学习|模式识别|最小错误率贝叶斯分类和matlab实现
1、贝叶斯公式
首先要知道贝叶斯公式:
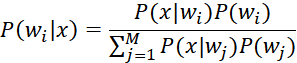
其中,![]() 是先验概率,
是先验概率,![]() 是条件概率,我们要求的
是条件概率,我们要求的![]() 是后验概率。
是后验概率。
由于分母项在不管求样本的哪个后验概率时都是一样的,实际上我们需要关注的只是分子,因此有
![]()
2、基于最小错误率的贝叶斯分类理论
接下来阐释基于最小错误率的思想,以及贝叶斯公式在其中如何发挥作用。
假设现在有两类模式,w1和w2

就是当x属于w1时却分到了w2的概率,当x属于w2时却分到了w1的概率,这两种概率构成了错误概率
画个样本空间X的后验概率图:
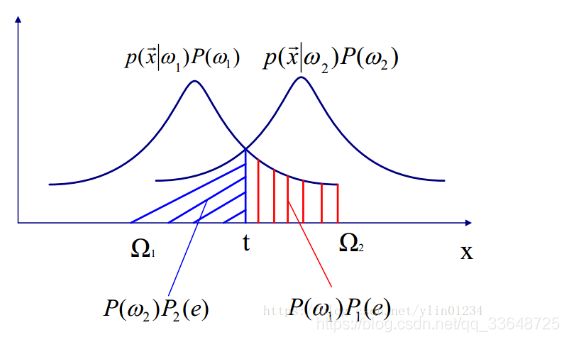
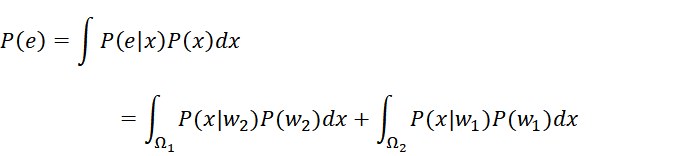
在模式分类时,我们的目标是尽量减少分类的错误,即追求最小的错误率,用式子表达就是:
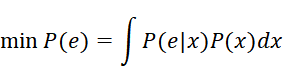
这个式子的意思就是对所有的样本x,我们要最小化他们的P(e|x)。
这样看其实还不知道怎么算,但如果使用贝叶斯公式来表达的话就很清楚了。
可以看出最小化错误率就是最大化后验概率,因此在决策的时候我们只需要比较后验概率P(w|x)的大小,
如果![]() 则判别为w1,反之则判别为w2。这样我们就能最小化错误率了。
则判别为w1,反之则判别为w2。这样我们就能最小化错误率了。
而后验概率可以用贝叶斯公式计算,因此使用贝叶斯公式对样本进行分类的分类器为最小错误率贝叶斯分类器,它的判别函数为:
![]()
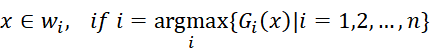
上面即为最小错误率贝叶斯分类器。
要计算判别函数值(后验概率),就要先知道先验概率和条件概率。
1)先验概率![]() 可以通过计算各类样本在总样本数占的比例来得到,如w1类样本数为5,总样本数为11,那么P(w1)=5/11
可以通过计算各类样本在总样本数占的比例来得到,如w1类样本数为5,总样本数为11,那么P(w1)=5/11
2)条件概率![]() 使用高斯分布计算:
使用高斯分布计算:
若样本x为d维向量,第i类wi样本的条件概率密度函数服从均值为mi,协方差为Si的多元高斯分布,条件概率函数为:
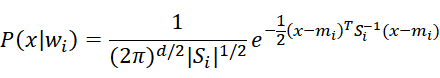
3)取对数,最终的判别函数为:
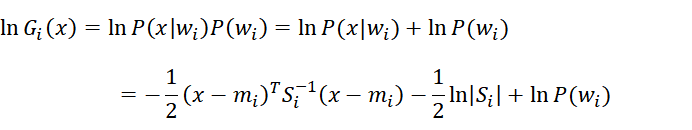
(推导的时候有一项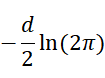 为常数项可以省略)
为常数项可以省略)
推到这里已经知道我们要做什么了,就是算样本的平均值,协方差,以及先验概率
4)算出样本x的每类Gi(x)值后,取最大的Gi(x)值对应的i,即样本x属于wi类
3、matlab实现
这里使用了教材《模式识别与人工智能(基于matlab)》的一段代码
clear;
clc;
%% 加载样本dataset,包含训练数据和测试数据,数据shape为[样本数,特征维数] %%
load('dataset.mat');
train_data = [A_train;B_train;C_train;D_train];
test_data = [A_test;B_test;C_test;D_test];
N1_train = size(A_train, 1); N2_train = size(B_train, 1); N3_train = size(C_train, 1); N4_train = size(D_train, 1); % 各个类别的训练样本数
N_train = N1_train + N2_train + N3_train + N4_train; % 训练样本总数
N1_test = size(A_test, 1); N2_test = size(B_test, 1); N3_test = size(C_test, 1); N4_test = size(D_test, 1); % 各个类别的测试样本的数量
N_test = N1_test + N2_test + N3_test + N4_test; % 测试样本总数
w = 4; % 类别数
n = 3; % 特征数
%% 初始样本数据计算 %%
% 求样本均值
X1 = mean(A_train)'; X2 = mean(B_train)'; X3 = mean(C_train)'; X4 = mean(D_train)';
% 求样本协方差矩阵
S1 = cov(A_train); S2 = cov(B_train); S3 = cov(C_train); S4 = cov(D_train);
% 求协方差矩阵的逆矩阵
S1_ = inv(S1); S2_ = inv(S2); S3_ = inv(S3); S4_ = inv(S4);
% 求协方差矩阵的行列式
S11 = det(S1); S22 = det(S2); S33 = det(S3); S44 = det(S4);
% 先验概率
Pw1 = N1_train/N_train; Pw2 = N2_train/N_train; Pw3 = N3_train/N_train; Pw4 = N4_train/N_train;
%% 计算测试样本的后验概率 %%
for k = 1 : N_test
P1 = -1/2*(test_data(k,:)'-X1)'*S1_*(test_data(k,:)'-X1)-1/2*log(S11)+log(Pw1);
P2 = -1/2*(test_data(k,:)'-X2)'*S2_*(test_data(k,:)'-X2)-1/2*log(S22)+log(Pw2);
P3 = -1/2*(test_data(k,:)'-X3)'*S3_*(test_data(k,:)'-X3)-1/2*log(S33)+log(Pw3);
P4 = -1/2*(test_data(k,:)'-X4)'*S4_*(test_data(k,:)'-X4)-1/2*log(S44)+log(Pw4);
P = [P1 P2 P3 P4];
Pmax = max(P); % 取后验概率最大的那一类
if Pmax == P1
w = 1;
plot3(test_data(k,1), test_data(k,2), test_data(k,3),'ro');
grid on;hold on;
elseif Pmax == P2
w = 2;
plot3(test_data(k,1), test_data(k,2), test_data(k,3),'b>');
grid on;hold on;
elseif Pmax == P3
w = 3;
plot3(test_data(k,1), test_data(k,2), test_data(k,3),'g+');
grid on;hold on;
elseif Pmax == P4
w = 4;
plot3(test_data(k,1), test_data(k,2), test_data(k,3),'y*');
grid on;hold on;
else
return
end
end
运行结果:
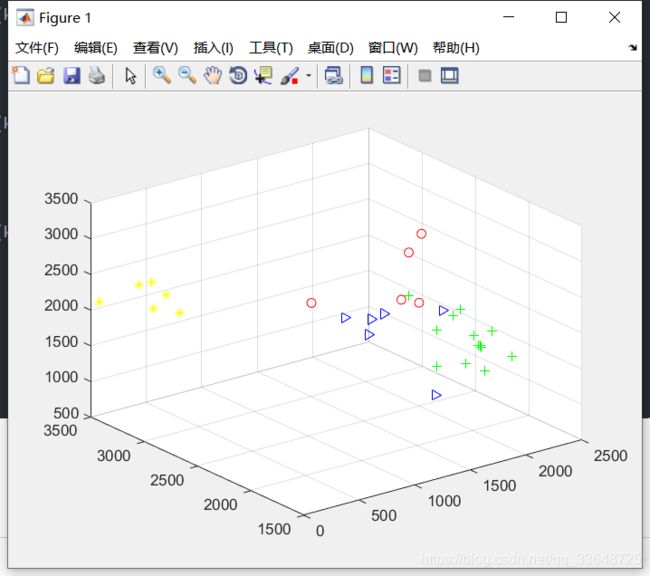
分类的结果还是比较好的