7.性能测试工具Locust的初级使用
转载*请注明原始出处:http://blog.csdn.net/a464057216/article/details/48392169
后续此博客不再更新,欢迎大家搜索关注微信公众号“测开之美”,测试开发工程师技术修炼小站,持续学习持续进步。
安装完Locust工具后,只需要编写一个简单Python文件即可对系统进行负载测试。下面举个例子:
from locust import Locust, TaskSet, task
class UserBehavior(TaskSet):
@task
def job(self):
pass
class User(Locust):
task_set = UserBehavior
min_wait = 1000
max_wait = 3000
然后在终端输入:
mars@mars-Ideapad-V460:~/test$ locust
[2015-09-12 10:46:36,876] mars-Ideapad-V460/INFO/locust.main: Starting web monitor at *:8089
[2015-09-12 10:46:36,919] mars-Ideapad-V460/INFO/locust.main: Starting Locust 0.7.3
然后在浏览器中访问localhost:8089,弹出如下页面:
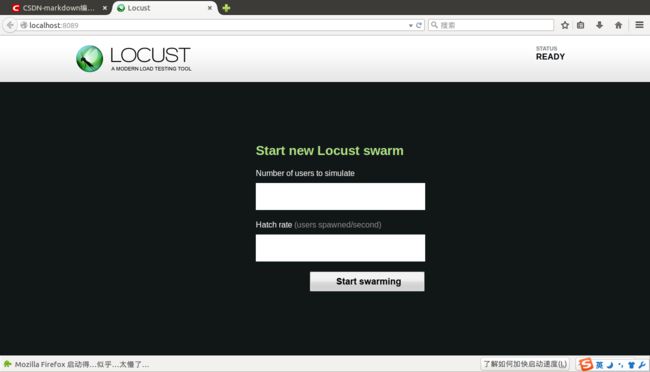
第一行Number of users to simulate是模拟用户的数量,第二行Hatch rate (users spawned/second表示产生模拟用户的速度,所有用户产生完后开始测试统计,填写完成后点击“Start swarming”即可开始测试:
这个页面的解释我们后续介绍,下面写解释一下locustfile.py里面的内容。每个locustfile.py里面最少包含两个内容:用户的基本信息、用户的任务信息。
用户的基本信息由示例中的User(继承自Locust)定义,min_wait和max_wait定义了每个用户执行两个任务之间的等待时间的上下限,单位是毫秒,task_set属性指向一个TaskSet类,TaskSet类定义了用户的任务信息。本例中每个用户执行每个任务之间会等待1~3秒之间的一段随机时间。
用户的任务信息由示例中UserBehavior(继承自TaskSet)定义,每个任务由@task装饰器定义,一个TaskSet中可以有多个任务,也可以指定任务的执行权重。本例中用户只有一个任务,就是什么也不做。
TaskSet还可以有多种方式定义,比如:
from locust import HttpLocust, TaskSet
def job1(l):
l.client.get('/')
def job2(l):
l.client.get('/s?ie=utf-8&f=8&rsv_bp=0&rsv_idx=1&tn=baidu&wd=a&rsv_pq=d3e6a1bc0000db99&rsv_t=b2a65Q2Jsj%2FAFujUB%2F6qDEOhO1ylxo5ORDWYiZj%2FHU%2B5AhmDDqDWQQKTlzE&rsv_enter=1&rsv_sug3=1&rsv_sug1=2&rsv_sug2=0&inputT=206&rsv_sug4=207')
class UserBehavior(TaskSet):
tasks = {job1:1, job2:2}
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 3000
max_wait = 6000
在终端运行locustfile2.py:
mars@mars-Ideapad-V460:~/test$ locust -H https://www.baidu.com -f locustfile2.py
[2015-09-12 11:22:01,766] mars-Ideapad-V460/INFO/locust.main: Starting web monitor at *:8089
[2015-09-12 11:22:01,767] mars-Ideapad-V460/INFO/locust.main: Starting Locust 0.7.3
运行结果如下:
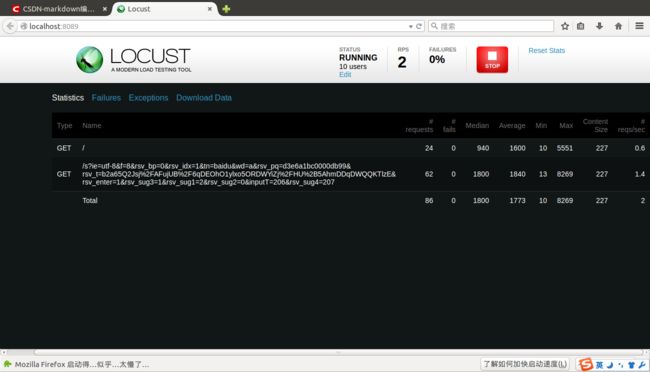
这一次TaskSet类的定义中不再使用@task修饰符,而是使用tasks属性,{job1:1, job2:2}表示每个用户执行job2的频率是job1的两倍,也可以使用如下语句:
tasks = [(job1,1), (job2,2)]
或者不指定每个任务的执行权重(也就是1:1):
tasks = [job1, job2]
job1和job2是一个可调用的对象,有一个Locust类作为参数(本例是HttpLocust)。
这个例子中还使用了HttpLocust(继承自Locust)用于Web测试,它比Locust类多了client属性,相当于是一个 HttpSession。
运行第二个例子的时候,使用的如下命令行:
mars@mars-Ideapad-V460:~/test$ locust -H https://www.baidu.com -f locustfile2.py
[2015-09-12 11:22:01,766] mars-Ideapad-V460/INFO/locust.main: Starting web monitor at *:8089
[2015-09-12 11:22:01,767] mars-Ideapad-V460/INFO/locust.main: Starting Locust 0.7.3
其中-H指定了待测试的Web服务的URL前缀,所以job1其实访问的是https://www.baidu.com/,job2访问的是https://www.baidu.com/s?**********。-f指定测试脚本的位置,本例中是locustfile2.py。
而第一个例子中,没有指定-H,是因为第一个例子不是测试Web应用,使用默认的None就够,没有指定-f,是因为Locust工具会自动在当前目录寻找locustfile.py执行。
如果要在多台机器之间分布式运行Locust,需要指定一个master机器,然后在master机器上执行如下命令:
$ locust -f locustfile.py -H http://www.sample.com --master
将其他机器作为slave,然后在这些slave上运行如下命令:
$ locust -f locustfile.py -H http://www.sample.com --slave --master-host=
关于locust的更多命令行功能可以使用locust --help命令看一下。
如果觉得我的文章对您有帮助,欢迎关注我(CSDN:Mars Loo的博客)或者为这篇文章点赞,谢谢!