MYSQL索引优化(索引失效场景)
学习mysql是作为一名Java工程师必不可少的事情,但是我们只认识mysql的增删查改建表等等的sql语句其实远远不够的,对于进阶mysql来说,索引是一个很重要的部分。下面我们就来说一下在mysql中索引失效的几种场景吧。
首先先来看看测试的表结构
dept部门表

建立的索引(name,number,comment三个字段的复合索引)
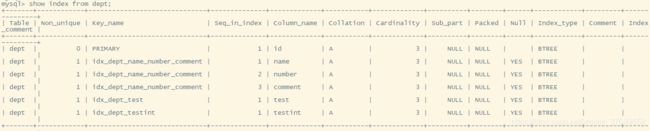
测试数据
1.遵从最左前缀原则
什么是最左前缀原则?其实所谓的最左前缀原则是对于复合索引来说的,一个复合索引是由两个或以上的列去构建的,此时就有了索引顺序的问题了,比如说我又一个student表,里面有id,name,age,score这四个字段,其中我给name,age,score建立了复合索引,那么我们在去根据索引去查询数据的时候where条件后面就要是name或者name=? and age = ?又或者name=? and age=? and score = ?,而不能是age=?或者score=?或者age=? and score=?,总而言之就是最左边的索引一定要是在第一位。我们下面用explain关键字来查看sql的执行计划。

我们这里关注的列有type,possible_keys可能用上的索引,key真正用上的索引,key_len(真实使用到的索引的长度,使用到的索引越多这个值越大),ref,row(在表中扫描了多少行,这值越少说明索引的效果越明显),extra。
我们能看到由于我们建立了name,age,comment的复合索引,而我们在where条件里面也确实使用到了这三个列的值作为条件并且顺序也符合了最左前缀原则,所以type为ref,表示这条sql语句使用了索引去查询数据。假如我们使用name和age作为where条件尼?结果

可以看出基本没什么变化,唯一变化的就是key_len的值变少了,说明我们的用到的索引少了。
假如我们不遵守最左前缀原则尼?

可以发现type变成了all了,即此时的查询为全表扫描,并没有使用到索引了。
而假如我们跳过了number字段的条件查询尼?

发现name这个索引依然被使用到,这说明了最左前缀原则就是最左边的索引至少一定要在第一位复合索引才能被使用到。
对索引进行大小条件的范围比较也是会使得后面的索引无效的,我们可以看
 可以看到完全使用上三个字段的索引时key_len是41,而现在是28,其实是comment这个字段的索引没有用上,因为number使用了“<”的条件范围比较,所以会使得后面的comment字段的索引无效。
可以看到完全使用上三个字段的索引时key_len是41,而现在是28,其实是comment这个字段的索引没有用上,因为number使用了“<”的条件范围比较,所以会使得后面的comment字段的索引无效。
其实我们可以自己造点数据去理解最左前缀原则,比如:
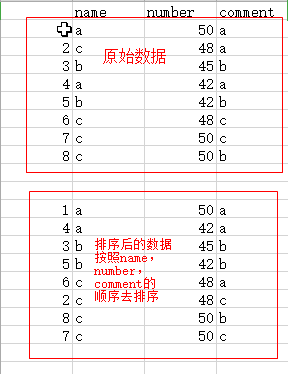
可以把排序后的数据当成就是name,number,comment三个字段的复合索引作用排序后的结果。当我们的查询语句的条件写成name = ‘c’ and comment = ‘c’,我们可以看到,根据索引能直接挑选出name=‘c’的数据行,然后此时我们如果c这一列的值是乱序的,导致了我们comment=‘c’的这一列的索引直接失效,相当扫描了全部name=‘c’的数据行中,comment=‘c’的数据行,而如果我们在name和comment中间加上number=50尼?先查出name=‘c’的数据行,然后在筛选出number=‘50’的数据行,然后此时得到的数据行对于comment这列来说的话就是有序的了,正是因为有序,所以查找comment=‘c’的数据行就不用扫描筛选下来的全部的数据了,此时comment这列的索引就生效了。
2.不要在索引列上进行函数或者四则运算以及(自动或手动)类型转换
在索引列上面进行函数或者加减乘除的四则运算也会使得这个索引失效。

type等于all,即全表扫描,即此时test列上的索引没有用到,索引失效。
3.尽量不要使用select *
在写查询语句的时候,尽量做到要什么字段就select什么字段,而且该字段最好与复合索引的字段顺序保持一致,不要直接用*来查出所有的字段,因为当我们查询的字段与复合索引的字段顺序保持一致的话,那么我们就可以直接去遍历我们的索引文件去查询数据,即全索引查询。

可以看到我们这里select的字段顺序与复合索引顺序一致,possible_keys为mysql优化器中察觉到我们的sql中并没有使用到索引去查询数据,因为我们并没有添加任何的查询条件,很明显这应该是一个全表查询呀,但是我们发现key的值是我们的复合索引,说明实际上该sql是使用到了索引去查询数据的,type也不是all,而是index(全索引查询),为什么尼?因为当我们select里面的字段和我们建立的复合索引的字段顺序一致时,mysql就会直接去我们遍历我们的索引,而索引其实就是一棵树(mysql是b+Tree),遍历索引就是遍历一棵树,树的叶子节点都包含了我们的数据对应的物理地址,这就是全索引查询。而select * 如果字段不是和复合索引的字段范围之内并且顺序一致的话,就会导致type为all,而index明显是比all性能要高的,因为遍历一棵树所需的时间复杂log2(n)与全表遍历的时间复杂度n来比较的话,明显是遍历索引比较快了,而且全表扫描所付出的磁盘IO消耗比全索引扫描要大得多。 而用到全索引扫描时,我们可以看到Extra该列里面有一个Using index的值表明该sql使用了全索引扫描。
5.不要在索引列中使用!=导致索引失效,进而导致全表扫描

type等于all,即全表扫描。
6.在索引列中使用like %字符串%会使得索引失效进而会全表扫描

type为all,即全表扫描。
那么如果我们换成yanfa%的话就能避免type等于all了

其实很容易理解,%yanfa%表示查找有任意yanfa这个字符串的数据,这样的话去匹配我们的索引的话就不能直接定位到哪条数据了,而只能通过全表扫描来进行一遍遍地区查看哪条数据有yanfa这个字符串了。而使用yanfa%去匹配的话,意思就是查找某列以yanfa开头的数据,至少mysql能通过索引去匹配yanfa开发的数据,这样得到的type就是range(范围查询)了。
7.字符串不加单引号会索引失效

这里的testint字段是一个varchar类型的字段,而且在这列上创建了普通索引,按道理来说应该是可以用上索引的,但是我们现在看到type是all,发生了全表扫描,即没有使用到索引。其实我们仔细看一下可以发现testint是一个varchar类型的字段,但是我们的where条件后面的0是一个int类型的值,在mysql底层会自动转换类型为varchar的类型,所以这句sql的查询是没问题的,问题就出在为什么varchar类型的字段,如果值是一个数字的话一定要加上单引号尼,这时我们再回到上面的第二点“自动或手动的类型转换也会使得索引失效”,而我们上面这种情况就属于自动的类型转换,mysql自动地帮我们进行了类型转换,导致该索引失效了。
那么如果我们的需求只能用%字符串%这种匹配方式来实现尼?这时我们回到这种方式的弊端来想,这种方式最大的坏处就是全表扫描,那么我们就优化成不要全表扫描就好了,这时我们可以想到使用覆盖索引去解决。

这时type就从all变成了index了。
8.尽量不要使用or关键字

使用or关键去添加查询条件的话会导致索引失效,type为性能最差的all。
上面说的索引失效的例子,我们在开发中是尽量避免,如果我们的需求只能这样去实现的话,那么我们不能因为这样会导致索引失效而不去使用,这样反而是得不偿失的尼。