Sqoop详解
通常一个组织中有价值的数据都要存储在关系型数据库系统中。但是为了进一步进行处理,有些数据需要抽取出来,通过MapReduce程序进行再次加工。为了能够和HDFS系统之外的数据库系统机型交互,MapReduce程序需要使用外部API来访问数据。Sqoop就是一个开源的工具,它允许用户将数据从关系型数据库抽取到hadoop中;也可以把MapReduce处理完的数据导回到数据库中。
1、sqoop使用
在学习sqoop使用之前,我们需要查看sqoop都是可以完成什么任务,通过键入:sqoop help,我们就可以看到sqoop可以提供的服务。在项目中,我们主要使用的是sqoop import服务,在使用的过程中,我们还会经历很多定制修改,讲逐一讲解。
1.1将数据从数据库导入到hadoop中
导入指令:sqoop import –connect jdbc:mysql://hostname:port/database –username root –password 123456 –table example –m 1。在这里讲解一下指令的构成,如下:
1、--connect jdbc:mysql://hostname:port/database指定mysql数据库主机名和端口号和数据库名;
2、--username root 指定数据库用户名
3、--password 123456 指定数据库密码
4、--table example mysql中即将导出的表
5、-m 1 指定启动一个map进程,如果表很大,可以启动多个map进程
6、导入到HDFS中的路径 默认:/user/grid/example/part-m-00000
注意:默认情况下,Sqoop会将我们导入的数据保存为逗号分隔的文本文件。如果导入数据的字段内容存在分隔符,则我们可以另外指定分隔符、字段包围字符和转义字符。使用命令行参数可以指定分隔符、文件格式、压缩以及对导入过程进行更细粒度的控制。
1.2、生成代码
除了能够将数据库表的内容写到HDFS,Sqoop还生成了一个Java源文件(example.java)保存在当前的本地目录中。在运行了前面的sqoop import命令之后,可以通过ls example.java命令看到这个文件。代码生成时Sqoop导入过程的必要组成部分,他是在Sqoop将源数据库的表数据写到HDFS之前,首先用生成的代码对其进行反序列化。
生成的类中能够保存一条从被导入表中取出的记录。该类可以在MapReduce中使用这条记录,也可以将这条记录保存在HDFS中的一个SequenceFile文件中。在导入过程中,由Sqoop生成的SequenceFile文件会生成的类,将每一个被导入的行保存在其键值对格式中“值”的位置。
也许你不想将生成的类命名为example,因为每一个类的实例只对应与一条记录。我们可以使用另外一个Sqoop工具来生成源代码,并不执行导入操作,这个生成的代码仍然会检查数据库表,以确定与每个字段相匹配的数据类型:
Sqoop codegen –connect jdbc:mysql://localhost/yidong –table example –class-name example
Codegen工具只是简单的生成代码,他不执行完整的导入操作。我们指定希望生成一个名为example的类,这个类将被写入到example.java文件中。在之前执行的导入过程中,我们还可以指定—class-name和其他代码生成参数。如果你意外的删除了生成的源代码,或希望使用不同于导入过程的设定来生成代码,都可以用这个工具来重新生成代码。
如果计划使用导入到SequenceFile文件中的记录,你将不可避免的用到生成的类(对SequenceFile文件中的数据进行反序列化)。在使用文本文件中的记录时,不需要用生成的代码。
1.3、深入了解数据库导入
在深入理解之前,我们需要先想一个问题:Sqoop是通过一个MapReduce作业从数据库中导入一个表,这个作业从表中抽取一行行记录,然后写入到HDFS。MapReduce是如何记录的?
下图是Sqoop从数据库中导入到HDFS的原理图:
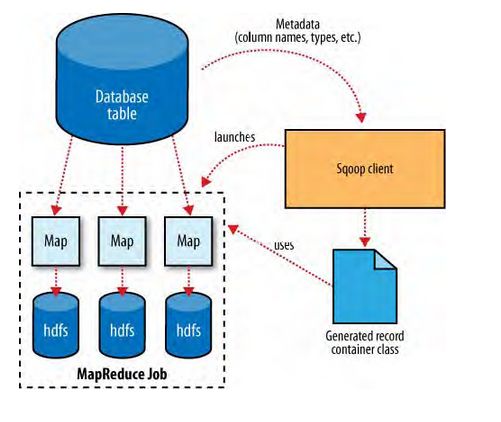
在导入开始之前,Sqoop使用JDBC来检查将要导入的表。他检索出表中所有的列以及列的SQL数据类型。这些SQL类型(VARCHAR、INTEGER)被映射到Java数据类型(String、Integer等),在MapReduce应用中将使用这些对应的java类型来保存字段的值。Sqoop的代码生成器使用这些信息来创建对应表的类,用于保存从表中抽取的记录。例如前面提到过的example类。
对于导入来说,更关键的是DBWritable接口的序列化方法,这些方法能使Widget类和JDBC进行交互:
Public void readFields(resultSet _dbResults)throws SQLException;
Public void write(PreparedStatement _dbstmt)throws SQLException;
JDBC的ResultSet接口提供了一个用户从检查结果中检索记录的游标;这里的readFields()方法将用ResultSet中一行数据的列来填充Example对象的字段。
Sqoop启动的MapReduce作业用到一个InputFormat,他可以通过JDBC从一个数据库表中读取部分内容。Hadoop提供的DataDriverDBInputFormat能够为几个Map任务对查询结果进行划分。为了获取更好的导入性能,查询会根据一个“划分列”来进行划分的。Sqoop会选择一个合适的列作为划分列(通常是表的主键)。
在生成反序列化代码和配置InputFormat之后,Sqoop将作业发送到MapReduce集群。Map任务将执行查询并将ResultSet中的数据反序列化到生成类的实例,这些数据要么直接保存在SequenceFile文件中,要么在写到HDFS之前被转换成分割的文本。
Sqoop不需要每次都导入整张表,用户也可以在查询中加入到where子句,以此来限定需要导入的记录:Sqoop –query
导入和一致性:在向HDFS导入数据时,重要的是要确保访问的是数据源的一致性快照。从一个数据库中并行读取数据的MAP任务分别运行在不同的进程中。因此,他们不能共享一个数据库任务。保证一致性的最好方法就是在导入时不允许运行任何进行对表中现有数据进行更新。
1.4、使用导入的数据
一旦数据导入HDFS,就可以供定制的MapReduce程序使用。导入的文本格式数据可以供Hadoop Streaming中的脚本或者TextInputFormat为默认格式运行的MapReduce作业使用。
为了使用导入记录的个别字段,必须对字段分割符进行解析,抽取出的字段值并转换为相应的数据类型。Sqoop生成的表类能自动完成这个过程,使你可以将精力集中在真正的要运行的MapReduce作业上。
1.5、导入的数据与hive
Hive和sqoop共同构成一个强大的服务于分析任务的工具链。Sqoop能够根据一个关系数据源中的表来生成一个hive表。既然我们已经将表的数据导入到HDFS中,那么就可以直接生成相应hive表的定义,然后加载保存在HDFS中的数据,例如:
Sqoop create-hive-table –connect jdbc:mysql://localhoust/yidong –table example –fields-terminated-by “,”
Load data inpath ‘example’ into table example
注:在为一个特定的已导入数据集创建相应的hive表定义时,我们需要指定该数据集所使用的分隔符。否则,sqoop将允许hive使用自己默认的风格符。
如果想直接从数据库将数据导入到hive,可以将上述三个步骤(将数据导入HDFS,创建hive表,将hdfs中的数据导入hive)缩短为一个步骤。在进行导入时,sqoop可以生成hive表的定义,然后直接将数据导入hive表:
Sqoop import –connect jdbc:mysql://localhost/hadoopguide –table widgets –m 1 –hive-import
1.6、导入大对象
很多数据库都具有在一个字段中保存大量数据的能力。取决于数据是文本还是二进制类型,通常这些类型为CLOB或BLOB。数据库一般会对这些“大对象”进行特殊处理。Sqoop将导入的大对象数据存储在LobFile格式的单独文件中,lobfile格式能够存储非常大的单条记录。Lobfile文件中的每条记录保存一个大对象。
在导入一条记录时,所有的“正常”字段会在一个文本文件中一起物化,同时还生成一个指向保存CLOB或BLOB列的lobfile文件的引用。
2、执行导出
在sqoop中,导出是将hdfs作为一个数据源,而将一个远程的数据库作为目标。将一张表从hdfs导出到数据库时,我们必须在数据库中创建一张用于接收数据的目标表。虽然sqoop可以推断出那个java类型适合存储sql数据类型,但反过来确实行不通。因此,必须由用户来确定哪些类型是最合适的。
例如:我们打算从hive中导出zip_profits表到mysql数据库中。
①先在mysql中创建一个具有相同序列顺序及合适sql表型的目标表:
Create table sales_by_sip(volume decimal(8,2),zip integer);
②接着运行导出命令:
Sqoop export –connect jdbc:mysql://localhost/hadoopguide –m 1 –table sales_by_zip –export-dir /user/hive/warehouse/zip_profits –input-fields-terminated-by “\0001”
③过mysql来确认导出成功:
mysql hadoopguide –e ‘select * from sales_by_zip’
注意:在hive中创建zip_profits表时,我们没有指定任何分隔符。因此hive使用了自己的默认分隔符;但是直接从文件中读取这张表时,我们需要将所使用的分隔符告知sqoop。Sqoop默认记录是以换行符作为分隔符。因此,可在sqoop export命令中使用—input-fields-terminated-by参数来指定字段分隔符。
2.1、深入了解导出
Sqoop导出功能的架构与其导入功能非常相似,在执行导出操作之前,sqoop会根据数据库连接字符串来选择一个导出方法。一般为jdbc。然后,sqoop会根据目标表的定义生成一个java类。这个生成的类能够从文本文件中解析记录,并能够向表中插入类型合适的值。接着会启动一个MapReduce作业,从HDFS中读取源数据文件,使用生成的类解析记录,并且执行选定的导出方法。
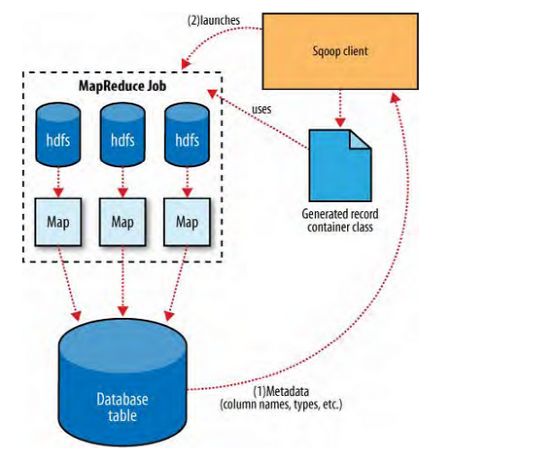
基于jdbc的导出方法会产生一批insert语句,每条语句都会向目标表中插入多条记录。多个单独的线程被用于从HDFS读取数据并与数据库进行通信,以确保涉及不同系统的I/O操作能够尽可能重叠执行。
虽然HDFS读取数据的MapReduce作业大多根据所处理文件的数量和大小来选择并行度(map任务的数量),但sqoop的导出工具允许用户明确设定任务的数量。由于导出性能会受并行的数据库写入线程数量的影响,所以sqoop使用combinefileinput类将输入文件分组分配给少数几个map任务去执行。
2.2、导出与事务
进程的并行特性,导致导出操作往往不是原子操作。Sqoop会采用多个并行的任务导出,并且数据库系统使用固定大小的缓冲区来存储事务数据,这时一个任务中的所有操作不可能在一个事务中完成。因此,在导出操作进行过程中,提交过的中间结果都是可见的。在导出过程完成前,不要启动那些使用导出结果的应用程序,否则这些应用会看到不完整的导出结果。
更有问题的是,如果任务失败,他会从头开始重新导入自己负责的那部分数据,因此可能会插入重复的记录。当前sqoop还不能避免这种可能性。在启动导出作业前,应当在数据库中设置表的约束(例如,定义一个主键列)以保证数据行的唯一性。
2.3、导出与SequenceFile
Sqoop还可以将存储在SequenceFile中的记录导出到输出表,不过有一些限制。SequenceFile中可以保存任意类型的记录。Sqoop的导出工具从SequenceFile中读取对象,然后直接发送到OutputCollector,由他将这些对象传递给数据库导出OutputFormat。为了能让Sqoop使用,记录必须被保存在SequenceFile键值对格式的值部分,并且必须继承抽象类com.cloudera.sqoop.lib.SqoopRecord。
3、项目案例
在我们移动项目中,有些数据是通过web页面维护,这些数据都是通过管理员手动添加到分析系统中的。为了使hive可以更好的进行分析,所以需要将这些服务数据,定期导入到我们的hive数据仓储中,这时sqoop就需要发挥作用了。
需要通过sqoop将数据从mysql导入到hive数据仓储的服务有:应用管理、渠道管理、自定义事件管理、里程碑管理。他们对应的数据库(10.6.219.86)表分别是:base_app、base_channel、base_event、base_milestone。
3.1、采用sqoop指令导入
在本次实践中,我们仅以导入应用管理表(base_app)为例进行说明。
1、执行sqoop指令将数据从mysql导入到hive中,指令为:
Sqoop import --connect jdbc:mysql://10.1.11.78:3306/video --table base_event --username root --password 123456 -m 1 --hive-import --hive-database video --hive-table base_event --hive-overwrite --fields-terminated-by "\t"--lines-terminated-by “\n”--as-textfile
指令详解:
- sqoop import ---执行sqoop导入指令;
- --connect jdbc:mysql://hostname:port/database ---要连接的数据库地址、端口号、数据库database;
- --table base_app ----- 要操作的数据库表;
- --username root ----- 连接数据库的用户名;
- --password 123456 --- 连接数据库的密码;
- -m 1 ------ 要启动的map数量
- --hive-import --- 采用hive方式导入
- [--create-hive-table] --- 如果导入的表在hive中不存在的话,sqoop自动在hive中创建该表。但是当表存在的情况下,添加该选项会导致指令报错。所以在实际操作中,不建议使用,并且在实际的操作过程中,即使我们不添加该项辅助指令,sqoop也会在hive中创建导入的表。
- --hive-database yidong --- 要将数据库表导入到hive的那个database中;
- --hive-table base_app --- 要将数据库表导入到hive的那个表中;
- --hive-overwrite ---如果hive的表中已经存在数据,添加该项操作后,会将原有的数据覆盖掉。
- --fields-terminated-by “\t” --- hive存储到hdfs中的文件中字段间的分隔符;
- --lines-terminated-by “\n”– hive存储到hdfs中的文件中每行间的分隔符;
- --as-textfile ---hive存储到hdfs中的文件格式,采用文本存储;
常用辅助指令详解:
1、通过help指令查看sqoop导入帮助:
Sqoop help import;
2、Sqoop导入行辅助操作详解:
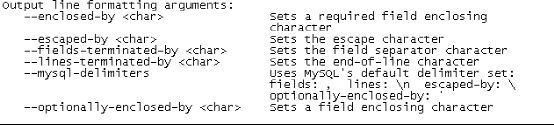
3、Sqoop hive导入辅助操作详解:

3.2、通过oozie编写workflow定时将同步数据
在本次项目实践中,我们需要用到oozie的sqoop action。在这章节中,我会演示给大家如何编写workflow.xml实现定时数据同步的。
在项目运作的过程中发现,为了能更好的进行数据同步,建议首先把需要同步的数据库表在环境初始化的过程中,在hive数据仓储中创建出来。这样项目运作的过程中,会很轻松的执行。
编写workflow.xml进行同步工作,workflow.xml内容如下:
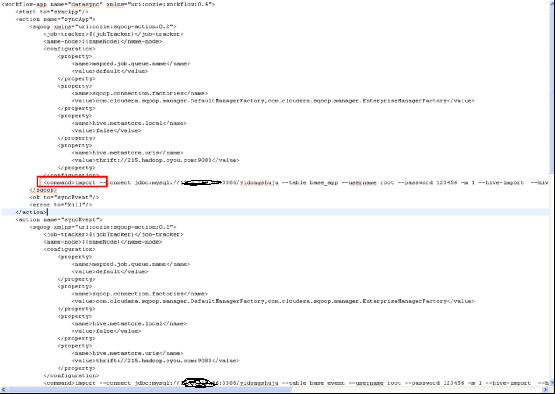
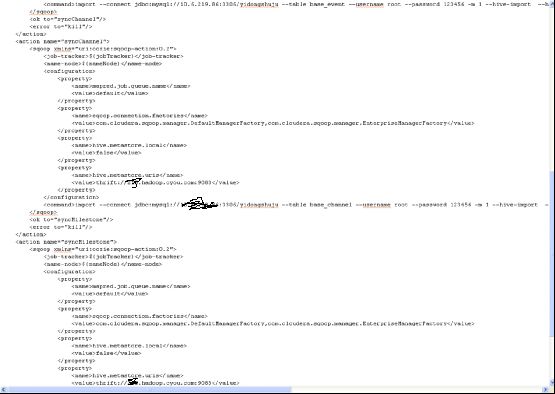

在该例子中,我们是对四个需要同步的表进行,通过sqoop进行了同步。大家在编写oozie sqoop action脚本的工程中,需要特别注意:sqoop支持两种方式配置指令,一种是command,另一种是arg的方式。不管是采用哪种方式,导入导出的过程的命令中,一定不要出现sqoop,而是从sqoop需要执行的指令以后的内容开始(从import或者export开始),请查看截图中的红色标注。
3.3、项目实践总结归纳
① 首先在初始化同步工作流环境的过程中,先在script.hql文件中编写建表语句,在hive数据仓储中创建出需要进行同步的table。
② 编写workflow.xml文件,定义需要同步表的sqoop工作流,且工作流需要执行的命令中,不会出现“sqoop”关键字,而是从该关键字以后的指令开始,如:在cli情况下我们需要同步数据库,执行的命令为:sqoop import jdbc:mysql://……;而在workflow.xml配置的command命令中为:import jdbc:mysql://…..,在这里不用再填写sqoop,否则会报错,这是初学人员常遇到的错误,谨记!!!!
③ 在sqoop导入mysql数据到hive时,--fields-terminated-by "\t",自定义的分隔符要为双引号。否则指定的分隔符无效!