mysql学习笔记(6)_存储过程
原本觉得掌握最基本的语法就行了,但发现老师最近又提到了存储过程,我觉得有必要学习整理一下,以下是我的简单笔记
存储过程的含义以及优点
- 含义:一组预先编译号的sql语句的集合,理解成批处理语句
- 优点:
- 1.提高代码的重用性
- 2.简化操作
- 3.减少了编译次数并且减少了和数据库服务器的连接次数,提高了效率
存储过程的创建语法
create procedure 存储过程名(参数列表)
begin
存储过程体(一般合法的SQL语句)
end
参数列表包含三个部分(参数模式,参数名称,参数类型)
参数列表举例:IN stuname varchar(20)
参数模式:
- IN :该参数库作为输入,也就是该参数需要调用方法传入值(但不能返回值)
- OUT:该参数可以作为输出,也就是该参数可以作为返回值(但不能传入值)
- INOUT:该参数既可以作为输入又可以作为输出,也就是该参数既需要传入值,又可以返回值
注意:
如果存储过程只有一句话,BEGIN END可以省略
存储过程体中的每条SQL语句的结尾要求必须加分号
存储过程体的结尾可以使用DELIMITER重新设置
语法:DELIMITER 结束标记
案例:DELIMITER $
存储过程的调用语法
CALL 存储过程名(实参列表);
存储过程的举例
1.空参的存储过程 (也就是没有参数)
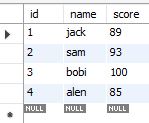
例:向student表中插入4条数据 。
先创建一个student表
create table student(
id int auto_increment,//学号
name varchar(20),//名字
score double,//分数
primary key(id)
);
创建相应的存储过程
delimiter $
create procedure myp1()
begin
insert into student(name,score)
values ('jack',89),('sam',93),('bobi',100),('alen',85);
end $
创建好后我们需要调用这个存储过程就能实现插入操作
call myp1();
然后我们查看student表就可以发现成功插入了4条数据
2.创建带in模式参数的存储过程
例1:通过学生id,查找对应分数(我这里就简单的单表查询进行演示一下)
delimiter $
create procedure myp02(IN id int)
begin
select s.score
from student s
where s.id=id;
end $
调用该存储过程
call myp02(1);
这里传入的id为1,即返回jack的分数

例2.案例1:输入id和学生名,判断该学生是否存在
delimiter $
create procedure myp004(IN id int,IN name varchar(20))
begin
declare result int default 0;#声明变量和默认值
select count(*) into result#赋值
from student s
where s.id = id
and s.name = name;
select if(result>0,'存在学生','不存在学生') '存在与否' ;
end $
调用过程
call myp004(1,'哈哈');
则输出如下:

2.创建带out模式参数的存储过程
准备:先创建一个课程表
create table class(
id int primary key auto_increment,
cname varchar(20)
);
我向其中插入了以下4条数据

例:通过学生id,查找对应课程
delimiter $
create procedure myp5(IN sid int,out cname varchar(20))
begin
select c.cname into cname
from class c
inner join student s on s.id = c.id
where s.id = sid;
end $
调用过程
call myp5(1,@Name);//这里其实就是将更具id查到的课程名赋值给变量@Name
select @Name;//我们再查询这个变量就可以得到这个课程名
查询如下:

2.创建带inout模式参数的存储过程
例:传入a和b两个值,最终a和b都翻倍并返回
delimiter $
create procedure myp6(inout a int, inout b int)
begin
set a=a*2;
set b=b*2;
end
$
调用过程
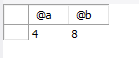
set @a=2;//设置变量@a=2
set @b=4;//设置变量@b=4
call myp6(@a,@b);//将两个变量作为参数传入该存储过程
select @a,@b;//然后我们再查看变量@a和@b的值
查询如下:
删除存储过程
语法:drop procedure 存储过程名;
注:一次只能删除一个
查看存储过程的信息
语法:show create procedure 存储过程名;
例:show create procedure myp1;
示例如下:

此处只是列举了最基础的例子,很多情况可能没有涉及到,希望各位大佬能够提出自己的见解,共同学习,共同进步!