概述
TSQL语法习惯和规范
1,TSQL语法习惯和规范(一切不是教条主义)
目标:编写健壮的sql语句,生成更加高效的执行计划
所有的性能优化中,理论基础固然重要,但往往经验比理论更重要;经验说明你踩过的坑多;但解决问题的能力也建立在你的知识积累和思考
你可以尝试建立一些烂表,烂数据结构,然后尝试优化它
优秀的数据结构往往反映了你的领域模型
查询语句
下面我们以以下这条查询语句来分析Sql的语法规范:
UserInfo表,10万行数据,主键Id,非聚集索引UserCode
Employee表,100万行数据,无任何索引
Employee表中有一个UserId字段,用于记录Employee对应的User
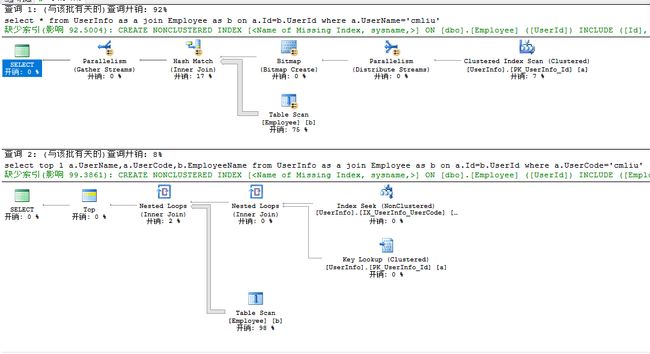
select * from UserInfo as a join Employee as b on a.Id=b.UserId where a.UserName='cmliu'
1,需要明确需要返回的字段;尽可能避免"select *"语句
减少IO数据量
提高索引的覆盖,提高索引的使用率
2,需要限定返回集合数据量;尤其是数据量比较大的时候
防止大批量的数据操作
有效使用索引
防止扫描操作带来大量的磁盘IO和内存开销
考虑一下,那些需要返回全部数据的业务场景是否是合理的,是否可以用其他方案替代;
大数据量时全部数据返回来,用户能看得过来吗?是否可以折中或者替代
3,优先考虑使用索引;在需要对数据进行过滤的时候,优先考虑使用索引字段
如果存在多个索引字段,那么我们优先考虑选择重复率最低的索引字段
一般情况下,我们会选择重复率不超过5%的字段作为索引字段
4,过滤字段上不要使用任何计算,包括函数逻辑计算
计算会照成查询优化器无法使用计算字段的索引
按上面规范优化之后
select top 10 a.UserName,a.UserCode,b.EmployeeName from UserInfo as a join Employee as b on a.Id=b.UserId where a.UserCode='cmliu'
4,Order By:order by 子句的性能取决于参与排序的数据量的大小
控制排序数据集的大小,排序是在数据筛选的结果完成后进行排序的,避免大数据量的排序操作
排序消耗的资源超过内存限制时,排序过程中则会使用到TempDB,此时性能会大大下降
因为TempDB是公共的,大批量数据排序甚至会导致整个系统出现大量的sql性能下降
使用索引,尤其是必须针对大批量数据排序操作时
排序合理使用索引甚至可以在查询过程中不发生排序
5,数据量级
大批量的数据操作会导致将查询中的大量数据从内存拆分到TempDB,TempDB是公共的,是存储在磁盘上的,这会增加IO消耗
大批量的数据操作会清理缓存,会使缓存失效
数据量级建立在数据库服务器硬件资源,网络资源的性能与数据结构设计上
对于有些系统来说100万行就是大数据量,而针对有些系统来说1000万行都是小数据量
行业里面一般情况下将千万级,亿级数据量定为大数据量;常见的大数据量主要集中在流水,记录等这些业务方面;如支付流水,订单流水,交易流水,存取款流水,仓库流水,定位记录等
6,Group By
group by对数据进行分组统计时,也要使用排序算法;所以对于order by的优化是对group by的优化是一样的;
所以group by过程中可能会发生Hash计算或者排序计算,如果你在group by的字段合理的索引,就可以避免哈希计算和排序;如下图
考虑限制参与group by的数据量;因为发生Hash计算时,大数据量会更加消耗资源
在全字段Group By时,你会发现group by与distinct是一致的;因为本质上distinct在计算时,就是进行一次全字段的group by;对比以下两个sql语句的执行结果与执行计划,你就会明白
注,下面的UserId,Age是有索引的,所以在group by时没有发生排序
select distinct UserId,Age from SortUsers select UserId,Age from SortUsers group by UserId,Age

Update语句
Update语句执行时也会查询目标数据;和Select相比;它们在锁方面有差异
Update会对数据优先添加【更新锁】,确认要进行修改时,【更新锁】转换成【排他锁】;然后才会更新数据
Select使用的共享锁,Update的排它锁,更新锁比共享锁的兼容性更低;
Update在更新大数据量的时候,或者Update存在性能问题时,或者Update长时间执行的,或者在一个事务中时,容易照成阻塞。
Update的优化
优先照顾Update语句;在更新频繁,或者大数据量的更新时;优先考虑Update的性能,避免长时间阻塞,如update的索引,使用唯一字段来进行筛选过滤的数据
Delete语句
delete语句检索数据的性能和Select是一样的
delete删除数据时,使用【排他锁】
delete删除数据时,会影响到索引的维护,对性能的要求更高;
delete删除语句的查询字段使用索引时,应该权衡更新,查询,删除操作的频率;不要因为过多的索引影响数据的删除,更新的性能
delete删除数据时,为了保证ACID,会对删除的数据记录日志;大批量的数据删除会造成大量的日志记录,会影响性能
Where子句
sql的优化通常都是针对具有条件过滤(where)的语句进行的;没有过滤条件的查询语句只能选择表扫描或者索引扫描
where语句优化
是否有合适的索引可供使用
字段是否有函数计算
返回字段集合(是否按需返回,返回的字段是否有索引)
返回数据量
关联查询
嵌套循环是查询连接中最好的一种方式,以小数据集作为外部数据,大数据集作为内部循环的集合
连接查询的连接字段优先使用索引字段,重复率低的字段
嵌套连接以小表扫描(优先考虑索引扫描),大表查找为佳(优先考虑索引查找)
数据集相当且已排序时,使用合并连接
索引是宝贵的,也是昂贵,出现性能问题时,不是立马对参与关联查询的所有表,所有参与查找或者连接字段健索引;而是找一个表,给1到2个字段建立索引;
在大部分情况下(不要盲目),对大表建立索引的性价比会比较高。
哈希连接算法伪代码表示(实际上就是笛卡尔积):
foreach(var R1 in 小表){
H1=Hash(R1.Key);
Insert H1 into HashBucket;
}
foreach(var R2 in 大表){
H2=Hash(R2.Key);
foreach(var H1 in HashBucket){
if(H1=H2){
输出(R1,R2);
}
}
}
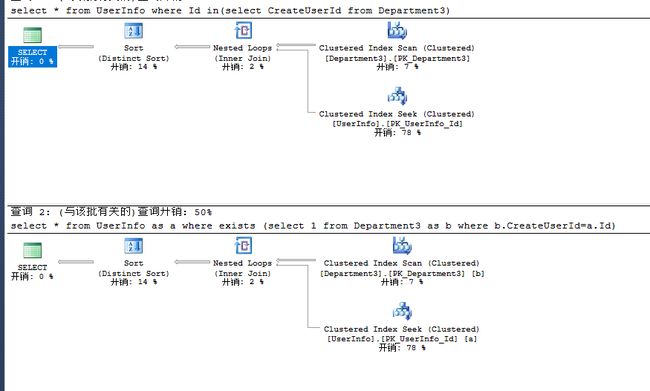
子查询
子查询尽量集中在where子句中,方便阅读
在一个与剧中,子查询数量不超过3个,整个查询语句涉及的表不超过5个
子查询的语句会被执行计划分解,简化,特殊的转换,转成常用的连接操作
在特殊的情况下,子查询不能被优化或者简化,在这些情况下,子查询会优先执行,作为下一个操作的输入部分
过于复杂的子查询会造成性能上的瓶颈
避免在子查询中对大数据集进行汇总或者排序操作
尽量缩小子查询中可能返回的结果集范围
优先考虑使用确定性的判断符(等于,in,exsit),避免使用any,all
exist在子查询中通常会转换成inner join
in在子查询中通常会直接转换成连接运算符
如下示例图
性能优化工具
sqlserver2017具有自动优化功能
sqlserver2017智能查询处理:自使用查询处理
性能监控和优化
查询存储
查询存储是数据库性能优化的基础,当sql性能出现问题,而我们是无法获取这个sql的执行计划;
而查询存储就是收集当时的执行信息存储在磁盘中,
包括执行计划,运行时统计信息,等待信息;
你可以在查询存储中看到耗时的查询,回归的查询等
qlserver2017开启查询存储会对数据库造成3%-5%的性能影响;默认情况下是不开启的
sqlserver2017开启查询存储方法一:使用sql
SET QUERY_STORE = ON (OPERATION_MODE = READ_WRITE);
sqlserver2017开启查询存储方法二:在sql server mangement studio中,选择要监控的数据库,右键"属性",在属性面版中,选择查询存储>操作模式,修改值为"读写"
在数据查询存储的配置面板上有一个数据刷新间隔;默认15分钟,数据刷新间隔小会影响到数据库性能

查询存储的结果

执行计划回归
执行计划可能会因为内存的压力清除,也可能会因为数据的趋势,索引而变更;
执行计划的变更会可能导致相同的sql语句采用不同的执行计划;一般情况下,新的执行计划会比旧的执行计划要好
也存在新的执行计划没有旧的执行计划好的情况;这样新的执行计划就会导致性能回归;
在没有查询存储的情况下,我们是无法发现执行计划回归的;查询回归,
参数嗅探
sqlserver编译sql时会评估传入的参数,生成对应的执行计划缓存,参数值会保存在执行计划缓存中
自动优化
对潜在查询性能问题进行深入分析,并提供优化建议;自动选择更好的执行计划;当数据库引擎发现更好的执行计划时,会自动更正执行计划
sql server要执行多次来搜集执行计划的信息
影响执行计划质量的因素:统计信息果实,不合理的索引,低效的sql语句,代码重编译
自学习,持续监控
开启自动调优sql:
alter database current set AUTO_TUNING(FORCE_LAST_GOOD_PLAN=ON);