软件构造总结笔记
软件构造总结笔记
- 本笔记依据考试大纲,调整课堂讲义的分点,以知识点分化作为条理,精简原本人课堂笔记,进行总结
- GitHub仓库资源:gzn00417/2020Spring-Software-Construction
文章目录
- 软件构造总结笔记
-
- 2020考试题型
- 考试大纲:
- 一、软件构造基础
-
- 1.1 软件构造的多维度视图
- 1.2 软件构造的阶段划分、各阶段的构造活动
-
- 构造阶段 Build-Time View
-
- 构建时+瞬时+代码
- 构建时+周期+代码
- 构建时+瞬时+组件
- 构建时+周期+组件
- 运行阶段 Run-Time View
-
- 运行时+瞬时+代码
- 运行时+周期+代码
- 运行时+瞬时+组件(略)
- 运行时+周期+组件(略)
- 1.3 内部/外部的质量指标
-
- 外部质量因素
- 内部质量因素
- 权衡 Tradeoff
- 二、软件构造过程
-
- 2.1 软件配置管理SCM与版本控制系统VCS
- 2.2 Git
-
- 基本指令
-
- 管理变化
- 分支Branch和合并Merge
- 工作原理和结构
- 2.3 GitHub
- 三、ADT & OOP
-
- 3.1 数据类型和类型检查
-
- 基本数据类型 & 对象数据类型
- 静态类型检查 & 动态类型检查
- Mutable可变 & Immutable不可变
- 值的改变 & 引用的改变
- 表示泄露和防御式拷贝
- Snapshot diagram
- 3.2 设计规约(Specification)
-
- Spec概念
- 前置条件 & 后置条件
- 行为等价性
- Spec的写法
- Spec的强度
- 3.3 抽象数据类型(ADT)
-
- 四类ADT操作
- 表示独立性
- 抽象函数AF & 表示不变量RI
- 测试ADT
- 以注释的形式撰写AF、RI、 Safety from Rep Exposure
- 3.4 面向对象编程(OOP)
-
- 接口(Interface)& 抽象类(Abstract Class)& 具体类(Concrete Class)
- 继承(Inheritance) & 重写(Override)
- 多态(Polymorphism) & 重载(Overload)
- 3.5 ADT和OOP中的等价性
-
- 不可变对象的引用等价性 & 对象等价性
- `equals()` & `hashCode()`
- 可变对象的观察等价性 & 行为等价性
- 四、可复用性
-
- 4.1 可复用性的概念
- 4.2 面向复用的软件构造技术
-
- Liskov Substitution Principle 里氏替换原则(LSP)
- 协变 & 反协变
- 泛型
- 委派(Delegation)
- 组合(Composition)和CRP原则
- 白盒框架 & 黑盒框架的原理与实现
- 4.3 面向复用的设计模式
-
- Adapter 适配器模式
- Decorator 装饰者模式
- facade 外观模式
- Strategy 策略模式
- Template Method 模板方法模式
- Iterator 迭代器模式
- 五、可维护性
-
- 5.1 可维护性的度量
-
- 可维护性的常见度量指标
- 聚合度与耦合度
- 5.2 可维护性的构造原则 SOLID
- 5.3 面向可维护性的设计模式和构造技术
-
- Factory Method 工厂方法模式
- Abstract Factory 抽象工厂模式
- Proxy 代理模式
- Observer 观察者模式
- Visitor 访问者模式
- State 状态模式
- Memento 备忘录模式
- 5.3 语法驱动的构造
- 六、健壮性
-
- 6.1 健壮性和正确性的含义和区别
- 6.2 错误与异常处理
-
- Throwable
- Java中的内部错误(Error) & 异常(Exception)
- 异常处理
- Checked & Unchecked Exceptions区别
- Checked异常的处理机制
-
- 自定义异常类
- 声明异常 & 抛出异常
- 捕获异常 & 处理异常
- Finally
- LSP & 异常
- 6.3 断言与防御式编程
-
- 防御式编程的基本思想
- 断言Assertion
- 6.4 代码调试
-
- 调试的基本过程和方法
- 使用日志开展调试
- 6.5 软件测试与测试优先的编程
-
- 使用JUnit进行单元测试(Unit Test)
- 黑盒测试
- 等价类划分和边界值分析
- 测试覆盖度
- 以注释的形式撰写测试策略
- 七、并行
-
- 7.1 并发Concurrent
-
- 进程和线程
- 交错和竞争
- 7.2 线程安全策略
-
- 紧闭 Confinement
- 不可变 Immutability
- 线程安全数据类型
- Synchronization & Lock
-
- 死锁
2020考试题型
- 填空:4个,8分
- 简答、写代码、改代码:9个,合计56分
- 设计题:3个,合计36分
简答/设计题:
- 给出需求描述、ADT的基本代码
- 开展设计和代码:绘图/建模、设计、修改代码、写新代码、写注释
- (AF/RI/Spec/Safety from Rep Exposure/Testing Strategy /Thread Safety Argument)
- 设计测试用例、改进/优化各项质量指标等
考试大纲:
-
第一、二章5%:软件构造基础、过程
- 软件构造的多维度视图
- 软件构造的阶段划分、各阶段的构造活动
- 内部/外部的质量指标
- 软件配置管理SCM与版本控制系统VCS
- Git的结构、工作原理、基本指令
- GitHub
-
第三章40%:ADT+OOP
- 基本数据类型、对象数据类型,
- 静态类型检查、动态类型检查
- Mutable可变/Immutable不可变
- 值的改变、引用的改变
- 表示泄露、防御式拷贝
- UnmodifiableCollections
- Snapshot diagram
- Specification、前置/后置条件
- 行为等价性
- Spec的写法、Spec的强度
- ADT操作的四种类型
- 表示独立性
- 不变量、表示不变量RI
- 表示空间、抽象空间、AF
- 以注释的形式撰写AF、RI、 Safety from Rep Exposure
- 接口、抽象类、具体类
- 继承、override
- 多态、overload
- 泛型
- 等价性equals()和==
- equals()的自反、传递、对称
- hashCode()
- 不可变对象的引用等价性、对象等价性
- 可变对象的观察等价性、行为等价性
-
第四、五章30%:可复用性+可维护性
- Programing for/with reuse
- LSP
- 协变、反协变
- 数组的子类型化
- 泛型的子类型化
- 泛型中的通配符(?)
- Delegation
- Comparator和Comparable
- CRP原则、接口的组合
- 白盒框架的原理与实现
- 黑盒框架的原理与实现
- 可复用设计模式:adapter、decorator、fagade、strategy、 template method、iterator/iterable
- Java中的常见数据类型,特别是集合类Collections (List, Set, Map)
- 可维护性的常见度量指标
- 聚合度与耦合度
- SOLID
- 可维护设计模式:factory method、abstract factory、proxy、Observer/Observable、visitor、 state、 memento
- 语法、正则表达式
-
第六章15%:健壮性
- 健壮性和正确性的含义和区别
- Throwable
- Error/Runtime异常、 其他异常、Checked异常、Unchecked异常
- Checked异常的处理机制:声明、抛出、捕获、处理、释放资源等、自定义异常类
- 断言的作用、应用场合
- 防御式编程的基本思想、SpotBugs
- 调试的基本过程和方法、使用日志开展调试
- 黑盒测试用例的设计:等价类划分、边界值分析
- 以注释的形式撰写测试策略
- 用JUnit编写和执行测试用例
- 测试覆盖度、Eclemma
-
第七章10%:并行
- 进程和线程
- 线程的创建和启动,Thread、Runnable
- 内存共享模式、消息传递模式
- 时间分片、交错执行、竞争条件
- 线程的休眠、中断
- 线程安全threadsafe的四种策略****
- 一Confinement、Immutability、ThreadSafe类型(SynchronizedCollections)
- 一Synchronization/ Lock
- 死锁
- 以注释的形式撰写线程安全策略(ThreadSafe Argument)
一、软件构造基础
1.1 软件构造的多维度视图
软件多维视图
- 按阶段划分:构造时/运行时视图
- 按动态性划分:时刻/阶段视图
- 按构造对象划分:代码/构件视图

1.2 软件构造的阶段划分、各阶段的构造活动

构造阶段 Build-Time View
-
Code:代码的逻辑组织
functions
classes
methods
interfaces -
Component:代码的物理组织
files
directories
packages
libraries
构建时+瞬时+代码
- 源代码
- 函数、类、方法、接口
- 三个层面
- 词汇:使用的语句、字符串、变量、注释(半结构化)
- 语法:语法树、流程图(彻底结构化)
- 语义:源代码实现的目标 & 组成部分联系情况
构建时+周期+代码
- 记录周期内代码变化
Code Churn - 版本控制工具
构建时+瞬时+组件
- 模块化组织为文件、目录
- 文件被压缩为package、library
- 与库文件链接
- 静态链接
发生在构造阶段
复制
不依赖
缺点:难以升级 - 动态链接
不会加入可执行文件
做标记
运行时根据标记装载库至内存
发布软件时,记得将程序所有依赖的动态库都复制给用户
优点:易于升级
- 静态链接
构建时+周期+组件
- files/packages/components/libraries 如何变化 不同版本
- Software Configuration Item(SCI)配置项
运行阶段 Run-Time View
- 程序被载入目标机器
Code:逻辑实体在内存中呈现?
Components:物理实体在物理硬件环境中呈现?
Moment:特定时刻形态?
Period:随时间变化? - 关注点:
- 可执行程序、原生机器码、程序完全解释执行
- 库文件
- 分布式程序
运行时+瞬时+代码
- Code snapshot 代码快照图(第三章)
- 运行时程序变量层面状态
- Memory dump 内存信息转储
- 查看内存使用情况(实验)
- 宏观:任务管理器
运行时+周期+代码
- UML图
- 执行跟踪tracing
- 用日志记录程序执行的调用次序
运行时+瞬时+组件(略)
运行时+周期+组件(略)
1.3 内部/外部的质量指标
外部质量因素
- 用户感受得到、影响使用
- 正确性 Correctness
i. 遵守规格说明书
ii. 分层:从底层到顶层,都要正确
iii. 设法测试 - 鲁棒性 Robustness
健壮性:对异常情况做出适当反映
异常取决于规格说明,是其没有涉及的部分 - 易扩展性 Extendibility
易于调整、适应变化(软件是易变的)
改变的多少(与规模密切相关、越大越难以扩展)
Decentralization 离散化:模块自治性越强,变化时对其余模块影响越小 - 复用性 Reusability
利用已有的、复用性好的程序,开发成本少
相似的模式、利用共性
模块化 - 兼容性 Compatibility
软件元素融合
关键:标准化 - 效率 Efficiency
对硬件资源尽可能少的需求
与其他存在矛盾 - 可移植性 Portability
便于将软件产品移植到各种环境 - 易用性 Ease of use
用户:轻松掌握使用、包括安装、运行、GUI等 - 功能性
(冲突)过多新功能 --> 损失一致性(兼容性)、影响易用性
先实现主要功能、提高质量,再丰富功能 - 时效性 Timeliness
Others
a. 可验证性
b. 完整性 Integrity
i. 保护组件(程序和数据)在未经授权时不会被修改
c. 可修复性
d. 经济
i. 与时效性相关
ii. 系统能够按照等于或低于预算完成的能力
内部质量因素
- 影响使用代码的相关人员、软件本身和开发者
- 内部质量因素通常用作外部质量因素的部分度量
- LOC
lines of code - Cyclomatic Complexity 圈复杂度
衡量一个模块判定结构的复杂程度 - Architecture-related factors
Coupling 耦合度 --> 低
Cohesion 内聚度 --> 高
矛盾 - 可读性
- 易理解性
- 清晰 Clearness
- 复杂度
- 大小 Size
权衡 Tradeoff
-
因素之间相互影响、矛盾、相关
- 经济性 与 功能性/可复用性 矛盾
- 有效性/可复用性 与 轻便性 矛盾
- 更高效、对硬件和软件有高要求
- 时效性 与 可扩展性 矛盾
- 完整性 与 易用性
-
首要:正确性!
二、软件构造过程
2.1 软件配置管理SCM与版本控制系统VCS
SCM ≥ VCS
- 软件配置管理SCM
- 追踪和控制软件的变化
- 软件配置项SCI:软件中发生变化的基本单元(文件:Component-Level)
- 版本控制系统VCS
- 本地版本控制系统:仓库存储于开发者本地机器,无法共享和合作
- 集中式版本控制系统:仓库存储于独立的服务器,支持多开发者之间的协作
- 分布式版本控制系统:仓库存储于:独立的服务器 + 每个开发者的本地机器
2.2 Git
基本指令
添加文件:
git add xxx.xxx
提交文件:git commit -m "message"
push到远程仓库:git push origin master
从远程仓库pull:git pull origin master
管理变化

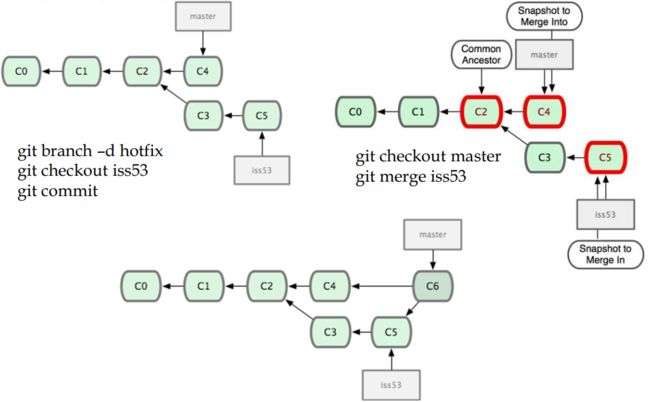
分支Branch和合并Merge
新建分支:
git checkout -b branch_name
切换分支:git checkout branch_nameorgit checkout master
选择一个分支与当前分支合并:git merge branch_name2(之前已有指令git checkout branch_name1)

工作原理和结构
-
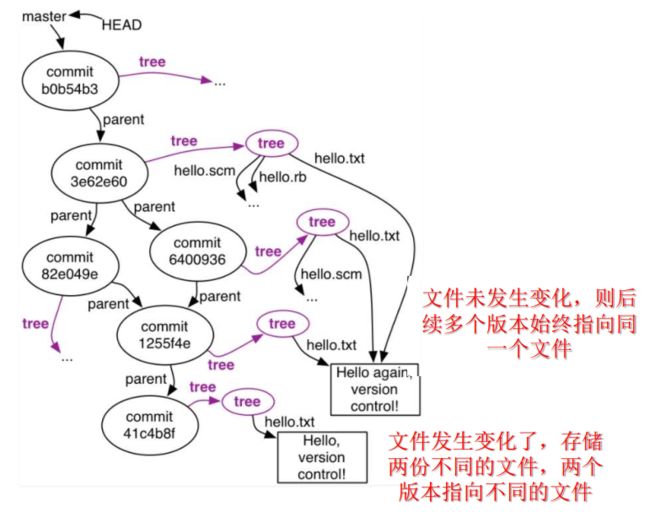
Object Graph
- 版本之间的演化关系图
- 一条边A->B表征了“在版本B的基础上作出变化,形成了版本A”

-
Commit
- 每个commit指向一个父亲
- 分支:多个commit指向一个父亲
- 合并:一个commit指向两个父亲
管理变化:
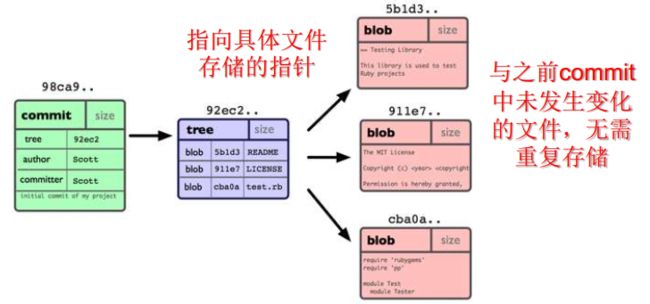
Git存储发生变化的文件(而非代码行),不变化的文件不重复存储
Commits: nodes in Object Graph
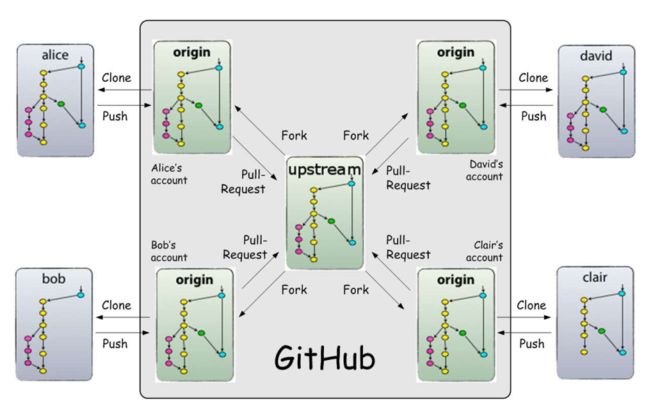
2.3 GitHub
三、ADT & OOP
3.1 数据类型和类型检查
基本数据类型 & 对象数据类型
| Primitives | Object Reference Types |
|---|---|
| int, long, byte, short, char, float, double, boolean | Classes, interfaces, arrays, enums, annotations |
| 只有值,没有ID (与其他值无法区分) | 既有ID,也有值 |
| 不可变 | 可变/不可变 |
| 在栈中分配内存 | 在堆中分配内存 |
| Can’t achieve unity of expression | Unity of expression with generics |
| 代价低 | 代价昂贵 |
静态类型检查 & 动态类型检查
- 静态类型检查
- 关于“类型的检查”,不考虑值
- 在编译阶段发现错误,避免将错误带入运行阶段
- 提高程序的正确性、健壮性
- 静态类型检查错误:
- 语法错误
- 类名/函数名错误
- 参数数目错误
- 参数类型错误
- 返回值类型错误
- 动态类型检查
- 关于“值”的检查
- 动态类型检查错误:
- 非法的参数值
- 非法的返回值
- 越界
- 空指针
Mutable可变 & Immutable不可变
不变对象:一旦被创建,始终指向同一个值
可变对象:拥有方法可以修改自己的值/引用
final
- 尽量使用
final作为方法的输入参数、作为局部变量 final表明了程序员的一种“设计决策”final类无法派生子类final变量无法改变值/引用final方法无法被子类重写
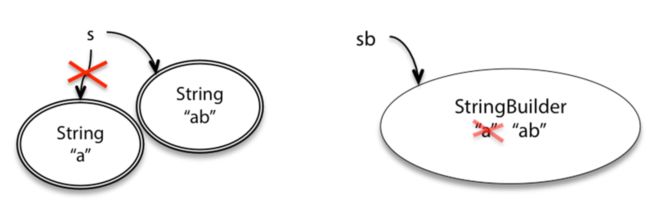
- String 不可变
- StringBuilder 可变
/* String部分 */
String s = "a"; //开辟一个存储空间,里面存着字符a,s指向这块空间,记为space1
String t = s; //让t指向s所指向的空间即space1
s = s.concat("b"); //把字符a和字符b连接,然后把“ab”放在一个新的存储空间,记为space2,最后让s指向这块空间
//我们可以看到,现在s和t所指向的是两块不同的空间,空间中的内容也不一样,因此s和t的效果是不一样的
/* StringBuilder部分 */
StringBuilder sb = new StringBuilder("a"); //开辟一个存储空间,里面存着字符a
StringBuilder tb = sb; //开辟一个存储空间,里面存着字符a
sb.append("b"); //取出a,然后与字符b连接,然后把“ab”仍然放在这块空间内,把原来的“a”覆盖了,sb的指向没变
//在这个情况下,由于从始至终只用到了一块存储空间,所以sb和tb的效果实际上是相同的
mutable 优点:
- 拷贝:不可变类型,频繁修改会产生大量的临时拷贝,需要垃圾回收;可变类型,最少化拷贝,以提高效率
- 获得更好的性能
- 模块之间共享数据
UnmodifiableCollections:Java设计有不可变的集合类提供使用
值的改变 & 引用的改变
- “改变一个变量”:将该变量指向另一个值的存储空间(引用)
- “改变一个变量的值”:将该变量当前指向的值的存储空间中写入一个新的值
表示泄露和防御式拷贝
通过防御式拷贝,给客户端返回一个全新的对象(副本),客户端即使对数据做了更改,也不会影响到自己。例如:
return new Date(groundhogAnswer.getTime());
大部分时候该拷贝不会被客户端修改,可能造成大量的内存浪费
如果使用不可变类型,则节省了频繁复制的代价
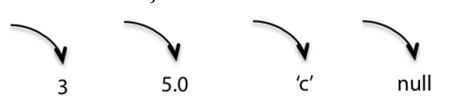
Snapshot diagram
运行时、代码层面、瞬时
- 基本类型的值
- 对象类型的值
- 可变对象:单线圈

- 不可变对象:双线圈

- 不可变的引用:双线箭头
- 可变的引用:单线箭头

- 引用是不可变的,但指向的值却可以是可变的
- 可变的引用,也可指向不可变的值
- 可变对象:单线圈
例:用Snapshot表示String和StringBuilder的区别
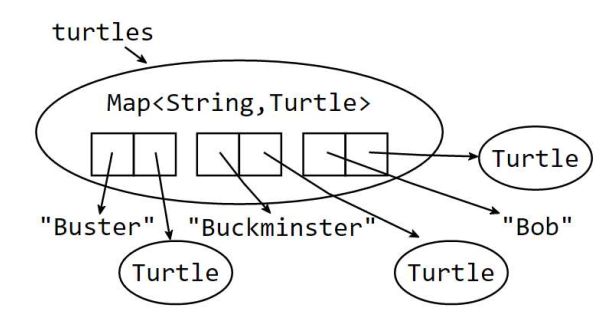
集合类Snapshot图
- List

- Set

- Map
3.2 设计规约(Specification)
Spec概念
程序和客户端达成的一致

作用:
- 给“供需双方”都确定了责任并区分责任,调用时双方都要遵守(客户端只需要理解Spec即可)
- 隔离“变化”、降低耦合度
- 不需要了解具体实现

要素:
- 输入数据类型(客户端约束)
- 输出数据类型(内部实现约束)
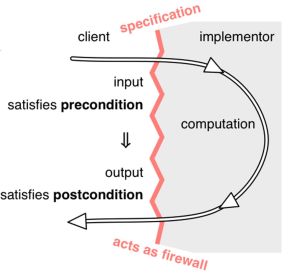
前置条件 & 后置条件
- 前置条件:For 客户端
- 后置条件:For 开发者
- 契约:
前置条件满足了,后置条件必须满足;
前置条件不满足,后置条件不一定满足(输入错误,可以抛出异常)。
行为等价性
- 站在客户端角度、根据规约:功能是否等价
例:以下两段代码是否等价
规约:


解:
- 当
val在范围内时,两者返回相同; - 当
val不在范围内时,前者返回arr.length,后者返回-1; - 根据规约,两者效果相同,因此等价。
Spec的写法
- 方法注释
@param@return@throws- 输入类型、返回类型
一个好的Spec应该:
- 内聚的
Spec描述的功能应单一、简单、易理解
规约做了两件事,所以要分离开形成两个方法。 - 信息丰富的
不能让客户端产生理解歧义 - 足够“强”
太弱的spec,客户不放心
开发者应尽可能考虑特殊情况,在post-condition给出处理措施 - 足够“弱”
太强的spec,在很多特殊情况下难以达到,给开发者增加了实现的难度(client当然非常高兴)
Spec的强度
- 前置条件越弱,规约强度越强;
- 后置条件越强,规约强度越强;
- 规约越强,开发者责任越重,客户端责任越轻;

- 某个具体实现,若满足规约,则落在其范围内;否则,在其之外。
- 程序员可以在规约的范围内自由选择实现方式;
- 更强的规约,表达为更小的区域;
3.3 抽象数据类型(ADT)
设计ADT:规格Spec–>表示Rep–>实现Impl
四类ADT操作
- Creators
- 实现:构造函数constructor或静态方法(也称factory method)
- Producers
- 需要有“旧对象”
return新对象- eg.
String.concat()
- Observers
- eg.
List的.size()
- eg.
- Mutators
- 改变对象属性
- 若返回值为
void,则必然改变了对象内部状态(必然是mutator)
表示独立性
- client使用ADT时无需考虑其内部如何实现,ADT内部表示的变化不应影响外部spec和客户端。
抽象函数AF & 表示不变量RI
- 抽象值构成的空间(抽象空间):客户端看到和使用的值
- 程序内部用来表示抽象值的空间(表示空间):程序内部的值
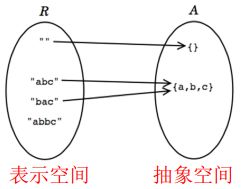
- Mapping:满射、未必单射(未必双射)
ADT开发者关注表示空间R,client关注抽象空间A
-
抽象函数(AF):
- R和A之间映射关系的函数
- 即如何去解释R中的每一个值为A中的每一个值。
- AF : R → A
- R中的部分值并非合法的,在A中无映射值
-
表示不变性(RI):
- 某个具体的“表示”是否是“合法的”
- 所有表示值的一个子集,包含了所有合法的表示值
- 一个条件,描述了什么是“合法”的表示值
- 检查RI:
随时检查RI是否满足
在所有可能改变rep的方法内都要检查
Observer方法可以不用,但建议也要检查,以防止你的“万一”
测试ADT
因为测试相当于client使用ADT,所以它也不能直接访问ADT内部的数据域,所以只能调用其他方法去测试被测试的方法。
-
针对creator:构造对象之后,用observer去观察是否正确
-
针对observer:用其他三类方法构造对象,然后调用被测observer,判断观察结果是否正确
-
针对producer:produce新对象之后,用observer判断结果是否正确
以注释的形式撰写AF、RI、 Safety from Rep Exposure
- 在代码中用注释形式记录AF和RI
- 精确的记录RI:rep中的所有fields何为有效
- 精确记录AF:如何解释每一个R值
- 表示泄漏的安全声明
- 给出理由,证明代码并未对外泄露其内部表示——自证清白
3.4 面向对象编程(OOP)
接口(Interface)& 抽象类(Abstract Class)& 具体类(Concrete Class)
接口:定义ADT
类:实现ADT
Concrete class --> Abstract Class --> Interface
接口:
- 接口之间可以继承与扩展
- 一个类可以实现多个接口(从而具备了多个接口中的方法)
- 一个接口可以有多种实现类
抽象类:
- 至少有一个抽象方法
- 抽象方法 Abstract Method
- 未被实现
- 如果某些操作是所有子类型都共有,但彼此有差别,可以在父类型中设计抽象方法,在各子类型中重写
具体类:
- 实现所有父类未实现的方法
继承(Inheritance) & 重写(Override)
- 类 & 类:继承
- 类 & 接口:实现、扩展
覆盖/重写Override:
- 重写的函数:完全同样的signature
- 实际执行时调用哪个方法,运行时决定
- 重写的时候,不要改变原方法的本意
- 运行阶段进行动态检查
- 父类型中的被重写函数体
- 不为空:
- 该方法是可以被直接复用的
- 对某些子类型来说,有特殊性,可重写父类型中的函数,实现自己的特殊要求
- 为空:
- 其所有子类型都需要这个功能
- 但各有差异,没有共性,在每个子类中均需要重写
- 不为空:
super
- 重写之后,利用
super()复用了父类型中函数的功能,还可以对其进行扩展 - 如果是在构造方法中调用父类的构造方法,则必须在构造方法的第一行调用
super()
严格继承:子类只能添加新方法,无法重写超类中的方法(方法带
final关键字)
多态(Polymorphism) & 重载(Overload)
重载:多个方法具有同样的名字,但有不同的参数列表或返回值类型。
Override和Overload
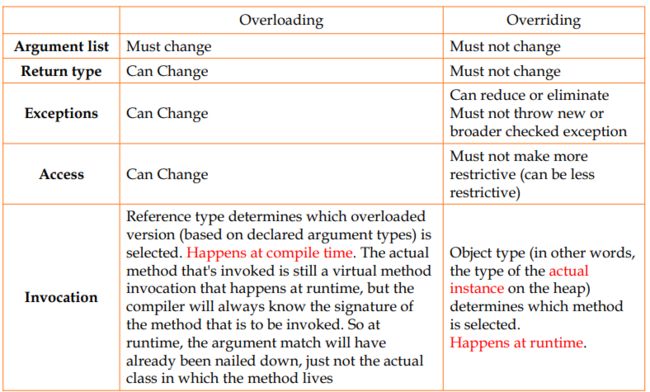
-
特殊多态:功能重载
- 方便client调用:client可用不同的参数列表,调用同样的函数
- 根据参数列表进行最佳匹配
public void changeSize(int size, String name, float pattern) {}- 重载函数错误情况❌
public void changeSize(int length, String pattern, float size) {}:虽然参数名不同,但类型相同public boolean changeSize(int size, String name, float pattern) {}:参数列表必须不同
- 在编译阶段时决定要具体执行哪个方法(与之相反,overridden methods则是在run-time进行dynamic checking)
- 可以在同一个类内重载,也可在子类中重载
-
参数化多态:使用泛型
?编程 -
子类型多态:期望不同类型的对象可以统一处理而无需区分,遵循LSP原则
3.5 ADT和OOP中的等价性
不可变对象的引用等价性 & 对象等价性
-
==
引用等价性
相同内存地址
对于:基本数据类型 -
equals()
对象等价性
对于:对象类型 -
在自定义ADT时,需要用
@Override重写Object.equals()(在Object中实现的缺省equals()是在判断引用等价性) -
如果用
==,是在判断两个对象身份标识 ID是否相等(指向内存里的同一段空间)
equals() & hashCode()
equals()的性质:自反、传递、对称、一致性
equals()重写范例- 判断引用等价性
- 判断类的一致性
- 判断具体值是否满足等价条件(自定义)
- 以Lab3的
Plane为例
@Override
public boolean equals(Object o) {
if (o == this)
return true;
if (!(o instanceof Plane)) {
return false;
}
Plane plane = (Plane) o;
return Objects.equals(number, plane.number) && Objects.equals(strType, plane.strType)
&& intSeats == plane.intSeats && age == plane.age;
}
instanceof:
- 判断类
- 仅在equals里使用
hashCode():
- 等价的对象必须有相同的
hashCode - 不相等的对象,也可以映射为同样的
hashCode,但性能会变差 - 自定义ADT要重写hashcode
- 返回值是内存地址
可变对象的观察等价性 & 行为等价性
- 观察等价性: 在不改变状态的情况下,两个mutable对象是否看起来一致
- 行为等价性:调用对象的任何方法都展示出一致的结果
对可变类型来说,往往倾向于实现严格的观察等价性, 但在有些时候,观察等价性可能导致bug,甚至可能破坏RI。
四、可复用性
4.1 可复用性的概念
programming for reuse 面向复用编程:开发出可复用的软件
programming with reuse 基于复用编程:利用已有的可复用软件搭建应用系统
- 优点
- 降低成本和开发时间
- 经过充分的测试,可靠、稳定
- 标准化,在不同应用中保持一致

4.2 面向复用的软件构造技术
Liskov Substitution Principle 里氏替换原则(LSP)
- 子类型多态:客户端可用统一的方式处理不同类型的对象
- 在可以使用父类的场景,都可以用子类型代替而不会有任何问题
- 编译强制规则
- 子类型可以增加方法,但不可删除方法
- 子类型需要实现抽象类型中的所有未实现方法
- 协变:子类型中重写的方法必须有相同或子类型的返回值或者符合co-variance的参数
- 逆变:子类型中重写的方法必须使用同样类型的参数或者符合contra-variance的参数
- 子类型中重写的方法不能抛出额外的异常
- Also applies to specified behavior (methods):
- Same or stronger invariants 更强的不变量
- Same or weaker preconditions 更弱的前置条件
- Same or stronger postconditions 更强的后置条件
协变 & 反协变
父类型 → 子类型:
- 协变:返回值和异常不变或越来越具体
- 逆变(反协变):参数类型要相反地变化,要不变或越来越抽象

泛型
泛型类型是不支持协变的:
如
ArrayList是List的子类型,但List不是List的子类型
这是因为发生了类型擦除,运行时就不存在泛型了,所有的泛型都被替换为具体的类型。
但是在实际使用的过程中是存在能够处理不同的类型的泛型的需求的,如定义一个方法参数是List类型的,但是要适应不同的类型的E,于是可使用通配符?来解决这个需求:
- 无类型条件限制:
public static void printList(List<?> list) {
for (Object elem: list)
System.out.print(elem + " ");
}
- 当为A类型的父类型
public static void printList(List<? super A> list){
...}
- 当为A类型的子类型
public static void printList(List<? extends A> list){
...}
委派(Delegation)
- 一个对象请求另一个对象的功能
- 通过运行时动态绑定,实现对其他类中代码的动态复用
- “委托”发生在object层面
- “继承”发生在class层面


Types of Delegation:
- 依赖 Dependency:临时性的delegation
- 把被delegation的对象以参数方式传入。只有在需要的时候才建立与被委派类的联系,而当方法结束的时候这种关系也就随之断开了。
class Duck {
//no field to keep Flyable object
public void fly(Flyable f) {
f.fly(); } //让这个鸭子以f的方式飞
public void quack(Quackable q) {
q.quack() }; //让鸭子以q的方式叫
}
- 关联 Association:永久性的delegation
- 分为:组合(Composition)和聚合(Aggregation)
- 被delegation的对象保存在rep中,该对象的类型被永久的与此ADT绑定在了一起。
- 组合 Composition:更强的Association,但难以变化
- 在rep或构造方法中设定
Duck d = new Duck();
d.fly();
class Duck {
//这两种实现方式的效果是相同的
Flyable f = new FlyWithWings(); //写死在rep中
public Duck() {
f = new FlyWithWings(); } //写死在构造方法中
public void fly(){
f.fly(); }
}
- 聚合 Aggregation:更弱的Association,可动态变化
- 在构造方法中传入参数绑定
Flyable f = new FlyWithWings();
Duck d = new Duck(f);
d.fly();
class Duck {
Flyable f; // 这个必须由构造方法传入参数绑定
public Duck(Flyable f) {
this.f = f; } // 在此传入
public void fly(){
f.fly(); }
}
组合(Composition)和CRP原则
- 利用delegation的机制,将功能的具体实现与调用分离,在实现中又通过接口的继承树实现功能的不同实现方法,而在调用类中只需要创建具体的子类型然后调用即可。组合就是多个不同方面的delegation的结合。
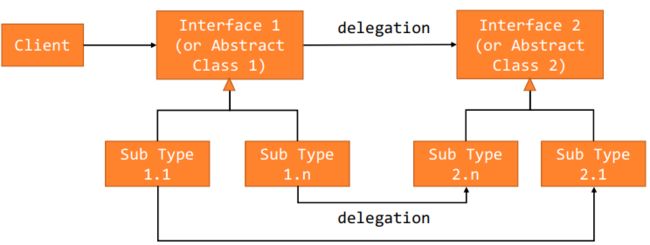
- 抽象层是不会轻易发生变化的,会发生变化的只有底层的具体的子类型,而具体功能的变化(实现不同的功能)也是在最底层,所以抽象层是稳定的。而在具体层,两个子类之间的委派关系就有可能是稳定的也有可能是动态的,这取决于需求和设计者的设计决策。

白盒框架 & 黑盒框架的原理与实现
- 黑盒框架
- 通过实现特定接口进行框架扩展,采用的是delegation机制达到这种目的,通常采用的设计模式是策略模式(Strategy)和观察者模式(Observer);
- 黑盒所预留的是一个接口,在框架中只调用接口中的方法,而接口中方法的实现就依据派生出的子类型的不同而不同,它的客户端启动的就是框架本身。
- 白盒框架
- 通过继承和重写实现功能的扩展,通常的设计模式是模板模式(Template Method);
- 白盒框架所执行的是框架所写好的代码,只有通过override其方法来实现新的功能,客户端启动的的是第三方开发者派生的子类型。
4.3 面向复用的设计模式
Adapter 适配器模式
- 将某个类/接口转换为client期望的其他形式
- 增加接口
- 通过增加一个接口,将已存在的子类封装起来
- client面向接口编程,从而隐藏了具体子类。
适用场合:你已经有了一个类,但其方法与目前client的需求不一致。
根据OCP原则,不能改这个类,所以扩展一个adaptor和一个统一接口。

Decorator 装饰者模式
继承组合会引起组合爆炸/代码重复
- 为对象增加不同侧面的特性
- 对每一个特性构造子类,通过委派机制增加到对象上
- 客户端需要一个具有多种特性的object,通过逐层的装饰来实现
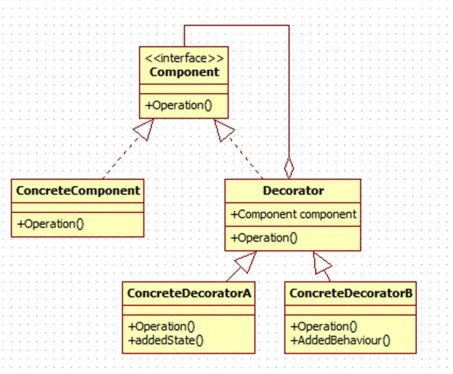
例子:
Stack对应上图Component接口ArrayStack对应ConcreteComponent,基础类StackDecorator对应Decorator,装饰类(可以是抽象类)UndoStack对应ConcreteDecoratorA,装饰类的具体类
//Stack接口,定义了所有的Stack共性的基础的功能
interface Stack {
void push(Item e);
Item pop();
}
//最基础的类,啥个性也没有的Stack,只有共性的实现
public class ArrayStack implements Stack {
... //rep
public ArrayStack() {
...}
public void push(Item e) {
...}
public Item pop() {
... }
}
//装饰器类,可以是一个抽象类,用于扩展出有各个特性方面的各个子类
public abstract class StackDecorator implements Stack {
protected final Stack stack; //用来保存delegation关系的rep
public StackDecorator(Stack stack) {
this.stack = stack; //建立稳定的delegation关系
}
public void push(Item e) {
stack.push(e); //通过delegation完成任务
}
public Item pop() {
return stack.pop(); //通过delegation完成任务
}
}
//一个有撤销特性功能的子类
public class UndoStack extends StackDecorator implements Stack {
private final UndoLog log = new UndoLog();
public UndoStack(Stack stack) {
super(stack); //调用父类的构造方法建立delegation关系
}
public void push(Item e) {
log.append(UndoLog.PUSH, e); //实现个性化的功能
super.push(e); //共性的功能通过调用父类的实现来完成
}
public void undo() {
//implement decorator behaviors on stack
}
...
}
- 使用装饰对象:层层嵌套初始化
new Class1(new Class2(new Class3(...)))
// 先创建出一个基础类对象
Stack s = new ArrayStack();
// 利用UndoStack中继承到的自己到自己的委派建立起从UndoStack到ArrayStack的delegation关系
// 这样,UndoStack也就能够实现最基础的功能,并且自身也实现了个性化的功能
Stack us = new UndoStack(s);
// 通过一层层的装饰实现各个维度的不同功能
Stack ss = new SecureStack(new SynchronizedStack(us));
JDK中装饰器模式的应用:
static ListunmodifiableList(List list)
static SetsynchronizedSet(Set set)
facade 外观模式
- 客户端需要通过一个简化的接口来访问复杂系统内的功能
- 提供一个统一的接口来取代一系列小接口调用,相当于对复杂系统做了一个封装,简化客户端使用
- 便于客户端学习使用,解耦
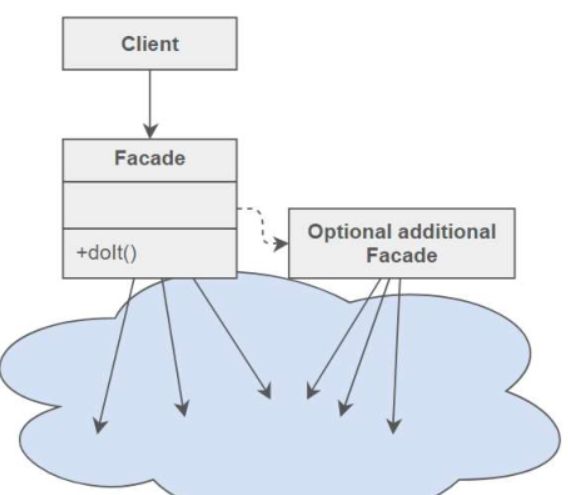
Strategy 策略模式
- 有多种不同的算法来实现同一个任务
- 但需要client根据需要动态切换算法,而不是写死在代码里
- 为不同的实现算法构造抽象接口,利用delegation,运行时动态传入client倾向的算法类实例
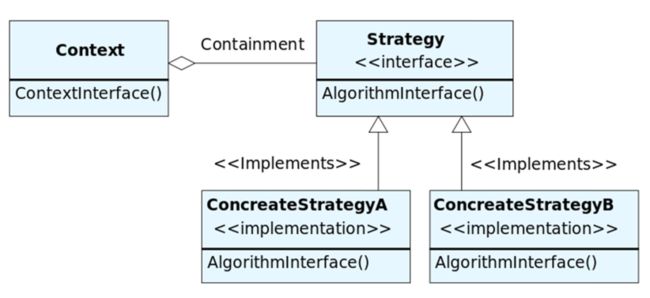
Template Method 模板方法模式
- 框架:白盒框架
- 做事情的步骤一样,但具体方法不同
- 共性的步骤在抽象类内公共实现,差异化的步骤在各个子类中实现
- 使用继承和重写实现模板模式

适用场合:有共性的算法流程,但算法各步骤有不同的实现典型的“将共性提升至超类型,将个性保留在子类型”
Iterator 迭代器模式
- 客户端希望遍历被放入容器/集合类的一组ADT对象,无需关心容器的具体类型
- 也就是说,不管对象被放进哪里,都应该提供同样的遍历方式
实现方式是在ADT类中实现Iterable接口,该接口内部只有一个返回一个迭代器的方法,然后创建一个迭代器类实现Iterator接口,实现hasnext()、next()、remove()这三个方法。
五、可维护性
5.1 可维护性的度量
可维护性的常见度量指标
指标:
- 可维护性
- 可扩展性
- 灵活性
- 可适应性
- 可管理性
- 支持性
- 实际方法:
- 继承的层次数
- 类之间的耦合度
- 单元测试的覆盖度
聚合度与耦合度
模块化编程:高内聚 & 低耦合
5 Rules of Modularity Design:
- Direct Mapping 直接映射
- Few Interfaces 尽可能少的接口
- Small Interfaces 尽可能小的接口
- Explicit Interfaces 显式接口
- Information Hiding 信息隐藏
5.2 可维护性的构造原则 SOLID
- (SRP) The Single Responsibility Principle 单一责任原则
- 责任:变化的原因
- 不应该有多于1个原因让你的ADT发生变化,否则就拆分开
- (OCP) The Open-Closed Principle 开放-封闭原则
- 对扩展性的开放
- 模块的行为应是可扩展的
- 从而该模块可表现出新的行为以满足需求的变化
- 对修改的封闭
- 但模块自身的代码是不应被修改的
- 扩展模块行为的一般途径是修改模块的内部实现
- 如果一个模块不能被修改,那么它通常被认为是具有固定的行为
- 关键的解决方案:抽象技术
- 对扩展性的开放
- (LSP) The Liskov Substitution Principle 里氏替换原则
- 子类型必须能够替换其基类型
- 派生类必须能够通过其基类的接口使用,客户端无需了解二者之间的差异
- (ISP) The Interface Segregation Principle 接口聚合原则
- 不能强迫客户端依赖于它们不需要的接口:只提供必需的接口(聚合接口)
- 客户端不应依赖于它们不需要的方法
- (DIP) The Dependency Inversion Principle 依赖转置原则
- 抽象的模块不应依赖于具体的模块
- 具体应依赖于抽象
5.3 面向可维护性的设计模式和构造技术
Factory Method 工厂方法模式
虚拟构造器
- 当client不知道要创建哪个具体类的实例,或者不想在client代码中指明要具体创建的实例时,用工厂方法。
- 定义一个用于创建对象的接口,让其子类来决定实例化哪一个类,从而使一个类的实例化延迟到其子类。
Abstract Factory 抽象工厂模式
- 提供接口以创建一组相关/相互依赖的对象,但不需要指明其具体类。
- 创建的不是一个完整产品,而是“产品族”(遵循固定搭配规则的多类产品的实例),得到的结果是:多个不同产品的object,各产品创建过程对client可见,但“搭配”不能改变。
- 本质上,Abstract Factory是把多类产品的factory method组合在一起
例子
- 一个UI,包含多个窗口控件,这些控件在不同的OS中实现不同
- 一个仓库类,要控制多个设备,这些设备的制造商各有不同,控制接口有差异
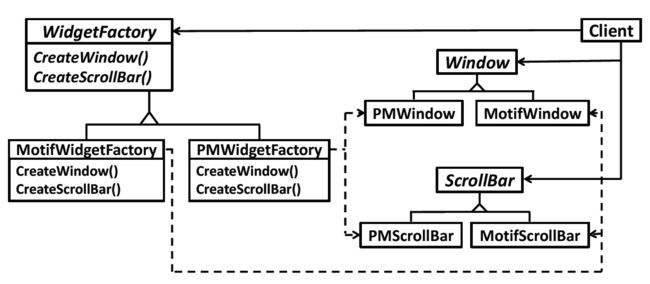
Abstract Factory vs Factory Method
| Abstract Factory | Factory Method |
|---|---|
| 创建多个类型对象 | 创建一个对象 |
| 多个factory方法 | 一个factory方法 |
| 使用组合/委派 | 使用继承/子类型 |
Proxy 代理模式
- 某个对象比较“敏感”/“私密”/“贵重”,不希望被client直接访问到,故设置proxy,在二者之间建立防火墙。
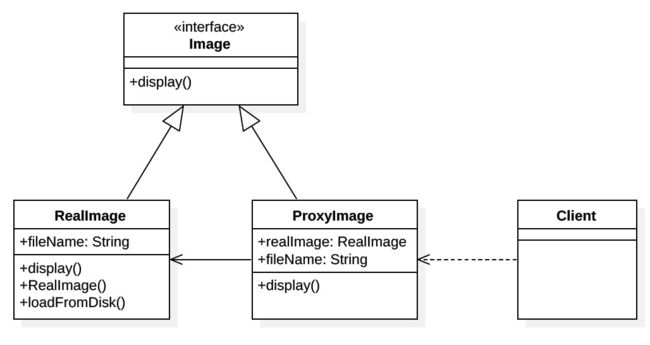
public class ProxyImage implements Image {
private Image realImage;
private String fileName;
public ProxyImage(String fileName){
this.fileName = fileName; // 不需要在构造的时候从文件装载
}
@Override
public void display() {
if(realImage == null) {
// 如果display的时候发现没有装载,则再委派
realImage = new RealImage(fileName); // Delegate到原来的类来成具体装载
}
realImage.display();
}
}
- 客户端
Image image = new ProxyImage("pic.jpg");
image.display();
image.display();
- 在
new ProxyImage("pic.jpg")时仅仅是将文件名保存下来,没有加载真正的图片RealImage; - 在第一次调用
Image.display()时,image委派Rep中的realImage进行加载,并显示; - 在第二次调用,因为已经加载过,因此直接委派
realImage.display()显示
Adaptor和Proxy区别
- Adaptor目的:消除不兼容,目的是B以客户端期望的统一的方式与A建立起联系。
- Proxy目的:隔离对复杂对象的访问,降低难度/代价,定位在“访问/使用行为

Observer 观察者模式
- 本ADT随时获取另一ADT状态变化
- 一对多广播
- “偶像”对“粉丝”广播

- 需要广播的ADT记录着所有观察自己的Observer,在自己状态变化时,对于每个Observer调用其
Update()方法进行更新,即获取该ADT的状态变化
Java里已经实现了该模式,提供了
Observable抽象类(直接派生子类即可,构造“偶像”)
Java提供了Observer接口,实现该接口,构造“粉丝”
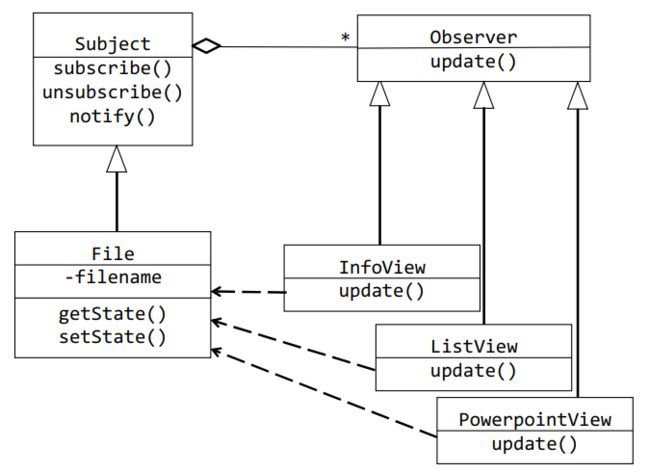
//偶像类
public class Subject {
private List<Observer> observers = new ArrayList<Observer>();//维护一个粉丝列表
private int state;
public int getState() {
return state; }
public void attach(Observer observer){
observers.add(observer); } //粉丝关注偶像
public void setState(int state) {
this.state = state;
notifyAllObservers(); //状态有变化的时候广播给粉丝
}
private void notifyAllObservers(){
for (Observer observer : observers)
observer.update();
}
}
//粉丝类
public abstract class Observer {
//粉丝的抽象接口
protected Subject subject;
public abstract void update();
}
public class BinaryObserver extends Observer{
//粉丝的具体类
public BinaryObserver(Subject subject){
this.subject = subject; // 关注偶像
this.subject.attach(this); // 告知偶像自己关注了他
}
@Override
public void update() {
//被偶像回调,通知自己有新消息
//可能有不同的行为
System.out.println("Binary String: "+Integer.toBinaryString(subject.getState()));
}
}
//
public class ObserverPatternDemo {
public static void main(String[] args) {
Subject subject = new Subject(); //一个偶像
new HexaObserver(subject); //三个粉丝
new OctalObserver(subject);
new BinaryObserver(subject);
System.out.println("First state change: 15");
subject.setState(15); //偶像状态变化,虽然没有直接调用粉丝行为的代码,但确实有对粉丝的delegation
System.out.println("Second state change: 10");
subject.setState(10);
}
}
Visitor 访问者模式
- 对特定类型的object的特定操作(visit),在运行时将二者动态绑定到一起,该操作可以灵活更改,无需更改被visit的类
- 本质上:将数据和作用于数据上的某种/些特定操作分离开来
- 为ADT预留一个将来可扩展功能的“接入点”,外部实现的功能代码可以在不改变ADT本身的情况下通过delegation接入ADT

即:“我”(源ADT)允许(调用
this.accept())“你”(visitor)来访问我的数据(在accept()方法内委派visitor.visit())——数据源主动允许访问
使得访问方法可以变化
可以为源ADT预留功能
/* Abstract element interface (visitable) */
public interface ItemElement {
public int accept(ShoppingCartVisitor visitor); //埋下一个槽
}
/* Concrete element */
public class Book implements ItemElement{
private double price;
...
int accept(ShoppingCartVisitor visitor) {
visitor.visit(this); //把自己通过这个槽传过去
}
}
public class Fruit implements ItemElement{
private double weight;
...
int accept(ShoppingCartVisitor visitor) {
visitor.visit(this); //所有的子类都会实现这个槽
}
}
/* Abstract visitor interface */
public interface ShoppingCartVisitor {
int visit(Book book);
int visit(Fruit fruit);
}
public class ShoppingCartVisitorImpl implements ShoppingCartVisitor {
//一种实现
public int visit(Book book) {
int cost=0;
if(book.getPrice() > 50) cost = book.getPrice()-5;
else cost = book.getPrice();
System.out.println("Book ISBN::"+book.getIsbnNumber() + " cost ="+cost);
return cost;
}
public int visit(Fruit fruit) {
int cost = fruit.getPricePerKg()*fruit.getWeight();
System.out.println(fruit.getName() + " cost = "+cost);
return cost;
}
}
/* Client */
public class ShoppingCartClient {
public static void main(String[] args) {
ItemElement[] items = new ItemElement[]{
new Book(20, "1234"),
new Book(100, "5678"), new Fruit(10, 2, "Banana"), new Fruit(5, 5, "Apple")};
int total = calculatePrice(items);
System.out.println("Total Cost = " + total);
}
private static int calculatePrice(ItemElement[] items) {
ShoppingCartVisitor visitor = new ShoppingCartVisitorImpl();
int sum=0;
for(ItemElement item : items)
sum = sum + item.accept(visitor);
return sum;
}
}
Visitor vs Iterator:
- Iterator:以遍历的方式访问集合数据而无需暴露其内部表示,将“遍历”这项功能delegate到外部的iterator对象。
- Visitor:在特定ADT上执行某种特定操作,但该操作不在ADT内部实现,而是delegate到独立的visitor对象,客户端可灵活扩展/改变visitor的操作算法,而不影响ADT
Strategy vs Visitor:
- visitor是站在外部client的角度,灵活增加对ADT的各种不同操作(哪怕ADT没实现该操作)
- strategy则是站在内部ADT的角度,灵活变化对其内部功能的不同配置。
State 状态模式
- 最好不要使用if/else结构在ADT内部实现状态转换(考虑将来的扩展和修改)
- 使用delegation,将状态转换的行为委派到独立的state对象去完成

Memento 备忘录模式
- 记住对象的历史状态,以便于“回滚”
- defines three distinct roles
- 需要“备忘”的类
- 添加originator的备忘记录和恢复
- 备忘录,记录originator对象的历史状态
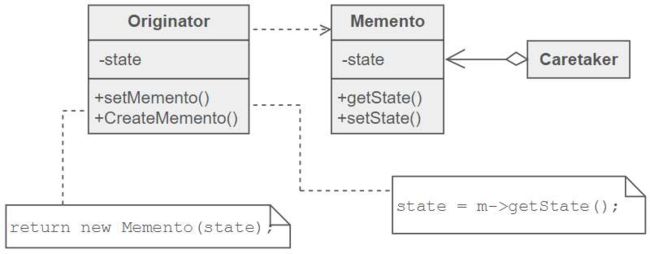
- 需要“备份”的ADT的rep中只记录当前状态
- 每次“备份”都生成一个外部的Memento对象
Caretaker负责掌控全部的状态备份,客户端通过它来操纵ADT的状态备份与恢复
5.3 语法驱动的构造
3种最重要的操作:
- Concatenation连接:
x ::= y zx matches y followed by z - Repetition重复:
x ::= y*x matches zero or more y - Union选择:
x ::= y | zx matches either y or z
例:解析
URL:http://didit.csail.mit.edu:4949/
url ::= 'http://' hostname (':' port)? '/'
hostname ::= word '.' hostname | word '.' word
port ::= [0-9]+
word ::= [a-z]+
语法解析树:

六、健壮性
6.1 健壮性和正确性的含义和区别
- 健壮性:系统在不正常输入或不正常外部环境下仍能够表现正常的程度
- 面向健壮性的编程
- 处理未期望的行为和错误终止
- 即使终止执行,也要准确/无歧义的向用户展示全面的错误信息
- 错误信息有助于进行debug
- Robustness principle (Postel’s Law):对自己的代码要保守,对用户的行为要开放
- 正确性:程序按照spec加以执行的能力,是最重要的质量指标!
区别
- 正确性:永不给用户错误的结果
- 健壮性:尽可能保持软件运行而不是总是退出
- 正确性倾向于直接报错(error),健壮性则倾向于容错(fault-tolerance)
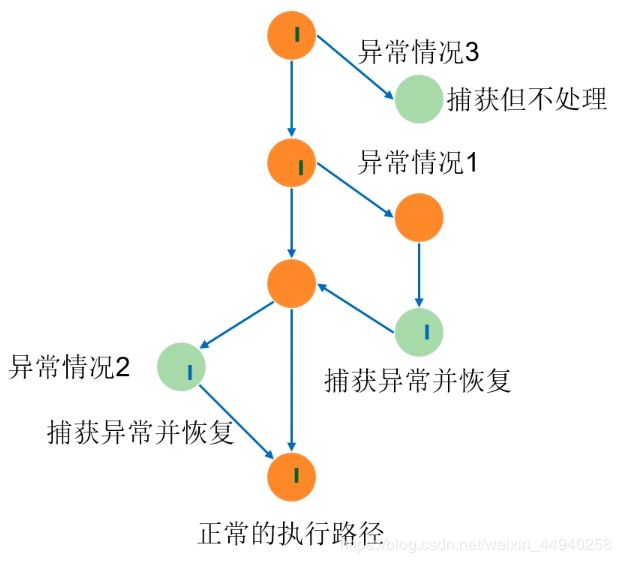
6.2 错误与异常处理
Throwable
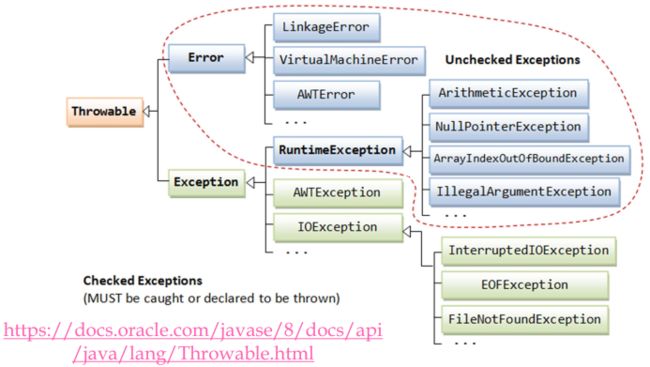
Java中的内部错误(Error) & 异常(Exception)
- Error 内部错误 and Exception 异常
- 内部错误:程序员通常无能为力,一旦发生,想办法让程序优雅的结束
- 用户输入错误
- 设备错误
- 物理限制
- 异常:你自己程序导致的问题,可以捕获、可以处理
- 内部错误:程序员通常无能为力,一旦发生,想办法让程序优雅的结束
由于程序员对Error通常无法预料无法解决,因此重点关注可被解决的Exception
异常处理
Java中Exception可以被分为两个部分,蓝色的运行时异常和绿色的其他异常。
- 运行时异常:由程序员在代码里处理不当造成,在源代码中引入了故障,而如果在代码中提前进行验证,这些故障就可以避免。动态类型检查的时候会发现这种异常,而一旦出现,代码就必然有错误,可以通过调试解决。
- 其他异常:由外部原因造成,程序员无法完全控制的外在问题所导致的,即使在代码中提前加以验证,也无法完全避免失效发生。
- Java’s exception handling consists of three operations:
- Declaring exceptions (
throws)声明“本方法可能会发生XX异常”- Throwing an exception (
throw)抛出XX异常- Catching an exception (
try, catch, finally) 捕获并处理XX异常
Checked & Unchecked Exceptions区别
| Checked exception | Unchecked exception | |
|---|---|---|
| Basic | 必须被显式地捕获或者传递 (try-catch-finally-throw),否则编译器无法通过,在静态类型检查时就会报错 |
异常可以不必捕获或抛出,编译器不去检查,不会给出任何错误提示 |
| Class of Exception | 继承自Exception类(上图中的绿色部分) |
继承自RuntimeException类(上图中的蓝色部分) |
| Handling | 从异常发生的现场获取详细的信息,利用异常返回的信息来明确操作失败的原因,并加以合理的恢复处理 | 简单打印异常信息,无法再继续处理 |
| Appearance | 代码看起来复杂,正常逻辑代码和异常处理代码混在一起 | 清晰,简单 |
选取checked exception还是unchecked exception可遵循下面的原则:
- checked exception:如果客户端可以通过其他的方法恢复异常,而对开发者来说错误可预料但不可预防,它的出现已经脱离了程序能够掌控的范围。
- unchecked exception:如果客户端对出现的这种异常无能为力,而对开发者来说错误可预料可预防,它可以通过调整程序来避免出现。
Checked异常的处理机制
自定义异常类
可以选择创建自定义异常类型:
public class FooException extends Exception {
public FooException() {
super(); }
public FooException(String message) {
super(message); }
public FooException(String message, Throwable cause) {
super(message, cause); }
public FooException(Throwable cause) {
super(cause); }
}
声明异常 & 抛出异常
- 使用
throw关键字抛出异常,如:throw new EOFException();
String readData(Scanner in) throws EOFException // 声明:本函数可能发生该异常
{
. . .
while (. . .)
{
if (!in.hasNext()) // EOF encountered
{
if (n < len)
throw new EOFException(); // 异常在这里发生了
}
. . .
}
return s;
}
捕获异常 & 处理异常
可以使用try-catch语法对抛出的异常进行处理,也可以用throws语法将异常抛给上一级调用,然后在上一级中使用try-catch处理。
public static void fun() throws IOException {
// 已声明可能抛出的异常
...
}
public static void main(String args[]) {
try{
fun();
} catch (IOExeption e) {
// 延迟到此处捕获
e.printStackTrace();
}
}
所以,try-chtch所捕获到的异常可能有两个来源,一是自己内部的代码产生的,二是调用了其他的方法,并且该方法未处理抛给了本方法。
- 本来catch语句下面是用来做exception handling的,但也可以在catch里抛出异常
- 这么做的目的是:更改exception的类型,更方便client端获取错误信息并处理
try {
...
}
catch (AException e) {
// 捕获到A异常
// 抛出B异常,并带上异常消息
throw new BException( " xxx error:" + e. getMessage());
}
Finally
- 处理异常时释放资源:当异常抛出时,方法中正常执行的代码被终止,如果异常发生前曾申请过某些资源,那么异常发生后这些资源要被恰当的清理。
所以形成了try-catch-finally结构。不管程序是否碰到异常,finally都会被执行。
LSP & 异常
- 如果子类型中override了父类型中的方法,那么子类型中方法抛出的异常不能比父类型抛出的异常类型更宽泛,异常不能逆变
- 子类型方法可以抛出更具体的异常,也可以不抛出任何异常,异常可以协变
- 如果父类型的方法未抛出异常,那么子类型的方法也不能抛出异常
目的还是为了能够让客户端能够用统一的方式处理不同类型的对象。
6.3 断言与防御式编程
防御式编程的基本思想
- 最好的防御就是不要引入bug
- 如果无法避免
- 尝试着将bug限制在最小的范围内
- 限定在一个方法内部,不扩散
- Fail fast:尽快失败,就容易发现、越早修复
断言Assertion
断言:
- 在开发阶段的代码中嵌入,检验某些“假设”是否成立。若成立,表明程序运行正常,否则表明存在错误。
- 断言即是对代码中程序员所做假设的文档化,也不会影响运行时性能(在实际使用时,
assertion都会被disabled) - 语法:
assert condition : message;- 所构造
message在发生错误时显示给用户,便于快速发现错误所在
- 所构造
作用:
- 最高效、快速地找出/改正bug
- 提高可维护性
| Assertion | Exception |
|---|---|
| 提高“正确性” | 提高“健壮性” |
| 错误/异常处理是提高健壮性,处理外部行为;断言是提高正确性,处理内部行为 | 使用异常来处理你“预料到可以发生”的不正常情况;使用断言处理“绝不应该发生”的情况 |
| 内部行为 | 外部行为 |
| 处理“绝不应该发生”的情况 | 处理“可以预料到会发生”的情况 |
assert使用场所:
- 内部不变量:判断某个局部变量应该满足的条件,
assert x > 0 - 表示不变量:
checkRep() - 控制流不变量:例如,若不想让程序走向
switch-case的某个分支,则可以用断言直接在分支上assert false; - 方法的前置条件:判断传入参数是否满足前置条件
- 方法的后置条件:判断结果时候满足后置条件
6.4 代码调试
防御式编程–>测试–>调试
调试的基本过程和方法
调试 Debug:
- Debug的目的是寻求错误的根源并消除它
- Debug占用了大量的开发时间
- Debug是测试的后续步骤:test发现问题,debug消除问题
测试步骤:
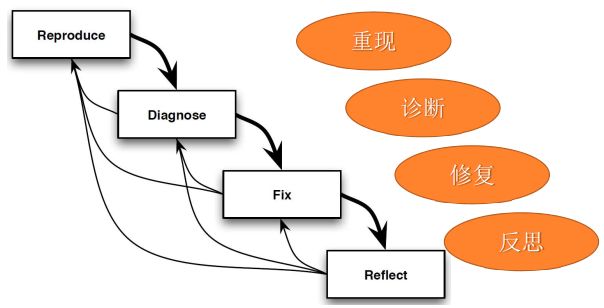
常用方法:假设-检验
Diagnose:
- Instrumentation 测量
- 即最基本的打印内容,把要观察的对象全部打印到控制台(最后要把这些语句都删掉)。
- 可使用log功能统一管理。
- Divide and Conquer 分治
- 防狼围栏算法
- Slicing 切片
- 寻找特定有关于“错误变量”的代码部分
- Focus on difference 寻找差异
- 充分利用版本控制系统,找出在哪个commit之后出现了bug症状
- Delta Debugging基于差异的调试:两个测试用例,分别通过/未通过;通过查找二者所覆盖的代码之间的差异,快速定位出可能造成bug的代码行。
- Symbolic Debugging 符号
- 符号化执行
- 不需输入特定的值,使用“符号值”(而非“实际值”)作为输入,解释器模拟程序执行,获得每个变量的“符号化表达式”,从而可判断是否执行正确。

- Debugger 调试器
使用日志开展调试
日志管理工具:
- JDK logging
- Apache Log4j
java.util.logging
通过设定日志级别来确定要log哪些信息,也可以通过Handler将日志存储在不同的地方。
日志级别(从高到低):SEVERE、WARNING、INFO、CONFIG、FINE、FINER、FINEST
设定级别:logger.setLevel(Level.INFO);
Logger
- 可以设定全局的logger,但是会造成信息混乱的后果,于是需要定义自己的logger,然后在程序中使用它。
import java.util.logging.*;
private static final Logger myLogger = Logger.getLogger("com.mycompany.myapp");
//often using class name as logger name
//或者用这种方式
public class LogTest {
static String strClassName = LogTest.class.getName(); //get class name
static Logger myLogger = Logger.getLogger(strClassName);
// using class name as logger name
...
myLogger.info(“ XXXX ”);
}
Logging Handlers
- Handler是日志的输出位置,缺省输出到控制台。
- 日志处理器也需要设定日志级别。
- Handler类型:
StreamHandler、ConsoleHandler、FileHandler、SocketHandler、MemoryHandler… - 设定处理器:
logger.addHandler(new FileHandler(“test.txt”) - 日志的格式:
SimpleFormatter、… - 设定格式:
fileHandler.setFormatter(new SimpleFormatter())
6.5 软件测试与测试优先的编程
- Unit单元测试:function、class
- Integration集成测试:classes、packages、components、subsystems
- System系统测试:system
- Regression回归测试:修改后再测试
- Acceptance验收测试
Static/Dynamic 测试
- Static:
- 不执行程序
- Reviews
- walkthroughs 预排/演练/走查
- inspections 视察
- Dynamic:
- 执行程序,有测试用例
- Debugger
使用JUnit进行单元测试(Unit Test)
单元测试:
- 针对软件最小单元
- 隔离模块
- 容易定位错误,容易调试
JUnit在测试方法前使用@Testannotation来表明这是一个JUnit测试方法。如果要在测试开始之前做一些准备则在准备方法前添加@Beforeannotation,如果要在测试结束后做一些收尾工作则在收尾方法前添加@Afterannotation。
JUnit使用的是断言机制来完成测试,常用的有三种测试方法:assertEquals()、assertTrue()、assertFalse()。
黑盒测试
- 白盒测试:对程序内部代码结构的测试
- 黑盒测试:对程序外部表现出来的行为的测试
黑盒测试:
- 检查代码功能
- 不关心内部细节
- 检查程序是否符合规约
- 用尽可能少的测试用例尽快运行、尽可能大发现程序错误
等价类划分和边界值分析
Equivalence Partitioning 等价类划分:
- 针对每个输入数据需要满足的约束条件,划分等价类,导出测试用例
- 每个等价类代表着对输入约束加以“满足/违反”的“有效/无效”数据集合
- 基于假设:相似的输入会展示相似的行为
- 因此,每个等价类选一个做代表即可,可以降低测试用例数量
Boundary Value Analysis 边界值分析
- 大量错误出现在输入域的边界而不是中央
- 对等价类划分的补充
覆盖划分的方法
- Full Cartesian product:笛卡尔积、全覆盖
- 测试完备、用例数量多、测试代价高
- Cover each Part:覆盖每个取值,最少1次即可
- 测试用例少、代价低、测试覆盖度不够高
例子:大整数乘法
- 二维输入空间
- 两个数的正负性:++,±,-+,–
- 特殊值:0,1,-1
- 很大的数

例:Max()
- 大于、等于、小于
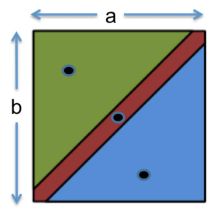
测试覆盖度
Code Coverage代码覆盖度:已有的测试用例有多大程度覆盖了被测程序 。
- 代码覆盖度越低,测试越不充分;
- 代码覆盖度越高,测试代价越高。
测试覆盖种类:
- Function 函数覆盖
- Statement 语句覆盖
- Branch 分支覆盖
- if、while、switch-case、for
- Condition条件覆盖 ≈ 分支覆盖
- Path路径覆盖
- 分支的组合 = 路径
测试效果:路径覆盖 > 分支覆盖 > 语句覆盖
测试难度:路径覆盖 > 分支覆盖 > 语句覆盖
100%语句覆盖是common(正常)目标
100%分支覆盖是desirable(令人满意的),arduous(很难实现),有些行业有更高标准
100%路径覆盖是infeasible(不可实行的)
以注释的形式撰写测试策略
- 在程序中显式记录测试策略(根据什么来选择测试用例)
- 在代码评审的过程中,其他人可以理解你的测试,并评判测试是否足够充分

七、并行
7.1 并发Concurrent
并发:
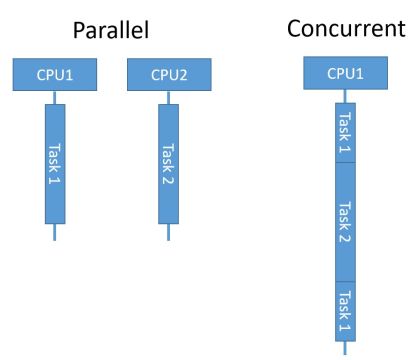
Two Models for Concurrent Programming:
- 共享内存:在内存中读写共享数据
- 两个处理器,共享内存
- 同一台机器上的两个程序,共享文件系统
- 同一个Java程序内的两个线程,共享Java对象

- 消息传递:通过channel交换消息
- 网络上的两台计算机,通过网络连接通讯
- 浏览器和Web服务器,A请求页面,B发送页面数据给A
- 即时通讯软件的客户端和服务器
- 同一台计算机上的两个程序,通过管道连接进行通讯
进程和线程
Process 进程
- 私有空间,彼此隔离
- 拥有整台计算机的资源
- 多进程之间不共享内存
- 一般来说,进程 = 程序 =应用
- JVM通常运行单一进程,但也可以创建新的进程
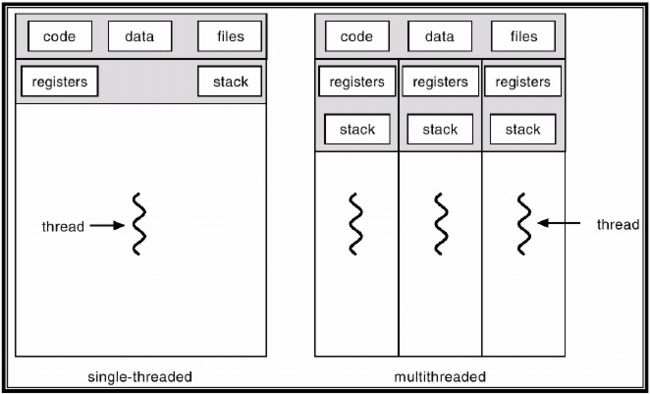
Threads 线程
- 程序内部的控制机制
- 共享内存
- 区分:进程 = 虚拟机;线程=虚拟CPU
常见应用:

Java中创建线程的两种方式
注意:要使用.start()方法,而不是.run()
从Thread类派生出子类:
- 这个方法由于是通过继承来实现的,所以如ADT已经有父类了,就不能使用这种方法了,所以应用较少。
//从Thread类派生子类
public class HelloThread extends Thread {
public void run() {
//待做的事都放在这个方法中,所以这个方法必须实现
System.out.println("Hello from a thread!");
}
public static void main(String args[]) {
//两种启动线程的方式
HelloThread p = new HelloThread();
p.start(); //注意是使用start()方法来启动的
//或者可以直接这样
(new HelloThread()).start();
}
}
从Runnable接口构造Thread对象:
- 更常用
//实现Runnable接口
public class HelloRunnable implements Runnable {
public void run() {
//与方法一相同
System.out.println("Hello from a thread!");
}
public static void main(String args[]) {
(new Thread(new HelloRunnable())).start(); //启动方式略有不同
}
}
//另一种实现方式是实现匿名类来实现Runnable接口
new Thread(new Runnable() {
public void run() {
System.out.println("Hello");
}
}).start();
交错和竞争
Time slicing 时间分片
- 通过时间分片,在多个进程/线程之间共享处理器
- 时间分片是由OS自动调度的
- 程序应该在任何调度方案下正常执行
共享内存和消息传递都会带来交错和竞争
并行程序难以测试和调试:
- 很难测试和调试因为竞争条件导致的bug
- 因为交错的存在,导致很难复现bug
- 增加print语句甚至导致这种bug消失!
利用某些方法调用来主动影响线程之间的交错关系
Thread.sleep(time):线程的休眠Thread.interrupt():向线程发出中断信号Thread.yield():使用该方法,线程告知调度器放弃CPU的占用权,从而可能引起调度器唤醒其他线程。尽量避免使用该方法。Thread.join():让当前线程保持执行,直到其执行结束。
t.isInterrupted()检查t是否已在中断状态中
当某个线程被中断后,一般来说应停止其run()中的执行,取决于程序员在run()中处理
7.2 线程安全策略
- 线程之间的“竞争条件”:作用于同一个mutable数据上的多个线程,彼此之间存在对该数据的访问竞争并导致interleaving,导致post-condition可能被违反,这是不安全的。

紧闭 Confinement
- 线程之间不共享mutable数据类型
- 如果一个ADT的rep中包含mutable的属性且多线程之间对其进行mutator操作,那么就很难使用confinement策略来确保该ADT是线程安全的
不可变 Immutability
- 使用不可变数据类型和不可变引用,避免多线程之间的race condition
final:变量只读,不可写- 如果ADT中使用了beneficent mutation,必须要通过“加锁”机制来保证线程安全
线程安全数据类型
- 如果必须要用mutable的数据类型在多线程之间共享数据,要使用线程安全的数据类型
- 集合类都是线程不安全的
- 一般来说,JDK同时提供两个相同功能的类,一个是threadsafe,另一个不是。原因:threadsafe的类一般性能上受影响
- Java API提供了进一步的decorator:
synchronizedXXX
private static Map<Integer,Boolean> cache = Collections.synchronizedMap(new HashMap<>());
- 在使用
synchronizedMap(hashMap)之后,不要再把参数hashMap共享给其他线程,不要保留别名,一定要彻底销毁 - 即使在线程安全的集合类上,使用
iterator也是不安全的 - 即使是线程安全的集合类,仍可能产生竞争:执行其上某个操作是threadsafe的,但如果多个操作放在一起,仍旧不安全
Synchronization & Lock
Principle:线程安全不应依赖于偶然
同步机制:通过锁的机制共享线程不安全的可变数据,变并行为串行。
Locks:
- 使用锁机制,获得对数据的独家mutation权,其他线程被阻塞,不得访问
- acquire:允许线程获得锁的所有权
- release:放弃锁的所有权,允许另一个线程获得它的所有权。
使用方法:
- 在Java中,任何对象都可以作为锁。可以创建一个没有意义的对象
Object lock = new Object();作为锁来使用,而拥有lock的线程可独占式的执行该部分代码。
Object lock = new Object();
synchronized (lock) {
// 线程阻塞在这里,直到锁被释放
// 现在这个线程获得了这把锁
do1(); //这个块中的所有语句都不能被打断了
// 退出块的同时释放锁
}
// 此时在另一个线程里有如下代码
synchronized (lock) {
//要等待lock被释放才能开始执行
do2(); //与上面线程里的代码操作的是同一个数据
}
作用:
- mutual exclusion互斥
- 拥有lock的线程可独占式的执行该部分代码

- 要互斥,必须使用同一个lock进行保护
- 对
synchronized的方法,多个线程执行它时不允许interleave,也就是说“按原子的串行方式执行”
ADT加锁:
- 用ADT自己做lock:
synchronized(this) - 所有对ADT的rep的访问都加锁
Monitor模式:
- ADT所有方法都是互斥访问
- 方法关键字中加入
synchronized相当于synchronized(this)
// 将synchronized关键字加在了方法声明里,效果与上面的写法相同
public synchronized void xxx(...){
...
}
在任何地方synchronized?
- No!
- 同步机制给性能带来极大影响
- 尽可能减小lock的范围
public static synchronized boolean findReplace(EditBuffer buf, ...)- 使用
static方法意味着在class层面上锁,对性能带来极大损耗。
- 使用
所有关于threadsafe的设计决策也都要在ADT中记录下来
Locking discipline
- 任何共享的mutable变量/对象必须被lock所保护
- 涉及到多个mutable变量的时候,它们必须被同一个lock所保护
- monitor pattern中,ADT所有方法都被同一个
synchronized(this)所保护
方法加
synchronized关键字:将多个atomic的操作组合为更大的atomic操作
死锁
死锁:多个线程竞争lock,相互等待对方释放lock。
- 典型的形式:交错申请锁
// T1:
synchronized(a){
//T1线程拿到了a锁
synchronized(b){
//T1线程等待T2线程释放b锁
...
}
}
// T2:
synchronized(b){
//T2线程拿到了b锁
synchronized(a){
//T2线程等待T1线程事放a锁
...
}
}
解决办法:
- lock ordering 锁排序:对所有的锁进行排序,按照排好的顺序来申请锁,所以,就一定会有一个线程最先拿到第一把锁,进而可以拿到所有的锁(因为其他线程拿不到第一把锁,都被挂起了)。
这个办法不是很常用,因为不是所有的对象都可以排序,而如果只是为了增加锁的功能而实现Comparable就太不划算了。
- coarse-grained locking 增加锁:除了原来使用的锁之外,在最外层增加一个新的锁,所有的线程都会先去申请这把锁,没申请到的线程自然就都被挂起了,所以拿到第一把锁的线程就能拿到所有的锁了。这个办法比较常用。
这两个办法的思想都是要让所有的线程在第一次申请锁的时候申请同一把锁,因此当一个线程先拿到一把锁的时候其他线程都被挂起了,所以这个线程就能顺利拿到后面所有的锁,因而避免了死锁。