JVM 调优,如何合理分配内存,减少Full GC?
介绍
我们都知道,项目线上发布的时候尽量避免使用JVM 默认的配置参数,默认的堆栈空间就几百MB,而且有些参数不太满足自己项目的实际场景。因此我们需要自定义自己项目的JVM 配置信息,最主要的目的就是让生产环境的JVM 跑得更加流畅,更加的稳定。 其中,作为开发程序员我们最关心的莫过于GC,因为或导致STW(stop the world)停顿时间,特别是Full GC(注:现代垃圾收集器 一般进行老年代收集的时候都会将永久带,metadata space 等整个堆空间进行内存回收,所以我这里直接用Full GC,而不是 old GC,如果严谨或者精确来说 你说Old GC 也没毛病,除非面试时候遇到较真的面试官,那就问清楚再回答 ),如果系统动不动就停顿个几秒钟或者几十秒,估计要拉一个程序员祭天了。
最好的情况下,我们希望我们的线上系统尽量只发生Young GC,或者 至少 一天或几个小时 才发生一次Full GC,因为Full GC 的耗时 和 性能 消耗式 Young GC的 十几二十倍,因此,本文关注的重点在于 如何优化 Full GC 的场景。
Young GC 和 Full GC 触发的时机
Young GC 触发时机
- 年轻代Eden 区没有空间可以分配给新生对象,就会触发Young GC,然后将存活对象放入Suvivor 区 或者 进入老年代
Full GC 触发时间
- (1)老年代空间不足,这个很简单,就是字面上的不足,例如:大对象不停的直接进入老年代,最终造成空间不足。或者达到设置的触发Full GC 的时机
- (2)永久带 空间不足(jdk1.8 之后 metadata space 空间不足)。
- (3)Young GC 对象进入 老年代,引发Full GC,这其实和(1)差不多,每次Young GC 后不断的有对象进入老年代,或老年代担保机制引发提前Full gc,其实根本原因还是对象进入老年代,造成老年代空间被占满,无法分配给新到来的对象,从而引发Full GC(具体如何触发就不就不详细说了,大致意思就是,内存被占满了,需要Full GC 释放垃圾对象占用的内存空间,如果想了解,自己查询一些资料就OK)。
下面回顾一下堆内存空间分配

思考:如何避免Full GC 产生?
首先我们大致知道了哪些情况会产生Full GC,其中最根本的原因就是有对象不停的进入老年代,最后导致空间不足,引发Full GC 释放空间。
那么我们解决思路就来了,直接破坏掉产生条件就行了,这么简单?对,说起来就是这么简单,我们直接减少运行时期间从Young GC 晋升 到老年代的对象,或者 没有对象晋升到老年代就行了。
破坏条件(1)大对象频繁进行老年代,造成老年代空间快速被占满,造成Full GC。
解决方案:
The default size for PretenureSizeThreshold is 0 which says that any size can be allocated in the young generation.
但是现在 默认 -XX:PretenureSizeThreshold=0,意味着任何对象都会现在新生代分配内存。 除非对象大小直接大于了Eden 区的整个内存大小,一般不会有,如果有,别转牛角尖,那么改代码吧。
所以现在大对象这个一般不用特别关注。
破坏条件(2)metaspace 空间不足
解决方案:一般这个里面存放的都是一些Class 类信息,Class 本身也是一个对象,需要空间存放。那么我们程序代码中什么时候会产生对象进入呢,当使用CGLIB 动态代理不停的生成代理类的时候,就会加载到元数据空间,当然一般4核8G 内存的物理机分配个512M 是完全没问题的,这也不再本文的重点介绍之类
破坏条件(3)从年轻代 晋升 到老年代的对象
破坏条件之前,我们还是思考下,什么情况下,新生代对象Young GC会进入老年代?
- a) Young GC 后,存活对象大于 survivor 区,存活对象全部进入老年代,注意动态年龄的区别。
- b) 达到了设置的年龄限制,默认是15次
- c) 动态年龄判定,新生代对象提前进行老年代 ,默认 从年龄小往大 对象大小累加 大于 设定值为界限(50%),超过该年龄的对象会进入老年代。MaxTenuringThreshold参数
动态年龄 举例
假设 现在 年龄1对象 占 30%,年龄2对象 占10%,年龄3对象占 30%,年龄4对象占30%,那么会其实比较关注的是 年龄3会不会晋升?
年龄1 + 年龄2 +年龄3 > 50,所以 以年龄3为界限, 对象年龄 >=3 的对象全部进入老年代。
又出现了三个条件,咋办?一样,去破坏条件,但是破坏之前我们先思考以下?
条件b) 难道把晋升年龄调大一点?注意,调大一点,只是会让长期存活对象,在新生代 多呆一会儿,其实没多大意义,假设 10秒一次Young GC 15 * 10 = 150s,都存活两分钟的对象,基本上已经确定是系统中长期存活的对象,调大一点,也仅仅是让它在新生代在多呆一会儿,还不如让它早点去它该区的老年区。
条件a) 存活对象大于存活区大小 和 条件c) 动态年龄判定 两个条件产生原因差不多,都是S(survivor)区大小分配不合理,可以同时进行优化。
实战教学
假设场景 : 先假设一个场景,新生代10MB(默认8:1:1),老年代10MB,假设线上某段时间QPS 为 100,每个处理时间为2s,每个处理会产生10kb的对象,一秒产生 100 * 10kb * 1 ≈ 1MB,那么8秒,Eden 区就满了,会直接触发Young GC,存活对象大小 2 * 100 * 10 kb ≈ 2MB,明显S区,放不下会进入老年代。
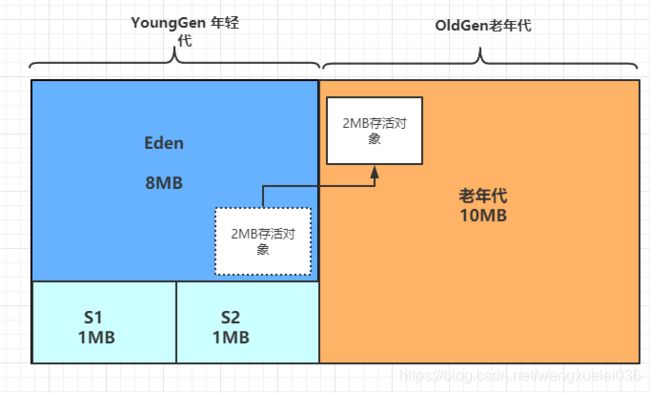
这么一想,大概5次过后,老年代就满了 需要进行一次Full GC, 那么意思就是 大概 四五十秒就会产生一次Full GC,要是线上也是这样那就拉闸了。
那么果然内存空间的分配才是最主要的问题,那么我们线上应该如何进行堆内存的分配呢?
最简单的方式就是调大内存,这是是最直接的,直接 将新生代调整为20MB,那么S区就放得下了。
那么你可能又会问,那之前不是说的动态年龄判定又怎么办,我的S区20MB,都全部放满了,不是超过了动态年龄判定的界限?
(1)继续调大内存,直接将新生代变为40MB
(2)调整比例将8:1:1,假设我们调整为2:1:1,Eden 10MB,S1 5MB,S2 5MB,这也放的下了
那么是不是 每次Young GC 完成后对象都在S区,下次Young GC 就直接回收了。
那么线上如何去思考内存分配呢?
(1)找到最大的压力瓶颈点,也可以说并发最多的点
(2)根据系统未来的业务量,访问量,去推算这个系统每秒的钟的并发量,注意项目的特殊性,一般可以是用2/8原则 0.8*PV/0.2天 转为秒。
(3)计算一次业务 新生代会占用多少内存,一般可以考虑 主要业务对象大小 * 10~20倍来预估,或者直接用工具直接监测。
(4)一次业务的时长,即一次请求的耗时。
(5)根据(1)(2)中的推算的每秒的并发量 预估推算对内存空间的占用量, 这个占用量 是一秒内或者说 在并发过程中无法回收的。无法回收的对象大小 = 业务处理时间 * QPS * 每个处理会产生的对象大小
(6)根据内存的推算结果预估出运行期间JVM的内存运转模型。
(7)部署多少台机器,每台机器配置如何
小总结
(1)新生代Eden区的大小,每个处理产生多少对象,QPS 决定了 每次Young GC的间隔时间。
(2)每个处理产生多少对象,QPS ,每隔处理的时间长度 决定了S区划分多少空间足够。
最根本还是找到触发导致性能缓慢的原因,来破坏掉条件,达到预期效果