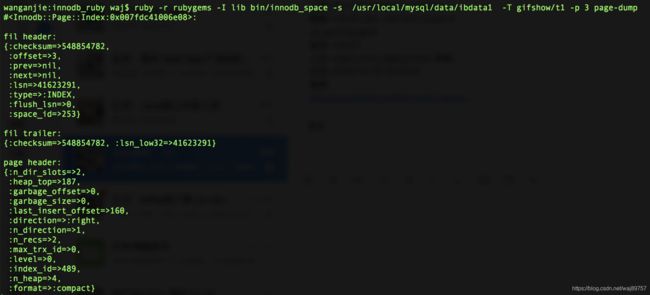
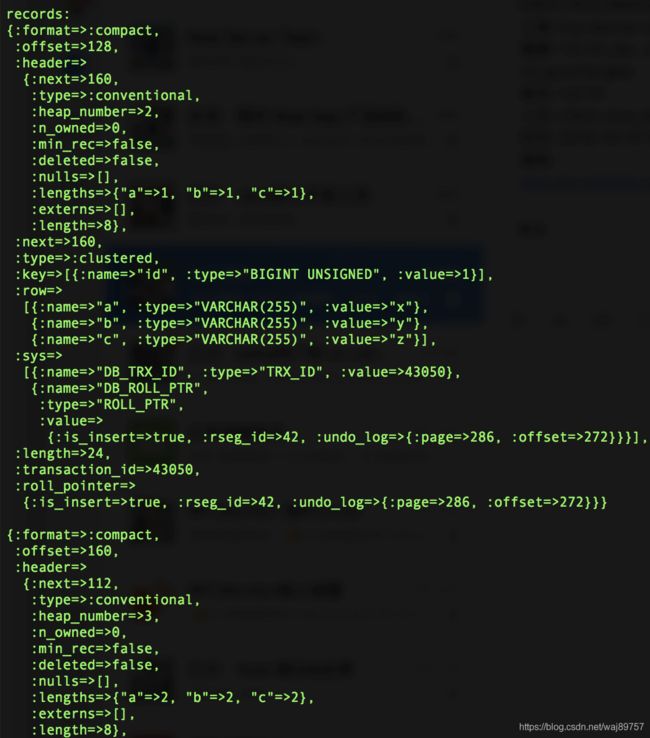
我们看聚簇索引存了什么东西:说几个重点结构,1.page header里的level=0 说明是叶子节点 2. records这个结构,几个关键字段 type = clustered 代表是数据行、 offset、next;可以看出是链表方式组织的结构。
我们再插入500条数据。

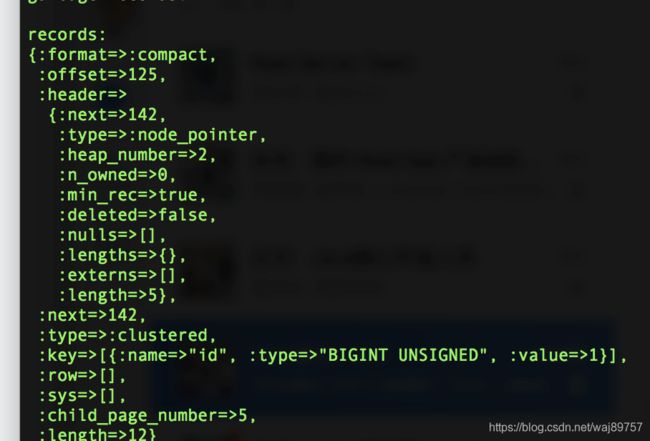
可以看出Page增多,BTree不再是一层。对第一个page做分析,可看到records type = node_pointer,说明这个数据行是指针,key字段可以看到是id = 1 child_page_number 说明下一层page号是5。
看到这里 大家结合自身对BTree的了解,是不是已经能体会到真正的结构了 下面开始介绍各种概念。
3.BTree的数据结构
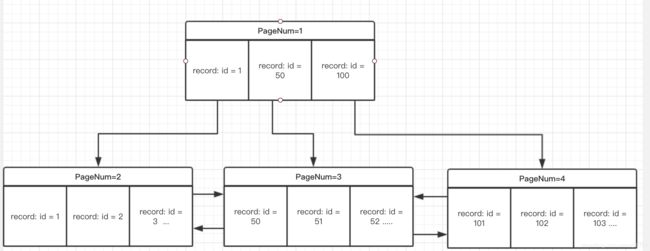
如图,BTree核心就是Page和Record,Page里包含一个Records链表,Page通过指针的方式组织成一个BTree。而真正查找要进行一次PageNum查找和一次Record链表查找。
举个例子,比如要查 id = 55;根据结构先找到level =1 (只会有一个page节点)的page,然后遍历record找到第一个小于等于5的record,它的child_page_num指针会告诉下一层page页,找到后再遍历record链表 即可找到记录。
数据结构
1.Page

就是由一个字节数组组成。
Fil Header
Page是双向链表,主要包含两个指针 FIL_PAGE_PREV IL_PAGE_NEXT,用来构建这个双向链表。
Page Header
存由PAGE_LEVEL 树的层级。 0 is leaf node
Infimum + Supremum Records
一个Page有多个Record,这两个用于保持最小和最大Record(按照index排序) 方便查找
User Records 用户记录
一个Page最大有65535 16K数据,也就是理论上一个rec就16k(实际远远小于16k),rec也是一个链表,且按照index逻辑有序,page的rec是按照物理顺序存储的。主键作为key,一般order by 就直接按照链表顺序查出来了。
Page Directory
记录key和record的映射,二分查找。因为BTree是针对Page维度的,最后需要key找到record。
4.BTree代码阅读
通篇搜索mysql代码,也没有找到一个struct表述page的数据结构。 这是因为,mysql仅用一个指针来初始化,从文件系统里获取连续一段空间(映射到block_t) 然后用指针初始化这个空间就形成了page结构,然后通过指针来构造树和链表。见上图
涉及数据结构
buf_block_t 一个文件块,取其中的一部分构成page
page_t = typedef byte page_t 本质就是一个字节指针。
涉及代码文件
buf0buf.h
btr0btr.cc
涉及函数
btr_create //Create the root node for a new index tree.
page = page_create(block, mtr, dict_table_is_comp(index->table),page_create_type);
page_create_low(buf_block_t *block, ulint comp,page_type_t page_type) 初始化一个Page页包括File Header Page Header Infi Supre Records
当第一次插入的时候,会从Page里找,发现没有节点,创建一个record加入到(rec_t)User Records里,你可以认为就是再连续数组后面追加了一些字节。
至此,BTree的数据结构就介绍完了,还有很多其他字段,不展开讲了。
5.普通索引怎么构建BTree
每个普通索引都有一个BTree,也就是mysql会开辟一块空间存这些Page,leaf page是聚簇索引的key。
select * from t1 where a = "x1" and b = "y1" 究竟会怎么查找呢?
首先,普通索引是key是一个元组(key1的val|key2的val|key3的val),比如记录1 a = "x" b = "y" c = "z" 映射成普通索引record的value 就是[x,y,z]这个内容。顺序是按照a b c顺序存储, 查找的时候一个字段一个字段,根据字符串ASCII码比较。
又插入记录 (x,y2,z) (x1,y,z) (x1,a,z) (x1,y1,z) (x1,y1,a)
最终顺序为: (x,y,z) (x,y2,z) (x1,a,z) (x1,y,z) (x1,y1,a) (x1,y1,z)
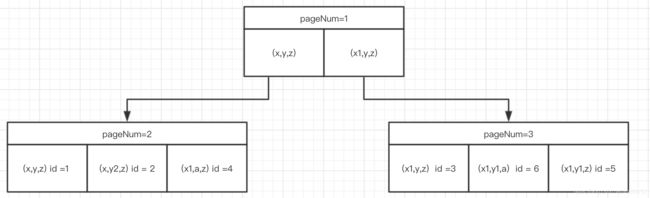
查找a = "x1" and b = "y1" 流程如下:
pageNumb1 a == x1 and b > y 则选择pageNum3
(x1,y1) > (x1,y) 最后输出 (x1,y1,z) (x1,y1,a)
小结:
回答开头三个问题
1.真正的数据结构是什么?也就是代码怎么写的?
Page+Records 树和链表的数据结构
2.这个BTree是在内存还是在磁盘里;内存是不是有一部分BTree的结构
可以看到都存在ibdata文件里;内存里不会有BTree结构 但是会有一些缓存(后面专门讲解)
3.联合索引BTree是怎么存储的,多字段查询是怎么检索的
record的key对应多字段的元组,查找时按照字段比较 找结果。
4.为什么用BTree结构,而不用其他存储结构 比如红黑树?
磁盘存储,顺序读写,一次IO操作系统一般会预取后几页。B+Tree层级少,同层Page是顺序存储的,查找数据时磁盘寻道时间会少。红黑树相邻节点物理上不相邻,深度很深,每一层都进行一次寻道,IO多。
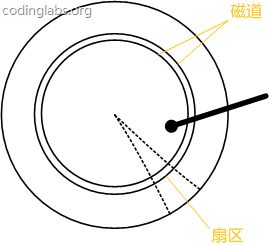
磁盘有扇区和磁道(类似于X Y轴),顺序查找不用寻道时间,随机查找需要大量转变扇区和磁道
一个物理地址 = 扇区+磁道
寻道时间: 变动磁头找到磁道
旋转时间:旋转磁盘找到扇区