Redis学习日志(一)
底层数据结构:sds、list、dict、ziplist、intset、skiplist
1.String
Redis构建了简单动态字符串SDS来作为默认字符串表示,属于可修改字符串的值。
当一些如打印日志等不需被修改的字符串则用C语言传统字符串表示。
sds用于存储字符串、AOF缓冲区、客户端状态中的输入缓冲区等。
sds实际是char型指针,即C语言的字符串表述形式
sdshdr是redis中的简单动态字符串结构,而实际上在使用字符串时,
依旧是使用char* 而不是sdshdr,在C中可根据地址偏移,
得到该char* (sds)所在的sdshdr的地址,借用指针进行操作。
sds定义:
struct sdshdr{
int len;//记录buf数组中已使用字节长度,等于SDS保存的字符串长度
int free;//记录buf数组中未使用的字节长度
char buf[];//字符数组,用于保存字符串
}buf[]保存字符,最后一个字节保存空字符’\0’结尾,这1字节空间不计算在len属性中。
遵循空字符结尾惯例,可对C字符串函数库中进行一些重用。
/* 根据给定的初始化字符串 init 和字符串长度 initlen
* 创建一个新的 sds
* 参数
* init :初始化字符串指针
* initlen :初始化字符串的长度
* 返回值
* sds :创建成功返回 sdshdr 相对应的 sds
* 创建失败返回 NULL
* 复杂度
* T = O(N) */
sds sdsnewlen(const void *init, size_t initlen) {
struct sdshdr *sh;
// 根据是否有初始化内容,选择适当的内存分配方式
// T = O(N)
if (init) {
// zmalloc 不初始化所分配的内存
sh = zmalloc(sizeof(struct sdshdr)+initlen+1);
} else {
// zcalloc 将分配的内存全部初始化为 0
sh = zcalloc(sizeof(struct sdshdr)+initlen+1);
}
// 内存分配失败,返回
if (sh == NULL) return NULL;
// 设置初始化长度
sh->len = initlen;
// 新 sds 不预留任何空间
sh->free = 0;
// 如果有指定初始化内容,将它们复制到 sdshdr 的 buf 中
// T = O(N)
if (initlen && init)
memcpy(sh->buf, init, initlen);
// 以 \0 结尾
sh->buf[initlen] = '\0';
// 返回 buf 部分,而不是整个 sdshdr
return (char*)sh->buf;
} SDS与C字符串相比:
①SDS结构的len属性记录了字符串长度,当要获取时,复杂度仅为O(1),无需进行O(n)的遍历;
②杜绝缓冲区溢出:在对SDS字符串进行修改时,会检查SDS剩余空间(free属性)是否充足,
若不足则先进行扩展。
③减少修改字符串时的内存重分配次数
④可保存二进制数据
⑤兼容部分C字符串函数
2.链表
Redis链表结构(adlist.h/listNode)
typedef struct listNode{
struct listNode *prev;//前置节点
struct listNode *next;//后置节点
void *value;//节点值
}listNode;对listNode进行一层包装(adlist/list)
typedef struct list{
listNode *head//表头节点
listNode *tail;//表尾结点
unsigned long len;//链表包含的节点数量
void *(*dup)(void *ptr);//节点值复制函数
void (*free)(void *ptr);//节点值释放函数
int (*match)(void *ptr,void *key);//节点值对比函数
}list;|list listNode <– listNode <–listNode
|head –> value=.. –> value=..–> value=.. –>null
|tail —————————————↑
|len=3
|dup –>…..list结构中的3个listNode
|free –>….
|match –>…
Redis链表特性:
双端:链表节点有prev和next指针
无环:表头节点的prev和表尾节点的next指向null 不循环
带头指针和尾指针:list结构的head指针和tail指针
计数器:list结构的len属性保存节点个数
多态:链表节点使用void*指针保存节点值,
可通过list结构的dup、free、match属性为节点值设置类型特定函数
因此链表可保存各种不同类型的值。
(①void指针可以指向任意类型的数据,亦即可用任意数据类型的指针对void指针赋值
②可以用void指针来作为函数形参,就可以接受任意数据类型的指针作为参数)
3.字典
(map映射,用于保存键值对 key-value)
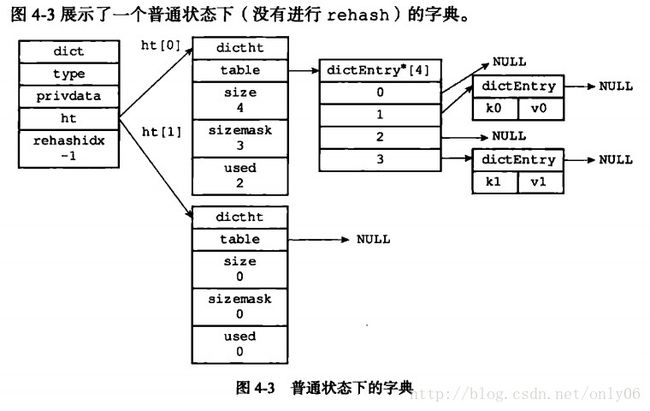
Redis哈希表结构(dict.h/dictht)
typedef struct dictht{
dictEntry **table;//哈希表数组
unsigned long size;//哈希表大小
unsigned long sizemask;//哈希表大小掩码用于计算索引值(=size-1)
unsigned long used;//已有节点数量
}dictht;table数组中每个元素指向dict.h/dictEntry结构的指针。
每个dictEntry结构保存一个键值对。size属性记录哈希表大小(table数组大小)
哈希表节点dictEntry
typedef struct dictEntry{
void *key;//键
union{ //值
void *val;
uint64_tu64;
int64_ts64;
}v;
struct dictEntry *next;//下个哈希表节点
}dictEntry;key属性保存键值对中的键,v属性保存值,值可以是一个指针、uint64_t整数或int64_t整数。
next属性指向另一个哈希表节点指针,可以将多个哈希值相同的键值对连接起来,解决键冲突问题。
例:
|dictht 两个索引值相同的键k1 k0 通过dictEntry结构的next指针连接起来
|table ----> dictEntry*[4]
|size=4 |0 -->null
|sizemask=3 |1 -->null
|used=2 |2 -->null
|3 --> dictEntry --> dictEntry -->null
|k1 |v1 |k0 |v0dict.h/dict结构表示字典(在dictht上再包装一层)
typedef struct dict{
dictType *type;//类型特定函数
void *privdata;//私有数据
dictht ht[2];//哈希表
int trehashidx;//rehash索引,当rehash不在进行时,为-1
}dict;type属性和privdata属性针对不同类型的键值对,
type指向dictType结构指针,每个dictType结构保存了一簇特定类型键值对的操作函数
privdata属性保存了需要传给特定函数的可选参数
typedef struct dictType{
unsigned int (*hashFunction)(const void *key);
void *(*keyDup) (void *privdata,const void *key);
void *(*valDup) (void *privdata,const void *key);
int (*keyCompare)(void *privdata,const void *key1,const void *key2);
void *(*keyDestructor) (void *privdata, void *key);
void *(*valDestructor) (void *privdata,void *obj);
}dictType;
ht属性是包含两个项(dictht)的数组,一般只使用ht[0]哈希表,当对ht[0]进行rehash时才使用ht[1]
rehashidx属性记录rehash,若当前没有在进行,则值为-1。
例:普通状态下(没有rehash)的字典 (图4-3普通状态下的字典)
4.哈希算法
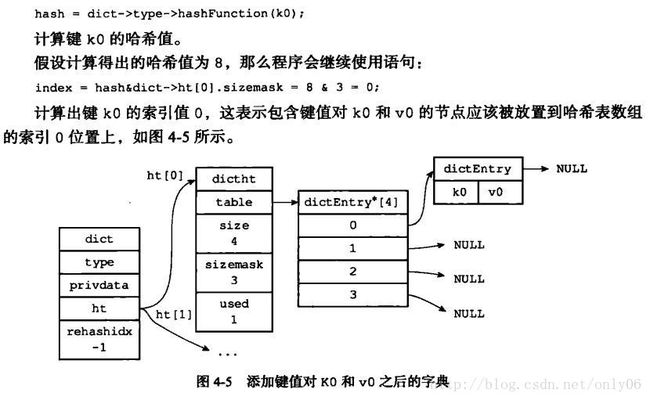
当将一个新键值对加入到字典中时,先计算键的哈希值和索引值(哈希值对sizemask取模),
再根据索引值将新键值节点放入到dictht的table数组中合适的dictEntry链表中。
hash=dict->type->hashFunction(key);
index=hash& dict->ht[x].sizemask;
例:添加一个新键值对的过程图(图4-5添加新键值对)
键冲突问题:有两个或以上数量的键分配到同一个索引上时
开放地址法(再散列,直到索引不冲突):反复计算索引,并要求有足够的索引能用来存储。
链地址法:当索引冲突时,在该索引下以链表的方式存储
Redis中dictEntry节点组成的链表没有指向尾部的指针,因此采用头插法,将新节点添加到链表表头O(1)
5.rehash
当哈希表保存的键值对逐渐增多或减少时,为了维持合理的负载因子,对哈希表大小进行相应的扩展或收缩
步骤如下:
1)为字典ht[1]哈希表分配空间,
若是扩展操作,则ht[1]的大小为第一个大于等于ht[0].used*2 的2^n (即size=2^n>=ht[0].used*2)
若是收缩操作,则ht[1]的大小为第一个大于等于ht[0].used的2^n (即size=2^n>=ht[0].used)
2)将保存在ht[0]中的所有键值对重新计算散列到ht[1]中
3)完成上述rehash操作后,释放ht[0],更换ht[1]为ht[0],创建一个新的空ht[1]为下次rehash使用
(即 free(ht[0]),*ht[0]=*ht[1],ht[1]=new dictht)
过程图(图4-8rehash扩展)

int dictRehash(dict *d, int n) {
// 只可以在 rehash 进行中时执行
if (!dictIsRehashing(d)) return 0;
// 进行 N 步迁移
// T = O(N)
while(n--) {
dictEntry *de, *nextde;
/* Check if we already rehashed the whole table... */
// 如果 0 号哈希表为空,那么表示 rehash 执行完毕
// T = O(1)
if (d->ht[0].used == 0) {
// 释放 0 号哈希表
zfree(d->ht[0].table);
// 将原来的 1 号哈希表设置为新的 0 号哈希表
d->ht[0] = d->ht[1];
// 重置旧的 1 号哈希表
_dictReset(&d->ht[1]);
// 关闭 rehash 标识
d->rehashidx = -1;
// 返回 0 ,向调用者表示 rehash 已经完成
return 0;
}
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
// 确保 rehashidx 没有越界
assert(d->ht[0].size > (unsigned)d->rehashidx);
// 略过数组中为空的索引,找到下一个非空索引
while(d->ht[0].table[d->rehashidx] == NULL) d->rehashidx++;
// 指向该索引的链表表头节点
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
// 将链表中的所有节点迁移到新哈希表
// T = O(1)
while(de) {
unsigned int h;
// 保存下个节点的指针
nextde = de->next;
/* Get the index in the new hash table */
// 计算新哈希表的哈希值,以及节点插入的索引位置
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
// 插入节点到新哈希表
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
// 更新计数器
d->ht[0].used--;
d->ht[1].used++;
// 继续处理下个节点
de = nextde;
}
// 将刚迁移完的哈希表索引的指针设为空
d->ht[0].table[d->rehashidx] = NULL;
// 更新 rehash 索引
d->rehashidx++;
}
return 1;
}哈希表扩展与收缩条件:(以下条件满足一个即可)
负载因子=哈希表已保存节点数量/哈希表大小
load_factor=ht[0].used/ht[0].size;
扩展:
1)服务器目前没有在执行BGSAVE/BGREWRITEAOF命令,且哈希表负载因子>=1
2)服务器目前正在执行BGSAVE/BGREWRITEAOF命令,但哈希表负载因子>=5
收缩:
当负载因子<0.1时,执行收缩操作。
6.渐进式rehash
当哈希表中的键值对比较多时,如果采用集中式一次性完成rehash会造成一定的影响
为了避免对服务器性能造成影响,采用多次渐进式地将ht[0]里的键值对rehash到ht[1]
步骤如下:
1)为ht[1]分配空间,让字典同时持有ht[0]、ht[1]
2)维持索引计数器变量rehashidx,设置为0,表示rehash开始。
3)rehash期间,对字典进行正常操作的同时,会顺带将ht[0]上rehashidx索引上的键值对rehash到ht[1],完成后rehashidx+1
4)随着字典操作的不断进行,最终使ht[0]上所有键值对rehash到ht[1]上,修改rehashidx值为-1,过程结束。
// 在给定毫秒数内,以 100 步为单位,对字典进行 rehash 。
int dictRehashMilliseconds(dict *d, int ms) {
// 记录开始时间
long long start = timeInMilliseconds();
int rehashes = 0;
while(dictRehash(d,100)) {
rehashes += 100;
// 如果时间已过,跳出
if (timeInMilliseconds()-start > ms) break;
}
return rehashes;
}注意:rehashidx的值范围为[-1,ht[0].sizemask]
在渐进式rehash期间,对字典的操作会在ht[0]中先查找对应键,没有命中则在ht[1]中查找,
对于新增的键,会一律存在ht[1]中,使ht[0]逐渐变成空表。
7.跳跃表
有序数据结构,在每个节点中维持多个指向其他节点的指针,达到快速访问节点的目的。
有序链表中,节点具有多个指向,可加快搜索,复杂度O(logn)
level 3 -INF———–21↓————————-55↓
level 2 -INF—2↓——-21↓——-37↓————55↓
level 1 -INF–>2–>17–>21–>33–>37–>46–>55
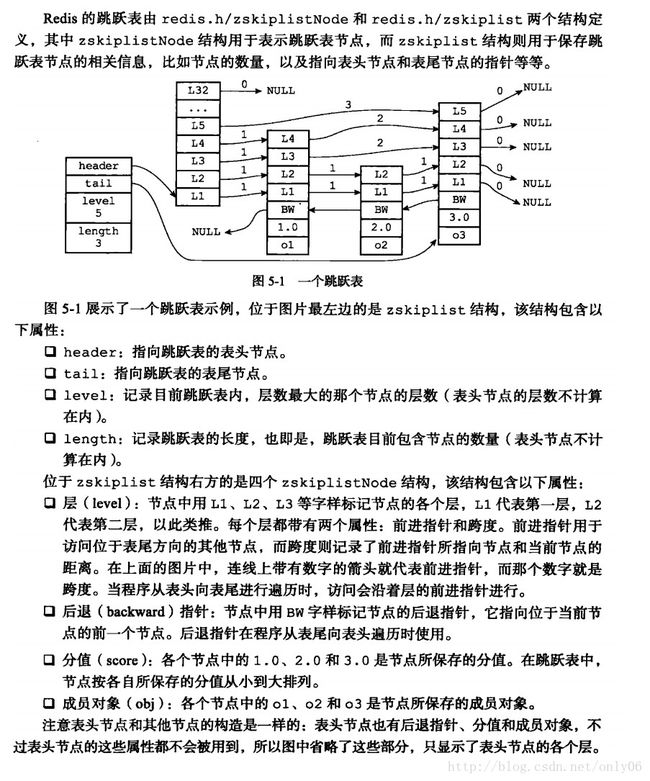
Redis跳跃表由redis.h/zskiplistNode和redis.h/zskiplist结构定义
zskiplistNode表示跳跃表节点, zskiplist表示关于节点的相关信息,如节点数量、头尾指针等
(图5-1跳跃表)
typedef struct zskiplistNode{
struct zskiplistLevel{ //层
struct zskiplistNode *forward; //前进指针
unsigned int span; //跨度
}level[];
struct zskiplistNode *backward;//后退指针
double score;//分值
robj *obj;//成员对象
}zskiplistNode;1)层:跳跃表节点的level数组可包含多个元素,每个元素包含指向其他节点的指针。
level[i].forward代表 本节点在第i层中的指向的下一个节点
每次创建一个新跳跃表节点时,根据幂次定律随机生成一个介于1和32之间的值作为level数组大小,即高度
2)跨度:level[i].span属性,记录两个节点之间的距离。跨度用于计算目标节点在跳跃表中的排位。(将沿途访问过的所有层跨度累加)
3)后退指针:用于从尾部逆向访问至表头,每次仅后退一个节点。
4)分值和成员:跳跃表中节点按分值从小到大排序,obj成员指向一个字符串对象,保存SDS值
(同一个跳跃表中各节点的成员对象是唯一的,但分值可以重复)
使用zskiplist结构维持跳跃表,快速访问表头、表尾节点,获取节点数量等信息。
typedef struct zskiplist{
struct zskiplistNode *header,*tail;//表头尾节点
unsigned long length;//表中节点数量
int level;//表中最高层数
}zskiplist;
/* 创建一个层数为 level 的跳跃表节点,
* 并将节点的成员对象设置为 obj ,分值设置为 score 。
* 返回值为新创建的跳跃表节点 */
zskiplistNode *zslCreateNode(int level, double score, robj *obj) {
// 分配空间
zskiplistNode *zn = zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
// 设置属性
zn->score = score;
zn->obj = obj;
return zn;
}
/* 创建并返回一个新的跳跃表,ZSKIPLIST_MAXLEVEL=32 */
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
// 分配空间
zsl = zmalloc(sizeof(*zsl));
// 设置高度和起始层数
zsl->level = 1;
zsl->length = 0;
// 初始化表头节点
// T = O(1)
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
// 设置表尾
zsl->tail = NULL;
return zsl;
}
/**由于跳跃表的第一层level[0]是简单顺序链表形式保存所有节点关系的。
因此在需要释放表时遍历level[0]依次释放即可。*/
void zslFree(zskiplist *zsl) {
zskiplistNode *node = zsl->header->level[0].forward, *next;
// 释放表头
zfree(zsl->header);
// 释放表中所有节点
// T = O(N)
while(node) {
next = node->level[0].forward;
zslFreeNode(node);
node = next;
}
// 释放跳跃表结构
zfree(zsl);
}
e.HyperLogLog:hyperloglog.c 中的 hllhdr
struct hllhdr {
char magic[4]; /* "HYLL" */
uint8_t encoding; /* HLL_DENSE or HLL_SPARSE. */
uint8_t notused[3]; /* Reserved for future use, must be zero. */
uint8_t card[8]; /* Cached cardinality, little endian. */
uint8_t registers[]; /* Data bytes. */
};7.5 HyperLogLog
可以接受多个元素作为输入,并给出输入元素的基数估算值:
基数:集合中不同元素的数量。比如 {‘apple’, ‘banana’, ‘cherry’, ‘banana’, ‘apple’} 的基数就是 3 。
估算值:算法给出的基数并不是精确的,可能会比实际稍微多一些或者稍微少一些,但会控制在合
理的范围之内。
HyperLogLog 的优点是,即使输入元素的数量或者体积非常非常大,计算基数所需的空间总是固定
的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基
数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以
HyperLogLog 不能像集合那样,返回输入的各个元素。
redis> PFADD str1 “apple” “banana” “cherry”
(integer) 1
redis> PFCOUNT str1
(integer) 3
redis> PFADD str2 “apple” “cherry” “durian” “mongo”
(integer) 1
redis> PFCOUNT str2
(integer) 4
redis> PFMERGE str1&2 str1 str2
OK
redis> PFCOUNT str1&2
(integer) 5
8.整数集合
用于保存整数值的集合抽象数据结构,保存int16_t、int32_t、int64_t,无重复元素。
intset.h/intset结构:
typedef struct intset {
uint32_t encoding;//编码方式
uint32_t length;//元素数量
int8_t contents[];//元素数组
}intset;contents数组中元素按从小到大排列,不含重复项。
contents元素类型取决于encoding
|intset
|encoding=INT16
|length=5
|contents –> |-5|18|89|252|14632|
sizeof(int16_t)*5=80位空间大小
当新添加的整数类型比原集合编码类型要大时,则对集合进行升级更新,将数组内元素都变为较大的类型并调整内存空间位
如,当原集合类型为INT_16,新增一个INT_64时,则将原元素都更改为INT_64 调整集合空间大小.
升级:更改编码并修改原底层数组中元素值的地址,改为新编码方式赋予
详见 源码intset.c/intsetUpgradeAndAdd 函数
例: 原先contents[0] 为INT_16编码存储的整数5 ,地址范围为 0X….a - 0X….b
当contents编码升级为INT_32时,对于整数5的地址可用空间变大了0X…a -0X…c
所以需要对整数5以INT_32编码形式重新赋予contents[0],覆盖整个可用空间地址。
// 根据集合原来的编码方式,从底层数组中取出集合元素
// 然后再将元素以新编码的方式添加到集合中
// 当完成了这个步骤之后,集合中所有原有的元素就完成了从旧编码到新编码的转换
// 因为新分配的空间都放在数组的后端,所以程序先从后端向前端移动元素
// 举个例子,假设原来有 curenc 编码的三个元素,它们在数组中排列如下:
// | x | y | z |
// 当程序对数组进行重分配之后,数组就被扩容了(符号 ? 表示未使用的内存):
// | x | y | z | ? | ? | ? |
// 这时程序从数组后端开始,重新插入元素:
// | x | y | z | ? | z | ? |
// | x | y | y | z | ? |
// | x | y | z | ? |
// 最后,程序可以将新元素添加到最后 ? 号标示的位置中:
// | x | y | z | new |
// 上面演示的是新元素比原来的所有元素都大的情况,也即是 prepend == 0
// 当新元素比原来的所有元素都小时(prepend == 1),调整的过程如下:
// | x | y | z | ? | ? | ? |
// | x | y | z | ? | ? | z |
// | x | y | z | ? | y | z |
// | x | y | x | y | z |
// 当添加新值时,原本的 | x | y | 的数据将被新值代替
// | new | x | y | z |
while(length--)
_intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc));
//_intsetGetEncoded返回以旧编码获得的length位置上的整数值value,
//_intsetSet将value以新编码放到contents数组的正确位置上。9.压缩列表
ziplist,列表键和哈希键的底层实现之一。
压缩列表采取的方式犹如单向链表,比双端链表要节省空间,
在节点方面,与双端链表相比,数据结构更加简单。
但双端链表结构记录更详细信息,对于复杂情况更加快速。
例:
redis> RPUSH lst 1 3 5 12345 “hello” “good”
(integer)6
redis> OBJECT ENCODING lst
“ziplist”
列表键lst中包含的是较小的整数值及短字符串。
当一个哈希键中只包含少量键值对,且键值是小整数值或短字符串,也会使用压缩列表
例:
redis> HMSET profile “name” “Jack” “age” 28 “job” “Programmer”
OK
redis> OBJECT ENCODING profile
“ziplist”
压缩列表由一系列特殊编码的连续内存块组成,顺序型数据结构。
一个压缩列表可包含任意多个结点entry,每个节点可保存一个字节数组或整数值。
压缩列表组成部分:
|zlbytes|zltail|zllen|entry1|entry2|…|entryN|zlend|
zlbytes: uint32_t 记录整个压缩列表占用的内存字节数
zltail :uint32_t 记录压缩列表表尾节点距离起始地点的偏移量。
zllen :uint16_t 记录压缩列表包含的节点数量(数量大于uint16_t_MAX时需要遍历计算)
entryX : 列表节点
zlend :uint8_t 标记末端。
压缩列表节点组成部分:
|previous_entry_length|encoding|content|
节点可保存一个字节数组或一个整数值
字节数组:
1)长度小于等于63(2^6 -1)字节的字节数组
2)长度小于等于16383(2^14 -1)字节的字节数组
3)长度小于等于4294967295(2^32 -1)字节的字节数组
整数值:
1)4位长,介于0-12的无符号整数
2)1字节长的有符号整数
3)3字节长的有符号整数
4)int16_t类型整数
5)int32_t类型整数
6)int64_t类型整数
|previous_entry_length|:1或5字节 记录压缩列表中前一个节点的长度
|encoding|:记录节点content属性所保存数据的类型及长度
|content|:保存节点的值,值的类型和长度由encoding属性决定
/* 保存 ziplist 节点信息的结构 */
typedef struct zlentry {
// prevrawlen :前置节点的长度
// prevrawlensize :编码 prevrawlen 所需的字节大小 用来计算节点的编码
unsigned int prevrawlensize, prevrawlen;
// lensize :编码 len 所需的字节大小
unsigned int lensize, len;
// 当前节点 header 的大小
// 等于 prevrawlensize + lensize
unsigned int headersize;
// 当前节点值所使用的编码类型
unsigned char encoding;
// 指向当前节点的指针
unsigned char *p;
} zlentry; // len :当前节点值的长度压缩列表小结{
是一种为节约内存开发的顺序型数据结构
用作列表键和哈希键的底层实现之一
可包含多个节点,每个节点保存一个字节数组或整数值
添加新节点或删除节点,可能引发连锁更新操作,不过出现的几率不高
}