【小甲鱼】python零基础入门学习笔记 03讲~43讲
本篇基于【莫烦】python基础教程,属于查漏补缺
建议学习顺序 小甲鱼->莫烦numpy&pandas
目录
- 第003讲 插曲之变量和字符串
- 课堂笔记
- 变量
- 变量 需要注意的地方
- 字符串
- 原始字符串
- 课后练习
- 第004讲 改进我的小游戏
- 课后练习
- 第005讲 闲聊之python的数据类型
- 课堂笔记
- python的一些数值类型
- 整型 int
- 浮点型 float
- 布尔类型 bool
- e记法(科学记数法)
- 类型转换
- 整数 int(x)
- 字符串 str()
- 浮点数 float()
- 获取关于类型的信息
- isinstance() 与 type() 区别:
- 判断函数
- 课后练习
- 第006讲 python之常用操作符
- 课堂笔记
- 加+ 减- 乘* 除/ 取余% 幂** 地板除法//
- 除法 /
- 地板除法 //
- 优先级问题
- 课后练习
- 第008讲 了不起的分支和循环2
- 课堂笔记
- python可以有效避免“悬挂else”
- 条件表达式(三元操作符)
- 断言(assert)
- 课后练习
- 第009讲 了不起的分支和循环3
- 课堂笔记
- for 循环
- range()
- 两个重要的语句 break & continue
- 课后练习
- 第010讲 列表:一个打了激素的数组1
- 课堂笔记
- 创建列表
- 向列表添加元素
- list.append(obj) 在列表末尾添加一个元素
- list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值
- list.insert(index, obj) 将指定对象插入列表的指定位置
- 第011讲 列表:一个打了激素的数组2
- 课堂笔记
- 从列表中获取元素
- 从列表删除元素
- list.remove(obj) 移除列表中某个值的第一个匹配项。
- del 语句 删除变量
- list.pop([index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
- 列表分片(slice)
- 课后练习
- 第012讲 列表:一个打了激素的数组3
- 课堂笔记
- 列表的一些常用操作符
- 列表的内置函数&方法
- 课后练习
- 第013讲 元组(tuple):戴上了枷锁的列表
- 课堂笔记
- 创建和访问一个元组
- 元组运算符
- 元组索引,截取
- 修改元组
- 删除元组
- 第014讲 字符串:各种奇葩的内置方法
- 课堂笔记
- python的字符串内建函数
- 课后练习
- 第015讲 字符串:格式化
- 课堂笔记
- 字符串格式化
- python字符串格式化符号:
- 格式化操作符辅助指令:
- [format 格式化函数](http://www.runoob.com/python/att-string-format.html)
- 数字格式化
- Python 的转义字符及其含义
- 课后练习
- 第016讲 序列!序列
- 课堂笔记
- 列表、元组和字符串的共同点
- 常见函数
- list([iterable]) 生成一个列表或把一个可迭代对象转换为列表
- max(list/tuple) 返回列表元素最大值
- sum(iterable[, start])返回序列iterable和可选参数start的总和
- sorted() 对所有可迭代的对象进行排序操作
- reversed(seq) 返回一个反转的迭代器
- enumerate(sequence, [start=0]) 用于将一个可遍历的数据对象组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
- zip 将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
- 课后练习
- 第017讲 函数:Python的乐高积木块
- 课堂笔记
- 定义一个函数
- 函数调用
- 参数
- 函数的返回值
- 课后练习
- 第018讲 函数:灵活即强大
- 课堂笔记
- 形参和实参
- 函数文档
- 关键字参数
- 默认参数
- 收集参数/可变参数/不定长参数
- 第019讲 函数:我的地盘听我的
- 课堂笔记
- 函数与过程
- 再谈谈返回值
- 局部变量与全局变量
- 第020讲 函数:内嵌函数和闭包
- 课堂笔记
- global 关键字
- 内嵌函数/内部函数
- 闭包
- 课后练习
- 第021讲 函数:lambda表达式
- 课堂笔记
- 匿名函数
- 语法
- lamda表达式的作用
- 过滤器filter()
- 语法
- 实例
- 映射map()
- 语法
- 实例
- 课后练习
- 第022讲 函数:递归是神马
- 课堂笔记
- 递归求阶乘
- 课后练习
- 第023讲 递归:这帮小兔崽子
- 课堂练习
- 斐波那契数列的实现
- 第024讲 递归:汉诺塔
- 课堂笔记
- 课后练习
- 第025讲 字典:当索引不好用时1
- 课堂笔记
- 创建字典
- 创建一个空字典
- 访问字典
- dict() 函数
- 语法
- 实例
- 第026讲 字典:当索引不好用时2
- 课堂笔记
- 字典内置函数&方法
- fromkeys()方法
- keys()方法
- values()方法
- items()方法
- get()方法
- has_key()方法
- clear()方法
- copy()方法
- Python 直接赋值、浅拷贝和深度拷贝解析
- pop() 方法
- popitem() 方法
- setdefault()方法
- update()方法
- 课后练习
- 第027讲 集合:在我的世界里,你就是唯一
- 课堂笔记
- 去重功能
- 判断元素是否在集合中存在
- 计算集合元素个数
- 集合内置方法完整列表
- 不可变集合 frozenset()函数
- 语法
- 实例
- 课后练习
- 第028讲 文件:因为懂你,所以永恒
- 课堂笔记
- 打开文件 open()函数
- 语法:
- 不同模式打开文件的完全列表:
- 文件对象方法
- 课后练习
- 第029讲 文件:一个任务
- 课堂笔记
- 任务
- 第030讲 文件系统:介绍一个高大上的东西
- 课堂笔记
- OS模块
- os模块中关于文件/目录常用的函数使用方法
- os.path模块中关于路径常用的函数使用方法
- 第031讲 永久储存:腌制一缸美味的泡菜
- 课堂笔记
- pickle模块
- 保存数据/读取数据
- 课后练习
- 第032讲 异常处理:你不可能总是对的1
- 课堂笔记
- 以下是 Python 内置异常类的层次结构:
- 第033讲 异常处理:你不可能总是对的2
- 课堂笔记
- try-except语句
- 语法
- 实例
- try-finally语句
- 语法
- 实例
- raise语句 引发异常
- 语法
- 实例
- 课后练习
- 第034讲 丰富的else语句及简洁的with语句
- 课堂笔记
- else语句
- if...else
- while和for循环
- 与异常处理语句搭配
- 简洁的with语句
- 第035讲 图形用户界面入门:EasyGui
- 课堂笔记
- 第036讲 类和对象:给大家介绍对象
- 课堂笔记
- 面向对象(Object Oriented)的特征
- 封装
- 继承
- 多态
- 课后练习
- 第037讲 类和对象:面向对象编程
- 课堂笔记
- self是什么?
- 魔法方法之__init__(self) 构造方法
- 公有、私有
- 课后练习
- 第038讲 类和对象:继承
- 课堂笔记
- 解决重写方法覆盖父类方法的问题
- 调用未绑定的父类方法(该方法不重要)
- 使用 super 函数(完美方法)
- 多重继承:就是同时继承多个父类的属性和方法。
- 课后练习
- 第039讲 类和对象:拾遗
- 课堂笔记
- 组合
- 类、类对象和实例对象
- 绑定
- 课后练习
- 第040讲 类和对象:一些相关的BIF
- 课堂笔记
- issubclass(class, classinfo)
- isinstance(object, classinfo)
- hasattr(object, name)
- getattr(object, name[ , default] )
- setattr(object, name, value)
- delattr(object, name)
- property(fget = None, fset = None, fdel = None, doc = None)
- 第041讲 魔法方法:构造和析构
- 课堂笔记
- __init__(self[,args...])
- __new__(cls[, ...])
- __del__(self)
- 第042讲 魔法方法:算术运算1
- 课后练习
- 第043讲 魔法方法:算术运算2
- 第044讲 魔法方法:简单定制
第003讲 插曲之变量和字符串
课堂笔记
变量
- 变量名就像我们现实社会的名字,把一个值赋值给一个名字时,TA会存储在内容中,称之为变量(variable),在大多数语言中,都把这种行为称为“给变量赋值”或“把值存储在变量中”。
- 不过python与大多数其他计算机语言的做法稍有不同,Ta并不是把值存储在变量中,而更像是把名字贴在值的上面。
- 所以有些python程序员会说“python”没有“变量”,只有“名字”。
变量 需要注意的地方
- 在使用变量之前,需要对其先赋值
- 变量名可以包括字母、数字、下划线,但变量名不能以数字开头。
- 大小写敏感,字母可以是大写或小写,但大小写是不同的。也就是说Fish和fish对python来说是完全不同的两个名字。
- 等号(=)是赋值的意思,左边是名字,右边是值,不可写反。
- 变量的命名理论可以取任何合法的名字,但作为一个优秀的程序员,请尽量给变量取一个专业一点儿的名字
字符串
- 到目前为止,我们所认识的字符串就是引号内的一切东西,我们也把字符串叫做文本,文本和数字是截然不同的
>>>5+8
13
>>>'5'+'8'
'58'
- 要告诉python你在创建一个字符串,就要在字符两边加上引号,可以是单引号或者双引号,但必须成对,不能一边单一边双。
- 想要打印单引号(双引号),需要使用转义符(\)进行转义,或者外层使用双引号(单引号)
>>>"Let's go!"
>>>>'Let\'s go!'
原始字符串
- 我们可以用反斜杠对自身进行转义
- 如果一个字符串中有很多个反斜杠,手动添加会很麻烦
- 原始字符串的使用使之非常简单,只需要在字符串前加一个英文字母r即可:
python 3.6之后又发生了变化 非bulitin字符会自动添加反斜杠 - 如果希望得到一个跨越多行的字符串,需要使用三重引号字符串(’‘‘balabala’‘’)同样,单引号与双引号需要成对出现,在IDLE中使用CTRL+j换行,直接打印换行符会变成\n,print()就能正常显示换行后的效果
>>> a='''白日依山尽,
黄河入海流。
欲穷千里目,
更上一层楼。'''
>>> print(a)
白日依山尽,
黄河入海流。
欲穷千里目,
更上一层楼。
>>> a
'白日依山尽,\n黄河入海流。\n欲穷千里目,\n更上一层楼。'
课后练习
- 在不上机的情况下,以下代码你能猜到屏幕会打印什么内容吗?
>>first = 520 >>second = '520' >>first = second >>print(first)
会打印:520,注:这里没有单引号括起来,但是他是一个字符串,因为使用 print() 打印,所以不包含单引号。可以试试直接>>>first,它是一个字符串的。
- 如果非要在原始字符串结尾输入反斜杠,可以如何灵活处理?
>>>str = r'C:\Program Files\FishC\Good''\\'
- 在这一讲中,我们说变量的命名需要注意一些地方,但小甲鱼在举例的时候貌似却干了点儿“失误”的事儿,你能看得出小甲鱼例子中哪里有问题吗?
Python 貌似不介意我们对内置函数进行赋值操作,所以这点我们以后就要注意啦,否则可能会出现以下的 BUG:
>>> print = 1
>>> print("I love FishC")
Traceback (most recent call last):
File "" , line 1, in <module>
print("I love FishC")
TypeError: 'int' object is not callable
第004讲 改进我的小游戏
课后练习
- Python3 中,一行可以书写多个语句吗?
可以,语句之间用分号;隔开即可,如:
>>> print("我爱你");print("你也爱我")
我爱你
你也爱我
- Python3 中,一个语句可以分成多行书写吗?
可以,一行过长的语句可以使用反斜杠或者括号分解成几行,如:
>>> 3 > 4 and \
1 < 2
False
或者:
>>> (3 > 4 and
1 < 2)
False
- 【该题针对有C或C++基础的朋友】请问Python的 and 操作符 和C语言的 && 操作符 有何不同?
没什么不同,就是长得不一样。
用C语言,判断语句这么写:if( x==1 && y==2 );用Python,只能这么写:if x==1 and y==2:
- 听说过“短路逻辑(short-circuit logic)”吗?
逻辑操作符有个有趣的特性:在不需要求值的时候不进行操作。这么说可能比较“高深”,即 ‘不做无用功’ 。如,表达式 x and y,需要 x 和 y 两个变量同时为真(True)的时候,结果才为真。 因此,如果当 x 变量得知是假(False)的时候,表达式就会立刻返回 False,而不用去管 y 变量的值。 这种行为被称为短路逻辑(short-circuit logic)或者惰性求值(lazy evaluation)。
动动手习题及答案:
动动手
0. 完善第二个改进要求(为用户提供三次机会尝试,机会用完或者用户猜中答案均退出循环)并改进视频中小甲鱼的代码。
import random
secret = random.randint(1,10)
guess = 0
count = 3
print("----------START------------")
while guess != secret and count > 0:
print("All 3 chances,and you still have",count,"chances")
temp = input("Please enter a number(1~10):")
guess = int(temp)
count = count - 1
if guess == secret:
print("wonderfully congraduation!")
else:
if guess > secret:
print("you guess gigger!")
else:
print("you guess smaller!")
if count > 0:
print("you have chance,you can continue!")
else:
print("No chance,byebye!")
print("Game over!")
第005讲 闲聊之python的数据类型
课堂笔记
- 变量没有数据类型,python有
- 字符串的相加为拼接,数字的相加得到和
python的一些数值类型
整型 int
python2分为整型和长整型,python3 后大小只受虚拟内存限制
浮点型 float
与整型的区别在于有没有小数点
布尔类型 bool
特殊的整型,TRUE相当于1,FALSE相当于0,可以进行四则运算,但不推荐这么做
e记法(科学记数法)
为浮点型
>>>1e-2
0.01
类型转换
整数 int(x)
- 不能出现中文、英文等非数字
- 浮点数转化为整型采取截断处理 int(5.99)=5
字符串 str()
浮点数 float()
整数转浮点数默认产生一位小数 float(1)=1.0
获取关于类型的信息
- type() 返回函数的类型
-** isinstance(object, classinfo) **函数来判断一个对象是否是一个已知的类型
object – 实例对象。
classinfo – 可以是直接或间接类名、基本类型或者由它们组成的元组。
返回值
如果对象的类型与参数二的类型(classinfo)相同则返回 True,否则返回 False。
>>>a = 2
>>> isinstance (a,int)
True
>>> isinstance (a,str)
False
>>> isinstance (a,(str,int,list)) # 是元组中的一个返回 True
True
isinstance() 与 type() 区别:
type() 不会认为子类是一种父类类型,不考虑继承关系。
isinstance() 会认为子类是一种父类类型,考虑继承关系。
class A:
pass
class B(A):
pass
isinstance(A(), A) # returns True
type(A()) == A # returns True
isinstance(B(), A) # returns True
type(B()) # returns B
如果要判断两个类型是否相同推荐使用 isinstance()。
判断函数
x.isalnum() 所有字符都是数字或者字母,为真返回 Ture,否则返回 False。
x.isalpha() 所有字符都是字母,为真返回 Ture,否则返回 False。
x.isdigit() 所有字符都是数字,为真返回 Ture,否则返回 False。
x.islower() 所有字符都是小写,为真返回 Ture,否则返回 False。
x.isupper() 所有字符都是大写,为真返回 Ture,否则返回 False。
x.istitle() 所有单词都是首字母大写,为真返回 Ture,否则返回 False。
x.isspace() 所有字符都是空白字符,为真返回 Ture,否则返回 False。
课后练习
- 你知道为什么布尔类型(bool)的 True 和 False 分别用 1 和 0 来代替吗?
answer:计算机只认识二进制,即0和1
3 .我们人类思维是习惯于“四舍五入”法,你有什么办法使得 int() 按照“四舍五入”的方式取整吗?
answer:int(a + 0.5)
>>> a = 6.1
>>> int(a + 0.5)
6
>>> a = 6.5
>>> int(a + 0.5)
7
动动手
1 写一个程序,判断给定年份是否为闰年。(注意:请使用已学过的 BIF 进行灵活运用)
这样定义闰年的:能被4整除但不能被100整除,或者能被400整除都是闰年。
print('----闰年计算器----')
temp = input('请输入年份XXXX,如2014:')
while temp.isdigit()==False :
temp = input('输入错误,请重新输入:')
year = int(temp)
if year/4==int(year/4) and (year/100!=int(year/100) or year/400==int(year/400)):
print(year,'年是闰年')
else:
print(year,'年不是闰年')
print('结束!')
第006讲 python之常用操作符
课堂笔记
加+ 减- 乘* 除/ 取余% 幂** 地板除法//
除法 /
python2 中整数/整数=整数,为地板除法,向下取整,例如:10/8=1
python3 后变为普通除法
地板除法 //
浮点数/浮点数=整数
优先级问题
- 先乘除后加减,括号里的先运算
- 比较操作符优先于逻辑操作符
- 一元操作符/单目操作符:负号-
二元操作符/双目:and 之类涉及两个数的操作符 - 幂运算优先级比左侧的一元操作符高,比右侧的一元操作符低
>>>-3**2
-9
>>>3**-2
0.1111111111111111
- 幂运算右侧一元操作符>幂运算(**)>正负号(+x -x)>算术操作符(* / // + -)>比较操作符(< <= > >= == !=)>逻辑运算符(not>and>or)

课后练习
1.a < b < c 事实上是等于?
answer:(a < b) and (b < c)
4 请用最快速度说出答案:not 1 or 0 and 1 or 3 and 4 or 5 and 6 or 7 and 8 and 9
answer:4
优先级顺序:not > and > or
(not 1 )or (0 and 1) or (3 and 4) or (5 and 6) or (7 and 8 and 9)
考虑短路逻辑:0 or 0 or 4 or 6 or 9 = 4
注:
1.在纯and语句中,如果每一个表达式都不是假的话,那么返回最后一个,因为需要一直匹配直到最后一个。如果有一个是假,那么返回假
2.在纯or语句中,只要有一个表达式不是假的话,那么就返回这个表达式的值。只有所有都是假,才返回假
3.总而言之,碰到and就往后匹配,碰到or如果or左边的为真,那么就返回or左边的那个值,如果or左边为假,继续匹配or右边的参数。 例如:
(False or 5) 输出5
(5 or False) 输出5
(0 or False) 输出False
(True or 3) 输出True
(2 or True) 输出2
(0 or True) 输出True
(True or False)输出True
(True and 4) 输出4
(1 and True) 输出后者
(False and 1) 输出False
(1 and False) 输出False
(0 and True) 输出0
(not 3) 输出False
(not 0) 输出True
第008讲 了不起的分支和循环2
课堂笔记
python可以有效避免“悬挂else”
强制使用缩进决定if else对应关系避免了“悬挂else”问题
条件表达式(三元操作符)
- 有了这个三元操作符的条件表达式,你可以使用一条语句来完成以下的条件判断和赋值操作:
x,y = 4,5
if x < y:
small = x
else:
small = y
例子可以改进为:
small = x if x < y else y
断言(assert)
- assert 这个关键字我们称之为“断言”,当这个关键字后边的条件为假的时候,程序自动崩溃并抛出AssertionError的异常
- 举个例子
>>>assert 3 > 4
- 一般来说我们可以用Ta在程序中置入检查点,当需要确保程序中的某个条件一定为真才能让程序正常工作的话,assert关键字就非常有用了。
课后练习
2.假设有 x = 1,y = 2,z = 3,请问如何快速将三个变量的值互相交换?
answer: x,y,z = y,z,x
4.你听说过成员资格运算符吗?
answer:'in’用来检查某一个值是否在list中,在则返回True,否则返回False
>>> a = [1,2,3,4]
>>> b = 3
>>> b in a
True
动动手
1.Python 的作者在很长一段时间不肯加入三元操作符就是怕跟C语言一样搞出国际乱码大赛, 蛋疼的复杂度让初学者望而生畏,不过,如果你一旦搞清楚了三元操作符的使用技巧, 或许一些比较复杂的问题反而迎刃而解。
请将以下代码修改为三元操作符实现:
Code:if x < y and x < z: small = x else: if y < z: small = y else: small = z
small = x if (z Python for循环可以遍历任何序列的项目,如一个列表或者一个字符串。 1.下面的循环会打印多少次”I Love FishC”? answer:错误,in 是成员资格运算符,不能迭代 TypeError: ‘int’ object is not iterable 6.什么情况下我们要使循环永远为真? answer:比如用于游戏的实现,游戏只要运行着就要时刻接收用户的输入,用永远为真来确保游戏一直‘’在线‘’。 动动手 注:while count: 由于while执行条件为True,当count变为0 =False 循环停止 数组:同种类型的数据放在一起,通过数组的下标进行索引 注:list.XXX 点后面的称之为方法,len(),带括号的称为函数 obj – 添加到列表末尾的对象。 用一个列表扩展另一个列表 index – 对象 obj 需要插入的索引位置。 没有匹配项会报错 利用索引值,每次我们可以从列表获取一个元素,如果一次性需要获取多个元素,利用列表分片可以实现这个要求。 或者 copy() 方法跟使用切片拷贝是一样的: clear() 方法用于清空列表的元素,但要注意,清空完后列表仍然还在哦,只是变成一个空列表。 居然分别打印了0到9各个数的平方,然后还放在列表里边了有木有?! 列表推导式(List comprehensions)也叫列表解析,灵感取自函数式编程语言 Haskell。Ta 是一个非常有用和灵活的工具,可以用来动态的创建列表,语法如: 相当于 问题:请先在 IDLE 中获得下边列表的结果,并按照上方例子把列表推导式还原出来。 列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。 0.注意,这道题跟上节课的那道题有点儿不同,回答完请上机实验或参考答案。 如果不上机操作,你觉得会打印什么内容? answer:[1,2,3,4,5] 第一个A指向了B的内存地址;第二个B重新开辟了一个内存地址 与字符串一样,元组之间可以使用 + 号和 * 号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。 因为元组也是一个序列,所以我们可以访问元组中的指定位置的元素,也可以截取索引中的一段元素, 步长的负号就是反向,从右到左取值. 类似于字符串,元组中的元素值是不允许修改的,但我们可以对元组进行截取后连接组合。 截取后生成了新的元组,并把temp的标签给了新元组,原来的元组还在存储位置,失去标签后不久会被回收器清除 元组中的元素值是不允许删除的,要删除单个元素的话可以使用截取的方式,但我们可以使用del语句来删除整个元组 方法一:三引号 方法二:\ 方法三:每一行一对引号 三引号字符串不赋值的情况下,通常当作跨行注释使用。 会报错是因为在字符串中,我们约定“\t”和“\r”分别表示“横向制表符(TAB)”和“回车符”(详见:http://bbs.fishc.com/thread-39140-1-1.html),因此并不会按照我们计划的路径去打开文件。 Python 为我们铺好了解决的道路,只需要使用原始字符串操作符(R或r)即可: 动动手: Python 支持格式化字符串的输出 。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。 如下实例: print “My name is %s and weight is %d kg!” % (‘Zara’, 21) 实例 也可以设置参数: 也可以向 str.format() 传入对象: 实例 输出结果为: 下表展示了 str.format() 格式化数字的多种方法: ^, <, > 分别是居中、左对齐、右对齐,后面带宽度, : 号后面带填充的字符,只能是一个字符,不指定则默认是用空格填充。+ 表示在正数前显示 +,负数前显示 -;(空格)表示在正数前加空格 输出结果为: 如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。 所谓迭代,是重复反馈过程的活动,其目的通常是为了接近并到达所需的目标或结果。每一次对过程的重复被称为一次“迭代”,而每一次迭代得到的结果会被用来作为下一次迭代的初始值。 函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。 return语句[表达式]退出函数,选择性地向调用方返回一个表达式。不带参数值的return语句返回None。 使用函数: 如果你回答两个,那么恭喜你错啦,答案是0,因为类似于这样的写法是错误的! 我想你如果这么写,你应该是要表达这么个意思: 函数调用使用关键字参数来确定传入的参数值。 使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。 以下实例在函数 printme() 调用时使用参数名: 以上实例输出结果: 给定了默认值的参数 以上实例输出结果: 你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述2种参数不同,声明时不会命名。基本语法如下: 加了星号(*)的变量名会存放所有未命名的变量参数。把传入的参数用元组打包存放起来。收集参数后面如果还有参数,必须要通过关键字参数声名或者给默认值,否则所有参数都给了收集参数,函数会报错。 以上实例输出结果: 输出: 在许多编程语言中,函数(function)是有返回值的,过程(procedure)是简单、特殊并且没有返回值的。python严格来说只有函数,没有过程 不用关注返回值的类型,可以通过返回列表来返回多个值,或者用逗号隔开,python默认发包成元组后返回 定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。 局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。即全局变量若在函数内被赋值,则采取屏蔽(shadowing)的机制,生成一个名字同全局变量一模一样的局部变量,两者不互相影响。如下实例: 以上实例输出结果: 函数内是局部变量 : 30 想要把局部变量变为全局变量,需要在变量前加global关键字。 运行结果 4.请问如何访问funIn() 直接调用funOut() 5.请问如何访问funIn() python 使用 lambda 来创建匿名函数。 lambda函数的语法只包含一个语句,如下: 以上实例输出结果: filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换。 该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。 filter(function, iterable) 过滤出列表中的所有奇数: 结合lambda函数能够更加简洁 map() 会根据提供的函数对指定序列做映射。 第一个参数 function。以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。 map(function, iterable, …) 3.你可以利用filter()和lambda表达式快速求出100以内所有3的倍数吗? 4.还记得列表推导式吗?完全可以使用列表推导式代替filter()和lambda组合,你可以做到吗? 在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。 来修改递归深度为1000层 2.思考一下,按照递归的特性,在编程中有没有不得不使用递归的情况? 例如汉诺塔,目录索引(因为你用元不知道这个目录里边是否还有目录),快速排序(二十世纪十大算法之一),树结构的定义等如果使用递归,会事半功倍,否则会导致程序无法实现或相当难以理解。 4.请聊一聊递归的优缺点 优点: 递归明显要慢不少 1,请写一个函数get_digits(n),将参数n分解出每个位的数字并按顺序存放到列表中。举例:get_digits(12345)==>[1,2,3,4,5] 字典是另一种可变容器模型,且可存储任意类型对象。 字典的每个键值 key=>value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示: d = {} 把相应的键放入熟悉的方括弧,如下实例: 以上实例输出结果: dict() 函数用于创建一个字典。 class dict(**kwarg) dict()严格来说不是一个BIF,而是工厂函数(类型),之前的str(),int(),list(),tuple()…都是工厂函数 用于创建一个新字典,以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值。 语法 实例 以上实例输出结果为: 以列表返回一个字典所有的键。 以上实例输出结果为: 以列表返回字典中的所有值。 以上实例输出结果为: 以列表返回可遍历的(键, 值) 元组数组。 字典值 : [(‘Google’, ‘www.google.com’), (‘taobao’, ‘www.taobao.com’), (‘Runoob’, ‘www.runoob.com’)] 返回指定键的值,如果值不在字典中返回默认值。 以上实例输出结果为: 用于判断键是否存在于字典中,如果键在字典dict里返回true,否则返回false。 用于删除字典内所有元素。 返回一个字典的浅复制。 1、b = a: 赋值引用,a 和 b 都指向同一个对象。 删除字典给定键 key 及对应的值,返回值为被删除的值。key 值必须给出。 否则,返回 default 值。 随机返回并删除字典中的一对键和值。如果字典已经为空,却调用了此方法,就报出KeyError异常。 和get() 方法类似, 如果键不存在于字典中,将会添加键并将值设为默认值。 Value : 菜鸟教程 把字典dict2的键/值对更新到dict里。 以上实例输出结果为: 0.Python的字典是否支持一键(key)多值(value)? 不支持 1.字典中如果试图为一个不存在的键(key)赋值会怎样? 会自动创建对应的键,并添加相应的值进去。 3.python对键和值有没有类型限制》 键必须是可哈希(Hash)的对象,不能是可变类型(变量、列表、字典本身等) 不能保持列表的顺序 计算集合 s 元素个数。 返回一个冻结的集合,冻结后集合不能再添加或删除任何元素。 class frozenset([iterable]) 4.请问set1 = {[1,2]}和set1 = set([1,2])是一样的吗? 不一样。前者报错,[1,2]是列表,列表地址不是固定的,不是可哈希的对象。后者是包含两个元素1,2的集合。集合与字典的存储方式一样。相同元素得到的哈希值(存放地址)是相同的,所以在集合中所有相同的元素都会被覆盖掉,因此有了集合的唯一性。哈希函数计算的地址不可能是按顺序排放的,所以集合才强调是无序的! 5.打开你的IDLE,输入set1 = {1,1.0},你发现什么? 因为python的哈希函数计算相同元素的哈希值,也就是地址是一样的。 你必须先用Python内置的open()函数打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写。 file object = open(file_name [, access_mode][, buffering]) 5.如何跌代打出文件对象(f)中的每一行数据? 8.还是视频中的那个演示文件(record.txt),请问为何f.seek(45,0)不会出错,但f.seek(46)就出错了呢? f.seek()定位的文件指针是按字节为单位计算的,文件record.txt以GBK进行编码,一个汉字为两字节,f.seek(45)的位置恰好位于字符“小”的开始位置,故可正常打印,而f.seek(46)定位的位置位于字符“小”的中间位置,而按照GBK的编码规则将无法将其解码! 9.试尝试将文件(OpenMe.mp3)打印到屏幕上。 运行结果如下: 10.编写代码,将上一题中的文件(OpenMe.mp3)保存为新文件(OpenMe.txt) 将文件(record.txt)中的数据进行分割并按照以下规律保存起来: 我们所知道常用的操作系统就有:Windows,Mac OS,Linux,Unix等,这些操作系统底层对于文件系统的访问工作原理是不一样的,因此你可能就要针对不同系统来考虑使用哪些文件系统模块,这样的做法是非常不友好且麻烦的,因此这样就意味着你的程序运行环境一改变,你就要相应的去修改大量的代码来应付。 有了OS模块,我们不需要关心什么操作系统下使用什么模块,OS模块会帮你选择正确的模块并调用。 0.pickle的实质是什么? 利用一些算法将你的数据对象“腌制”成二进制文件,存储在磁盘上,当然也可以放在数据库或通过网络传输到另一台计算机上。 Python 标准异常总结 BaseException try语句一旦检测出异常,剩下的语句讲不会被执行 try: 捕获所有异常,部分类别输出(不建议): 同时捕获多个异常: try: raise [Exception [, args [, traceback]]] 3.把文件关闭放在finally语句块中执行还是会出现问题,像下边这个代码,当前文件夹中并不存在My_File。txt这个文件,那么程序执行起来会发生什么事情呢?你有办法解决这个问题吗? 出错信息: 大多数编程语言来说,else语句都只能跟if语句搭配。但在Python里,else语句的功能更加丰富。 要么怎样,要么不怎样 干完了能怎样,干不完就别想怎样 如果没有出错,则打印出‘没有任何错误!’ 打开文件又要关闭文件,还要关注异常处理有点烦人,所以Python提供了一个with语句,利用这个语句抽象出文件操作中频繁使用的try/except/finally相关的细节。 对文件使用with语句,将可以大大减少你的代码量,而且你再也不用担心文件打开了忘记关闭的尴尬了(with会自动帮你关闭文件)。 https://javablogs.iteye.com/blog/2098369 对象=属性(静态)+方法(动态) 上面的语句就定义好了一个类。 调用类和调用函数相同,Python的类名以大写字母开头,函数以小写字母开头,方便区分。 这里实例化了一个对象,并用 tt 这个变量给指过去,下面的语句用于调用对象里的方法: 这里我们自定义一个 list 的子类 Mylist,我们发现子类 Mylist 也能调用父类 list 的方法。 不同对象对同一方法相应不同的行动(名字一样,实现的功能不同) 答:变量(属性)和函数(方法)。 答:类和对象的关系就如同模具和用这个模具制作出的物品之间的关系。一个类为它的全部对象给出了一个统一的定义,而他的每个对象则是符合这种定义的一个实体,因此类和对象的关系就是抽象和具体的关系。 答:叮当猫,咖啡猫,Tom(Tom&Jerry),Kitty(Hello Kitty)…… 答:正确的做法是应该尽可能的抽象,因为这样更符合面向对象的思维。 答:方法跟函数其实几乎完全一样,但有一点区别是方法默认有一个 self 参数。 动动手 Python 的 self 相当于 C++ 的 this 指针。我们知道,类是图纸,而由类实例化出的对象才是真正可以住人的房子,根据一张图纸就可以设计出成千上万的房子,这些房子都长得差不多,因为它们都来自于同一张图纸,但是它们都有不同的主人,每个人都只可以回到自己的家,self 就相当于每个房子的门牌号,有了 self,就可以轻松的找到自己的房子,Python 的 self 参数就是同样的道理,由同一个类可以生成无数个对象,这些对象都长得很相似,因为它们都是来源于同一个类的属性和方法,当一个对象的方法被调用的时候,对象会将自身作为第一个参数传给 self 参数,接收到这个 self 参数的时候,Python 就知道你是哪一个对象在调用方法了。举例说明: 我们生成两个实例化对象 a 和 b,这里都调用 kick() 方法,但是实现结果不一样,是因为 a.kick() 和 b.kick() 都有一个隐藏属性 self,会找到各自对应的 name,这些都是由Python 在背后默默的工作,你只需要在类的定义的时候把 self 写进第一个参数。 类中方法给变量赋值时只有有self.的前缀才能被外界单独调用。 .魔法方法:如果你的对象实现了这些方法中的某一个,那么这个方法在特殊情况下被Python所调用。Python的这些具有魔力的方法总是会被双下划线所包围。 init(self)方法的魔力体现在只要实例化一个对象的时候,那么这个方法就会在对象被创建的时候自动调用。有过C++基础的同学就会知道,这就是构造函数。 其实实例化对象的时候是可以存入参数的,这些参数会自动的存入到__init__(self)方法中, init(self,param1,param2…) #(默认不重写的形式就是__init__(self)) 也就是我们这个魔法方法中,我们可以通过重写这个方法(如上)来自定义对象的初始化操作,说起来比较复杂,举例说明: 默认上来说,对象的属性和方法都是公开的,都是共有的,我们可以通过点(.)操作符来进行访问,举例说明: 为了实现类似于私有变量的特征,Python内部采用了一种叫做 name mangling(名字改编,名字重整)的技术,在Python 中定义私有变量只主要在变量名或函数名前加上“__”两个下划线,那么这个函数或变量就会为私有的了。 这时,p.__name 和 p.name 都无法访问对象的name属性,因为它们都找不到了,这样在外部就会将变量名隐藏起来,理论上如果要访问,就要从内部进行,可以这样写: 上面的方法只是理论上的,其实只要你琢磨一下,name mangling 技术的意思就是名字改编、名字重整,那么应该不难发现,Python只是动了一下手脚,它把双下划线开头的变量改了名字而已,它自动是改成了** _类名__变量名**(单下划线+类名+双下划线+变量名),如下 : 所以说,Python的私有机制是伪私有,Python是没有权限控制的,所以变量是可以被外部调用的。 答:__init__方法会在类实例化时被自动调用,我们称之为魔法方法。你可以重写这个方法,为对象定制初始化方案。 答:首先你要明白类、类对象、实例对象是三个不同的名词。我们常说的类指的是类定义,由于“Python无处不对象”,所以当类定义完之后,自然就是类对象。在这个时候,你可以对类的属性(变量)进行直接访问(MyClass.name)。 动动手 语法:class 类名(父类名): 被继承类被称为基类、父类或超类,继承者被称为子类,一个子类可以继承它的父类的任何属性和方法。举例说明: 需要注意的是:如果子类中定义与父类同名的方法或属性,则会自动覆盖父类对应的方法和属性。 这样就不会报错了,需要注意的是, Fish.init(self) 中的 self 是调用它的父类的方法,但是这个 self 是子类的实例对象。 就相当于:Fish.init(shark)。实际上,在上面出错的程序代码运行之后,我们输入下面的语句可是可以的:这里就相当于重新进行了一次初始化。 使用super 函数能够帮我们自动找到父类的方法,而且还会为我们传入 self 参数,super 函数可以完美的替换上述的方法。 super().init(),super 函数的超级之处就在于你不用给定任何父类的名字,如果继承有多重继承或者父类的名字太过复杂的时候,也不用给出父类的名字,就可以自动帮你一层一层的找出它所有父类里面对应的方法,由于你不需要给出父类的名字,也就意味着如果你要改变类的继承关系,你只需要修改 class Shark(Fish): 里面的父类的名字即可。 语法:class 类名(父类1名,父类2名…): 多重继承可以同时继承多个父类的属性和方法,但是多重继承很容易导致代码混乱,所以当你不确定你真的必须要使用多重继承的时候,请尽量避免使用。 答:会报错,因为 init 特殊方法不应当返回除了 None 以外的任何对象。 答:覆盖父类方法,例如将函数体内容写 pass,这样调用 fly 方法就没有任何反应了。 答:多重继承容易导致重复调用问题,下边实例化 D 类后我们发现 A 被前后进入了两次(有童鞋说两次就两次憋,我女朋友还不止呢……)。 为了让大家都明白,这里只是举例最简单的钻石继承问题,在实际编程中,如果不注意多重继承的使用,会导致比这个复杂N倍的现象,调试起来不是一般的痛苦……所以一定要尽量避免使用多重继承。 答:super 函数再次大显神威。 所谓的组合,就是把类的实例化放到新类里面,那么它就把旧类给组合进去了,不用使用继承了,没有什么风险了。组合一般来说就是把几个没有继承关系,没有直线关系的几个类放在一起,就是组合。要实现纵向关系之间的类,就使用继承。 Python 的特性还支持另外一种很流行的编程模式,叫做 Mix-in,叫做混入的意思,有兴趣的可以参见-> Python Mixin 编程机制。 我们这里有一个 E 类,只有一个属性 count ,初始化为0。实例化一个 a,一个 b,一个 c,显然 a.count = 0,b.count = 0,c.count = 0。如果对 c.count += 10,现在 c.count = 10,但是 a.count = 0,b.count = 0。因为 E 是一个类,在写完 E 之后就变成了一个类对象,因为Python无处不对象,所有的东西都是对象,方法也是对象,所以我们这里 E.count = 0 也是等于 0 。此时我们对这个类对象加等于100 , E.count += 100,此时 a.count = 100,b.count = 100,但是 c.count = 10。其实是因为 c.count += 10 这里 c.count 被赋值的时候,我们是对实例化对象 c 的属性进行赋值,相当于我们生成了一个 count 来覆盖类对象的 count,如图(C替换为E): 类定义到类对象,还有实例对象a,b,c,需要注意的是,类中定义的属性都是静态属性,就像 E 里面的count,类属性和类对象是相互绑定的,并不会依赖于下面的实例对象,所以当 c.count += 10 的时候,并不会影响到 E,只是改变了 c 自身,因为在 c.count += 10 的时候,是实例对象 c 多了一个count 的属性,也就是实例属性,它把类属性给覆盖了。这在以后还会继续讲解,在此之前,我们先谈一下:**如果属性的名字和方法相同时,属性会把方法覆盖掉。**举例说明: c.x = 1 是实例化后的 c ,创建了一个 x 的属性,这时如果要调用 它的函数 x() 就会报错,出错信息说:整型是不能被调用的。 这就是初学者容易发生的一个问题,如果属性的名字和方法名相同,属性会覆盖方法。为了避免名字上的冲突,大家应该遵守一些约定俗成的规矩: Python 严格要求方法需要有实例才能被调用,这种限制其实就是Python 所谓的绑定概念。 删除CC之后CC中的方法仍然能被调用的原因是:主函数进程在内存中的栈区,类和对象在内存中的堆区,类在堆区中的方法区,方法区存放的是代码静态变量,静态方法,字符串常量,类对象和类的方法存放在不同的位置,所以删除时不会连带。创建实例对象后,系统在内存的堆开辟新的一块内存区域存放实例对象,对象的名字只是指向这个内存堆得地址而已,类中的静态变量静态方法还在方法区内,随着程序的结束才会消失。而创建的实例对象是被python的垃圾回收机制回收的。 答:num 和 count 是类属性(静态变量),x 和 y 是实例属性。大多数情况下,你应该考虑使用实例属性,而不是类属性(类属性通常仅用来跟踪与类相关的值)。 答:因为 Python 严格要求方法需要有实例才能被调用,这种限制其实就是 Python 所谓的绑定概念。所以 Python 会自动把 bb 对象作为第一个参数传入,所以才会出现 TypeError:“需要 0 个参数,但实际传入了 1 个参数“。 正确的做法应该是: 动动手 方法用于判断参数 class 是否是类型参数 classinfo 的子类。 检查一个实例对象 object 是否属于一个类 classinfo, 另外,Python 提供了几个BIF让我们访问对象的属性: attr = attribute:属性。 返回对象指定的属性值。如果指定的属性不存在,如果你有设置 default,它会把这个default 参数打印出来,否则会抛出一个AttributeError异常。 设定对象中指定属性的值,如果指定的属性不存在,会新建一个新的属性,并给其赋值。 删除对象中指定的属性,如果属性不存在,就抛出一个AttributeError异常。 俗话说,条条大路通罗马。Python 其实提供了好几个方式供你选择,property 是一个BIF,作用是通过属性设置属性 property 函数的作用就是设置一个属性,这个属性就是去操作定义好的属性, 举例说明: property 的优势:举个例子,在上面这个例子中,这个程序慢慢写的很复杂了,有一天,你想把这个程序进行大改,把函数名进行改写,如果没有 property,那你提供给用户的调用接口就需要修改,就会降低用户体验,但是有了property,问题就不存在了,因为提供给用户的接口都是 x,程序里面无论如何修改,property里面的参数跟着改进行了,用户还是只用调用 x 来设置或者获取 size 属性就可以了。 其实__init__方法并不是实例化对象时第一个被调用的魔法方法,第一个被调用的应该是__new__(cls[, …])方法,它跟其他的魔法方法不同,第一个参数不是self,而是class,它在init之前被调用,它后边有参数的话,会原封不动的传给__init__方法,new方法需要一个实例对象作为返回值,需要返回一个对象,通常是返回cls这个类的实例对象,也可以返回其它类的对象,需要说明的是,new方法平时是极少去重写的,一般用Python默认的方案即可,但是用一种情况我们需要重写new魔法方法,就是继承一个不可变类型的时候,又需要进行些改的时候,那么它的特性就显得尤为重要了。 这里继承的父类 str 是不可修改的,我们就不能在init中对其自身进行修改,所以我们就需要在new的时候进行一个替换,然用替换后的调用str的new方法做一个返回。如果这里的new没有做重写的话,就会自动调用父类str的new。 依照Python官方文档的说法,__new__方法主要是当你继承一些不可变的class时(比如int, str, tuple), 提供给你一个自定义这些类的实例化过程的途径。还有就是实现自定义的metaclass。 但运行后会发现,结果根本不是我们想的那样,我们任然得到了-3。这是因为对于int这种 不可变的对象,我们只有重载它的__new__方法才能起到自定义的作用。 通过重载__new__方法,我们实现了需要的功能。 如果我们说init和new方法是对象的构造器的话,那么Python也提供了一个析构器,就是del方法,当对象需要被销毁的时候,这个方法就会自动的被调用,但要注意的是,并非我们写 del x ,就会调用 x.__del__(),del方法是垃圾回收机制,当没有任何变量去引用这个对象时,垃圾回收机制就会自动将其销毁,这时候才会调用对象的del方法。: 实例化的时候就会调用__init__方法,然后有c1 和 c2 两个变量指向这个对象,但并不是 del c1 或者 del c2 的时候就会调用__del__方法,而是当指向该对象的变量都被del的时候,才会被自动调用,来销毁这个对象。 在Python2.2之前,类和类型是分开的,在Python2.2之后,作者试图对这两个东西进行统一,做法就是将 int()、float()、str()、list()、tuple() 这些 BIF 转换为工厂函数,那什么是工厂函数呢? 我们试图演示一下: 然后我们发现: Python的魔法方法还提供了让你自定义对象的数值处理,通过对我们这些魔法方法进行重写,你可以自定义任何对象间的算术运算。 例如: 发现了没,我在这里对原有 int 的加法和减法进行了改写,把加法变为减法,减法变为加法。 动动手 上节课我们介绍了需要关于算术运算的魔法方法,意思是当你的对象进行相关的算术操作的时候,自然而然的就会触动对应的魔法方法,一旦你重写了这些魔法方法,那么Python就会根据你的意图进行计算。 通过对指定的魔法方法进行重写,你完全可以让Python根据你的意图去实现程序,我们来举个例子: 我们重写 int 函数,偷偷摸摸的把 int 覆盖掉,重写之前,它是继承了正常的 int,很明显,当我们进行加法操作时,给它一个减法操作的结果,然后我们的类还把原来的 int 覆盖掉。 其它方法还是继承了正常的 int,只有加法操作变为了减法。第009讲 了不起的分支和循环3
课堂笔记
for 循环
for 目标 in 表达式:
循环体range()
两个重要的语句 break & continue
for i in range(10):
while i%2 !=0:
print(i)
continue
i+=2
print(i)
#不断输出1的死循环
"""""""""""""""""""
for i in range(10):
if i%2 !=0:
print(i)
continue
i+=2
print(i)
#输出结果 2、1、4、3、6、5、8、7、10、9
课后练习
for i in 5:
print('I Love FishC')
0.设计一个验证用户密码程序,用户只有三次机会输入错误,不过如果用户输入的内容中包含"*"则不计算在内。
Code:print('======================用户密码验证系统====================')
password = '5201314'
count = 3
while count:
key = input('请您输入密码:')
if key == password:
print('祝贺,密码正确!!!')
print('验证成功!!!')
break
elif "*" in key:
print('抱歉,密码中不能含有*,您还有',count,'次机会',end = ',')
continue
else:
print('密码输入错误!您还有',count - 1,'次机会',end = ',')
count -= 1
第010讲 列表:一个打了激素的数组1
课堂笔记
python的变量没有数据类型,因此加入了更为强大的列表创建列表
member=['小甲鱼','小布丁','黑夜','迷途','怡静']
mix=[1,'小甲鱼',3.14,[1,2,3]]
empty=[]
向列表添加元素
函数与方法的区别
1.与类和实例无绑定关系的function都属于函数(function);
2.与类和实例有绑定关系的function都属于方法(method);
3.函数的调用:函数的调用是直接写 函数名(函数参数1,函数参数2,…) ;
4.方法的调用:方法是通过对象点方法调用的(这里是指对象方法)list.append(obj) 在列表末尾添加一个元素
>>>member.append('福禄娃娃')
>>>member
['小甲鱼', '小布丁', '黑夜', '迷途', '怡静', '福禄娃娃']
list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值
seq – 元素列表。>>>member.extend(['竹林小溪','Crazy迷恋'])
>>>member
['小甲鱼', '小布丁', '黑夜', '迷途', '怡静', '福禄娃娃', '竹林小溪', 'Crazy迷恋']
list.insert(index, obj) 将指定对象插入列表的指定位置
obj – 要插入列表中的对象。>>>member.insert(0,'牡丹')
>>>member
['牡丹', '小甲鱼', '小布丁', '黑夜', '迷途', '怡静', '福禄娃娃', '竹林小溪', 'Crazy迷恋']
第011讲 列表:一个打了激素的数组2
课堂笔记
从列表中获取元素
从列表删除元素
list.remove(obj) 移除列表中某个值的第一个匹配项。
>>>member.remove('怡静')
>>>member
['牡丹', '小甲鱼', '小布丁', '黑夜', '迷途', '福禄娃娃', '竹林小溪', 'Crazy迷恋']
del 语句 删除变量
>>>del member[1]
>>>member
['牡丹', '小布丁', '黑夜', '迷途', '福禄娃娃', '竹林小溪', 'Crazy迷恋']
list.pop([index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
>>>member.pop(1)
'小布丁'
>>>member
['牡丹', '黑夜', '迷途', '福禄娃娃', '竹林小溪', 'Crazy迷恋']
列表分片(slice)
>>>member[1:3]
['黑夜', '迷途']
>>>member2=member[:]
# 实现变量的拷贝,member2=member直接等于是赋值,相当于一个数贴了两个名字,两个会同样变化,而拷贝不会
课后练习
list1 = [1, [1, 2, [‘小甲鱼’]], 3, 5, 8, 13, 18]list1[1][2][0] = '小鱿鱼'
>>> 列表名.sort()
>>> 列表名.sort()
>>> 列表名.reverse()
>>> 列表名.sort(reverse=True)
>>> list2 = list1.copy()
>>> list2
[1, [1, 2, ['小甲鱼']], 3, 5, 8, 13, 18]
>>> list2.clear()
>>> list2
[]
没听过?!没关系,我们现场来学习一下吧,看表达式:>> [ i*i for i in range(10) ]
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
[有关A的表达式 for A in B]
例如>>> list1 = [x**2 for x in range(10)]
>>> list1
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
list1 = []
for x in range(10):
list1.append(x**2)
>>> list1 = [(x, y) for x in range(10) for y in range(10) if x%2==0 if y%2!=0]
for x in range(10):
for y in range(10):
if x % 2 == 0 and y %2 != 0:
list2.append((x,y))
第012讲 列表:一个打了激素的数组3
课堂笔记
列表的一些常用操作符
Python 表达式
结果
描述
len([1, 2, 3])
3
长度
[1, 2, 3] + [4, 5, 6]
[1, 2, 3, 4, 5, 6]
组合
[‘Hi!’] * 4
[‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’]
重复
3 in [1, 2, 3]
True
元素是否存在于列表中(只影响一层)
for x in [1, 2, 3]: print x,
1 2 3
迭代
[123,456]<[456,123]
True
比较(从第一个开始比较,取第一个的结果,若为=则比较下一个)
列表的内置函数&方法
序号
函数
说明
1
cmp(list1, list2)
比较两个列表的元素
2
len(list)
列表元素个数
3
max(list)
返回列表元素最大值
4
min(list)
返回列表元素最小值
5
list(seq)
将元组转换为列表
序号
方法
说明
1
list.append(obj)
在列表末尾添加新的对象
2
list.count(obj)
统计某个元素在列表中出现的次数
3
list.extend(seq)
在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
4
list.index(obj)
从列表中找出某个值第一个匹配项的索引位置
5
list.insert(index, obj)
将对象插入列表
6
list.pop([index=-1])
移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
7
list.remove(obj)
移除列表中某个值的第一个匹配项
8
list.reverse()
反向列表中元素
9
list.sort(cmp=None, key=None, reverse=False)
对原列表进行排序
课后练习
>>> old = [1, 2, 3, 4, 5]
>>> new = old
>>> old = [6]
>>> print(new)
e.g.:>>> B = [2, 2, 3, 3, 4, 4, 5, 5]
>>> A = B
>>> A
[2, 2, 3, 3, 4, 4, 5, 5]
>>> C = B[:]
>>> C
[2, 2, 3, 3, 4, 4, 5, 5]
>>> B.sort(reverse = True)
>>> B
[5, 5, 4, 4, 3, 3, 2, 2]
>>> A
[5, 5, 4, 4, 3, 3, 2, 2]
>>> C
[2, 2, 3, 3, 4, 4, 5, 5]
>>> B = [2, 2, 3, 3, 4, 4, 5, 5]
>>> A = B
>>> A
[2, 2, 3, 3, 4, 4, 5, 5]
>>> C = B[:]
>>> C
[2, 2, 3, 3, 4, 4, 5, 5]
>>> B = [6]
>>> B
[6]
>>> A
[2, 2, 3, 3, 4, 4, 5, 5]
>>> C
[2, 2, 3, 3, 4, 4, 5, 5]
第013讲 元组(tuple):戴上了枷锁的列表
课堂笔记
创建和访问一个元组
tup1 = ()
tup1 = (50,) 等价于 tup1=50,元组运算符
Python 表达式
结果
描述
len((1, 2, ‘小甲鱼’))
3
计算元素个数
(1, 2, 3) + (4, 5, 6)
(1, 2, 3, 4, 5, 6)
连接
(8,) * 4
(8,8,8,8)
复制
3 in (1, 2, 3)
True
元素是否存在
for x in (1, 2, 3): print x,
1 2 3
迭代
元组索引,截取
L = (‘spam’, ‘Spam’, ‘SPAM!’)
Python 表达式
结果
描述
L[2]
‘SPAM!’
读取第三个元素
L[-2]
‘Spam’
反向读取,读取倒数第二个元素
L[1:]
(‘Spam’, ‘SPAM!’)
截取元素
L[x:y:z]
切片索引,x是左端,y是右端,z是步长,在[x,y)区间从左到右每隔z取值,默认z为1可以省略z参数.
修改元组
>>>temp=('小甲鱼','黑夜','迷途','小布丁')
>>>temp=temp[:2]+('怡静',)+temp[2:]
>>>temp
('小甲鱼', '黑夜', '怡静', '迷途', '小布丁')
删除元组
del temp
第014讲 字符串:各种奇葩的内置方法
课堂笔记
python的字符串内建函数
方法
描述
string.capitalize()
把字符串的第一个字符改为大写
string.casefold()
把整个字符串的所有字符改为小写
string.center(width)
将字符串居中,并使用空格填充至长度 width 的新字符串
string.count(sub[, start[, end]])
返回 sub 在字符串里边出现的次数,start 和 end 参数表示范围,可选。
string.encode(encoding=‘utf-8’, errors=‘strict’)
以 encoding 指定的编码格式对字符串进行编码。
string.endswith(sub[, start[, end]])
检查字符串是否以 sub 子字符串结束,如果是返回 True,否则返回 False。start 和 end 参数表示范围,可选。
string.expandtabs([tabsize=8])
把字符串中的 tab 符号(\t)转换为空格,如不指定参数,默认的空格数是 tabsize=8。
string.find(sub[, start[, end]])
检测 sub 是否包含在字符串中,如果有则返回索引值,否则返回 -1,start 和 end 参数表示范围,可选。
string.index(sub[, start[, end]])
跟 find 方法一样,不过如果 sub 不在 string 中会产生一个异常。
string.isalnum()
如果字符串至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False。
string.isalpha()
如果字符串至少有一个字符并且所有字符都是字母则返回 True,否则返回 False。
string.isdecimal()
如果字符串只包含十进制数字则返回 True,否则返回 False。
string.isdigit()
如果字符串只包含数字则返回 True,否则返回 False。
string.islower()
如果字符串中至少包含一个区分大小写的字符,并且这些字符都是小写,则返回 True,否则返回 False。
string.isnumeric()
如果字符串中只包含数字字符,则返回 True,否则返回 False。
string.isspace()
如果字符串中只包含空格,则返回 True,否则返回 False。
string.istitle()
如果字符串是标题化(所有的单词都是以大写开始,其余字母均小写),则返回 True,否则返回 False。
string.isupper()
如果字符串中至少包含一个区分大小写的字符,并且这些字符都是大写,则返回 True,否则返回 False。
string.join(sub)
以字符串作为分隔符,插入到 sub 中所有的字符之间。
string.ljust(width)
返回一个左对齐的字符串,并使用空格填充至长度为 width 的新字符串。
string.lower()
转换字符串中所有大写字符为小写。
string.lstrip()
去掉字符串左边的所有空格
string.partition(sub)
找到子字符串 sub,把字符串分成一个 3 元组 (pre_sub, sub, fol_sub),如果字符串中不包含 sub 则返回 (‘原字符串’, ‘’, ‘’)
string.replace(old, new[, count])
把字符串中的 old 子字符串替换成 new 子字符串,如果 count 指定,则替换不超过 count 次。
string.rfind(sub[, start[, end]])
类似于 find() 方法,不过是从右边开始查找。
string.rindex(sub[, start[, end]])
类似于 index() 方法,不过是从右边开始。
string.rjust(width)
返回一个右对齐的字符串,并使用空格填充至长度为 width 的新字符串。
string.rpartition(sub)
类似于 partition() 方法,不过是从右边开始查找。
string.rstrip()
删除字符串末尾的空格。
string.split(sep=None, maxsplit=-1)
不带参数默认是以空格为分隔符切片字符串,如果 maxsplit 参数有设置,则仅分隔 maxsplit 个子字符串,返回切片后的子字符串拼接的列表。
string.splitlines(([keepends]))
在输出结果里是否去掉换行符,默认为 False,不包含换行符;如果为 True,则保留换行符。。
string.startswith(prefix[, start[, end]])
检查字符串是否以 prefix 开头,是则返回 True,否则返回 False。start 和 end 参数可以指定范围检查,可选。
string.strip([chars])
删除字符串前边和后边所有的空格,chars 参数可以定制删除的字符,可选。
string.swapcase()
翻转字符串中的大小写。
string.title()
返回标题化(所有的单词都是以大写开始,其余字母均小写)的字符串。
string.translate(table)
根据 table 的规则(可以由 str.maketrans(‘a’, ‘b’) 定制)转换字符串中的字符。将所有a替换为b
string.upper()
转换字符串中的所有小写字符为大写。
string.zfill(width)
返回长度为 width 的字符串,原字符串右对齐,前边用 0 填充。
课后练习
>>> str1 = '''待我长发及腰,将军归来可好?
此身君子意逍遥,怎料山河萧萧。
天光乍破遇,暮雪白头老。
寒剑默听奔雷,长枪独守空壕。
醉卧沙场君莫笑,一夜吹彻画角。
江南晚来客,红绳结发梢。'''
>>> str2 = '待卿长发及腰,我必凯旋回朝。\
昔日纵马任逍遥,俱是少年英豪。\
东都霞色好,西湖烟波渺。\
执枪血战八方,誓守山河多娇。\
应有得胜归来日,与卿共度良宵。\
盼携手终老,愿与子同袍。'
>>> str3 = ('待卿长发及腰,我必凯旋回朝。'
'昔日纵马任逍遥,俱是少年英豪。'
'东都霞色好,西湖烟波渺。'
'执枪血战八方,誓守山河多娇。'
'应有得胜归来日,与卿共度良宵。'
'盼携手终老,愿与子同袍。')
>>> file1 = open(r'C:\windows\temp\readme.txt', 'r')
>>> str1[::3]
#从左到右以步长为3截取
0. 请写一个密码安全性检查的脚本代码:check.py# 密码安全性检查代码
#
# 低级密码要求:
# 1. 密码由单纯的数字或字母组成
# 2. 密码长度小于等于8位
#
# 中级密码要求:
# 1. 密码必须由数字、字母或特殊字符(仅限:~!@#$%^&*()_=-/,.?<>;:[]{}|\)任意两种组合
# 2. 密码长度不能低于8位
#
# 高级密码要求:
# 1. 密码必须由数字、字母及特殊字符(仅限:~!@#$%^&*()_=-/,.?<>;:[]{}|\)三种组合
# 2. 密码只能由字母开头
# 3. 密码长度不能低于16位
16. symbols = r'''`!@#$%^&*()_+-=/*{}[]\|'";:/?,.<>'''
17. chars = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
18. nums = '0123456789'
19.
20. passwd = input('请输入需要检查的密码组合:')
21.
22. # 判断长度
23. length = len(passwd)
24.
25. while (passwd.isspace() or length == 0) :
26. passwd = input("您输入的密码为空(或空格),请重新输入:")
27.
28. if length <= 8:
29. flag_len = 1
30. elif 8 < length < 16:
31. flag_len = 2
32. else:
33. flag_len = 3
34.
35. flag_con = 0
36.
37. # 判断是否包含特殊字符
38. for each in passwd:
39. if each in symbols:
40. flag_con += 1
41. break
42.
43. # 判断是否包含字母
44. for each in passwd:
45. if each in chars:
46. flag_con += 1
47. break
48.
49. # 判断是否包含数字
50. for each in passwd:
51. if each in nums:
52. flag_con += 1
53. break
54.
55. # 打印结果
56. while 1 :
57. print("您的密码安全级别评定为:", end='')
58. if flag_len == 1 or flag_con == 1 :
59. print("低")
60. elif flag_len == 2 or flag_con == 2 :
61. print("中")
62. else :
63. print("高")
64. print("请继续保持")
65. break
66.
67. print("请按以下方式提升您的密码安全级别:\n\
68. \t1. 密码必须由数字、字母及特殊字符三种组合\n\
69. \t2. 密码只能由字母开头\n\
70. \t3. 密码长度不能低于16位'")
71. break
第015讲 字符串:格式化
课堂笔记
字符串格式化
以上实例输出结果:
My name is Zara and weight is 21 kg!python字符串格式化符号:
符 号
描述
%c
格式化字符及其ASCII码
%s
格式化字符串
%d
格式化整数
%u
格式化无符号整型
%o
格式化无符号八进制数
%x
格式化无符号十六进制数
%X
格式化无符号十六进制数(大写)
%f
格式化浮点数字,可指定小数点后的精度
%e
用科学计数法格式化浮点数
%E
作用同%e,用科学计数法格式化浮点数
%g
根据值的大小决定使用 %f 或 %e
%G
作用同 %g,根据值的大小决定使用 %f 或者 %E
%p
用十六进制数格式化变量的地址
格式化操作符辅助指令:
符号
功能
*
定义宽度或者小数点精度
-
用做左对齐
+
在正数前面显示加号( + )
在正数前面显示空格
#
在八进制数前面显示零(‘0’),在十六进制前面显示’0x’或者’0X’(取决于用的是’x’还是’X’)
0
显示的数字前面填充’0’而不是默认的空格
%
‘%%‘输出一个单一的’%’
(var)
映射变量(字典参数)
m.n
m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话)
format 格式化函数
>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
'hello world'
>>> "{1} {0} {1}".format("hello", "world") # 设置指定位置
'world hello world'
print("网站名:{name}, 地址 {url}".format(name="菜鸟教程", url="www.runoob.com"))
# 通过字典设置参数
site = {"name": "菜鸟教程", "url": "www.runoob.com"}
print("网站名:{name}, 地址 {url}".format(**site))
# 通过列表索引设置参数
my_list = ['菜鸟教程', 'www.runoob.com']
print("网站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是必须的
""""""""""""""""""""""""""""""""""
输出结果为:
网站名:菜鸟教程, 地址 www.runoob.com
网站名:菜鸟教程, 地址 www.runoob.com
网站名:菜鸟教程, 地址 www.runoob.com
""""""""""""""""""""""""""""""""""""
class AssignValue(object):
def __init__(self, value):
self.value = value
my_value = AssignValue(6)
print('value 为: {0.value}'.format(my_value)) # "0" 是可选的
value 为: 6数字格式化
>>> print("{:.2f}".format(3.1415926));
3.14
数字
格式
输出
描述
3.1415926
{:.2f}
3.14
保留小数点后两位
3.1415926
{:+.2f}
+3.14
带符号保留小数点后两位
-1
{:+.2f}
-1.00
带符号保留小数点后两位
2.71828
{:.0f}
3
不带小数
5
{:0>2d}
05
数字补零 (填充左边, 宽度为2)
5
{:x<4d}
5xxx
数字补x (填充右边, 宽度为4)
10
{:x<4d}
10xx
数字补x (填充右边, 宽度为4)
1000000
{:,}
1,000,000
以逗号分隔的数字格式
0.25
{:.2%}
25.00%
百分比格式
1000000000
{:.2e}
1.00e+09
指数记法
13
{:10d}
13
右对齐 (默认, 宽度为10)
13
{:<10d}
13
左对齐 (宽度为10)
13
{:^10d}
13
中间对齐 (宽度为10)
11
‘{:b}’.format(11)
’{:d}’.format(11)
’{:o}’.format(11)
’{:x}’.format(11)
’{:#x}’.format(11)
’{:#X}’.format(11)1011
11
13
b
0xb
0XB进制
b、d、o、x 分别是二进制、十进制、八进制、十六进制。
此外我们可以使用大括号 {} 来转义大括号,如下实例:print ("{} 对应的位置是 {{0}}".format("runoob"))
runoob 对应的位置是 {0}Python 的转义字符及其含义
符号
说明
’
单引号
"
双引号
\a
发出系统响铃声
\b
退格符
\n
换行符
\t
横向制表符(TAB)
\v
纵向制表符
\r
回车符
\f
换页符
\o
八进制数代表的字符
\x
十六进制数代表的字符
\0
表示一个空字符
\\
反斜杠
课后练习
1. q = True
2. while q:
3. num = input('请输入一个整数(输入Q结束程序):')
4. if num != 'Q':
5. num = int(num)
6. print('十进制 -> 十六进制 : %d -> 0x%x' % (num, num))
7. print('十进制 -> 八进制 : %d -> 0o%o' % (num, num))
8. print('十进制 -> 二进制 : %d -> ' % num, bin(num))
9. else:
10. q = False
第016讲 序列!序列
课堂笔记
列表、元组和字符串的共同点
常见函数
list([iterable]) 生成一个列表或把一个可迭代对象转换为列表
>>>a='i love'
>>>b=list(a)
>>>b
['i', ' ', 'l', 'o', 'v', 'e']
>>>aTuple = (123, 'xyz', 'zara', 'abc');
>>>aList = list(aTuple)
>>>aList
[123, 'xyz', 'zara', 'abc']
max(list/tuple) 返回列表元素最大值
>>>list1, list2 = ['123', 'xyz', 'zara', 'abc'], [456, 700, 200]
>>>print "Max value element : ", max(list1);
>>>print "Max value element : ", max(list2);
Max value element : zara #输出ASCII码最大的
Max value element : 700
sum(iterable[, start])返回序列iterable和可选参数start的总和
>>> sum((2, 3, 4), 1) # 元组计算总和后再加 1
10
sorted() 对所有可迭代的对象进行排序操作
sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
list 的 sort 方法返回的是对已经存在的列表进行操作,无返回值,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。reversed(seq) 返回一个反转的迭代器
# 字符串
seqString = 'Runoob'
print(list(reversed(seqString)))
# 元组
seqTuple = ('R', 'u', 'n', 'o', 'o', 'b')
print(list(reversed(seqTuple)))
# range
seqRange = range(5, 9)
print(list(reversed(seqRange)))
# 列表
seqList = [1, 2, 4, 3, 5]
print(list(reversed(seqList)))
""""""""""""""""""""""""""""
['b', 'o', 'o', 'n', 'u', 'R']
['b', 'o', 'o', 'n', 'u', 'R']
[8, 7, 6, 5]
[5, 3, 4, 2, 1]
"""""""""""""""""""""""""""""
enumerate(sequence, [start=0]) 用于将一个可遍历的数据对象组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
>>> list(enumerate(seasons, start=1)) # 下标从 1 开始
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
#for 循环使用 enumerate
>>>seq = ['one', 'two', 'three']
>>> for i, element in enumerate(seq):
... print i, element
0 one
1 two
2 three
zip 将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
>>>a = [1,2,3]
>>> b = [4,5,6]
>>> c = [4,5,6,7,8]
>>> zipped = zip(a,b) # 打包为元组的列表
[(1, 4), (2, 5), (3, 6)]
>>> zip(a,c) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
>>> zip(*zipped) # 与 zip 相反,*zipped 可理解为解压,返回二维矩阵式
[(1, 2, 3), (4, 5, 6)]
课后练习
第017讲 函数:Python的乐高积木块
课堂笔记
定义一个函数
函数调用
参数
函数的返回值
# 可写函数说明
def sum( arg1, arg2 ):
# 返回2个参数的和."
total = arg1 + arg2
print "函数内 : ", total
return total;
# 调用sum函数
total = sum( 10, 20 );
课后练习
0) 可以降低代码量(调用函数只需要一行,而拷贝黏贴需要N倍代码)
1) 可以降低维护成本(函数只需修改def部分内容,而拷贝黏贴则需要每一处出现的地方都作修改)
2) 使序更容易阅读(没有人会希望看到一个程序重复一万行“I love FishC.com”)
def MyFun((x, y), (a, b)):
return x * y - a * b
我们分析下,函数的参数需要的是变量,而这里你试图用“元祖”的形式来传递是不可行的。>>> def MyFun(x, y):
return x[0] * x[1] - y[0] * y[1]
>>> MyFun((3, 4), (1, 2))
10
第018讲 函数:灵活即强大
课堂笔记
形参和实参
>>>def MyFirstFunction(name):
'函数定义过程这的 name是叫形参'
#因为Ta只是一个形式,表示占据一个参数位置
print('传递进来的'+name+'叫做实参,因为Ta是具体的参数值!')
>>>MyFirstFunction('小甲鱼')
传递进来的小甲鱼叫做实参,因为Ta是具体的参数值!
函数文档
关键字参数
def printinfo( name, age ):
"打印任何传入的字符串"
print "Name: ", name;
print "Age ", age;
return;
#调用printinfo函数
printinfo( age=50, name="miki" );
Name: miki
Age 50默认参数
def printinfo( name, age = 35 ):
"打印任何传入的字符串"
print "Name: ", name;
print "Age ", age;
return;
#调用printinfo函数
printinfo( age=50, name="miki" );
printinfo( name="miki" );
Name: miki
Age 50
Name: miki
Age 35收集参数/可变参数/不定长参数
def functionname([formal_args,] *var_args_tuple ):
"函数_文档字符串"
function_suite
return [expression]
不定长参数实例如下:def printinfo( arg1, *vartuple ):
"打印任何传入的参数"
print "输出: "
print arg1
for var in vartuple:
print var
return;
# 调用printinfo 函数
printinfo( 10 );
printinfo( 70, 60, 50 );
10
输出:
70
60
50第019讲 函数:我的地盘听我的
课堂笔记
函数与过程
再谈谈返回值
局部变量与全局变量
total = 0; # 这是一个全局变量
# 可写函数说明
def sum( arg1, arg2 ):
#返回2个参数的和."
total = arg1 + arg2; # total在这里是局部变量.
print "函数内是局部变量 : ", total
return total;
#调用sum函数
sum( 10, 20 );
print "函数外是全局变量 : ", total
函数外是全局变量 : 0
小甲鱼建议不到万不得已不要使用全局变量,简洁概括为
1.代码可读性变差
2.代码安全性降低第020讲 函数:内嵌函数和闭包
课堂笔记
global 关键字
内嵌函数/内部函数
闭包
>>>def FunX(x):
def FunY(y):
return x*y
return FunY
>>>i=FunX(8)
>>>i
<function __main__.FunX.<locals>.FunY(y)>
>>>i(5)
40
>>>FunX(8)(5)
40
def Fun1():
x = [5]
def Fun2():
x[0] *= x[0]
return x[0]
return Fun2()
print(Fun1())
def Fun3():
x = 5
def Fun4():
nonlocal x
x *= x
return x
return Fun4()
print(Fun3())
25
25课后练习
def funOut():
def funIn():
print('宾果!你成功访问到我啦!')
return funIn()
>>>funOut()
宾果!你成功访问到我啦!
def funOut():
def funIn():
print('宾果!你成功访问到我啦!')
return funIn
>>>funOut()()
宾果!你成功访问到我啦!
第021讲 函数:lambda表达式
课堂笔记
匿名函数
语法
lambda [arg1 [,arg2,…argn]]:expression
如下实例:sum = lambda arg1, arg2: arg1 + arg2;
# 调用sum函数
print "相加后的值为 : ", sum( 10, 20 )
print "相加后的值为 : ", sum( 20, 20 )
相加后的值为 : 30
相加后的值为 : 40lamda表达式的作用
过滤器filter()
语法
参数
function – 判断函数。
iterable – 可迭代对象。
返回值
返回一个迭代器对象实例
def is_odd(n):
return n % 2 == 1
tmplist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
newlist = list(tmplist)
print(newlist)
>>>list(filter(lambda x : x%2,range(10)))
[1,3,5,7,9]
映射map()
语法
参数
function – 函数
iterable – 一个或多个序列
返回值
Python 2.x 返回列表。
Python 3.x 返回迭代器。实例
>>>def square(x) : # 计算平方数
... return x ** 2
...
>>> map(square, [1,2,3,4,5]) # 计算列表各个元素的平方
[1, 4, 9, 16, 25]
课后练习
list(filter(lambda n : not(n%3),range(1,100)))
例如将第三题转为列表推导式:[i for i in range(1,100) if not(i%3)]
第022讲 函数:递归是神马
课堂笔记
import sys
sys.setrecursionlimit(1000)
递归求阶乘
课后练习
1)递归的基本思想是把规模大的问题变成规模小的问题组合,从而简化问题的解决难度(例如汉诺塔游戏)。
2)有些问题使用递归使得代码简洁易懂(例如你可以很容易的写出前中后序的二叉树遍历的递归算法,但如果要写出相应的非递归算法就不是初学者可以做到的了。)
缺点:
1)由于递归的原理是函数调用自个儿,所以一旦大量的调用函数本身空间和时间消耗是“奢侈的”。
2)初学者很容易错误的设置了返回条件,导致递归代码无休止调用,最终栈溢出,程序崩溃。第023讲 递归:这帮小兔崽子
课堂练习
斐波那契数列的实现
import time
n = int(input('请输入一个整数:'))
print('-----迭代-----')
time1 = time.clock()
f = [1,1]
if n >= 2:
for i in range(1,n-1):
f.append(f[i-1]+f[i])
print('经历了%d个月后共有%d对小兔子' % (n, f[-1]))
cost1=time.clock()-time1
print(cost1)
print('-----递归-----')
time2 = time.clock()
def feb(n):
if n<1:
print('输入有误,请重新输入')
elif n ==1 or n==2:
return 1
else:
return feb(n-1)+feb(n-2)
result = feb(n)
print('经历了%d个月后共有%d对小兔子' % (n, result))
cost2=time.clock()-time2
print(cost2)
""""""""""
请输入一个整数:30
-----迭代-----
经历了30个月后共有832040对小兔子
4.55111499472924e-05
-----递归-----
经历了30个月后共有832040对小兔子
0.22572506372983217
""""""""""
第024讲 递归:汉诺塔
课堂笔记
n = int(input('请输入一个整数:'))
def hanoi(n,x,y,z):
if n ==1:
print(x,'->',z)
else:
hanoi(n-1,x,z,y)#讲前n-个盘子从x移动到y上
print(x,'->',z)#将第n个盘子从x移动到z
hanoi(n-1,y,x,z)#将前n-1个盘子从y移动到z
hanoi(n,'x','y','z')
课后练习
result=[]
def get_digits(n):
if n>0:
result.insert(0,n%10)
get_digit(n//10)
get_digits(12345)
print(result)
第025讲 字典:当索引不好用时1
课堂笔记
创建字典
d = {key1 : value1, key2 : value2 }创建一个空字典
访问字典
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
print "dict['Name']: ", dict['Name']
print "dict['Age']: ", dict['Age']
dict['Name']: Zara
dict['Age']: 7
dict() 函数
语法
class dict(mapping, **kwarg)
class dict(iterable, **kwarg)
参数说明:
**kwargs – 关键字
mapping – 元素的容器。
iterable – 可迭代对象。
返回值
返回一个字典。实例
>>>dict() # 创建空字典
{}
>>> dict(a='a', b='b', t='t') # 传入关键字 key不能用‘’包起来
{'a': 'a', 'b': 'b', 't': 't'}
>>> dict(zip(['one', 'two', 'three'], [1, 2, 3])) # 映射函数方式来构造字典
{'three': 3, 'two': 2, 'one': 1}
>>> dict([('one', 1), ('two', 2), ('three', 3)]) # 可迭代对象方式来构造字典,列表也可替换为元组,字典等
{'three': 3, 'two': 2, 'one': 1}
>>>dict1= dict((['a',2],['b',3]))#利用 dict(([key,value],[key,value])) 的方式创建字典
{'a': 2, 'b': 3}
>>>dict1['c']=4 #key存在则重新赋值,不存在则创建新的键值对,列表不能这么操作
{'a': 2, 'b': 3,'c':4}
第026讲 字典:当索引不好用时2
课堂笔记
字典内置函数&方法
fromkeys()方法
dict.fromkeys(seq[, value])
参数
seq – 字典键值列表。
value – 可选参数, 设置键序列(seq)的值。不选则为None
返回值
该方法返回一个新字典。seq = ('Google', 'Runoob', 'Taobao')
dict = dict.fromkeys(seq)
print "新字典为 : %s" % str(dict)
dict = dict.fromkeys(seq, [1,2,3])
print "新字典为 : %s" % str(dict)
新字典为 : {‘Google’: None, ‘Taobao’: None, ‘Runoob’: None}
新字典为 : {‘Google’: [1,2,3], ‘Taobao’: [1,2,3], ‘Runoob’: [1,2,3]}keys()方法
语法
dict.keys()
实例dict = {'Name': 'Zara', 'Age': 7}
print "Value : %s" % dict.keys()
Value : [‘Age’, ‘Name’]values()方法
语法
dict.values()
实例dict = {'Name': 'Zara', 'Age': 7}
print "Value : %s" % dict.keys()
Value : [7, ‘Zara’]items()方法
语法
dict.items()
实例dict = {'Google': 'www.google.com', 'Runoob': 'www.runoob.com', 'taobao': 'www.taobao.com'}
print "字典值 : %s" % dict.items()
# 遍历字典列表
for key,values in dict.items():
print key,values
Google www.google.com
taobao www.taobao.com
Runoob www.runoob.comget()方法
语法
dict.get(key, default=None)
参数
key – 字典中要查找的键。
default – 如果指定键的值不存在时,返回该默认值值。
实例dict = {'Name': 'Zara', 'Age': 27}
print( "Value : %s" % dict.get('Age'))
print ("Value : %s" % dict.get('Sex', "Never"))
Value : 27
Value : Neverhas_key()方法
语法
dict.has_key(key)clear()方法
语法
dict.clear()copy()方法
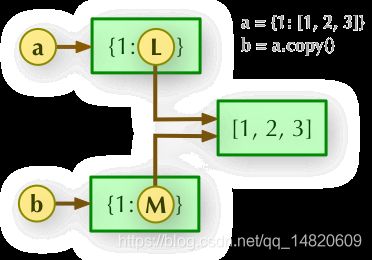
dict.copy()Python 直接赋值、浅拷贝和深度拷贝解析
实例>>>a = {1: [1,2,3]}
>>> b = a.copy()
>>> a, b
({1: [1, 2, 3]}, {1: [1, 2, 3]})
>>> a[1].append(4)
>>> a, b
({1: [1, 2, 3, 4]}, {1: [1, 2, 3, 4]})
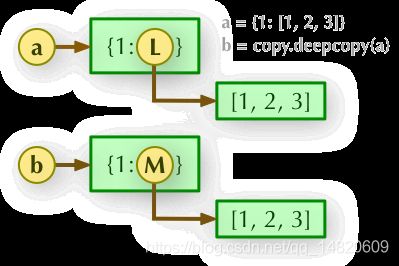
'深度拷贝需要引入 copy 模块:'
>>>import copy
>>> c = copy.deepcopy(a)
>>> a, c
({1: [1, 2, 3, 4]}, {1: [1, 2, 3, 4]})
>>> a[1].append(5)
>>> a, c
({1: [1, 2, 3, 4, 5]}, {1: [1, 2, 3, 4]})

2、b = a.copy(): 浅拷贝, a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象(是引用)。
b = copy.deepcopy(a): 深度拷贝, a 和 b 完全拷贝了父对象及其子对象,两者是完全独立的。
pop() 方法
语法
dict.pop(key[,default])
参数
key: 要删除的键值
default: 如果没有 key,返回 default 值popitem() 方法
语法
dict.popitem()setdefault()方法
语法
dict.setdefault(key, default=None)
参数
key – 查找的键值。
default – 键不存在时,设置的默认键值。
返回值
如果字典中包含有给定键,则返回该键对应的值,否则返回为该键设置的值。
实例
dict = {‘runoob’: ‘菜鸟教程’, ‘google’: ‘Google 搜索’}
print (“Value : %s” % dict.setdefault(‘runoob’, None))
print (“Value : %s” % dict.setdefault(‘Taobao’, ‘淘宝’))
以上实例输出结果为:
Value : 淘宝update()方法
语法
dict.update(dict2)
返回值
该方法没有任何返回值。
实例dict = {'Name': 'Zara', 'Age': 7}
dict2 = {'Sex': 'female' }
dict.update(dict2)
print "Value : %s" % dict
Value : {‘Age’: 7, ‘Name’: ‘Zara’, ‘Sex’: ‘female’}课后练习
值可以是任意的python对象第027讲 集合:在我的世界里,你就是唯一
课堂笔记
去重功能
num1=[1,2,3,4,5,5,3,1,0]
num1=list(set(num1))
判断元素是否在集合中存在
>>>thisset = set(("Google", "Runoob", "Taobao"))
>>> "Runoob" in thisset
True
>>> "Facebook" in thisset
False
计算集合元素个数
len(set)集合内置方法完整列表
方法
描述
set.add()
为集合添加元素
set.clear()
移除集合中的所有元素
set.copy()
拷贝一个集合
set.difference()
返回多个集合的差集
set.difference_update()
移除集合中的元素,该元素在指定的集合也存在。
set.discard()
删除集合中指定的元素
set.intersection()
返回集合的交集
set.intersection_update()
删除集合中的元素,该元素在指定的集合中不存在。
set.isdisjoint()
判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。
set.issubset()
判断指定集合是否为该方法参数集合的子集。
set.issuperset()
判断该方法的参数集合是否为指定集合的子集
set.pop()
随机移除元素
set.remove()
移除指定元素
set.symmetric_difference()
返回两个集合中不重复的元素集合。
set.symmetric_difference_update()
移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。
set.union()
返回两个集合的并集
set.update()
给集合添加元素
不可变集合 frozenset()函数
语法
参数
iterable – 可迭代的对象,比如列表、字典、元组等等。
返回值
返回新的 frozenset 对象,如果不提供任何参数,默认会生成空集合。实例
>>>a = frozenset(range(10)) # 生成一个新的不可变集合
>>> a
frozenset([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> b = frozenset('runoob')
>>> b
frozenset(['b', 'r', 'u', 'o', 'n']) # 创建不可变集合
课后练习
>>> set1 = {1,1.0}
>>> set1
{1}
第028讲 文件:因为懂你,所以永恒
课堂笔记
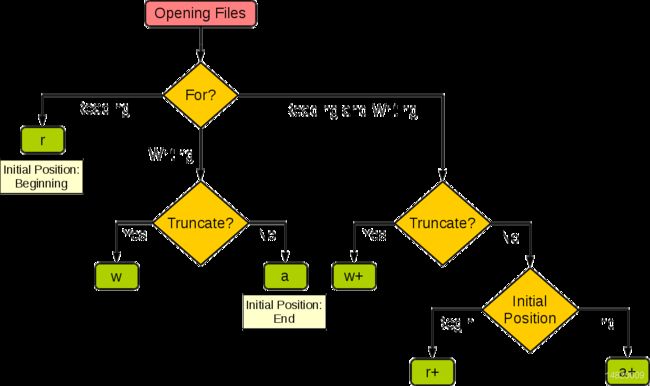
打开文件 open()函数
语法:
参数
file_name:file_name变量是一个包含了你要访问的文件名称的字符串值。
access_mode:access_mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读®。
buffering:如果buffering的值被设为0,就不会有寄存。如果buffering的值取1,访问文件时会寄存行。如果将buffering的值设为大于1的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。不同模式打开文件的完全列表:
模式
描述
t
文本模式 (默认)。
x
写模式,新建一个文件,如果该文件已存在则会报错。
b
二进制模式。
+
打开一个文件进行更新(可读可写)。
U
通用换行模式(不推荐)。
r
以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。
rb
以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。
r+
打开一个文件用于读写。文件指针将会放在文件的开头。
rb+
以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。
w
打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
wb
以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。
w+
打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
wb+
以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。
a
打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
ab
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
a+
打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
ab+
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。
模式
r
r+
w
w+
a
a+
读
+
+
+
+
写
+
+
+
+
+
创建
+
+
+
+
覆盖
+
+
指针在开始
+
+
+
+
指针在结尾
+
+
文件对象方法
文件对象方法
执行操作
f.close()
关闭文件 写入时只有关闭文件才能将内容从缓存区真正写入
f.read([size=-1])
从文件读取size个字符,当未给定size或给定负值的时候,读取剩余的所有字符,然后作为字符串返回
f.readline([size=-1])
从文件中读取并返回一行(包括行结束符),如果有size有定义则从指针的位置开始返回size个字符
f.write(str)
将字符串str写入文件
f.writelines(seq)
向文件写入字符串序列seq,seq应该是一个返回字符串的可迭代对象
f.seek(offset, from)
在文件中移动文件指针,从from(0代表文件起始位置,1代表当前位置,2代表文件末尾)偏移offset个字节
f.tell()
返回当前指针在文件中的位置
f.truncate([size=file.tell()])
截取文件到size个字节,默认是截取到文件指针当前位置
课后练习
for each_line in f:
print(each_line)
>>> f.seek(46)
46
>>> f.readline()
Traceback (most recent call last):
Flie "
f = open('D:\\OpenMe.mp3')
for each_line in f:
print(each_line,end='')
f.close()

f1 = open(r'D:\OpenMe.mp3',’r’)
f2 = open(r'D:\OpenMe.txt’,’w’)
for each_line in f1:
f2.write(each_line)
f1.close()
f2.close()
第029讲 文件:一个任务
课堂笔记
任务
f = open('record.txt')
boy=[]
girl=[]
count = 1
def save_file(boy,girl,count):
file_name_boy = 'boy_' + str(count) + '.txt'
file_name_girl = 'girl_' + str(count) + '.txt'
boy_file = open(file_name_boy, 'w')
girl_file = open(file_name_girl, 'w')
boy_file.writelines(boy)
girl_file.writelines(girl)
boy_file.close()
girl_file.close()
for each_line in f:
if each_line[:4] != '====':
#分割
(role,line_spoken) = each_line.split(':',1)
if role == '小甲鱼':
boy.append(line_spoken)
elif role == '小客服':
girl.append(line_spoken)
else:
#存放
save_file(boy,girl,count)
boy=[]
girl=[]
count += 1
save_file(boy,girl,count)
f.close()
第030讲 文件系统:介绍一个高大上的东西
课堂笔记
OS模块
os模块中关于文件/目录常用的函数使用方法
函数名
使用方法
getcwd()
返回当前工作目录
chdir(path)
改变工作目录
listdir(path=’.’)
列举指定目录中的文件名(’.‘表示当前目录,’…'表示上一级目录)
mkdir(path)
创建单层目录,如该目录已存在抛出异常
makedirs(path)
递归创建多层目录,如该目录已存在抛出异常,注意:'E:\a\b’和’E:\a\c’并不会冲突
remove(path)
删除文件
rmdir(path)
删除单层目录,如该目录非空则抛出异常
removedirs(path)
递归删除目录,从子目录到父目录逐层尝试删除,遇到目录非空则抛出异常
rename(old, new)
将文件old重命名为new
system(command)
运行系统的shell命令
walk(top)
遍历top路径以下所有的子目录,返回一个三元组:(路径, [包含目录], [包含文件])【具体实现方案请看:第30讲课后作业_】
以下是支持路径操作中常用到的一些定义,支持所有平台
os.curdir
指代当前目录。相当于点(’.’),非函数而是一个常用定义
os.pardir
指代上一级目录(’…’)
os.sep
输出操作系统特定的路径分隔符(Win下为’\’,Linux下为’/’)
os.linesep
当前平台使用的行终止符(Win下为’\r\n’,Linux下为’\n’)
os.name
指代当前使用的操作系统(包括:‘posix’, ‘nt’, ‘mac’, ‘os2’, ‘ce’, ‘java’)
os.path模块中关于路径常用的函数使用方法
函数名
使用方法
basename(path)
去掉目录路径,单独返回文件名
dirname(path)
去掉文件名,单独返回目录路径
join(path1[, path2[, …]])
将path1, path2各部分组合成一个路径名
split(path)
分割文件名与路径,返回(f_path, f_name)元组。如果完全使用目录,它也会将最后一个目录作为文件名分离,且不会判断文件或者目录是否存在
splitext(path)
分离文件名与扩展名,返回(f_name, f_extension)元组
getsize(file)
返回指定文件的尺寸,单位是字节
getatime(file)
返回指定文件最近的访问时间(浮点型秒数,可用time模块的gmtime()或localtime()函数换算)
getctime(file)
返回指定文件的创建时间(浮点型秒数,可用time模块的gmtime()或localtime()函数换算)
getmtime(file)
返回指定文件最新的修改时间(浮点型秒数,可用time模块的gmtime()或localtime()函数换算)
以下为函数返回 True 或 False
exists(path)
判断指定路径(目录或文件)是否存在
isabs(path)
判断指定路径是否为绝对路径
isdir(path)
判断指定路径是否存在且是一个目录
isfile(path)
判断指定路径是否存在且是一个文件
islink(path)
判断指定路径是否存在且是一个符号链接
ismount(path)
判断指定路径是否存在且是一个挂载点(本地盘是挂载点,例如:E:// c://)
samefile(path1, paht2)
判断path1和path2两个路径是否指向同一个文件
第031讲 永久储存:腌制一缸美味的泡菜
课堂笔记
pickle模块
保存数据/读取数据
import pickle
my_list=[123,3.14,'小甲鱼',['another list']]
pickle_file=open('my_list.pkl','wb')
pickle.dump(my_list,pickle_file)
pickle_file.close()
pickle_file=open('my_list.pkl','rb')
my_list2=pickle.load(pickle_file)
print(my_list2)
""""""""""""""
[123,3.14,'小甲鱼',['another list']]
""""""""""""""
课后练习
第032讲 异常处理:你不可能总是对的1
课堂笔记
AssertionError
断言语句(assert)失败
AttributeError
尝试访问未知的对象属性
EOFError
用户输入文件末尾标志EOF(Ctrl+d)
FloatingPointError
浮点计算错误
GeneratorExit
generator.close()方法被调用的时候
ImportError
导入模块失败的时候
IndexError
索引超出序列的范围
KeyError
字典中查找一个不存在的关键字
KeyboardInterrupt
用户输入中断键(Ctrl+c)
MemoryError
内存溢出(可通过删除对象释放内存)
NameError
尝试访问一个不存在的变量
NotImplementedError
尚未实现的方法
OSError
操作系统产生的异常(例如打开一个不存在的文件)
OverflowError
数值运算超出最大限制
ReferenceError
弱引用(weak reference)试图访问一个已经被垃圾回收机制回收了的对象
RuntimeError
一般的运行时错误
StopIteration
迭代器没有更多的值
SyntaxError
Python的语法错误
IndentationError
缩进错误
TabError
Tab和空格混合使用
SystemError
Python编译器系统错误
SystemExit
Python编译器进程被关闭
TypeError
不同类型间的无效操作
UnboundLocalError
访问一个未初始化的本地变量(NameError的子类)
UnicodeError
Unicode相关的错误(ValueError的子类)
UnicodeEncodeError
Unicode编码时的错误(UnicodeError的子类)
UnicodeDecodeError
Unicode解码时的错误(UnicodeError的子类)
UnicodeTranslateError
Unicode转换时的错误(UnicodeError的子类)
ValueError
传入无效的参数
ZeroDivisionError
除数为零
以下是 Python 内置异常类的层次结构:
±- SystemExit
±- KeyboardInterrupt
±- GeneratorExit
±- Exception
±- StopIteration
±- ArithmeticError
| ±- FloatingPointError
| ±- OverflowError
| ±- ZeroDivisionError
±- AssertionError
±- AttributeError
±- BufferError
±- EOFError
±- ImportError
±- LookupError
| ±- IndexError
| ±- KeyError
±- MemoryError
±- NameError
| ±- UnboundLocalError
±- OSError
| ±- BlockingIOError
| ±- ChildProcessError
| ±- ConnectionError
| | ±- BrokenPipeError
| | ±- ConnectionAbortedError
| | ±- ConnectionRefusedError
| | ±- ConnectionResetError
| ±- FileExistsError
| ±- FileNotFoundError
| ±- InterruptedError
| ±- IsADirectoryError
| ±- NotADirectoryError
| ±- PermissionError
| ±- ProcessLookupError
| ±- TimeoutError
±- ReferenceError
±- RuntimeError
| ±- NotImplementedError
±- SyntaxError
| ±- IndentationError
| ±- TabError
±- SystemError
±- TypeError
±- ValueError
| ±- UnicodeError
| ±- UnicodeDecodeError
| ±- UnicodeEncodeError
| ±- UnicodeTranslateError
±- Warning
±- DeprecationWarning
±- PendingDeprecationWarning
±- RuntimeWarning
±- SyntaxWarning
±- UserWarning
±- FutureWarning
±- ImportWarning
±- UnicodeWarning
±- BytesWarning
±- ResourceWarning第033讲 异常处理:你不可能总是对的2
课堂笔记
try-except语句
语法
<语句> #运行别的代码
except <名字>:
<语句> #如果在try部份引发了’name’异常
except <名字>[as reason]:
<语句> #如果引发了’name’异常,获得附加的数据
else:
<语句> #如果没有异常发生实例
try:
sum = 1 + '1'
fh = open("testfile.txt")
print(fh.read())
fh.close()
except IOError as reason:
print ('文件出错啦\n错误原因是:'+ str(reason))
except TypeError as reason:
print ('类型出错啦\n错误原因是:' + str(reason))
try:
sum = 1 + '1'
fh = open("testfile.txt")
print(fh.read())
fh.close()
except :
print ('出错啦')
except TypeError as reason:
try:
sum = 1 + '1'
fh = open("testfile.txt")
print(fh.read())
fh.close()
except (IOError,TypeError) as reason:
print ('出错啦')
try-finally语句
语法
<语句> #运行别的代码
except <名字>[as reason]:
<语句> #如果在try部份引发了’name’异常
finally:
无论如何都会被执行的代码实例
try:
fh = open("testfile.txt",'w')
print(fh.write('我存在了'))
sum = 1+'1'
except TypeError as reason:
print('类型出错啦\n错误原因是:' + str(reason))
finally:
fh.close()
raise语句 引发异常
语法
实例
>>>raise
Traceback (most recent call last):
File "D:\software\lib\site-packages\IPython\core\interactiveshell.py", line 3267, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "课后练习
try:
f = open('My_File.txt') # 当前文件夹中并不存在"My_File.txt"这个文件T_T
print(f.read())
except OSError as reason:
print('出错啦:' + str(reason))
finally:
f.close()
出错啦:[Errno 2] No such file or directory: ‘My_File.txt’
Traceback (most recent call last):
File “D:\untitled\Python_learn\test1.py”, line 7, in
f.close()
NameError: name ‘f’ is not definedtry:
f = open('My_File.txt') # 当前文件夹中并不存在"My_File.txt"这个文件T_T
print(f.read())
except OSError as reason:
print('出错啦:' + str(reason))
finally:
if 'f' in locals(): # 如果文件对象变量存在当前局部变量符号表的话,说明打开成功
f.close()
第034讲 丰富的else语句及简洁的with语句
课堂笔记
else语句
if…else
常见的if…else…语法while和for循环
#*************************************************#
# 判断给定数的最大公约数,如果是素数,则打印 #
#*************************************************#
def showMaxFactor(num):
count = num//2
while count > 1:
if num %count == 0:
print('%d最大的约数是%d'%(num,count))
break
count -= 1
else:
print('%d是素数!'%num)
num = int(input('请输入一个数:'))
showMaxFactor(num)
与异常处理语句搭配
try:
print(int('abc'))
except ValueError as reason:
print('出错啦:' + reason)
else:
print('没有任何异常!')
简洁的with语句
try:
with open('data.txt','w') as f:
for each_line in f:
print(each_line)
except OSError as reason:
print('出错了:'+str(reason))
finally:
f.close()
第035讲 图形用户界面入门:EasyGui
课堂笔记
第036讲 类和对象:给大家介绍对象
课堂笔记
下面是关于类的一个简单的例子:class Turtle: #Python中的类名约定以大写字母开头
"-----关于类的一个简单例子----"
#属性
color = 'green'
weight = 10
legs = 4
shell = True
mouth = '大嘴'
#方法
def climb(self):
print('我正在努力地向前爬.......')
def run(self):
print('我正在努力地向前爬.......')
def bite(self):
print('咬死你咬死你!!!')
def eat(self):
print('有吃的,真满足^_^')
def sleep(self):
print('累了,困了,睡觉了zzzzz')
tt = Turtle() #实例化一个类对象
>>> tt.climb()
我正在努力地向前爬.......
>>> tt.bite()
咬死你咬死你!!!
面向对象(Object Oriented)的特征
封装
继承
>>> class Mylist(list): #继承list
pass
>>> list1 = Mylist()
>>> list1.append(5)
>>> list1.append(3)
>>> list1.append(7)
>>> list1
[5, 3, 7]
>>> list1.sort()
>>> list1
[3, 5, 7]
多态
>>> class A:
def fun(self):
print('我是小A')
>>> class B:
def fun(self):
print('我是小B')
>>> a = A()
>>> b = B()
>>> a.fun()
我是小A
>>> b.fun()
我是小B
课后练习
0. 按照以下提示尝试定义一个 Person 类并生成类实例对象。
属性:姓名(默认姓名为“小甲鱼”)
方法:打印姓名
提示:方法中对属性的引用形式需加上 self,如 self.nameclass Person:
name = '小甲鱼'
def printName(self):
print(self.name)
第037讲 类和对象:面向对象编程
课堂笔记
self是什么?
>>> class Ball:
def setName(self, name):
self.name = name
def kick(self):
print("我叫%s,该死的,谁踢我..."% self.name)
>>> a = Ball()
>>> a.setName("球A")
>>> b = Ball()
>>> b.setName("球B")
>>> a.kick()
我叫球A,该死的,谁踢我...
>>> b.kick()
我叫球B,该死的,谁踢我...
魔法方法之__init__(self) 构造方法
>>> class Ball:
def __init__(self, name):
self.name = name
def kick(self):
print("我叫%s,该死的,谁踢我..."% self.name)
>>> a = Ball("土豆") #因为重写了__init__(self)方法,实例化对象时需要一个参数
>>> a.kick()
我叫土豆,该死的,谁踢我...
>>> b = Ball() #这里没有传入参数就会报错,可以在定义类是给name设置默认参数
Traceback (most recent call last):
File "公有、私有
>>> class Person:
name = "来自江南的你"
>>> p = Person()
>>> p.name
'来自江南的你'
>>> class Person:
__name = "来自江南的你"
>>> p = Person()
>>> p.__name
Traceback (most recent call last):
File ">>> class Person:
__name = "来自江南的你"
def getName(self):
return self.__name
>>> p = Person()
>>> p.getName()
'来自江南的你'
>>> class Person:
__name = "来自江南的你"
>>> p = Person()
>>> p._Person__name
'来自江南的你'
课后练习
class MyClass:
name = 'FishC'
def myFun(self):
print("Hello FishC!")
>>> MyClass.name
'FishC'
>>> MyClass.myFun()
Traceback (most recent call last):
File "
一个类可以实例化出无数的对象(实例对象),Python 为了区分是哪个实例对象调用了方法,于是要求方法必须绑定(通过 self 参数)才能调用。而未实例化的类对象直接调用方法,因为缺少 self 参数,所以就会报错。
0. 按照以下要求定义一个游乐园门票的类,并尝试计算2个成人+1个小孩平日票价。
class Ticket():
def __init__(self, weekend=False, child=False):
self.exp = 100
if weekend:
self.inc = 1.2
else:
self.inc = 1
if child:
self.discount = 0.5
else:
self.discount = 1
def calcPrice(self, num):
return self.exp * self.inc * self.discount * num
>>> adult = Ticket()
>>> child = Ticket(child=True)
>>> print("2个成人 + 1个小孩平日票价为:%.2f" % (adult.calcPrice(2) + child.calcPrice(1)))
2个成人 + 1个小孩平日票价为:250.00
第038讲 类和对象:继承
课堂笔记
>>> class Parent:
def hello(self):
print("正在调用父类的方法")
>>> class Child(Parent):
pass
>>> p = Parent()
>>> p.hello()
正在调用父类的方法
>>> c = Child()
>>> c.hello()
正在调用父类的方法
但是,这里覆盖的是子类实例化对象里面的方法而已,对父类的方法没有影响。
子类重写了父类的方法,就会把父类的方法给覆盖。要解决这个问题的话,我们应该在子类里面重写 方法的时候先调用父类的该方法,实现这样子的继承总共有两种技术。解决重写方法覆盖父类方法的问题
调用未绑定的父类方法(该方法不重要)
import random as r
class Fish:
def __init__(self):
self.x = r.randint(0, 10)
self.y = r.randint(0, 10)
def move(self):
self.x -= 1
print("我的位置是:", self.x, self.y)
class Goldfish(Fish):
pass
class Shark(Fish):
def __init__(self):
#调用未绑定的父类方法
Fish.__init__(self)
self.hungry = True
def eat(self):
if self.hungry:
print("吃货的梦想就是天天有吃的^_^")
self.hungry = False
else:
print("太撑了,吃不下了")
>>> shark = Shark()
>>> shark.move()
我的位置是: 6 0
>>> shark = Shark()
>>> Fish.__init__(shark)
>>> shark.move()
我的位置是: 6 1
使用 super 函数(完美方法)
import random as r
class Fish:
def __init__(self):
self.x = r.randint(0, 10)
self.y = r.randint(0, 10)
def move(self):
self.x -= 1
print("我的位置是:", self.x, self.y)
class Goldfish(Fish):
pass
class Shark(Fish):
def __init__(self):
#使用super函数
super().__init__()
self.hungry = True
def eat(self):
if self.hungry:
print("吃货的梦想就是天天有吃的^_^")
self.hungry = False
else:
print("太撑了,吃不下了")
>>> shark = Shark()
>>> shark.move()
我的位置是: 6 2
多重继承:就是同时继承多个父类的属性和方法。
>>> class Base1:
def foo1(self):
print("我是foo1,我为Base1代言...")
>>> class Base2:
def foo2(self):
print("我是foo2,我为Base2代言...")
>>> class C(Base1, Base2):
pass
>>> c = C()
>>> c.foo1()
我是foo1,我为Base1代言...
>>> c.foo2()
我是foo2,我为Base2代言...
课后练习
class MyClass:
def __init__(self):
return "I love FishC.com!"
>>> myClass = MyClass()
Traceback (most recent call last):
File "
class A():
def __init__(self):
print("进入A…")
print("离开A…")
class B(A):
def __init__(self):
print("进入B…")
A.__init__(self)
print("离开B…")
class C(A):
def __init__(self):
print("进入C…")
A.__init__(self)
print("离开C…")
class D(B, C):
def __init__(self):
print("进入D…")
B.__init__(self)
C.__init__(self)
print("离开D…")
这有什么危害?我举个例子,假设 A 的初始化方法里有一个计数器,那这样 D 一实例化,A 的计数器就跑两次(如果遭遇多个钻石结构重叠还要更多),很明显是不符合程序设计的初衷的(程序应该可控,而不能受到继承关系影响)。>>> d = D()
进入D…
进入B…
进入A…
离开A…
离开B…
进入C…
进入A…
离开A…
离开C…
离开D…
class A():
def __init__(self):
print("进入A…")
print("离开A…")
class B(A):
def __init__(self):
print("进入B…")
super().__init__()
print("离开B…")
class C(A):
def __init__(self):
print("进入C…")
super().__init__()
print("离开C…")
class D(B, C):
def __init__(self):
print("进入D…")
super().__init__()
print("离开D…")
>>> d = D()
进入D…
进入B…
进入C…
进入A…
离开A…
离开C…
离开B…
离开D…
动动手
第039讲 类和对象:拾遗
课堂笔记
组合
class Turtle:
def __init__(self, x):
self.num = x
class Fish:
def __init__(self, x):
self.num = x
class Pool:
def __init__(self, x, y):
self.turtle = Turtle(x)
self.fish = Fish(y)
def print_num(self):
print("水池里有乌龟 %d 只,小鱼 %d 条!" %(self.turtle.num, self.fish.num))
>>> pool = Pool(1, 10)
>>> pool.print_num()
水池里有乌龟 1 只,小鱼 10 条!
类、类对象和实例对象
>>> class E:
count = 0
>>> a = E()
>>> b = E()
>>> c = E()
>>> a.count
0
>>> b.count
0
>>> c.count
0
>>> c.count += 10
>>> c.count
10
>>> a.count
0
>>> b.count
0
>>> E.count
0
>>> E.count += 100
>>> E.count
100
>>> a.count
100
>>> b.count
100
>>> c.count
10
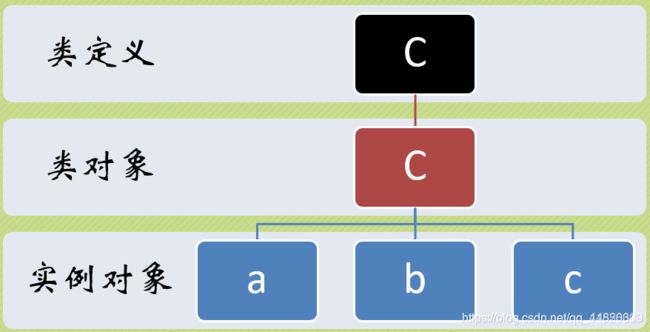
>>> class C:
def x(self):
print("X-man")
>>> c = C()
>>> c.x()
X-man
>>> c.x = 1
>>> c.x
1
>>> c.x()
Traceback (most recent call last):
File "
绑定
>>>class CC:
def setXY(self,x,y):
self.x = x
self.y = y
def printXY(self):
print(self.x,self.y)
>>>dd=CC()
>>>del CC
>>>ee=CC()
Traceback (most recent call last):
File "D:\software\lib\site-packages\IPython\core\interactiveshell.py", line 3267, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "课后练习
class C:
num = 0
def __init__(self):
self.x = 4
self.y = 5
C.count = 6
class BB:
def printBB():
print("no zuo no die")
>>> bb = BB()
>>> bb.printBB()
Traceback (most recent call last):
File "class BB:
def printBB(self):
print("no zuo no die")
>>> bb = BB()
>>> bb.printBB()
no zuo no die
0. 思考这一讲我学习的内容,请动手在一个类中定义一个变量,用于跟踪该类有多少个实例被创建
(当实例化一个对象,这个变量+1,当销毁一个对象,这个变量自动-1)。class C:
count = 0
def __init__(self):
C.count += 1
def __del__(self):
C.count -= 1
第040讲 类和对象:一些相关的BIF
课堂笔记
issubclass(class, classinfo)
关于这个函数有几点需要注意的:
isinstance(object, classinfo)
关于这个函数有几点需要注意的:
hasattr(object, name)
测试一个对象是否有指定的属性。name 要用引号把属性名引起来。>>> class C:
def __init__(self, x = 0):
self.x = x
>>> c1 = C()
>>> hasattr(c1, "x")
True
>>> hasattr(c1, x)
Traceback (most recent call last):
File "getattr(object, name[ , default] )
>>> class C:
def __init__(self, x = 0):
self.x = x
>>> c1 = C()
>>> getattr(c1, 'x')
0
>>> getattr(c1, 'y')
Traceback (most recent call last):
File "setattr(object, name, value)
>>> setattr(c1, 'y', '来自江南的你')
>>> getattr(c1, 'y', '你所访问的属性不存在')
'来自江南的你'
delattr(object, name)
property(fget = None, fset = None, fdel = None, doc = None)
>>> class C:
def __init__(self, size = 10):
self.size = size
def getSize(self):
return self.size
def setSize(self, value):
self.size = value
def delSize(self):
del self.size
x = property(getSize, setSize, delSize)
>>> c1 = C()
>>> c1.x
10
>>> c1.getSize() #直接调用property中第一个参数的方法
10
>>> c1.x = 18 #直接调用property中第二个参数的方法
>>> c1.getSize()
18
>>> c1.setSize(20)
>>> c1.x
20
>>> del c1.x
>>> c1.getSize()
Traceback (most recent call last):
File "第041讲 魔法方法:构造和析构
课堂笔记
init(self[,args…])
new(cls[, …])
>>> class CapStr(str):
def __new__(cls, string):
string = string.upper()
return str.__new__(cls, string)
>>> a = CapStr("I love fichc")
>>> a
'I LOVE FICHC'
首先我们来看一下第一个功能,具体我们可以用int来作为一个例子:
假如我们需要一个永远都是正数的整数类型,通过集成int,我们可能会写出这样的代码。class PositiveInteger(int):
def __init__(self, value):
super(PositiveInteger, self).__init__(self, abs(value))
i = PositiveInteger(-3)
print i
这是修改后的代码:class PositiveInteger(int):
def __new__(cls, value):
return super(PositiveInteger, cls).__new__(cls, abs(value))
i = PositiveInteger(-3)
print i
del(self)
>>> class C:
def __init__(self):
print("我是__init__方法,我被调用了")
def __del__(self):
print("我是__del__方法,我被调用了")
>>> c1 = C()
我是__init__方法,我被调用了
>>> c2 = c1
>>> del c1
>>> del c2
我是__del__方法,我被调用了
第042讲 魔法方法:算术运算1
>>> type(len)
<class 'builtin_function_or_method'>
>>> type(int)
<class 'type'>
>>> type(list)
<class 'type'>
所以,工厂函数就是类对象。
__add__(self, other)
定义加法的行为:+
__sub__(self, other)
定义减法的行为:-
__mul__(self, other)
定义乘法的行为:*
__truediv__(self, other)
定义真除法的行为:/
__floordiv__(self, other)
定义整数除法的行为://
__mod__(self, other)
定义取模算法的行为:%
__divmod__(self, other)
定义当被 divmod() 调用时的行为,divmod(a, b)返回一个元组:(a//b, a%b)
__pow__(self, other[, modulo])
定义当被 power() 调用或 ** 运算时的行为
__lshift__(self, other)
定义按位左移位的行为:<<
__rshift__(self, other)
定义按位右移位的行为:>>
__and__(self, other)
定义按位与操作的行为:&
__xor__(self, other)
定义按位异或操作的行为:^
__or__(self, other)
定义按位或操作的行为:
>>> class New_int(int):
def __add__(self, other):
return int.__sub__(self, other)
def __sub__(self, other):
return int.__add__(self, other)
>>> a = New_int(3)
>>> b = New_int(5)
>>> a + b
-2
>>> a - b
8
课后练习
0. 我们都知道在 Python 中,两个字符串相加会自动拼接字符串,但遗憾的是两个字符串相减却抛出异常。因此,现在我们要求定义一个 Nstr 类,支持字符串的相减操作:A – B,从 A 中去除所有 B 的子字符串。
示例:>>> a = Nstr('I love FishC.com!iiiiiiii')
>>> b = Nstr('i')
>>> a - b
'I love FshC.com!'
答:只需要重载 __sub__ 魔法方法即可。
class Nstr(str):
def __sub__(self, other):
return self.replace(other, '')
第043讲 魔法方法:算术运算2
>>> class int(int):
def __add__(self, other):
return int.__sub__(self,other)
>>> a = int('5')
>>> a
5
>>> b = int(3)
>>> a + b
2
>>> a - b
2
第044讲 魔法方法:简单定制