【知识积累】常见数据库问题
1、用两种方式根据部门号从高到低,工资从低到高列出每个员工的信息。
employee:
eid,ename,salary,deptid
select * from employee order by deptid desc,salary;默认是从低到高的排序,这个题目主要考的是order by的使用。
2、查询出每门课都大于80分的学生姓名
create table score(id int primary key auto_increment,name varchar(20),subject varchar(20),score int);
insert into score values
(null,'张三','语文',81),
(null,'张三','数学',75),
(null,'李四','语文',76),
(null,'李四','数学',90),
(null,'王五','语文',81),
(null,'王五','数学',100),
(null,'王五 ','英语',90);
select distinct name from score where name not in (select distinct name from score where score<=80);去找分数不满80的名字,然后将这些名字干掉,剩下的名字就是所有学科分数大于80的人
3、数据库,比如100用户同时来访,要采用什么技术解决?
答:可用连接池。C3P0连接池是Hibernate推荐使用的连接池。
4、说出数据库连接池的工作机制是什么?
答:Java EE服务器启动时会建立一定数量的池连接,并一直维持不少于该数量的池连接。客户端程序需要连接时,池驱动程序会返回一个未使用的池连接并将其标记为忙。
如果当前没有空闲连接,池驱动程序会新建一定数量的连接,新建连接的数量由配置参数决定。当使用的池连接调用完成后,池驱动程序将此连接标记为空闲,其他调用
就可以使用这个连接了。
5、Java中访问数据库的步骤?statement和preparedstatement的区别?
答:步骤:
- a、注册驱动
- b、建立连接
- c、创建statement
- d、执行sql语句
- e、处理结果集(如果结果集为查询语句)
- f、关闭连接
- a、 PreparedStatement可以写参数化查询,比Statement能获得更好的性能。
- b、对于PreparedStatement来说,数据库可以使用已经编译过及定义好的执行计划,这种预处理语句查询比普通的查询运行速度更快。
- c、PreparedStatement可以阻止常见的SQL注入式攻击。
- d、 PreparedStatement可以写动态查询语句
- e、PreparedStatement与java.sql.Connection对象是关联的,一旦你关闭了connection,PreparedStatement也没法使用了。
- f、“?” 叫做占位符。
- g、PreparedStatement查询默认返回FORWARD_ONLY的ResultSet,你只能往一个方向移动结果集的游标。当然你还可以设定为其他类型的值如:”CONCUR_READ_ONLY”。
- h、 不支持预编译SQL查询的JDBC驱动,在调用connection.prepareStatement(sql)的时候,它不会把SQL查询语句发送给数据库做预处理,而是等到执行查询动作的时候(调用executeQuery()方法时)才把查询语句发送个数据库,这种情况和使用Statement是一样的。
- i、占位符的索引位置从1开始而不是0,如果填入0会导致*java.sql.SQLException invalid column index*异常。所以如果PreparedStatement有两个占位符,那么第一个参数的索引时1,第二个参数的索引是2.
//Statement的用法
String sql="";
Statement s=conn.createStatement();
ResultSet r=s.ExecuteQuery(sql);
//PreparedStatement的用法
String sql="";
PreparedStatement p=conn.PrepareStatement(sql);
ResultSet r=p.ExecuteQuery();6、HQL和SQL的区别
答:HQL:面向对象的,是官方推荐的标准查询方式。from后面跟的是 类名+类对象,where 后用对象的属性作为条件。
SQL:结构化查询语句,面向数据库检索,不具备面向对象的特征。from后面跟的是表名,where后用表中的字段作为条件。
7、列约束和表约束:
列约束:
- a、Unique key:该列或者列的集合中所有值都是唯一的。
- b、check:限制输入值的范围
- c、not null:确保列中不出现null值。
表约束:
- a、primary key:主键是唯一识别表中的每一条记录,表中只能存在一个primary关键字。
- b、foreign key:保证系统参照完整性的手段
8、数据库对象管理:
视图(view):是从一个或多个表或视图中导出来的表,其结构和数据是建立在对表的查询基础上的。
优点:
- a、视图集中:使用户只关心他感兴趣的某些特定数据和他们所负责的特定任务。
- b、简化操作:视图本身就是一个复杂查询的结果集,每次执行相同的查询时,不必重写负责查询的语句,只需在视图中用简单的查询语句就可以了。
- c、安全性:通过视图用户只能查看或修改他们所看到的数据,其他表既不可见也不可访问。
索引(index):为了提高检索的能力
序列(sequence):常用关键字或给数据行排序
同义词:指为表、视图和序列等对象起的另一个名字。
9、游标:
对从表中检索出的数据进行灵活的操作,就其本质而言,游标是一种能从包括多条数据记录的结果集中每次提取一次记录的机制。
10、JDBC如何做事务处理?
Con.setAutoCommit(false)
Con.commit()
Con.rollback()
11、Class.forName的作用?为什么要用?
答:按参数中指定的字符串形式的类名去搜索并加载相应的类,如果该类字节码已经被加载过,则返回代表该字节码的Class实例对象,否则,按类加载器的委托机制去搜索和加载该类,如果所有的类加载器都无法加载到该类,则抛出ClassNotFoundException。加载完这个Class字节码后,接着就可以使用Class字节码的newInstance方法去创建该类的实例对象了。
有时候,我们程序中所有使用的具体类名在设计时(即开发时)无法确定,只有程序运行时才能确定,这时候就需要使用Class.forName去动态加载该类,这个类名通常是在配置文件中配置的,例如,spring的ioc中每次依赖注入的具体类就是这样配置的,jdbc的驱动类名通常也是通过配置文件来配置的,以便在产品交付使用后不用修改源程序就可以更换驱动类名。
12、JDO是什么?
答:JDO是java data object的简称,是java对象持久化的新的规范,也是一个用于存取某种数据库仓库中的对象的标准化API。
JDO提供了透明的对象存储,因此对开发人员来说,存储数据对象完全不需要额外的代码(JDBC API的使用)。
这些繁琐的例行工作已经转移到JDO产品提供商身上,使开发人员解脱出来,从而集中时间和精力在业务逻辑上。
另外,JDO很灵活,因为他可以在任何数据底层上运行。JDBC只是面向数据关系库(RDBMS)JDO更通用,提供到任何数据
底层的存储功能,比如关系数据库、文件、XML以及对象数据库(ODBMS)等等,使得应用可移植性更强。
13、数据库的三范式是什么?
第一范式(1NF):字段具有原子性,不可再分。所有关系型数据库系统都满足第一范式。
数据库表中的字段都是单一属性的,不可再分。例如,姓名字段,其中的名和姓必须作为一个整体,无法区分哪部分是名,哪部分是姓,
如果要区分名和姓,必须设计成两个独立的字段。
第二范式(2NF):第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。
要求数据库表中的每个实例或行必须可以被唯一的区分。通常需要为表加上一个列,以存储各个实例的唯一标识。这个唯一属性列被称为
主关键字或主键。
第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性
和主关键字的这一部分应该分离出来形成一个新的实体,新实体和原实体之间是一对多的关系。为实现区分通常为表加上一个列,以存储各个
实例的唯一标识。简而言之,第二范式就是非主属性非部分依赖于主关键字。
第三范式要求如下:
满足第三范式(3NF)必须先满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个数据库表中不包含已在其他表中包含的非主
关键字信息。所以第三范式具有如下特征:
a、每一列只有一个值
b、每一行都能区分
c、每一个表都不包含其他表已经包含的非主流关键字信息。
例如:帖子表中只能出现发帖人的id,而不能既出现发帖人的id又出现发帖人的姓名,否则只要出现同一个发帖人id的所有记录,他们中
的姓名部分都必须严格保持一致,只就是数据冗余。
14、说出数据库优化方面的经验?
答:Preparedstatement一般来说比statement性能高:一个sql发给服务器去执行,涉及步骤:语法检查、语义分析、编译、缓存。
有外键约束会影响插入和删除性能,如果程序能够保证数据的完整性,那在设计数据库时就去掉外键。(例如:免检产品,就是为了提高
效率,充分相信产品的制造商。)(对于hibernate来说,就应该有一个变化:employee→Department对象,现在设计时就成了
employee deptid)看mysql帮助文档子查询章节的最后部分,例如根据扫描的原理,下面的子查询语句要比第二条关联查询的效率高:
a、select e.name,e.salary where e.managerid=(select id from emloyee where name ="xxx");
b、select e.name,e.salary,m.name,m.salary from employees e,employees m where
e.magaerid=m.id and m.name="xxx";15、union和union all有什么不同?
假设我们有一个表Student,包括以下字段与数据:
drop table student;
create table student(
id int primary key,
name varchar(50) not null,
score number not null
)
insert into student values (1,'A',78);
insert into student values (2,'B',76);
insert into student values (3,'C',89);
insert into student values (4,'D',90);
insert into student values (5,'E',73);
insert into student values (6,'F',61);
insert into student values (7,'G',99);
insert into student values (8,'H',56);
select * from student where id <4 union select * from student where id>2 and id<6;结果:
insert into student values (1,'A',78);
insert into student values (2,'B',76);
insert into student values (3,'C',89);
insert into student values (4,'D',90);
insert into student values (5,'E',73);
select * from student where id <4 union all select * from student where id>2 and id<6;
insert into student values (1,'A',78);
insert into student values (2,'B',76);
insert into student values (3,'C',89);
insert into student values (3,'C',89);
insert into student values (4,'D',90);
insert into student values (5,'E',73); 可以看到,Union和Union All的区别之一在于对重复结果的处理。
Union在进行表链接后会筛选掉重复的记录,所有在表链接后会对所产生的结果集进行排序运算,删除重复的记录再
返回结果。实际大部分应用中是不会产生重复的记录,最常见的是过程表与历史表Union。而Union All只是简单的将
两个结果合并后就返回。这样,如果返回的两个结果集中有重复的数据,那么返回的结果集就会包含重复的数据了。
从效率上说,Union All要比Union快很多,所以,如果可以确认合并的两个结果集中不包含重复的数据的话,那么就
使用Union All。
16、分页语句
取出sql表中第31到40的记录(以自动增长ID为主键)
mysql方案:
select * from student order by id limit 30,10;oracle方案:
select * from (select rownum r,* from student where r<=40) where >30;17、所有部门之间比赛组合
一个叫的department的表,里面只有一个字段name,一共有4条记录,分别是a、b、c、d,对应四个球队,现在4个球队
进行比赛,用一条sql语句显示所有可能的比赛组合。
select a.name,b.name from team a,team b where a.name18、删除出了id号不同,其他都相同的学生冗余信息。
表student:
| id | 学号 | 姓名 | 课程编号 | 课程名称 | 分数 |
| 1 | 2005001 | 张三 | 001 | 数学 | 78 |
| 2 | 2005002 | 李四 | 002 | 数学 | 45 |
| 3 | 2005003 | 王五 | 003 | 数学 | 36 |
delect from student where id not in (select min(id)) from (select * from student) as t student
group by t.name);19、查出比经理薪水还高的员工信息。
create table employees(
id int primary key auto_increment,
name varchar(50),
salary int,
managerid int references employees(id)
)
insert into employees values (null,'ihm',10000,null),
(null,'zxx',15000,1),(null,'flx',9000,1),(null,'tg',10000,2),(null,'wzg',10000,3);答:
select e.* from employees e,employees m where e.managerid=m.id and e.salary>m.salary;这是一个递归表。zxx的经理是ihm,flx的经理是ihm,tg的经理是zxx,wzg的经理是flx。
20、求出小于45岁各个老师所带的大于12岁的学生。
数据库中有三个表:老师表teacher、学生表student、关系表tea_stu。
teacher:teaID、name、age
student:stuID、name、age
tea_stu:teaID、stuID
要求用一条sql语句查询出这样的结果:
a、显示的字段要有老师name、age每个老师所带的学生人数
b、只列出老师age为40以下,学生age为12以上的记录
create table teacher(teaID int primary key,name varchar(50),age int);
create table student(stuID int primary key,name varchar(50),age int);
create table tea_stu(teaID int references teacher(teaID),stuID int references student(stuID));
insert into teacher values(1,'zxx',45), (2,'lhm',25) , (3,'wzg',26) , (4,'tg',27);
insert into student values(1,'wy',11), (2,'dh',25) , (3,'ysq',26) , (4,'mxc',27);
insert into tea_stu values(1,1), (1,2), (1,3);
insert into tea_stu values(2,2), (2,3), (2,4);
insert into tea_stu values(3,3), (3,4), (3,1);
insert into tea_stu values(4,4), (4,1), (4,2) , (4,3);a、根据teaId对关系表进行分组。
select teaid,count(*) total from tea_stu group by teaid;b、进行表连接,得到大于12岁的学生。
select tea_stu.teaid,count(*) total form student,tea_stu where
student.stuid=tea_stu.stuid and student.age > 12 group by tea_stu.teaid;c、将b步骤得到的表与teacher表连接,得到小于45岁的老师。
select teacher.teaid,teacher.name,total from teacher,(select tea_stu.teaid,count(*)
total form student,tea_stu where student.stuid=tea_stu.stuid and student.age > 12
group by tea_stu.teaid) as tea_stu2 where tea_stu.teaid=teacher.teaid and teacher.age < 45;21、一个用户表有一个积分字段,加入数据库中有100多玩个用户,若要在每年第一天凌晨将积分清零,你讲考虑什么,你讲想什么办法解决?
a、alter table tableName drop column columnName;
alter table tableName add column columnName Type;#tableName:表名 columnName:列名 Type:列类型
这两条sql语句无法回滚rollback。
a、update user set columnName = 0;可以回滚,但是执行时间较长。
22、根据下表写sql语句
table employees structure:
employee_id number primary key,
first_name varchar(25),
last_name varchar(25),
salary number(8,2),
hireddate date,
departmentid number(2) #外键
table department structure:
departmentid number(2) primary key,
departmentName varchar(25)a、基于上述employees表写出查询:写出雇佣日期在今年(year(curdate()))的,
工资在[1000,2000]的(between 1000 and 2000),
或者员工姓名以'Obama'开头的所有员工(left(last_name,5)='Obama'),累出这些员工的全部个人信息。
select * from employees where year(hireddate)=year(curdate()) or (salary between 1000
and 2000) or left(last_name,5)='Obama';b、基于上述employees表写出查询:查出部门平均工资大于1800元的部门的所有员工(avg),列出这些员工的全部信息。
select department.departmentid,avg(salary) as sa from employees,department
where employees.departmentid=department.departmentid group by department.departmentid having sa>1800;#得到部门平均工资大于1800元的部门。。。得到的这个表叫vagtable
select employees.* from employees,vagtable where employees.departmentid=vagtable.departmentid;#将vagtable表和employees表连接起来。得到本部门平均工资大于1800的部门的所有员工。
c、基于上述employees表写出查询:查出个人工资高于其所在部门平均工资的员工,列出这些员工的全部个人信息及该员工
工资高于部门平均工资百分比。
select department.departmentid,avg(salary) as sa from employees,department
where employees.departmentid=department.departmentid group by department.departmentid;#得到各部门平均工资。。。得到的这个表叫vagtable
select employees.*,(employees.salary-vagtable.sa)/vagtable.sa from employees,vagtable
where employees.departmentid=vagtable.departmentid and employees.salary>vagtable.sa;#将vagtable表和employees表连接起来。得到个人工资告诉部门平均工资的所有员工(并计算超出的百分比)。
23、JDBC中的Preparedstatement相比Statement的好处。
答:一个sql语句发给服务器去执行的步骤为:语义检查、语义分析、编译成内部指令、缓存指令、执行指令等过程。
select * from student where id =3----缓存--àxxxxx二进制命令
select * from student where id =3----直接取-àxxxxx二进制命令
select * from student where id =4--- -à会怎么干?
如果当初是select * from student where id =?--- -à又会怎么干?
上面说的是性能提高
可以防止sql注入。
24、触发器的作用?
答:触发器是一种特殊的存储过程,主要通过事件触发而被执行。
a、强化约束,维护数据完整性和一致性。
b、可以跟踪对数据库的操作从而不允许未经许可的更新和变化。
25、什么是存储过程?怎么调用?
答:存储过程是一个预编译的sql语句,优点是运行模块化设计,创建一次,可以多次调用,并且如果某次
操作需要执行多次sql,那么使用存储过程比单纯sql语句执行要快。(重用性、效率)
调用:a、命令对象
b、外部程序
26、存储过程的优缺点?
答:
优点:
a、是预编译过的,效率快。
b、重用性好,可以多次调用。
c、安全性高,执行存储过程需要一定的权限。
d、其代码直接存储在数据库中,可以通过存储过程名直接调用,减少网络通讯。
缺点:移植性差。
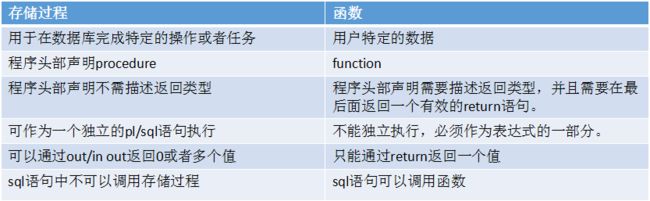
27、存储过程和函数的区别
答:
28、索引的作用?优缺点?
答:索引就是一种特殊的查询数据库的搜索,可以利用它加速对数据的检索。索引可以是唯一的,创建索引允许指定单个列或者多个列。
create index tableName_index on tableName(column1,column2);缺点:a、减慢了数据的录入。
b、增加了数据的大小尺寸。
29、什么样的字段适合建索引?
答:唯一、不能空、经常被查询的字段
30、什么是事务?
答:事务就是被捆绑在一起作为一个逻辑单元的sql语句分组。具有4个特效ICAD(原子性、一致性、隔离性、持久性):
原子性:事务要么被执行,要么不被执行。
一致性:事务执行后,数据处于一致的状态。
隔离性:事务不允许嵌套。
持久性:事务一旦执行完毕就会产生永久的影响,即使系统出错。(可以使用rollback回滚)
31、什么是锁?
答:在DBMS(database management system)中,锁是事务的关键,锁可以保证事务的完整性和并发性。与现实生活中的锁一样,它可以使某些数据的拥有者,在某段时间内不能使用某些数据或数据结构。