pandas架构学习
df=pd.dataFrame(data=‘数据的内容’,columns=[‘行标题1’,‘行标题2’],index=i)
list(zip(‘复合数据1’,‘复合数据2’))
df.value():值
df.ix[行范围, 列范围]
df.loc[起始索引(包含):终止索引(包含)]
df.iloc[起始索引(包含):终止索引(不包含)]
选择 top-N 个记录 (默认是 5 个)
df.head()
选择 N-bottom 个记录 (默认是 5 个)
df.tail()
把列(column)放置到索引位置
df.stack()
在索引包含了原来的列名字
df.stack().index
拆解列字符索引
df.unstack()

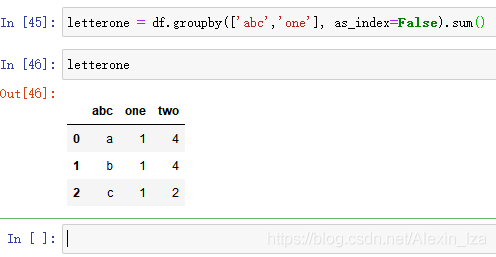
创建一个 groupby 对象
df.grouby(‘abc’)

设置默认行序号:as_index=False
删除索引e
df.drop(‘e’)
数学运算:
加法:add()
减法:sub()
乘法:mul()
除法:div()
中位数:median()
求和:sum()
最大值:max()
最小值:min()

df2.sort_values(by=‘age’) # 按 age 升序排列
直接修改值的大小:
df3.iat[1, 1] = 2
以时间为序号
pd.date_range(start=‘2018-01-01’, end=‘2018-12-31’, freq=‘D’)
转换时区
tz_localize(‘UTC’)
letters = ['A', 'B', 'C']
numbers = list(range(20))
mi = pd.MultiIndex.from_product([letters, numbers]) # 设置多重索引
s = pd.Series(np.random.rand(60), index=mi) # 随机数
多重索引切片:
s.loc[pd.IndexSlice[:‘B’, 5:]]
更改列名称:
frame.index.names = [‘first’, ‘second’]
将priority列的yes改为Ture,no改为False
df[‘priority’].map({‘yes’: True, ‘no’: False})
透视表创建:
df = pd.DataFrame({
'A': ['one', 'one', 'two', 'three'] * 3,
'B': ['A', 'B', 'C'] * 4,
'C': ['foo', 'foo', 'foo', 'bar', 'bar', 'bar'] * 2,
'D': np.random.randn(12),
'E': np.random.randn(12)})
print(df)
pd.pivot_table(df, index=['A', 'B'])
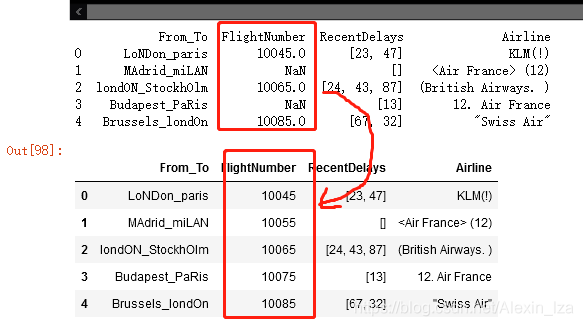
缺省值拟合:
df = pd.DataFrame({
'From_To': ['LoNDon_paris', 'MAdrid_miLAN', 'londON_StockhOlm',
'Budapest_PaRis', 'Brussels_londOn'],
'FlightNumber': [10045, np.nan, 10065, np.nan, 10085],
'RecentDelays': [[23, 47], [], [24, 43, 87], [13], [67, 32]],
'Airline': ['KLM(!)', ' (12)' , '(British Airways. )',
'12. Air France', '"Swiss Air"']})
print(df)
df['FlightNumber'] = df['FlightNumber'].interpolate().astype(int)
#df['RecentDelays'] = df['RecentDelays'].interpolate().astype(int,int)
df
数据拆分:以_为拆分依据
temp = df.From_To.str.split('_', expand=True)
temp.columns = ['From', 'To']
temp
利用正则去除多余字符
df['Airline'] = df['Airline'].str.extract(
'([a-zA-Z\s]+)', expand=False).str.strip()
df
相同数据清除
df = pd.DataFrame({
'A': [1, 2, 2, 3, 4, 5, 5, 5, 6, 7, 7]})
df.loc[df['A'].shift() != df['A']]
数据归一化处理:DataFrame 中不同列之间的数据差距太大,需要对其进行归一化处理。
公式: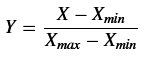
def normalization(df):
numerator = df.sub(df.min())
denominator = (df.max()).sub(df.min())
Y = numerator.div(denominator)
return Y
df = pd.DataFrame(np.random.random(size=(5, 3)))
print(df)
normalization(df)
Cumsum :计算轴向元素累加和,返回由中间结果组成的数组
对于多维数组
axis=0说明,第1维度,包含2行,第1行(也就是由1,2,3,4,5,6组成的list)不动,累加到第二行,注意是累加
axis=1说明,第2维度, 每个绿色中括号里第1行不变,也就是 [1,2,3]和[7,8,9]不动,累加到同兄弟行(同属一个中括号的行)
axis=2说明,第3维度,也是最内层,转化成列处理,紫色数字所在列不动,累加到其他列上
对于更高维度,可以参考3维来从外向内剥离的方式理解

