nlp常用任务以及各类任务常用模型
nlp常用任务以及各类任务常用模型
本文主要简单描述目前nlp方向的应用类型以及该类型下的常用方法(以及目前通用的数据集)
详细信息参考自 https://github.com/sebastianruder/NLP-progress
nlp四大任务类型
序列标注:分词/POS Tag词性标注/NER命名实体识别
分词/POS Tag词性标注
目前分词和词性标注技术已经非常成熟,常用的库有Jieba,哈工大pyltp等,以下不再赘述。
具体分词技术可以参考 https://blog.csdn.net/scarlettyellow/article/details/80458043
词性标注的目的在于得到分词之后每个词的语法属性(名词,动词,形容词等);主要任务是消除词性兼类歧义;可以应用在句法分析,词汇获取,信息抽取等应用中。
中文词性标注的难点在于中文没有屈折变化,也没有附加词缀,即一个词能够不改变形态的情况下表示多种意思,所以无法像英语那样通过词缀进行词性标注。
具体词性标注技术可以参考:
https://github.com/sebastianruder/NLP-progress/blob/master/english/part-of-speech_tagging.md
https://www.zhihu.com/question/302423008
汉语词性对照表: https://blog.csdn.net/sinat_33741547/article/details/78894163
NER命名实体识别
命名实体识别的目地的在于抽取出句子中的命名性指称项,即人名,地名等实体
中文进行命名实体识别的难点:
- 中文没有空格作为每个词的分隔,没有英文当中的大小写(英文中地名等相关名词一般为大写)。
- 中文的词非常灵活,有时不通过上下文无法判断出时候是命名实体,并且在不同的语境中同一个词表示的实体可能不同。
- 中文存在严重的词嵌套现象。
- 中文多数词会进行简化表达。
命名实体识别和词性标注一样可以看作是一个序列标注问题,即可以使用相同的统计学习方法(HMM,CRF等),也可以使用神经网络(LSTM等),目前比较流行的是神经网络+传统机器学习方法(RNN-CRF+Flair等)。
具体技术可参考:
https://www.cnblogs.com/robert-dlut/p/6847401.html
https://blog.csdn.net/ARPOSPF/article/details/81106212
相关模型和数据集:
https://github.com/sebastianruder/NLP-progress/blob/master/english/named_entity_recognition.md
分类任务:文本分类(Text classification)/情感分析
文本分类
文本分类分为基于sentence和基于document两大类,是nlp领域最经典的应用场景之一。文本分类的核心要点在于是否能得到好的文本向量表示,即好的文本向量(更好地代表原文本的特征)能够显著地提升分类精度。
为了得到较为合理化的embedding,目前nlp做的最好的是基于attention机制的各大预训练模型(Transformer, BERT, ERNIE, XLNet, GPT等)。
相关模型和数据集:
https://github.com/sebastianruder/NLP-progress/blob/master/english/text_classification.md
情感分析
情感分析也可以看作是一个特殊的分类任务,类别不同于一般的文本类别,例如评论类别的识别(好的评论或者不好的评论),重点在于分析文本所蕴含的情感。
具体描述:https://www.jianshu.com/p/e424061acc51
相关模型和数据集:
https://github.com/sebastianruder/NLP-progress/blob/master/english/sentiment_analysis.md
句子关系判断:QA问答/自然语言推理(Natural language inference)
QA问答
QA系统发展:
(一) 基于检索(IR)匹配: 根据关键词在文本库中搜索相关文档,并进行降序排序,然后从文档中提取答案。
(二) 知识图谱(结构化文本),基于知识库(KB-QA): 通过把大量知识通过一定格式汇聚起来形成知识库。

知识库问答的主流方法
1)语义解析(Semantic Parsing),主体思想是将自然语言转化为一系列形式化的逻辑形式(logic form),通过对逻辑形式进行自底向上的解析,得到一种可以表达整个问题语义的逻辑形式,通过相应的查询语句(类似lambda-Caculus)在知识库中进行查询,从而得出答案。
2)信息抽取(Information Extraction),通过提取问题中的实体,通过在知识库中查询该实体可以得到以该实体节点为中心的知识库子图,子图中的每一个节点或边都可以作为候选答案,通过观察问题依据某些规则或模板进行信息抽取,得到问题特征向量,建立分类器通过输入问题特征向量对候选答案进行筛选,从而得出最终答案。
3)向量建模(Vector Modeling),根据问题得出候选答案,把问题和候选答案都映射为分布式表达(Distributed Embedding),通过训练数据对该分布式表达进行训练,使得问题和正确答案的向量表达的得分(通常以点乘为形式)尽量高。
具体关于知识库的介绍: https://zhuanlan.zhihu.com/p/25735572
(三) MRC机器阅读理解: 给定一个问题 Q 和一个与 Q 相关的文档 D,自动得到 Q 对应的答案 A。
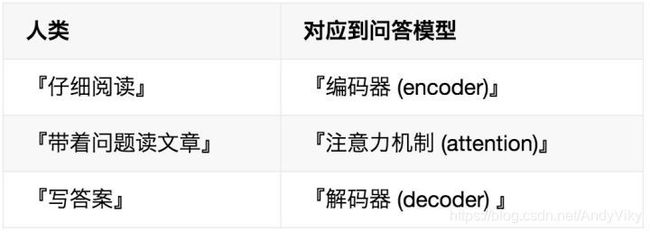
主要方法
1)匹配式:给出文章,问题和答案集,从答案集中选出最高得分的答案,像选择题。
2)抽取式:从文档中抽取出答案,前提是文档中包括问题答案。
3)生成式:当文档中没有答案时需要机器去自动生成答案,该方法与抽取式不同之处在于Encoder不同。
具体关于阅读理解的介绍:https://zhuanlan.zhihu.com/p/41217854
相关论文:https://github.com/dapurv5/awesome-question-answering
相关数据集:https://github.com/sebastianruder/NLP-progress/blob/master/english/question_answering.md#ms-marco
自然语言推理
自然语言推理主要是判断两个句子或者两个词之间的语义关系,即前提(premise)和假设(hypothesis)之间的蕴含关系。该任务最终会退化为一个分类任务,即去判断两个句子或词之间的关系的类别,一般情况下有三类(Entailment,Contradiction,Neutral)。
推理类型
- 词级别的推理
- 句子级别的推理
- 词匹配方法
常用数据集
- SNLI 包含 550k hypothesis/premise pairs, 目前测试精度最高的模型是 MT-DNN 和 SemBERT, 精度在91.6%。
- MultiNLI 包含 433k hypothesis/premise pairs, 相比于SNLI,MultiNLI提供了多题材数据, 目前最好模型是 RoBERTa。
- SciTail 包含 27k hypothesis/premise pairs, 和上面两个数据的不同之处在于该数据集来自于真实场景下四年级科学问答数据。
相关模型和数据集:
https://github.com/sebastianruder/NLP-progress/blob/master/english/natural_language_inference.md
生成式任务:机器翻译/文本摘要
机器翻译
简单来说机器翻译的基础框架就是编码解码器。通过网络捕捉不同语言之间的特性进行不同语言之间的转换(squence-to-squence)。
目前比较流行的机器翻译架构是基于self-attention的,自transformer提出之后,几乎所有的由LSTM或者CNN实现的squence-to-squence模型都用attention机制替换了一遍。
相关模型:https://github.com/sebastianruder/NLP-progress/blob/master/english/machine_translation.md
文本摘要
主要方法
1)抽取式(extractive):按照一定的权重,从原文中寻找跟中心思想最接近的一条或几条句子,缺点是句子不太通顺。
2)生成式(abstractive):通读原文后,在理解整篇文章意思的基础上,按自己的话生成流畅的翻译。(transformer),基础架构也是Encoder-Decoder。
相关模型和数据集:https://github.com/sebastianruder/NLP-progress/blob/master/english/summarization.md