深入分析Java I/O的工作机制
I/O是目前web应用主要的问题之一,大部分web应用系统的瓶颈是I/O瓶颈。
java 的I/O类可以分为如下4组:
基于字节操作的I/O接口:InputStream 和 OutputStream
基于字符操作的I/O接口:Writer 和 Reader
基于磁盘操作的I/O接口:File
基于网络操作的I/O接口:Socket
基于字节操作的I/O接口
1:InputStream的作用表示那些从不同数据源产生输入的类,即其派生类多是不同数据源对应的流对象。如下:
ByteArrayInputStream:从内存缓冲区读取字节数组
FileInputStream:从文件中读取字节,其构造参数可以是文件名、File对象或FileDescriptor
ObjectInputStream:主要用于反序列化,读取基本数据类型或对象
PipedInputStream:产生用于写入相关PipedOutputStream的数据,实现“管道化”概念,多用于多线程中。
FilterInputStream:作为装饰器类,其子类与上述不同流对象叠合使用,以控制特定输入流。
其中,FilterInputStream的子类通过添加属性或有用的接口控制字节输入流,其构造函数为InputStream,常见的几个如下:
DataInputStream:与DataOutputStream搭配使用,读取基本类型数据及String对象。
BufferdInputStream:使用缓冲区的概念,避免每次都进行实际读操作,提升I/O性能。(不是减少磁盘IO操作次数(这个OS已经帮我们做了),而是通过减少系统调用次数来提高性能的)
InflaterInputStream:其子类GZIPInputStream和ZipInputStream可以读取GZIP和ZIP格式的数据。
2:与InputStream相对应,OutputStream的作用表示将数据写入不同的数据源,常用的输出流对象如下:
ByteArrayOutputStream:在内存中创建缓冲区,写入字节数组
FileOutputStream:将字节数据写入文件中,其构造参数可以是文件名、File对象或FileDescriptor
ObjectOutputStream:主要用于序列化,作用于基本数据类型或对象
PipedOutputStream:任何写入其中的数据,都会自动作为相关PipedInputStream的输出,实现“管道化”概念,多用于多线程中。
FilterOutputStream:作为装饰器类,其子类与上述不同流对象叠合使用,以控制特定输出流。
其中,FilterOutputStream的子类通过添加属性或有用的接口控制字节输入流,其构造函数为InputStream,常见的几个如下:
DataOutputStream:与DataInputStream搭配使用,写入基本类型数据及String对象。
PrintStream:用于格式化输出显示。
BufferdOutputStream:使用缓冲区的概念,避免每次都进行实际写操作,提升I/O性能。
DeflaterOutputStream:其子类GZIPOutputStream和ZipOutputStream可以写GZIP和ZIP格式的数据。
基于字符操作的I/O接口
1. Reader类型
继承自Reader类的,字符型数据来源常用类,如下:
InputStreamReader:字节与字符适配器,子类包含FileReader(以字符形式读取文件)
CharArrayReader:读取字符数组
StringReader:数据源是字符串
BufferedReader:读取字符输入流,并进行缓存,常用法:BufferedReader in = new BufferedReader(new FileReader("foo.in")); 表示采用缓存的方式从文件读取数据
PipedReader:管道形式读取字符
FilterReader:对Reader装饰,直接使用的不多,如PushbackReader
2. Writer类型
继承自Writer类的,字符型数据来源常用类,如下:
OutputStreamReader:字节与字符适配器,子类包含FileWriter(以字符形式写文件)
CharArrayWriter:写字符数组
StringWriter:内部有StringBuffer,用于缓存构造字符串
BufferedWriter:字符输出流,常用法:PrintWriter out = new PrintWriter(new BufferedWriter(new FileWriter("foo.out"))); 表示将数据格式化并用缓存的方式写入文件
PipedWriter:管道形式输出字符
FilterWriter:对Writer装饰,如XMLWriter
字节与字符的转化接口
待完善
磁盘I/O工作机制
1:标准访问文件的方式
标准的访问方式是应用程序调用read()接口,操作系统检查在内核的高速缓存中有没有需要的数据,如果缓存中有,那就直接从缓存中返回,如果没有,则从磁盘重读取,换乘到操作系统的缓存中。
写入的方式是,用户的应用程序调用write()接口将数据从用户地址空间复制到内核地址空间的缓存中。这时候对用户程序来说写操作已经完成了。至于什么时候再写到磁盘中,看操作系统了。
2:直接I/O的方式
应用程序直接访问磁盘,这个是减少了一次,内核缓冲区复制到用户程序缓冲区的数据复制。这种访问方式是数据的管理方式为应用程序实现的数据库管理系统,对于这种访问方式的话,系统明确的知道,要缓存哪些数据,失效是时间,还可以对数据进行预加载,提前将数据加载到内存中,提高访问效率,操作系统的话,只是缓存最近一次访问的数据到缓存中。
3:同步访问文件的方式
读取和写入必须要同步,只要数据被成功的写入磁盘中,才会返回给应用程序一个成功的标准。
4:异步访问文件
当访问数据的线程发出请求后,线程会接着处理其它事情,不会被阻塞等待,当返回请求的数据的时候,在进行下面的操作,这提高了应用程序的效率,但是不会提高文件访问的效率。
5:内存映射的方式
内存中某一块区域昱磁盘的文件关联起来,当要访问内存的某一数据的时候,专为访问文件的某一数据,减少,内核空间缓存,复制到用户空间的缓存。因为这两块的空间数据,是共享的。
java访问磁盘文件
待完善
java序列化技术
待完善
网络I/O的机制
1:TCP状态转换图
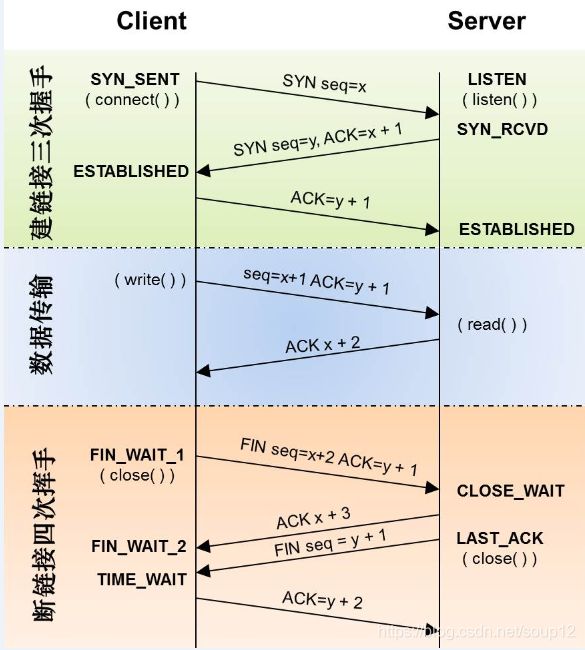
2:影响网络传输的因素:
网络带宽:就是一条物理链路,在1s内能传输的最大比特数,注意是比特不是字节
传输距离:由于数据在光纤中,,并不是直线,会有一个折射率,速度大概是光的2/3,所以传输会有延时
TCP拥塞控制:我们知道tcp传输是一个,停-等-停-等的协议,传输放要和接收方步调一致,要达到步调一致,就要通过拥塞控制调节:
3:java socket的工作机制
主机与主机的应用程序通信,必须通过socket建立连接,而建立socket连接,就需要底层通过tcp/ip来建立tcp连接,建立tcp的连接需要底层
的ip来寻址网络中的主机,而对应主机的应用程序很多,如何与指定的应用程序通信,就要通过tcp/upd的地址,也就是端口号,来指定了
建立通信连接
客户端,创建一个socket实例,操作系统为这个实例分配一个没有被占用的端口,并建立包含本地地址,远程地址,端口号的套接字数据结构
这个结构会保存到这个连接关闭为止,要进行tcp3次握手之后,这个socket实例才会被返回。否则将会报错,IOException
与之对应的服务端,将创建一个ServerSocket,只要指定的端口,没有被占用,这个实例一般会创建出来的,同时操作系统也会为它创建一个底层数据结构
这个数据结构,包含要监听的端口号,和包含监听地址的通配符,通常是*,也就是监听所有的。之后调用accept()方法,然后进入阻塞状态中,
等待请求。当一个新的请求,会新建一个新的套接字数据结构,包括请求地址和端口,这个套接字会关联到未完成的ServerSocket的实例的未完成连接的列表上
当进行了3次握手后,服务端的socket实例才会创建完成,然后将这个实例对应的数据结构,从ServerSocket的未完成列表里已到已完成列表里
。所以与serverSocket关联的列表里,每一个数据结构,都代表了一个与客户端建立的tcp连接
数据传输
数据传输是我们建立连接的主要目的,当连接建立完成,服务端和客户端,都会有一个socket ,都会有一个inpuTsTRAM 和 outputStream ,然后为他们分配一个缓存区,
用于接收和发送数据,当发送方,的发送队列满了,将会转移到接收方,方接收方的满了的话,那么发送方将会被阻塞
,直到接收方有足够的空间去接收发送方发的,这个缓冲区的大小和写入端,读取端的速度都会影响传输效率,因为有阻塞,所以双方还要有协调的过程,如果两条同时传数据,可能会发生死锁