TF-IDF算法提取文章的关键词
初学中文文本分词,从最简单的TF-IDF算法入手,理解其中的逻辑结构,其中使用jieba分词包作为分词模型。这里部分内容参考了_hahaha的博客。
TF-IDF原理
jieba分词提取关键词是按照词频(即每个词在文章中出现的次数)来提取的,比如要提取文章的前五个关键词,那么就是提取文章中出现次数最多的前五个词。而TF-IDF算法不仅统计每个词的词频,还为每个词加上权重。
举个例子
我们在大学选修了数学和体育两门课,数学为9学分,体育为1学分,期末的时候考试成绩分别为60和100分,那么如果我们说平均分是80分合理吗?其实是不合理的,因为一个9学分,一个1学分,我们投入的时间和精力是不一样的,所以应该用(9/10*60)+(1/10*100)=64分这样更为合理一些,这里80分是平均值,64分是数学期望,所以我们也说数学期望是加权的平均值。
TF-IDF计算公式
TF = 该词在文档中出现的次数
IDF = log2(文档总数/包含该词的文档数量 + 1)
TF-IDF = TF * IDF- 开发环境
系统: Win10; 开发软件: PyChram CE; 运行环境: Python3.6
- 导入所需用的包
import os
import codecs
import pandas
import re
import jieba
import numpy- 创建语料库
# 创建语料库
filePaths = []
fileContents = []
for root, dirs, files in os.walk(
'data/SogouC.mini/Sample'
):
for name in files:
filePath = os.path.join(root, name)
f = codecs.open(filePath, 'r', 'utf-8')
fileContent = f.read()
f.close()
filePaths.append(filePath)
fileContents.append(fileContent)
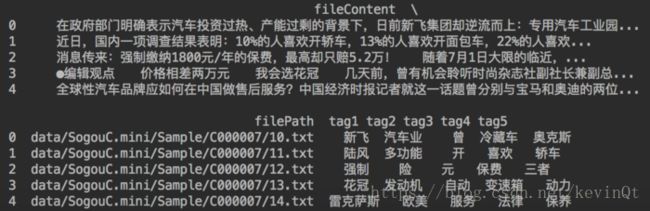
corpus = pandas.DataFrame({
'filePath': filePaths,
'fileContent': fileContents
})
运行结果:
- 分词
# 匹配中文分词
zhPattern = re.compile(u'[\u4e00-\u9fa5]+')
# 分词
segments = []
filePaths = []
for index, row in corpus.iterrows(): # 对语料库按行进行遍历
filePath = row['filePath']
fileContent = row['fileContent']
segs = jieba.cut(fileContent)
for seg in segs:
if zhPattern.search(seg): # 匹配中文分词
segments.append(seg)
filePaths.append(filePath)
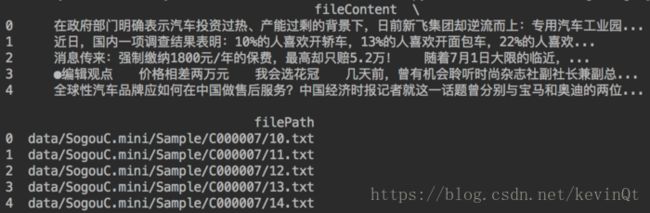
segmentDF = pandas.DataFrame({
'segment': segments,
'filePath': filePaths
})运行结果:
- 停用词过滤
# 停用词过滤
stopWords = pandas.read_csv( # 读取停用词表
'data/StopwordsCN.txt',
encoding='utf-8',
index_col=False,
quoting=3,
sep='\t'
)
segmentDF = segmentDF[~segmentDF['segment'].isin(stopWords['stopword'])]
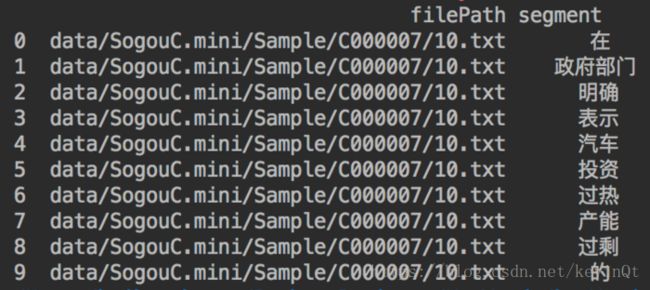
- 按文章进行词频统计
# 按文章进行词频统计
segStat = segmentDF.groupby(
by=['filePath', 'segment']
)['segment'].agg({
'计数': len
}).reset_index().sort_values( # reset_index()
'计数',
ascending=False # 倒序排列
)
# 把词频为小于1的词删掉
segStat = segStat[segStat['计数'] > 1]运行结果:
- 文档向量化
文档向量化:
假设有m篇文章d1、d2、d3、......、dm,对它们分别进行分词,得到n个分词向量w1、w2、w3、......、wn,那么就得到这m篇文档的分词向量矩阵F。其中fij代表第i篇文章中分词j出现的频率。

那么单篇文档的向量化,即第i篇文章,使用矩阵F的第i行数据进行表,即 Di ={ fi1, fi2, ..., fin }。
# 文档向量化
TF = segStat.pivot_table(
index='filePath', # 数据透视表的列
columns='segment', # 数据透视表的行
values='计数', # 数据透视表中的值
fill_value=0, # NA值统一替换为0
)运行结果:

- 计算TF-IDF
#计算TF-IDF
def handler(x):
return numpy.log2(len(corpus) / (numpy.sum(x > 0) + 1))
IDF = TF.apply(handler)
TF_IDF = pandas.DataFrame(TF * IDF)运行结果:
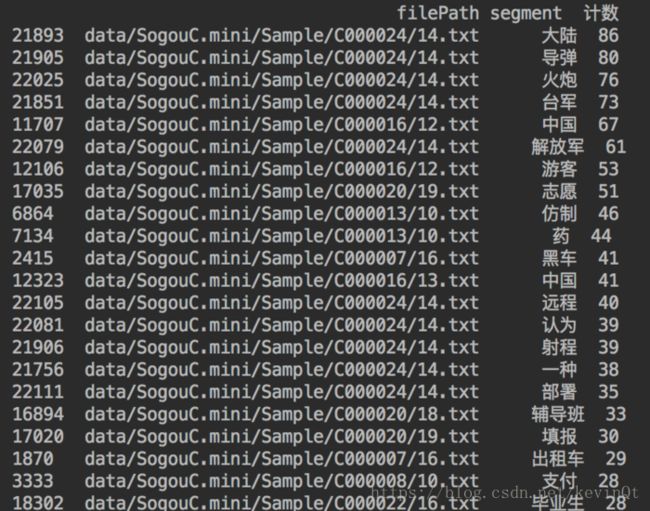
- 提取每篇文档的前五个关键词
#提取每篇文档的前五个关键词
tag1s = []
tag2s = []
tag3s = []
tag4s = []
tag5s = []
for filePath in TF_IDF.index:
tags = TF_IDF.loc[filePath].sort_values( # 用loc(索引名)遍历行,每行为一个Series
ascending=False # 对每行进行倒序排列
)[:5].index # 取每行前五个的索引值(即前五个分词名称)
tag1s.append(tags[0])
tag2s.append(tags[1])
tag3s.append(tags[2])
tag4s.append(tags[3])
tag5s.append(tags[4])
tagDF = pandas.DataFrame({
'filePath': corpus['filePath'],
'fileContent': corpus['fileContent'],
'tag1': tag1s,
'tag2': tag2s,
'tag3': tag3s,
'tag4': tag4s,
'tag5': tag5s
})运行结果: