数据结构与算法分析-栈
栈ADT
栈模型
栈(stack)是限制插入和删除只能在一个位置上进行的表,该位置是表的末端,叫做栈的顶(top)。对栈的基本操作有 P u s h Push Push(进栈)和 P o p Pop Pop(出栈),前者相当于插入,后者则是删除最后 插入的元素。最后插入的元素可以通过使用 T o p Top Top例程在执行 P o p Pop Pop之前进行考查。对空栈进行的 P o p Pop Pop或 T o p Top Top一般被认为是栈的ADT的错误。另一方面,当运行 P u s h Push Push时空间用尽是一个实现错误,但不是ADT错误。
栈有时叫做LIFO(后进先出) 表。一般的模型是,存在某个元素位于栈顶,而该元素是唯一的可见元素。
栈的实现
栈的链表实现
首先,给出一些定义。实现栈要用到一个表头。
#ifndef _Stack_h
#define _Stack_h
typedef int ElementType;
struct Node;
typedef struct Node *PtrToNode;
typedef PtrToNode Stack;
int IsEmpty( Stack S );
Stack CreateStack( void );
void DisposeStack( Stack S );
void MakeEmpty( Stack S );
void Push( ElementType X, Stack S );
ElementType Top( Stack S );
void Pop( Stack S );
#endif /* _Stack_h */
/* Place in implementation file */
/* Stack implementation is a linked list with a header */
struct Node
{
ELementType X;
PrtToNode Next;
};
下面给出测试空栈的代码,测试空栈与测试空表的方式相同。
int IsEmpty(Stack S)
{
return S->Next == NULL;
}
创建一个空栈,我们只要建立一个头结点; M a k e E m p t y MakeEmpty MakeEmpty设置 N e x t Next Next指针指向 N U L L NULL NULL。
Stack CreateStack(void)
{
Stack S;
S = malloc(sizeof(struct Node));
if(S == NULL)
FatalError("Out of space!!!");
S->Stack = NULL;
MakeEmpty(S);
return S;
}
void MakeEmpty(Stack S)
{
if(S == NULL)
Error("Must use CreateStack first");
else
while(!IsEmpty(S))
Pop(S);
}
P u s h Push Push是作为向链表前端进行插入而实现的,其中,表的前端作为栈顶。
void Push(ElementType X, Stack S)
{
PtrToNode TmpCell;
TmpCell = (PtrToNode)malloc(sizeof(struct Node));
if(TmpCell == NULL)
FatalError("Out of space!!!");
else
{
TmpCell->Element = X;
TmpCell->Next = S->Next;
S->Next = TmpCell;
}
}
T o p Top Top的实例是通过考查表在第一个位置上的元素而完成的。
ElementType Top(Stack S)
{
if(!IsEmpty(S))
return S->Next->Element;
Error("Empty stack");
return 0; /* Return value used to avoid warning */
}
最后, P o p Pop Pop是通过删除表的前端的元素而实现的。
PtrToNode FirstCell;
if(IsEmpty(S))
Error("Empty stack");
else
{
FirstCell = S->Next;
S->Next = S->Next->Next;
free(FirstCell);
}
很清楚,所有的操作均花费常数时间,因为这些例程没有任何地方涉及到栈的大小(空栈以外)。这种实现方法的缺点在于对malloc和free的调用的开销是昂贵的,特别是与指针操作的例程相比尤其如此。有的缺点通过使用第二个栈可以避免,该第二个栈初始时为空栈。当一个单元从第一个栈弹出时,它只是被放到了第二个栈中。此后,当第一个栈需要新的单元时,它首先去检查第二个栈。
栈的数组实现
另一种实现方法避免了指针并且可能是更流行的解决方案。这种策略潜在危害是我们需要提前声明一个数组的大小。
每一个栈有一个 T o p O f S t a c k TopOfStack TopOfStack,对于空栈它是-1(这就是空栈的初始化)。为了将某个元素 X X X压入到该栈中,我们将 T o p O f S t a c k TopOfStack TopOfStack加1,然后置 S t a c k [ T o p O f S t a c k ] = X Stack[TopOfStack]=X Stack[TopOfStack]=X,其中 S t a c k Stack Stack是代表具体栈的数组。为了弹出元素,我们置返回值为 S t a c k [ T o p O f S t a c k ] Stack[TopOfStack] Stack[TopOfStack]然后 T o p O f S t a c k TopOfStack TopOfStack减1。
这些操作不仅以常数时间运行,而且是以非常快的常数时间运行。在某些机器上,若在带有自增和自减寻址功能的寄存器上操作,则(整数的) P u s h Push Push和 P o p Pop Pop都可以写成一条机器指令。栈很可能是在计算机科学中在数组之后最基本的数据结构。
下面给出 S t a c k Stack Stack的定义,为指向一个结构体的指针。该结构体包含 T o p O f S t a c k TopOfStack TopOfStack域和 C a p a c i t y Capacity Capacity域。一旦知道最大容量,则该栈即可被动态地确定。
#ifndef _Stack_h
#define _Stack_h
typedef int ElementType;
struct StackRecord;
typedef struct StackRecord *Stack;
int IsEmpty(Stack S);
int IsFull(Stack S);
Stack CreateStack(int MaxElements);
void DisposeStack(Stack S);
void MakeEmpty(Stack S);
void Push(ElementType X, Stack S);
ElementType Top(Stack S);
void Pop(Stack S);
ElementType TopAndPop(Stack S);
#endif /* _Stack_h */
/* Place in implementation file */
/* Stack implementation is a dynamically allocated array */
#define EmptyTOS (-1)
#define MinStackSize (5)
struct StackRecord
{
int Capacity;
int TopOfStack;
ElementType *Array;
}
下面创建一个具有给定的最大值的栈。栈的数组不需要初始化。
Stack CreateStack(int MaxElements)
{
Stack S;
if(MaxElements < MinStackSize)
Error("Stack size is too small");
S = (Stack)malloc(sizeof(struct StackRecord));
if(S == NULL)
FatalError("Out of space!!!");
S->Array = (ElementType*)malloc(sizeof(ElementType) * MaxElements);
if(S->Array == NULL)
FatalError("Out of space!!!");
S->Capacity = MaxElements;
MakeEmpty(S);
return S;
}
为了释放栈结构应该编写例程 D i s p o s e S t a c k DisposeStack DisposeStack。这个例程首先释放栈数组,然后释放栈结构体。
void DisposeStack(Stack S)
{
if(S != NULL)
{
free(S->Array);
free(S);
}
}
下面是检测一个栈是否空栈的例程。
int IsEmpty(Stack S)
{
return S->TopOfStack == EmptyTOS;
}
下面是创建一个空栈的例程。
void MakeEmpty(Stack S)
{
S->TopOfStack = EmptyTOS;
}
进栈的例程。
void Push(ElementType X, Stack S)
{
if (IsFull(S))
Error("Full stack");
else
S->Array[++S->TopOfStack] = X;
}
将栈顶返回的例程。
ElementType Top(Stack S)
{
if(!IsEmpty(S))
return S->Array[S->TopOfStack];
Error("Empty stack");
return 0; /* Return value used to avoid warning */
}
从栈弹出元素的例程。
void Pop(Stack S)
{
if(IsEmpty(S))
Error("Empty stack");
else
S->TopOfStack--;
}
P o p Pop Pop偶尔写成返回弹出的元素(并使栈改变)的函数。虽然当前的想法是函数不应该改变其输入参数,但是下代码表明这在C中是最方便的方法。
ElementType TopAndPop(Stack S)
{
if(!IsEmpty(S))
return S->Array[S->TopOfStack--];
Error("Empty stack");
return 0; /* Return value used to avoid warning */
}
应用
平衡符号
做一个空栈。读入字符直到文件尾。如果字符是一个开放符号,则将其推入栈中。如果字符是一个封闭符号,则当栈空时报错。否则,将栈元素弹出。如果弹出的符号不是对应的开放符号,则报错。在文件尾,如果栈非空则报错。
很清楚,它是线性的,它仅需对输入进行一趟检验。因此,它是在线(on-line)的,是相当快的。
后缀表达式
假如计算 4.99 ∗ 1.06 + 5.99 + 6.99 ∗ 1.06 4.99*1.06+5.99+6.99*1.06 4.99∗1.06+5.99+6.99∗1.06,简单的四功能计算器将给出19.37,但科学计算器将给出18.69。科学计算器一般包括括号,因此我们可以通过加括号的方法得到正确答案,但是使用简单计算器我们需要记住中间结果。
该例的典型计算顺序可以是将4.99和1.06相乘并存为 A 1 A_1 A1,然后将5.99和 A 1 A_1 A1相加,再将结果存入 A 1 A_1 A1。我们再将6.99和1.06相乘并将答案存为 A 2 A_2 A2,最后将 A 1 A_1 A1和 A 2 A_2 A2相加并将最后的结果存入 A 1 A_1 A1。我们可以将这种操作顺序书写如下:
4.99 1.06 ∗ 5.99 + 6.99 1.06 ∗ + 4.99\space1.06\space*\space5.99\space+\space6.99\space1.06\space*\space+ 4.99 1.06 ∗ 5.99 + 6.99 1.06 ∗ +
这个记法叫做***后缀(postfix)***或***逆波兰(reverse Polish)***记法,其求值过程恰好就是我们上面所描述的过程。计算这个问题最容易的方法是使用一个栈。当见到一个数时就把它推入栈中;在遇到一个运算符时该运算符就作用于从该栈弹出的两个数(符号)上,将所得结果推入栈中。例如。后缀表达式
6 5 2 3 + 8 ∗ + 3 + ∗ 6\space5\space2\space3\space+\space8\space*\space+\space3\space+\space* 6 5 2 3 + 8 ∗ + 3 + ∗
计算如下:前四个字符放入栈中,此时栈变成
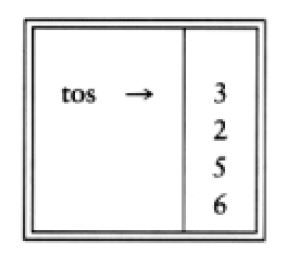
下面读到一个“+”号,所以3和2从栈中弹出,并且它们的和5被压入栈中。
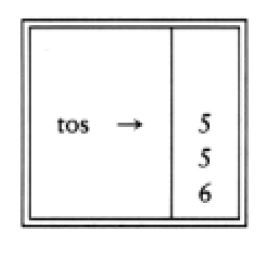
接着,8进栈。
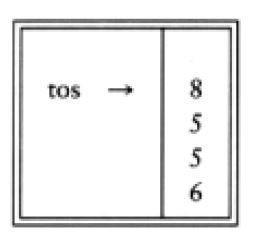
现在见到一个“*”号,因此8和5弹出,并且5*8=40进栈。
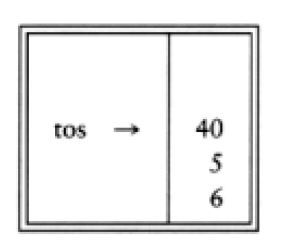
接着又见到一个“+”号,因此40和5被弹出,并且5+40=45进栈。

现在将3压入栈中。
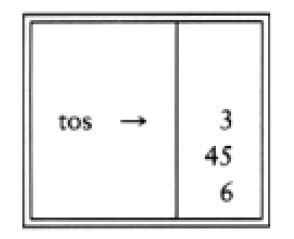
然后“+”使得3和45从栈弹出,并将45+3=48压入栈中。
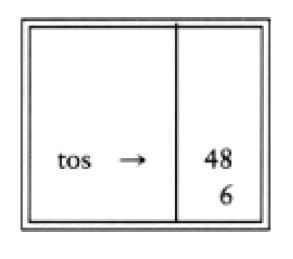
最后,遇到一个“*”号,从栈中弹出48和6,将结果6*48=288压进栈中。
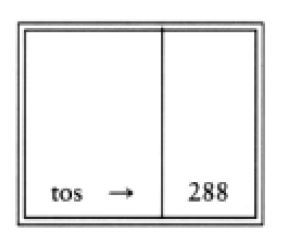
计算一个后缀表达式花费的时间是 O ( N ) O(N) O(N)。当一个表达式以后缀表达式记号给出时,没有必要知道任何优先规则。这是一个明显的有点。
中缀到后缀的转换
栈不仅可以用来计算后缀表达式的值,而且我们还可以用栈将一个标准形式的表达式(或叫做*中缀式(infix))转换成后缀式。我们通过只允许操作+,*,(,),并坚持普通的优先级法则将一般的问题浓缩成小规模的问题。我们还要进一步假设表达式是合法的。设我们欲将中缀表达式
a + b ∗ c + ( d ∗ e + f ) ∗ g a+b*c+(d*e+f)*g a+b∗c+(d∗e+f)∗g
转换成后缀表达式。正确的答案是
a b c ∗ + d e ∗ f + g ∗ + a\space b\space c\space*\space+\space d\space e\space*\space f\space+\space g\space*\space+ a b c ∗ + d e ∗ f + g ∗ +
当读到一个操作数的时候,立即把它放到输出中。操作符不立即输出,从而必须先存在某个地方。正确的做法是将已经见到过的操作符放进栈中而不是放到输出中。当遇到左圆括号时我们也将其推入栈中。我们从一个空栈开始计算。
如果遇到一个右括号,那么就将栈元素弹出,将弹出的符号写出直到我们遇到一个(对应的)左括号,但是这个左括号只被弹出,不被输出。
如果我们见到其他的符号(“+”,“*”,“(”),那么我们从栈中弹出栈元素直到发线优先级更低的元素为止。有一个例外:除非是在处理一个“)“的时候,否则我们绝不从栈中移走”(“。对于这种操作,”+“的优先级最低,而”(“的优先级最高。当从栈弹出元素的工作完成后,我们将操作符压入栈中。
最后,如果我们读到输入的末尾,我们将栈元素弹出直到该栈变成空栈,将符号写到输出中。
首先,a被读入,于是它流向输出。然后”+“被读入并被放入栈中。接着是b读入并流向输出。这一时刻的状态如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IemJAT0S-1579509385521)(https://s2.ax1x.com/2020/01/20/1PacY6.jpg)]
这时”*“号读入。操作符栈的栈顶元素比”*“的优先级低,故没有输出,”*“进栈。接着,c被读入并输出。至此,我们有
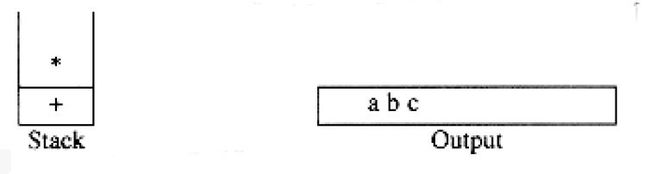
后面的符号是一个”+“号。检查一下栈,我们发现,需要将"*”从栈弹出并放到输出中;弹出栈中剩下的“+”号,该运算符不比刚刚遇到的“+”号优先级低而是有相同的优先级;然后,将刚刚遇到的“+”号压入栈中。
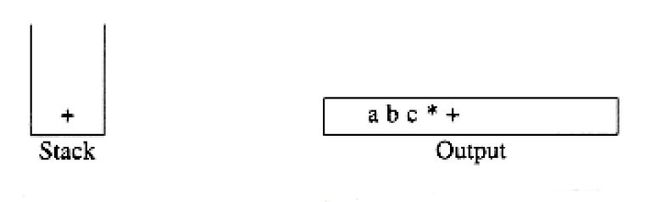
下一个被读到的符号是一个“(”,由于具有最高的优先级,因此它被放进栈中。然后,d读入并输出。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7my6dmFf-1579509385523)(https://s2.ax1x.com/2020/01/20/1Pdv8K.jpg)]
继续进行,我们又读到一个“*”。除非正在处理闭括号,否则开括号不会从栈中弹出,因此没有输出。下一个是e,他杯渡岛输出。
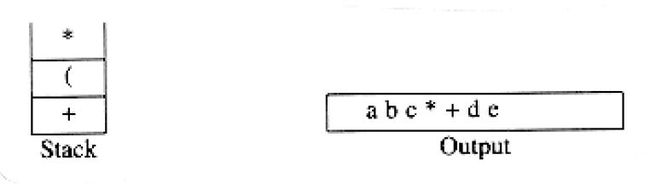
再往后读到的符号是“+”。我们将“*”弹出并输出,然后将“+”压入栈中。这以后,我们都到f并输出。
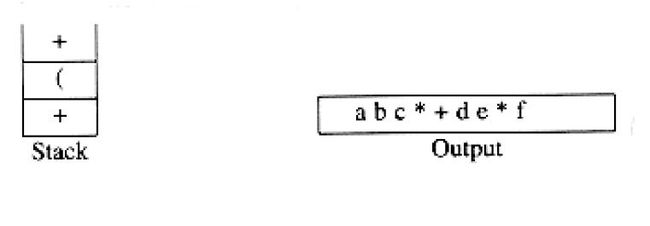
现在,我们读到一个“)”,因此将栈元素直到"("弹出,我们将一个“+”号输出。
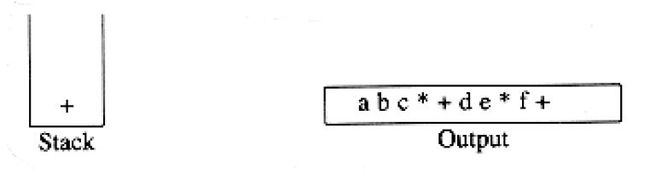
下面又读到一个“*”,该运算符被压入栈中。然后,g被读入并输出。

现在输入为空,因此将栈中的符号全部弹出并输出,直到栈变成空栈。
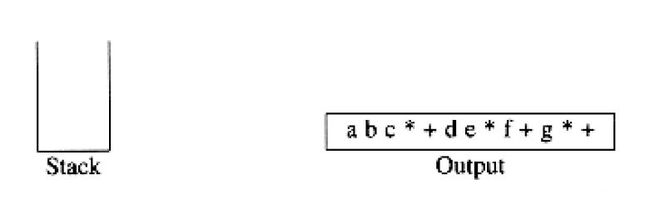
这种转换只需要 O ( N ) O(N) O(N)时间并经过一趟输入后工作完成。我们可以指定减法和加法有相同的优先级以及乘法和除法有相同的优先级而将减法和除法添加到指令集中去。一种巧妙的想法是将表达式 a − b − c a-b-c a−b−c转换成 a b − c − a\space b-c- a b−c−而不是转换成 a b c − − a\space b\space c-- a b c−−。
函数调用
当调用一个新函数时,主调例程的所有局部变量需要由系统存储起来,否则被调用的新函数将会覆盖调用例程的变量。不仅如此,该主调例程的当前位置必须要存储,以便在新函数运行完成后知道向哪里转移。
当存在函数调用的时候,需要存储的所有重要信息,诸如寄存器的值(对应变量的名字)和返回地址(它可从程序计数器得到,典型情况下计数器就是一个寄存器)等,都要以抽象的方式存放在“一张纸上“并被置于一个堆(pile)的顶部。然后控制转移到新函数,该函数自由地用它的一些值代替这些寄存器。如果它又进行其他函数的调用,那么它也遵循相同的过程。当函数要返回时,它查看堆(pile)顶部的那张”纸“并复原所有的寄存器。然后它进行返回转移。
显然,所有全部工作均可由一个栈来完成,而这正是在实现递归的每一种程序设计语言中实际发生的事实。所存储的信息或称为活动记录(activation record),或叫做栈帧(stack frame)。在典型情况下,需要做些微调整:当前环境是由栈顶描述的。因此,一条返回语句就可给出前面的环境(不用复制)。在实际计算机中的栈常常是从内存分区的高端向下增长,而在许多的系统中是不检测溢出的。
在正常情况下你不应该越出栈空间;发生这种情况通常是由失控递归(忘记基准情形)的指向引起。另一方面,某些完全合法并且表面上无害的程序也可以使你越出栈空间。如下代码所示。
/* Bad use of recusion: Printing a linked list */
/* No header */
void PrintList(List L)
{
if(L != NULL)
{
PrintElement(L->Element);
PirntList(L->Next);
}
}
该例程是用于打印一个链表,该例程完全合法,实际上是正确的。但不幸的是,如果这个链表含有20000个元素,那么就有表示最后一行嵌套调用20000个活动记录的一个栈。典型的情况是这些活动记录由于它们包含全部信息而特别庞大,因此这个程序很可能要越出空间。
这个程序称为尾递归(tail recursion),是使用极端不当的例子。尾递归涉及在最后一行的递归调用。尾递归可以通过将递归调用变成goto语句并在其前加上对函数每个参数的赋值语句而手工消除。它模拟了递归调用,因为没有什么需要存储;在递归调用结束之后,实际上没有必要知道存储的值。因此,我们就可以带着在一次递归调用中已经用过的那些值goto到函数的顶部。下面是改进后的代码。
/* Printing a linked list non-recursively */
/* Uses a mechanical translation */
/* No header */
void PrintList(List L)
{
top:
if(L != NULL)
{
PrintElement(L->Element);
L = L->Next;
goto top;
}
}
记住,你应该使用更自然的while循环结构。此处使用goto是为说明编译器如何自动地去除递归。
尾递归的去除是如此地简单,以致某些编译器能够自动地完成。但是即使如此,最好还是你的程序自己去除它。
递归总能被彻底除去(编译器是在转变成汇编语言时完成的),但是这么做是相当冗长乏味的。一般方法是要求使用一个栈,而且仅当你能够把最低限度的最小值放到栈上时,这个方法才值得一用。
虽然非递归程序一般说来确实比等价的递归程序要快,但是速度优势的代价却是由于去除递归而使得程序清晰性变得不足。