树上莫队算法
江湖传闻,莫队算法能够解决一切区间查询问题。这样说来,莫队算法也能够解决一切树上路径查询问题,将树上操作转化为DFS序列上的区间操作即可。当然考虑到,树上路径在DFS序列中的性质,还要会求 LCA 。
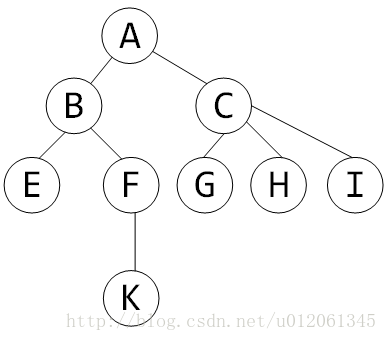
考虑上图中的树,其DFS序为
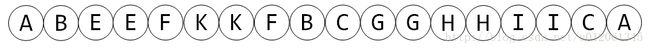
其任意点对 a 、 b 之间的路径,具有如下性质,令 lca 为 a 、 b 的最近公共祖先:
- 若 lca 是 a 、 b 之一,则 a 、 b 之间的 In 时刻的区间或者 Out 时刻区间就是其路径。例如 AK 之间的路径就对应区间 ABEEFK ,或者 KFBCGGHHIICA 。
- 若 lca 另有其人,则 a 、 b 之间的路径为 In[a] 、 Out[b] 之间的区间或者 In[b] 、 Out[a] 之间的区间。另外,还需额外加上 lca !!!考虑 EK 路径,对应为 EFK 再加上 B 。考虑 EH 之间的路径,对应为 EFKKFBCGGH 再加上 A 。
这样就能将路径查询转化为对应的区间查询。另外需要注意到,在DFS序上应用莫队算法移动指针时,如果是欲添加的节点在当前区间内已经有一个了,这实际上应该是一个删除操作;如果欲删除的节点在当前区间内已经有两个了,这实际上应该是一个添加操作。
SPOJ COT2(编号为10707)要求查询路径之间不同权值的个数,是一个典型的树上莫队题目。
首先求出DFS序,然后弄个数据结构和Tarjan算法把所有询问的 LCA 求出,再根据 LCA 的结果将原始询问转化为区间问题,最后使用莫队算法。
#include fprintf(fp,"(%d %d): %d\n",keys[i].a,keys[i].b,values[i]);
}
}
}Lca;
struct edge_t{
int to;
int next;
}Edge[SIZE<<1];
int ECnt = 1;
int Vertex[SIZE] = {0};
inline void mkEdge(int a,int b){
Edge[ECnt].to = b;
Edge[ECnt].next = Vertex[a];
Vertex[a] = ECnt++;
Edge[ECnt].to = a;
Edge[ECnt].next = Vertex[b];
Vertex[b] = ECnt++;
}
//生成DFS序
int InIdx[SIZE],OutIdx[SIZE];
int NewIdx[SIZE<<1];
int NCnt = 1;
void dfs(int node,int parent){
NewIdx[NCnt] = node;
InIdx[node] = NCnt++;
for(int next=Vertex[node];next;next=Edge[next].next){
int to = Edge[next].to;
if ( to != parent ) dfs(to,node);
}
NewIdx[NCnt] = node;
OutIdx[node] = NCnt++;
}
//Tarjan算法中用到的并查集
int Father[SIZE];
int find(int x){return x==Father[x]?x:Father[x]=find(Father[x]);}
bool Flag[SIZE] = {false};
vector<vector<int> > Questions(SIZE,vector<int>());
//Tarjan算法一次性求出所有的LCA
void Tarjan(int u,int parent){
Father[u] = u;
Flag[u] = true;
for(int next=Vertex[u];next;next=Edge[next].next){
int to = Edge[next].to;
if ( to == parent ) continue;
Tarjan(to,u);
Father[to] = u;
}
vector<int>&vec=Questions[u];
for(vector<int>::iterator it=vec.begin();it!=vec.end();++it){
int v = *it;
if ( Flag[v] ){
int r = find(v);
Lca.insert(Hash::key_t(u,v),r);
Lca.insert(Hash::key_t(v,u),r);
}
}
}
struct _t{
int s,e;
int idx;
int lca;
};
bool operator < (_t const&lhs,_t const&rhs){
int ln = lhs.s / BLOCK_SIZE;
int rn = rhs.s / BLOCK_SIZE;
return ln < rn || ( ln == rn && lhs.e < rhs.e );
}
int N,M;
int A[SIZE];
_t B[100000];
//将原树上的路径问题转化为DFS序中的区间问题
inline void mkQuestion(int a,int b,int idx){
int lca = Lca.find(Hash::key_t(a,b));
if ( lca == a || lca == b ){
int t = lca == a ? b : a;
B[idx].s = OutIdx[t];
B[idx].e = OutIdx[lca];
B[idx].lca = 0;
}else{
B[idx].lca = lca;
if ( OutIdx[a] < InIdx[b] ) B[idx].s = OutIdx[a], B[idx].e = InIdx[b];
else B[idx].s = OutIdx[b], B[idx].e = InIdx[a];
}
}
int MoAns;
int Ans[100000],Cnt[SIZE];
inline void insert(int n){
if ( 1 == ++Cnt[n] ) ++MoAns;
}
inline void remove(int n){
if ( 0 == --Cnt[n] ) --MoAns;
}
void MoOp(int idx){
int k = NewIdx[idx];
if ( Flag[k] ) remove(A[k]);
else insert(A[k]);
Flag[k] ^= 1;
}
void Mo(){
sort(B,B+M);
fill(Flag,Flag+N+1,false);
int curLeft = 1;
int curRight = 0;
MoAns = 0;
for(int i=0;iwhile( curRight < B[i].e ) MoOp(++curRight);
while( curLeft > B[i].s ) MoOp(--curLeft);
while( curRight > B[i].e ) MoOp(curRight--);
while( curLeft < B[i].s ) MoOp(curLeft++);
if ( B[i].lca ){
Ans[B[i].idx] = MoAns + ( 0 == Cnt[A[B[i].lca]] ? 1 : 0 );
}else{
Ans[B[i].idx] = MoAns;
}
}
}
void init(int n){
ECnt = NCnt = 1;
fill(Vertex,Vertex+n+1,0);
fill(Flag,Flag+n+1,false);
}
int getUnsigned(){
char ch = getchar();
while( ch > '9' || ch < '0' ) ch = getchar();
int ret = 0;
do ret = ret * 10 + (int)(ch-'0');while( '0' <= (ch=getchar()) && ch <= '9' );
return ret;
}
int W[SIZE];
bool read(){
if ( EOF == scanf("%d",&N) ) return false;
M = getUnsigned();
init(N);
//权值输入并离散化
for(int i=1;i<=N;++i) W[i] = A[i] = getUnsigned();
sort(W+1,W+N+1);
int* pn = unique(W+1,W+N+1);
for(int i=1;i<=N;++i) A[i] = lower_bound(W+1,pn,A[i]) - W;
int a,b;
for(int i=1;i1,0);
for(int i=0;i1,0);
for(int i=0;ireturn true;
}
int main(){
//freopen("1.txt","r",stdin);
while ( read() ){
Mo();
for(int i=0;iprintf("%d\n",Ans[i]);
}
return 0;
}