如何成为数据科学家_成为数据科学家
如何成为数据科学家

This blogpost is an excerpt of Springboard’s free guide to data science jobs and originally appeared on the Springboard blog.
该博客文章摘录自Springboard的数据科学工作免费指南,该文章最初出现在Springboard 博客上 。
数据科学技能 (Data Science Skills)
Most data scientists use a combination of skills every day, some of which they have taught themselves on the job or otherwise. They also come from various backgrounds. There isn’t any one specific academic credential that data scientists are required to have.
大多数数据科学家每天都使用多种技能,其中一些技能是他们在工作中或其他方面自学的。 他们也有不同的背景。 数据科学家不需要具备任何一种特定的学术资格。
All the skills discussed in this section can be self-learned. We’ve laid out some resources to get you started down that path. Consider it a guide on how to become a data scientist.
本节中讨论的所有技能都可以自学。 我们已经安排了一些资源,以使您入门。 将其视为如何成为数据科学家的指南。
数学 (Mathematics)
Mathematics is an important part of data science. Make sure you know the basics of university math from calculus to linear algebra. The more math you know, the better.
数学是数据科学的重要组成部分。 确保您了解从微积分到线性代数的大学数学基础。 您知道的数学越多越好。
When data gets large, it often gets unwieldy. You’ll have to use mathematics to process and structure the data you’re dealing with.
当数据变大时,它通常变得笨拙。 您将不得不使用数学来处理和构造要处理的数据。
You won’t be able to get out of knowing calculus, and linear algebra if you missed those topics in undergrad. You’ll need to understand how to manipulate matrices of data and get a general idea behind the math of algorithms.
如果您错过了本科课程中的这些主题,您将无法摆脱对微积分和线性代数的了解。 您将需要了解如何处理数据矩阵,并获得有关算法数学的一般认识。
Resources: This list of 15 Mathematics MOOC courses can help you catch up with math skills. MIT also offers an open course specifically on the mathematics of data science.
资源:这份15项MOOC数学课程的清单可以帮助您掌握数学技能。 麻省理工学院还提供专门针对数据科学数学的开放课程。
统计 (Statistics)
You must know statistics to infer insights from smaller data sets onto larger populations. This is the fundamental law of data science. Statistics will pave your path on how to become a data scientist.
您必须了解统计信息,才能从较小的数据集中推断出较大的数据。 这是数据科学的基本定律。 统计信息将为您成为一名数据科学家铺平道路。
You need to know statistics to play with data. Statistics allows you to better understand patterns observed in data, and extract the insights you need to make reasonable conclusions. For instance, understanding inferential statistics will help you make general conclusions about everybody in a population from a smaller sample.
您需要了解统计信息才能处理数据。 统计信息使您可以更好地理解数据中观察到的模式,并提取需要做出合理结论的见解。 例如,了解推论统计将帮助您从较小的样本中得出总体中每个人的一般结论。
To understand data science you must know the basics of hypothesis testing, and design experiments to understand the meaning and context of your data.
要了解数据科学,您必须了解假设检验的基础知识,并必须设计实验来了解数据的含义和上下文。
Resources: Our blog published a primer on how Bayes Theorem, probability and stats intersect with one another. The post forms a good basis for understanding the statistical foundation of how to become a data scientist.
资源:我们的博客发布了有关贝叶斯定理,概率和统计量如何相交的入门文章。 该职位为理解如何成为数据科学家的统计基础奠定了良好的基础。
演算法 (Algorithms)
Algorithms are the ability to make computers follow a certain set of rules or patterns. Understanding how to use machines to do your work is essential to processing and analyzing data sets too large for the human mind to process.
算法是使计算机遵循一组特定规则或模式的能力。 了解如何使用机器来完成您的工作对于处理和分析对于人的思维来说太大的数据集至关重要。
In order for you to do any heavy lifting in data science, you’ll have to understand the theory behind algorithm selection and optimization. You’ll have to decide whether or not your problem demands a regression analysis, or an algorithm that helps classify different data points into defined categories.
为了使您在数据科学领域做任何繁重的工作,您必须了解算法选择和优化背后的理论。 您必须决定您的问题是否需要回归分析,或者是一种有助于将不同数据点分类为已定义类别的算法。
You’ll want to know many different algorithms. You’ll also want to learn the fundamentals of machine learning. Machine learning is what allows for Amazon to recommend you products based on your purchase history without any direct human intervention. It is a set of algorithms that will use machine power to unearth insights for you.
您将需要了解许多不同的算法。 您还将需要学习机器学习的基础知识。 借助机器学习,Amazon可以根据您的购买历史向您推荐产品,而无需任何人工干预。 它是一组算法,将使用机器功能为您发掘见解。
To deal with massive datasets you’ll need to use machines to extend your thinking.
为了处理海量数据集,您将需要使用机器来扩展您的思维。
Resources: This guide by KDNuggets helps explain ten common data science algorithms in plain English. Here are 19 free public datasets so you can practice implementing different algorithms on data.
资源:本指南由KDNuggets有助于解释10共同数据的科学算法, 用简单的英语 。 这里有19个免费的公共数据集,因此您可以练习对数据实施不同的算法。
数据可视化 (Data Visualization)
Finishing your data analysis is only half the battle. To drive impact, you will have to convince others to believe and adopt your insights.
完成数据分析只是成功的一半。 为了产生影响,您必须说服他人相信并采纳您的见解。
Human beings are visual creatures. According to 3M and Zabisco, almost 90% of the information transmitted to your brain is visual in nature, and visuals are processed 60,000 times faster than text.
人类是视觉生物。 根据3M和Zabisco的说法,传递到您大脑的信息中,几乎90%是自然的视觉信息,视觉信息的处理速度比文本快60,000倍。
Data visualization is the art of presenting information through charts and other visual tools, so that the audience can easily interpret the data and draw insights from it. What information is best presented in a bar chart and what types of data should we present in a scatter plot?
数据可视化是通过图表和其他可视化工具呈现信息的艺术,以便观众可以轻松地解释数据并从中获取见解。 条形图中最好显示哪些信息,散点图中应该显示什么类型的数据?
Human beings are wired to respond to visual cues. The better you can present your data insights, the more likely it is that someone will take action based on them.
人类被连线以响应视觉提示。 您越能表现出数据见解,就越有可能有人根据这些见解采取行动。
Resources: We’ve got a list of 31 free data visualization tools you can play around with. Nathan Yau’s FlowingData blog is filled with data visualization tips and tricks that will bring you to the next level.
资源:我们列出了31种免费的数据可视化工具供您使用。 内森· 丘( Nathan Yau)的FlowingData博客中充斥着数据可视化提示和技巧,这些技巧将使您进入一个新的高度。
商业知识 (Business Knowledge)
Data means little without its context. You have to understand the business you’re analyzing. Clarity is the centerpiece of how to become a data scientist.
没有上下文,数据意义不大。 您必须了解要分析的业务。 清晰性是如何成为数据科学家的核心。
Most companies depend on their data scientists not just to mine data sets, but also to communicate their results to various stakeholders and present recommendations that can be acted upon.
大多数公司不仅依靠其数据科学家来挖掘数据集,而且还需要将其结果传达给各个利益相关者,并提出可以采取行动的建议。
The best data scientists not only have the ability to work with large, complex data sets, but also understand intricacies of the business or organization they work for.
最好的数据科学家不仅具有处理大型复杂数据集的能力,而且还了解其工作的业务或组织的复杂性。
Having general business knowledge allows them to ask the right questions, and come up with insightful solutions and recommendations that are actually feasible given any constraints that the business might impose.
具有一般的业务知识可以使他们提出正确的问题,并提出有见地的解决方案和建议,这些建议和建议在业务可能施加的任何约束条件下实际上是可行的。
Resources: This list of free business courses can help you gain the knowledge you need. Our Data Analytics for Business course can help you skill up on this dimension with a mentor.
资源:此免费商业课程列表可以帮助您获得所需的知识。 我们的企业数据分析课程可以帮助您在导师的指导下熟练掌握这一方面。
领域专长 (Domain Expertise)
As a data scientist, you should know the business you work for and the industry it lives in.
作为数据科学家,您应该了解您所从事的业务及其所处的行业。
Beyond having deep knowledge of the company you work for, you’ll also have to understand the field it works in for your business insights to make sense. Data from a biology study can have a drastically different context than data gleaned from a well-designed psychology study. You should know enough to cut through industry jargon.
除了对您所工作的公司有深入的了解之外,您还必须了解其工作领域以使您的业务见解有意义。 与从精心设计的心理学研究中收集的数据相比,生物学研究中的数据具有截然不同的背景。 您应该了解足够的知识来克服行业术语。
Resources: This will be largely industry-dependent. You’ll have to find your own way and learn as much about your industry as possible!
资源:这在很大程度上取决于行业。 您将必须找到自己的方式,并尽可能多地了解您的行业!
数据科学工具 (Data Science Tools)
分析思维 (Analytical Mind)
You’ll need an analytical mindset to do well in data science. A lot of data science involves solving problems with a sharp and keen mind.
您需要具有分析性思维才能在数据科学中表现出色。 许多数据科学都需要敏锐而敏锐的头脑来解决问题。
Resources: Keep your mind sharp with books and puzzles. A site like Lumosity can help make sure you’re cognitively sharp at all times.
资源:通过书籍和拼图保持头脑敏锐。 像Lumosity这样的网站可以帮助确保您始终保持认知敏锐。
With your skill set developed, you’ll now need to learn how to use modern data science tools. Each tool has its strengths and weaknesses, and each plays a different role in the data science process. You can use one of them, or you can use all of them. What follows is a broad overview of the most popular tools in data science as well as the resources you’ll need to learn them properly if you want to dive deeper.
随着技能的发展,您现在需要学习如何使用现代数据科学工具。 每个工具都有其优点和缺点,并且在数据科学过程中扮演着不同的角色。 您可以使用其中之一,也可以全部使用。 接下来是对数据科学中最受欢迎的工具的全面概述,以及如果您想更深入地学习,则需要适当地学习这些资源。
档案格式 (File Formats)
Data can be stored in different file formats. Here are some of the most common:
数据可以以不同的文件格式存储。 以下是一些最常见的方法:
CSV: Comma separated values. You may have opened this sort of file with Excel before. CSVs separate out data with a delimiter, a piece of punctuation that serves to separate out different data points.
CSV :逗号分隔的值。 您以前可能已经使用Excel打开了此类文件。 CSV用分隔符分隔数据,分隔符是一种标点符号,用于分隔不同的数据点。
SQL: SQL, or structured query language, stores data in relational tables. If you go from the right to a column to the left, you’ll get different data points on the same entity (for example, a person will have a value in the AGE, GENDER, and HEIGHT categories).
SQL :SQL或结构化查询语言将数据存储在关系表中。 如果从右边转到左边的列,则将在同一实体上获得不同的数据点(例如,某人的年龄,性别和身高类别中的值)。
JSON: Javascript Object Notation is a lightweight data exchange format that is both human and machine-readable. Data from a web server is often transmitted in this format.
JSON :Javascript对象表示法是一种轻量级的数据交换格式,既可以人工读取,也可以通过机器读取。 来自Web服务器的数据通常以这种格式传输。
电子表格 (Excel)
Introduction to Excel: Excel is often the gateway to data science, and something that every data scientist can benefit from learning.
Excel简介 :Excel通常是通向数据科学的门户,每位数据科学家都可以从中受益。
Excel allows you to easily manipulate data with what is essentially a What You See Is What You Get editor that allows you to perform equations on data without working in code at all. It is a handy tool for data analysts who want to get results without programming.
Excel使您可以使用本质上是“所见即所得”编辑器轻松地操纵数据,该编辑器使您可以对数据执行方程式,而无需使用任何代码。 对于想要无需编程即可获得结果的数据分析师来说,这是一个方便的工具。
Excel is easy to get started with, and it’s a program that anybody who is in analytics will intuitively grasp. It can be useful to communicate data to people who may not have any programming skills: they should still be able to play with the data.
Excel易于上手,这是任何从事分析的人员都会直观地掌握的程序。 与可能没有任何编程技能的人交流数据可能会很有用:他们仍然应该可以使用数据。
Who Uses This: Data analysts tend to use Excel.
谁使用此工具 :数据分析人员倾向于使用Excel。
Level of Difficulty Beginner
初学者的难度
Sample Project: Importing a small dataset on the statistics of NBA players and making a simple graph of the top scorers in the league
样例项目 :导入一个有关NBA球员统计数据的小型数据集,并制作一张有关联盟顶级得分手的简单图表
SQL (SQL)
Introduction to SQL: SQL is the most popular programming language to find data.
SQL简介 :SQL是查找数据的最流行的编程语言。
Data science needs data. SQL is a programming language specially designed to extract data from databases.
数据科学需要数据。 SQL是一种专门设计用于从数据库提取数据的编程语言。
SQL is the most popular tool used by data scientists. Most data in the world is stored in tables that will require SQL to access. You’ll be able to filter and sort through the data with it.
SQL是数据科学家最常用的工具 。 世界上大多数数据都存储在需要SQL访问的表中。 您将能够使用它过滤和排序数据。
Who Uses This: Data analysts and some data engineers tend to use SQL.
谁使用此工具 :数据分析人员和一些数据工程师倾向于使用SQL。
Level of Difficulty: Beginner
难度等级 :初学者
Sample Project: Using a query to select the top ten most popular songs from a SQL database of the Billboard 100.
示例项目 :使用查询从Billboard 100SQL数据库中选择最流行的十首歌曲。
Python (Python)
Introduction to Python Python is a powerful, versatile programming language for data science.
Python简介 Python是一种功能强大的通用数据科学编程语言。
Once you download Rodeo, Yhat’s Python IDE, you’ll quickly realize how intuitive Python is. A versatile programming language built for everything from building websites to gathering data from across the web, Python has many code libraries dedicated to making data science work easier.
下载Yhat的Python IDE Rodeo之后,您将很快意识到Python的直观性。 Python是一种通用的编程语言,适用于从构建网站到从Web收集数据的所有事物,Python具有许多专用于简化数据科学工作的代码库。
Python is a versatile programming language with a simple syntax that is easy to learn.
Python是一种通用的编程语言,具有易于学习的简单语法。
The average salary range for jobs with Python in their description is around $102,000. Python is the most popular programming language taught in universities: the community of Python programmers is only going to be larger in the years to come. The Python community is passionate about teaching Python, and building useful tools that will save you time and allow you to do more with your data.
使用Python的工作的平均薪资范围在$ 102,000左右 。 Python是大学中教授的最流行的编程语言:Python程序员社区在未来几年中只会越来越大。 Python社区热衷于教授Python,并构建有用的工具,这些工具可以节省您的时间,并允许您对数据做更多的事情。
Many data scientists use Python to solve their problems: 40% of respondents to a definitive data science survey conducted by O’Reilly used Python, which was more than the 36% who used Excel.
许多数据科学家都使用Python解决了他们的问题:由O'Reilly进行的权威数据科学调查的40%的受访者使用Python,超过了使用Excel的36%。
Who Uses This: Data engineers and data scientists will use Python for medium-size data sets.
谁使用此工具 :数据工程师和数据科学家将使用Python处理中型数据集。
Level of Difficulty: Intermediate
难度等级 :中级
Sample Project: Using Python to source tweets from celebrities, then doing an analysis of the most frequent words used by applying programming rules.
示例项目 :使用Python从名人那里获取推文,然后通过应用编程规则来分析最常用的单词。
[R (R)
Introduction to R: R is a staple in the data science community because it is designed explicitly for data science needs. It is the most popular programming environment in data science with 43% of data professionals using it.
R简介 :R是数据科学界的重要组成部分,因为它是专门为满足数据科学需求而设计的。 它是数据科学中最受欢迎的编程环境,有43%的数据专业人员正在使用它。
R is a programming environment designed for data analysis. R shines when it comes to building statistical models and displaying the results.
R是为数据分析而设计的编程环境。 R在建立统计模型和显示结果时大放异彩。
R is an environment where a wide variety of statistical and graphing techniques can be applied.
R是可以应用各种统计和图形技术的环境。
The community contributes packages that, similar to Python, can extend the core functions of the R codebase so that it can be applied to specific problems such as measuring financial metrics or analyzing climate data.
该社区提供了类似于Python的软件包,可以扩展R代码库的核心功能,以便可以将其应用于特定问题,例如度量财务指标或分析气候数据。
Who Uses This: Data engineers and data scientists will use R for medium-size data sets.
谁使用此工具 :数据工程师和数据科学家将R用于中等大小的数据集。
Level of Difficulty: Intermediate
难度等级 :中级
Sample Project: Using R to graph stock market movements over the last five years.
样本项目 :使用R绘制过去五年中的股市走势图。
大数据工具 (Big Data Tools)
Big data comes from Moore’s Law, a theory that computing power doubles every two years. This has led to the rise of massive data sets generated by millions of computers. Imagine how much data Facebook has at any given time!
大数据来自摩尔定律 ,这是计算能力每两年翻一番的理论。 这导致了数百万台计算机生成的海量数据集的兴起。 想象一下Facebook在任何给定时间拥有多少数据!
Any data set that is too large for conventional data tools such as SQL and Excel can be considered big data, according to McKinsey. The simplest definition is that big data is data that can’t fit onto your computer.
麦肯锡认为,对于常规数据工具(例如SQL和Excel)而言,任何太大的数据集都可以视为大数据 。 最简单的定义是,大数据是无法容纳在计算机上的数据。
Here are tools to solve that problem:
以下是解决该问题的工具:
Hadoop的 (Hadoop)
Introduction to Hadoop: By using Hadoop, you can store your data in multiple servers while controlling it from one.
Hadoop简介 :通过使用Hadoop,您可以将数据存储在多台服务器中,同时从一台服务器进行控制。
The solution is a technology called MapReduce. MapReduce is an elegant abstraction that treats a series of computers as it were one central server. This allows you to store data on multiple computers, but process it through one.
解决方案是一种称为MapReduce的技术。 MapReduce是一种优雅的抽象,将一系列计算机视为一个中央服务器。 这使您可以将数据存储在多台计算机上,但可以一台处理。
Hadoop is an open-source ecosystem of tools that allow you to MapReduce your data and store enormous datasets on different servers. It allows you to manage much more data than you can on a single computer.
Hadoop是一种开放源代码的工具生态系统,可让您MapReduce数据并将巨大的数据集存储在不同的服务器上。 与单台计算机相比,它可以管理更多的数据。
Who Uses This: Data engineers and data scientists will use Hadoop to handle big data sets.
谁使用此工具 :数据工程师和数据科学家将使用Hadoop处理大数据集。
Level of Difficulty:Advanced
难度等级 :高级
Sample Project: Using Hadoop to store massive datasets that update in real time, such as the number of likes Facebook users generate.
示例项目 :使用Hadoop存储实时更新的海量数据集,例如Facebook用户生成的点赞数。
NoSQL (NoSQL)
Introduction to NoSQL: NoSQL allows you to manage data without unneeded weight.
NoSQL简介 :NoSQL允许您管理数据而无需不必要的负担。
Tables that bring all their data with them can become cumbersome. NoSQL includes a host of data storage solutions that separate out huge data sets into manageable chunks.
随身携带所有数据的表可能会变得很麻烦。 NoSQL包含许多数据存储解决方案,这些解决方案将巨大的数据集分离为可管理的块。
NoSQL was a trend pioneered by Google to deal with the impossibly large amounts of data they were storing. Often structured in the JSON format popular with web developers, solutions like MongoDB have created databases that can be manipulated like SQL tables, but which can store the data with less structure and density.
NoSQL是Google率先开发的一种趋势,用于处理它们存储的大量数据。 MongoDB之类的解决方案通常以Web开发人员流行的JSON格式进行结构化,创建的数据库可以像SQL表一样进行操作,但是可以以较少的结构和密度存储数据。
Who Uses This: Data engineers and data scientists will use NoSQL for big data sets, often website databases for millions of users.
谁使用此工具 :数据工程师和数据科学家将NoSQL用于大数据集,通常是数百万用户的网站数据库。
Level of Difficulty: Advanced
难度等级 :高级
Sample Project: Storing data on users of a social media application that is deployed on the web.
示例项目 :将数据存储在Web上部署的社交媒体应用程序的用户上。
整合在一起:数据科学过程中的工具 (Bringing It All Together: Tools in the Data Science Process)
Each one of the tools we’ve described is complementary. They each have their strengths and weaknesses, and each one can be applied to different stages in the data science process.
我们描述的每种工具都是互补的。 它们每个都有其优点和缺点,并且每个都可以应用于数据科学过程的不同阶段。
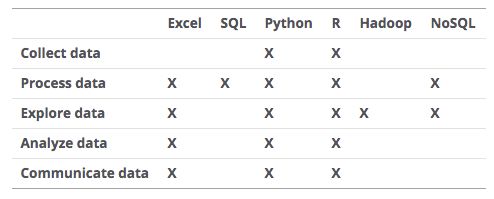
收集数据 (Collect Data)
Sometimes it isn’t doing the data analysis that is hard, but finding the data you need. Thankfully, there are many resources.
有时,并不是要进行困难的数据分析,而是要找到所需的数据。 值得庆幸的是,这里有很多资源。
You can create datasets by taking data from what is called an API or an application programming interface that allows you to take structured data from certain providers. You’ll be able to query all kinds of data from Twitter, Facebook, and Instagram among others.
您可以通过从所谓的API或应用程序编程接口获取数据来创建数据集,该API或应用程序编程接口允许您从某些提供程序获取结构化数据。 您将能够查询来自Twitter , Facebook和Instagram等的各种数据。
If you want to play around with public datasets, the United States government has made some free to all. The most popular datasets are tracked on Reddit. Dataset search engines such as Quandl allow you to search for the perfect dataset.
如果您想使用公共数据集, 美国政府已经向所有人免费提供了一些。 在Reddit上跟踪最受欢迎的数据集 。 诸如Quandl之类的数据集搜索引擎使您可以搜索理想的数据集。
Springboard has compiled 19 of our favorite public datasets on our blog to help you out in case you ever need good data right away.
Springboard已在我们的博客上编译了19个我们最喜欢的公共数据集 ,以帮助您在需要即时数据的情况下提供帮助。
Looking for something a little less serious? Check out Yhat’s 7 Datasets You’ve Likely Never Seen Before, including one on pigeon racing!
寻找一些不太严重的东西? 查看您以前从未见过的 Yhat的7个数据集 ,包括一个赛鸽比赛的数据集 !
Python supports most data formats. You can play with CSVs or you can play with JSON sourced from the web. You can import SQL tables directly into your code.
Python支持大多数数据格式。 您可以使用CSV播放,也可以使用来自网络的JSON播放。 您可以将SQL表直接导入代码中。
You can also create datasets from the web. The Python requests library scrapes data from different websites with a line of code. You’ll be able to take data from Wikipedia tables, and once you’ve cleaned the data with the beautifulsoup library, you’ll be able to analyze them in-depth.
您也可以从网上创建数据集。 Python请求库使用一行代码从不同的网站抓取数据。 您将能够从Wikipedia表中获取数据,并使用beautifulsoup库清除了数据后,就可以对其进行深入分析。
R can take data from Excel, CSV, and from text files. Files built in Minitab or in SPSS format can be turned into R dataframes.
R可以从Excel,CSV和文本文件中获取数据。 可以将以Minitab或SPSS格式构建的文件转换为R数据帧。
The Rvest package will allow you to perform basic web scraping, while magrittr will clean and parse the information for you. These packages are similar to the requests and beautifulsoup libraries in Python.
Rvest软件包将允许您执行基本的Web抓取,而magrittr将为您清理和解析信息。 这些软件包类似于Python中的request和beautifulsoup库。
处理数据 (Process Data)
Excel allows you to easily clean data with menu functions that can clean duplicate values, filter and sort columns, and delete rows or columns of data.
Excel使您能够使用菜单功能轻松清理数据,该功能可以清理重复值,过滤和排序列以及删除数据行或列。
SQL has basic filtering and sorting functions so you can source exactly the data you need. You can also update SQL tables and clean certain values from them.
SQL具有基本的过滤和排序功能,因此您可以准确地获取所需的数据。 您还可以更新SQL表并从中清除某些值。
Python uses the Pandas library for data analysis. It is much quicker to process larger data sets than Excel, and has more functionality.
Python使用Pandas库进行数据分析。 与Excel相比,处理更大的数据集要快得多,并且具有更多的功能。
You can clean data by applying programmatic methods to the data with Pandas. You can, for example, replace every error value in the dataset with a default value such as zero in one line of code.
您可以使用Pandas将编程方法应用于数据来清理数据。 例如,您可以用默认值(例如一行代码中的零)替换数据集中的每个错误值。
R can help you add columns of information, reshape, and transform the data itself. Many of the newer R libraries such as reshape2 allow you to play with different data frames and make them fit the criterion you’ve set.
R可以帮助您添加信息列,调整形状和转换数据本身。 许多较新的R库(例如reshape2)使您可以处理不同的数据帧,并使它们符合您设置的条件。
NoSQL allows you the ability to subset large data sets and to change data according to your will, which you can use to clean through your data.
NoSQL使您能够对大型数据集进行子集化,并根据自己的意愿更改数据,您可以使用它来清理数据。
探索数据 (Explore Data)
Excel can add columns together, get the averages, and do basic statistical and numerical analysis with pre-built functions.
Excel可以将列加在一起,获得平均值,并使用预建函数进行基本的统计和数值分析。
Python and Pandas can take complex rules and apply them to data so you can easily spot high-level trends.
Python和Pandas可以采用复杂的规则并将其应用于数据,因此您可以轻松地发现高级趋势。
You’ll be able to do deep time series analysis in Pandas. You could track variations in stock prices to their finest detail.
您将能够在Pandas中进行深度时间序列分析 。 您可以跟踪股价的变化,以了解其最详细的信息。
R was built to do statistical and numerical analysis of large data sets. You’ll be able to build probability distributions, apply a variety of statistical tests to your data, and use standard machine learning and data mining techniques.
R旨在对大型数据集进行统计和数值分析。 您将能够建立概率分布,对数据进行各种统计检验,并使用标准的机器学习和数据挖掘技术。
NoSQL and Hadoop both allow you to explore data on a similar level to SQL.
NoSQL和Hadoop都允许您浏览与SQL相似级别的数据。
分析数据 (Amalyze data)
Excel can analyze data at an advanced level. Use pivot tables that display your data dynamically, advanced formulas, or macro scripts that allow you to programmatically go through your data.
Excel可以分析高级数据。 使用可动态显示数据的数据透视表 , 高级公式或允许您以编程方式浏览数据的宏脚本 。
Python has a numeric analysis library: Numpy. You can do scientific computing and calculation with SciPy. You can access a lot of pre-built machine learning algorithms with the scikit-learn code library.
Python有一个数值分析库: Numpy 。 您可以使用SciPy进行科学计算和计算。 您可以使用scikit-learn代码库访问许多预构建的机器学习算法。
R has plenty of packages out there for specific analyses such as the Poisson distribution and mixtures of probability laws.
R有很多软件包可以用于特定分析,例如泊松分布和概率定律的混合。
交流数据 (Communicate Data)
Excel has basic chart and plotting functionality. You can easily build dashboards and dynamic charts that will update as soon as somebody changes the underlying data.
Excel具有基本的图表和绘图功能。 您可以轻松构建仪表板和动态图表,只要有人更改基础数据,这些仪表盘和动态图表就会立即更新。
Python has a lot of powerful options to visualize data. You can use the Matplotlib library to generate basic graphs and charts from the data embedded in your Python. If you want something that’s a bit more advanced, you could try Plot.ly and its Python API.
Python有很多强大的选项可以可视化数据。 您可以使用Matplotlib库从Python中嵌入的数据生成基本图形和图表。 如果您需要更高级的功能,可以尝试Plot.ly及其Python API 。
You can also use the nbconvert function to turn your Python notebooks into HTML documents. This can help you embed snippets of code into interactive websites or your online portfolio. Many people have used this function to create online tutorials on how to learn Python.
您还可以使用nbconvert函数将Python笔记本转换为HTML文档。 这可以帮助您将代码片段嵌入交互式网站或在线产品组合中。 许多人已经使用此功能来创建有关如何学习Python的在线教程 。
R was built to do statistical analysis and demonstrate the results. It’s a powerful environment suited to scientific visualization with many packages that specialize in graphical display of results. The base graphics module allows you to make all of the basic charts and plots you’d like from data matrices. You can then save these files into image formats such as jpg., or you can save them as separate PDFs. You can use ggplot2 for more advanced plots such as complex scatter plots with regression lines.
建立R是为了进行统计分析和证明结果 。 这是一个强大的环境,适用于科学可视化,其中包含许多专门用于结果图形显示的软件包。 基本的图形模块使您可以从数据矩阵制作所需的所有基本图表和绘图。 然后,您可以将这些文件保存为jpg。等图像格式,也可以将它们另存为单独的PDF。 您可以将ggplot2用于更高级的绘图,例如带有回归线的复杂散点图。
开始找工作 (Starting Your Job Search)
Now that you’ve gotten an idea of the skills and tools you need to know to get into data science and how to become a data scientist, it’s time to apply that theory to the practice of applying for data science jobs.
现在,您已经了解了进入数据科学所需的技能和工具以及如何成为数据科学家,现在该将该理论应用于申请数据科学工作的实践中了。
建立数据科学档案袋并恢复 (Build a Data Science Portfolio and Resume)
You need to make a great first impression to break into data science. That starts with your portfolio and your resume. Many data scientists have their own website which serves as both a repository of their work and a blog of their thoughts.
您需要打入数据科学的第一印象。 首先是您的投资组合和简历。 许多数据科学家都有自己的网站,既可以作为其工作的资料库,也可以作为其思想的博客。
This allows them to demonstrate their experience and the value they create in the data science community. In order for your portfolio to have the same effect, it must have the following traits:
这使他们能够展示自己的经验以及在数据科学界创造的价值。 为了使您的投资组合具有相同的效果,它必须具有以下特征:
– Your portfolio should highlight your best projects. Focusing on a few memorable projects is generally better than showing a large number of dilute projects. – It must be well-designed, and tell a captivating story of who you are beyond your work. – You should build value for your visitors by highlighting any impact you’ve had through your work. Maybe you built a tool that’s useful for everyone? Perhaps you have a tutorial? Showcase them here. – It should be easy to find your contact information.
–您的作品集应突出您的最佳项目。 通常,专注于一些令人难忘的项目要比展示大量稀有项目更好。 –必须精心设计,并讲述一个迷人的故事,说明您超出了工作范围。 –您应该通过突出您的工作所产生的影响为访客创造价值。 也许您构建了一个对所有人都有用的工具? 也许您有教程? 在这里展示它们。 –应该很容易找到您的联系信息。
Take a look at our mentor Sundeep Pattem’s personal portfolio for example projects.
看看我们的导师Sundeep Pattem的个人项目示例。
He’s worked on complex data problems that resonate in the real world. He has five projects dealing with healthcare costs, labor markets, energy sustainability, online education, and world economies, fields where there are plenty of data problems to solve.
他致力于解决在现实世界中引起共鸣的复杂数据问题。 他有五个项目涉及医疗保健成本,劳动力市场,能源可持续性,在线教育以及世界经济,这些领域需要解决大量数据问题。
These projects are independent of any workplace. They show that Sundeep innately enjoys creating solutions to complex problems with data science.
这些项目独立于任何工作场所。 他们表明,Sundeep与生俱来就喜欢为数据科学中的复杂问题创建解决方案。
If you’re short on project ideas, you can participate in data science competitions. Platforms like Kaggle, Datakind and Datadriven allow you to work with real corporate or social problems. By using your data science skills, you can show your ability to make a difference, and create the strongest portfolio asset of all: a demonstrated bias to action.
如果您缺少项目创意,则可以参加数据科学竞赛。 诸如Kaggle , Datakind和Datadriven之类的平台使您可以处理实际的公司或社会问题。 通过使用数据科学技能,您可以展示出有所作为的能力,并创造最强大的投资组合资产:表现出的行动偏见。
在哪里找到工作 (Where to Find Jobs)
- Kaggle offers a job board for data scientists. – You can find a list of open data scientist jobs at Indeed, the search engine for jobs. – Datajobs offers a listings site for data science. It’s a great place to see how to become a data scientist.
- Kaggle 为数据科学家提供了一个工作委员会 。 –您可以在工作搜索引擎Indeed中找到开放数据科学家工作的列表。 – Datajobs提供数据科学的列表站点。 这是了解如何成为数据科学家的好地方。
You can also find opportunities through networking and through finding a mentor. We continue to emphasize that the best job positions are often found by talking to people within the data science community. That’s how you become a data scientist.
您还可以通过网络和导师找到机会。 我们继续强调,最好的职位通常是通过与数据科学界内的人们交谈来找到的。 这就是您成为数据科学家的方式。
You’ll also be able to find opportunities for employment in startup forums. Hacker News has a job board that is exclusive to Y Combinator startups (perhaps the most prestigious startup accelerator in the world). Angellist is a database for startups looking to get funding and it has a jobs section.
您还可以在启动论坛中找到就业机会。 Hacker News的工作委员会是Y Combinator创业公司(也许是世界上最负盛名的创业加速器)专有的。 Angellist是初创企业寻求资金的数据库,并且具有“职位”部分。
王牌数据科学访谈 (Ace the Data Science Interview)
An entire book can be written on the data science interview–in fact, we did just that!
整本书都可以写在数据科学访谈上–实际上,我们就是这样做的!
If you get an interview, what do you do next? There are several kinds of questions that are always asked in a data science interview: your background, coding questions, and applied machine learning questions. You should always anticipate a mixture of technical and non-technical questions in any data science interview. Make sure you brush up on your programming and data science–and try to interweave it with your own personal story!
如果得到面试,下一步该怎么做? 在数据科学面试中总是会问几种问题 :您的背景,编码问题和应用机器学习问题。 在任何数据科学面试中,您都应该始终预见到技术和非技术问题的混合。 确保您精通编程和数据科学,并尝试将其与您自己的个人故事交织在一起!
You’ll also often be asked to analyze datasets. You’ll likely be asked culture fit and stats questions. To prepare for the coding questions, you’ll have to treat interviews on data science partly as a software engineering exercise. You should brush up on all coding interview resources, a lot of which are around online. Here is a list of data science questions you might encounter. Among some of these questions, you’ll see common ones like:
经常还会要求您分析数据集。 您可能会被问及文化适应度和统计数据问题。 要准备编码问题,您必须将对数据科学的访谈部分作为软件工程练习来对待。 您应该复习所有编码面试资源,其中很多都在线上 。 这是您可能会遇到的数据科学问题的列表。 在这些问题中,您会看到一些常见的问题,例如:
Among some of these questions, you’ll see common ones like:
在这些问题中,您会看到一些常见的问题,例如:
- Python vs R: which language do you prefer for [x] situation?
- What is K-means (a specific type of data science algorithm)? Describe when you would use it.
- Tell me a bit about the last data science project you worked on.
- What do you know about the key growth drivers for our business?
- Python vs R:在[x]情况下,您首选哪种语言?
- 什么是K均值(一种特定类型的数据科学算法)? 描述何时使用它。
- 告诉我一些有关您最近从事的数据科学项目的信息。
- 您对我们业务的主要增长动力了解多少?
The first type of question tests your programming knowledge. The second type of question tests what you know about data science algorithms, and makes you share your real-life experience with them. The third question is a deep dive into the work you’ve done with data science before. Finally, the fourth type of question will test how much you know about the business you’re interviewing with.
第一种问题测试您的编程知识。 第二类问题用来测试您对数据科学算法的了解,并让您与他们分享现实生活中的经验。 第三个问题是对您之前在数据科学领域所做的工作的深入了解。 最后,第四类问题将测试您对面试企业的了解程度。
If you can demonstrate how your data science work can help move the needle for your potential employers, you’ll impress them. They’ll know they have somebody who cares enough to look into what they’re doing, and who knows enough about the industry that they don’t have to teach you much. And that’s how to become a data scientist.
如果您能证明您的数据科学工作如何帮助您为潜在的雇主提供帮助,那么您会给他们留下深刻的印象。 他们会知道他们有足够的人关心他们正在做的事情,并且对这个行业足够了解,因此他们不需要教给您太多知识。 这就是成为数据科学家的方式。
关于跳板 (About Springboard)
翻译自: https://www.pybloggers.com/2017/01/becoming-a-data-scientist/
如何成为数据科学家