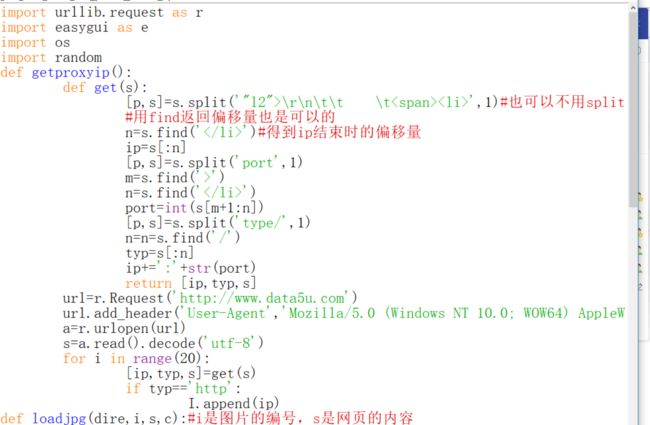
手把手教你学python第二十一讲(爬虫之正则表达式一:实战爬取小姐姐图)
这里先对代理ip做一点补充,查自己ip上一讲给的是一个网站。那么还有另外2个网站也是可以查到访问的ip的,会出现网站查到的ip不一样,这是因为

。
需要注意的是这两个都有反爬虫的,但是也简单,你只需要修改一个user-agent就可以了。当然这仅限于你不用代理的时候。不加user-agent虽然不会报错,但是返回的内容是空的

加上去之后

来试验一下代理
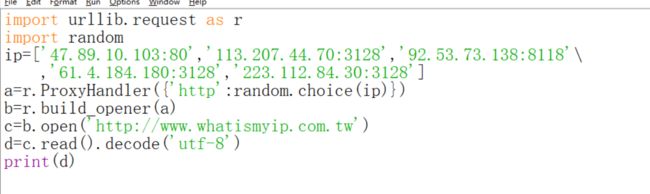
这里需要说明,对于有反爬虫机制检查user-agent的网站,代理的时候也需要加user-agent,不然

加上之后
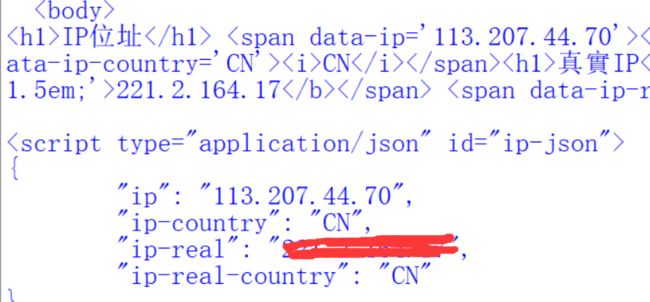
但是网站也不是吃素的,这里会显示两个ip,上一个是你用的代理ip,下面还会有ip-real。

再运行一次

用第二个网站重复过程。第二个也是有反爬虫的。不加user-agent

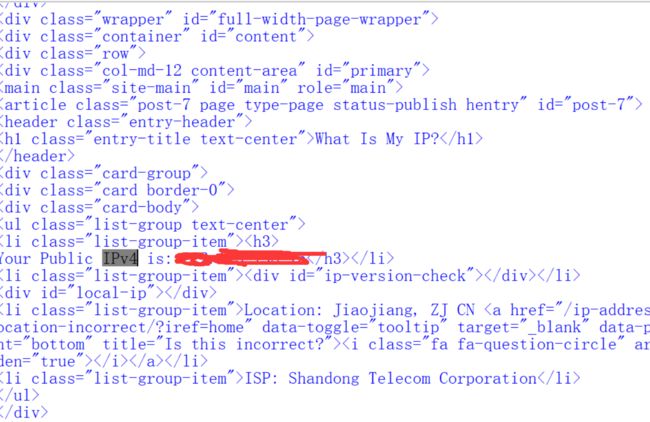
这个网站还有访问次数限制的。
上一讲还讲到了丢包,如果用过游戏加速器的人不会对这个次陌生,一般会有一个loss(丢包率)指标和ping(延迟),什么是丢包呢?


造成丢包的原因可以看看https://blog.csdn.net/duandianR/article/details/77513506
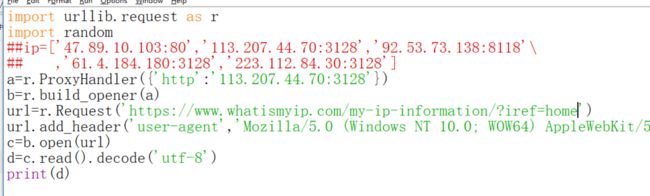
还有一点需要注意,代理和访问和网站类型要对应才行

用http代理访问https协议的网站试试
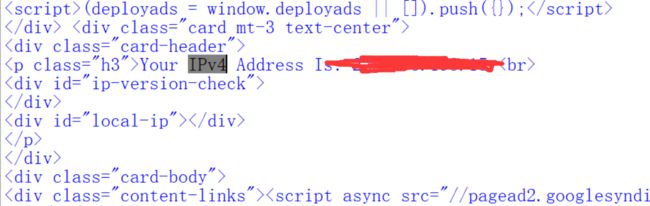
下面显示的还是我自己的ip,我是不会让你们看到我的ip的。
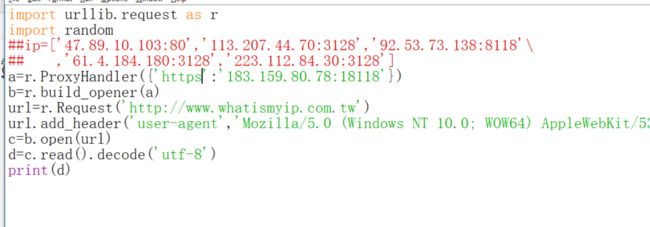
下面换一个https的代理ip
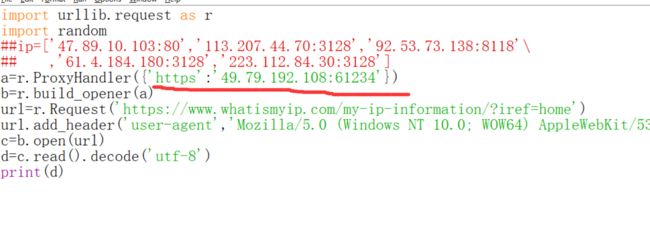

下面尝试用http代理去访问https网站。
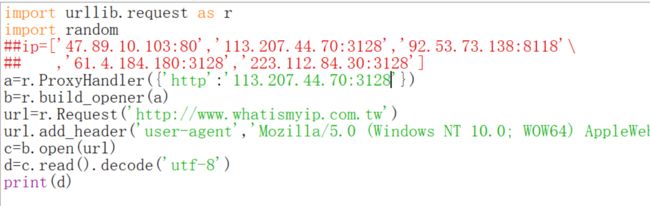

我这样试了一下返回的是代理ip,但是换一个https的代理ip之后

下面开始本节的预备内容,先利用已有的知识来做两件事:
我们都是把代理ip从网页上复制过来的,可不可以用python爬取?
爬取煎蛋网的小姐姐图。
为什么不先学正则表达式而先做这两件事?以后会明白的。先来做第一件事,爬取代理ip。选择一个代理ip网站。选中一个ip,点右键
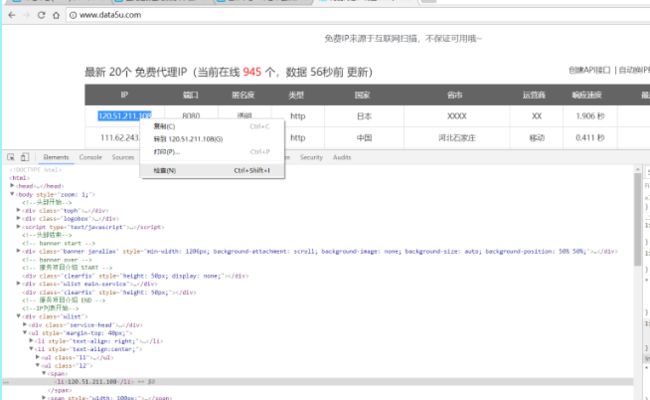
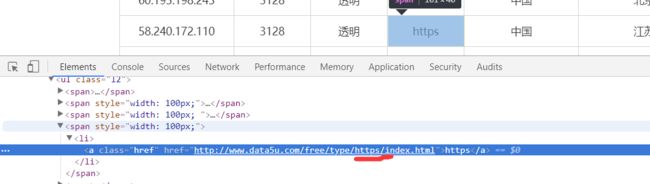
就可以找到ip的位置。同样的方法,可以找到对应的端口号和类型。
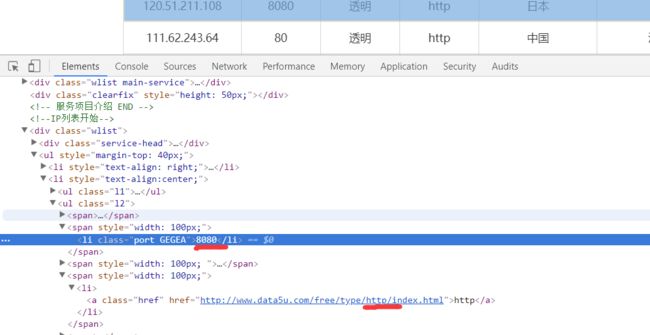
需要注意的是只有type后面才代表的是类型。https的是这样的。
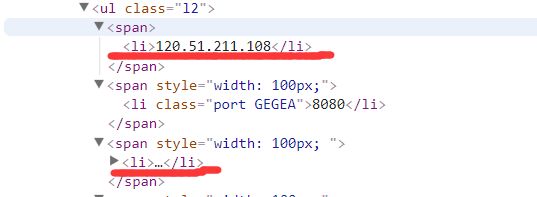
要想爬取ip,端口号和对应的类型就必须要知道特征。我们必须先来观察ip的特征。
前面有
那么
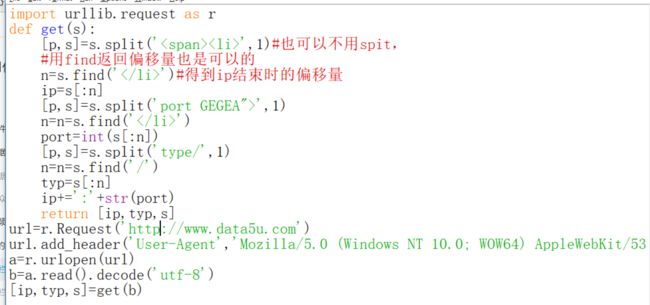
我们来看看结果。enmmmmmm...ip地址不知道去哪里了。说明很可能前面并不是ip的特征
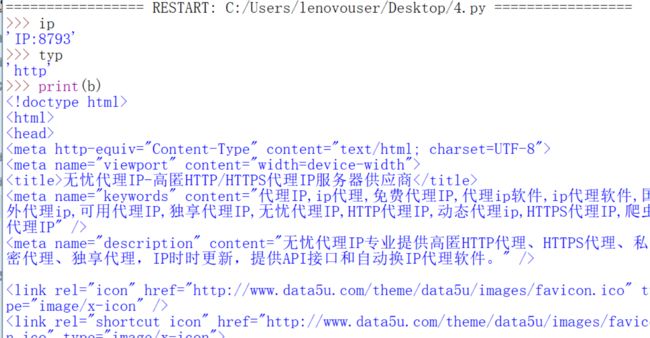
我们搜索一下前面的
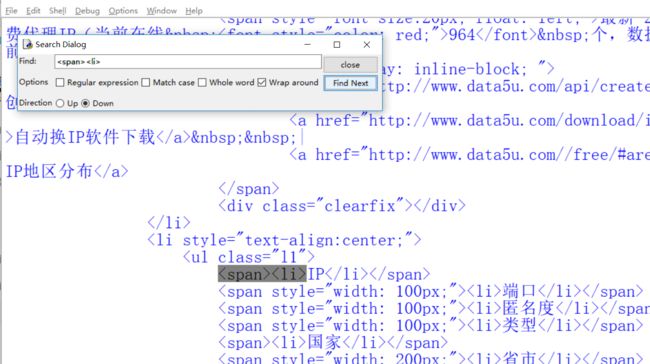
找到了问题。看来必须重新找ip的特征了。这里我们需要看b,而不能看print(b),因为print出来那些转义字符都没了,你直接看b是这样的,这其实是不完整的

要想看到全部的b,可以在edit里find一下就可以了,下面就找到了ip的特征了。

修改一下代码。

就可以了。

哇,费了九牛二虎之力终于爬到了一个ip,那么下面就试着爬10个试试,我们来加一个循环。但是其实还有一个问题,也许你已经发现了。
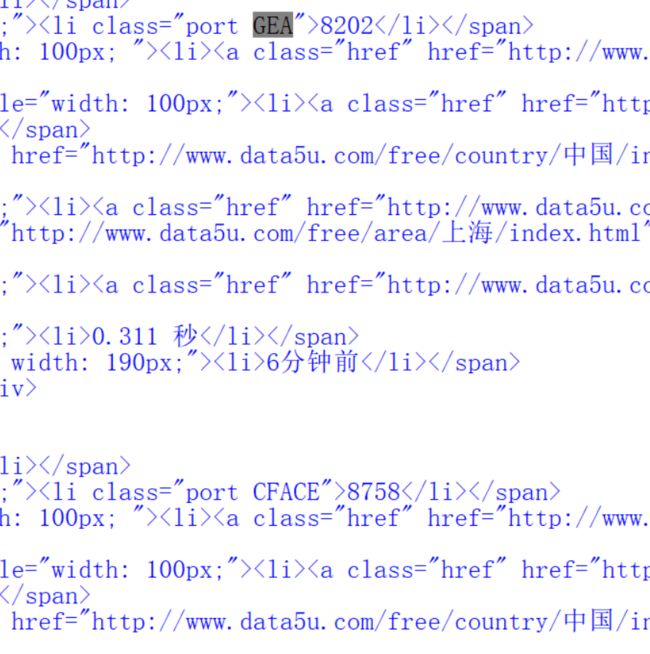
enmmm,还得加程序去处理这个问题。
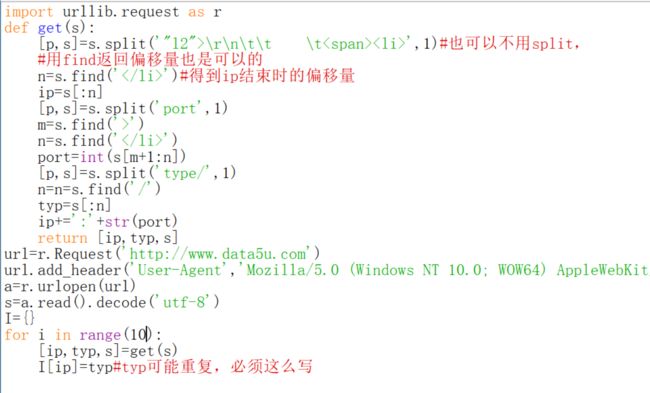

第一件事除了用了user agent没有用到代理ip,这是因为我们爬取的ip不是很多,如果你需要大量代理ip,可能有的网站不检测访问频率,那还好,如果有,你就得用代理ip去爬取代理ip,是不是有点绕。第二件事里面会用到代理ip去下载图片的。
第二件事,来爬取小姐姐的图片吧。先来踩点,所谓踩点就是提取我们要抓取信息的特征。
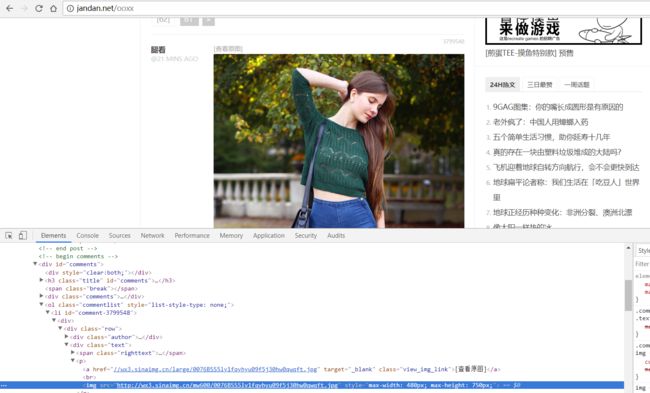
你右键一个图片,审查元素就会得到图片的网址。确实照着这个网址就会找到图片。
好的,那么我们就先来爬一张试试。是会报错的,图片也没有下载下来。

是什么原因呢?不要着急我们来对比下,爬到的东西和在网页上看到的东西就知道了。

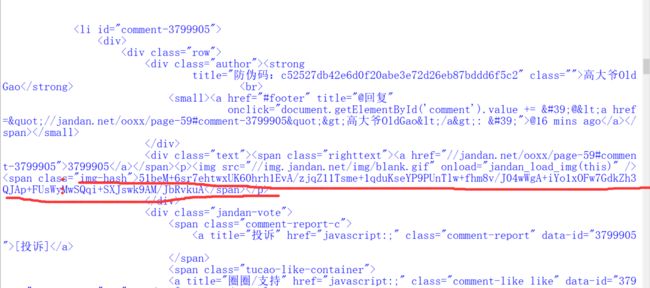
我们爬到的和在网页上看到的是不一样的,还有一种快捷键Ctrl+u,看到的就是一样的。
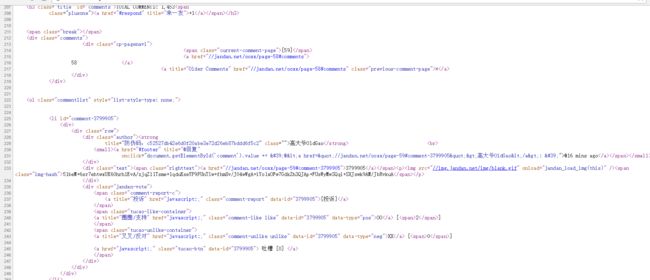
嗯,这个原因也不是很懂,毕竟我们的主要任务不是做网页开发。那么如何解决这个问题?一呢就是,上面不是用一种hash算法加密过的吗?那么看能不能破译一下。每张图片的这个哈希值都不一样,然而要想解密,太难了,我试过几种解密,都不成功。

于是第二种方法,换网站,不需要在一棵树上吊死。这种网站也有很多,你百度一下就可以出来的。我用的是这个。

下面就得重新踩点了。
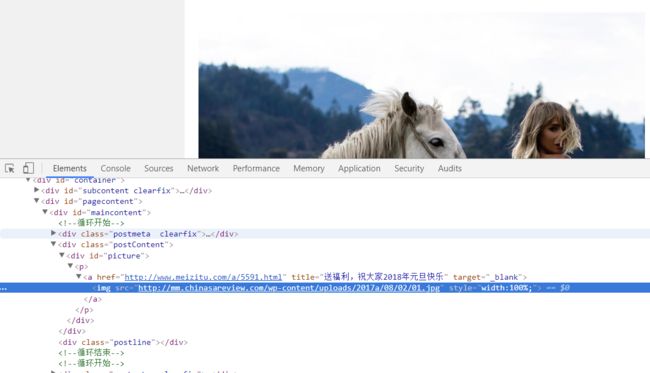
好的,我们再来试试。需要注意的是,这个网站是gb2312的编码方式。
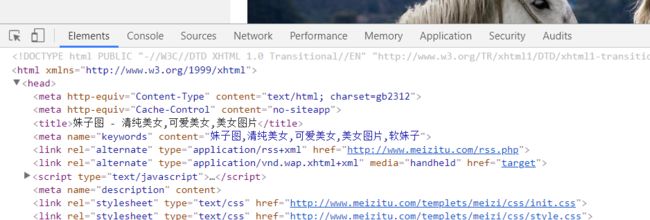
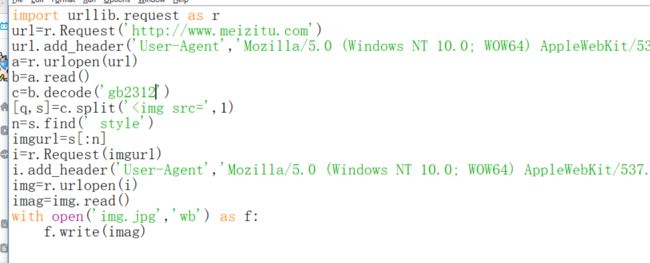
会出现下面的情况,没关系,出现问题我们解决问题就是了。
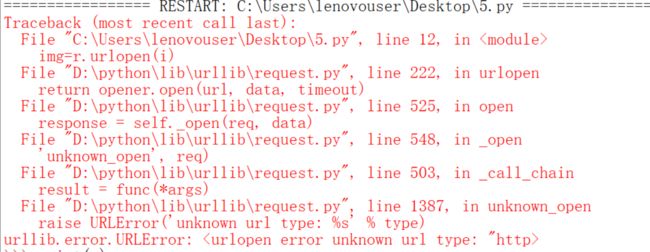
看到报错的原因是因为http>这样的字符不符合url的格式,我们去看看。
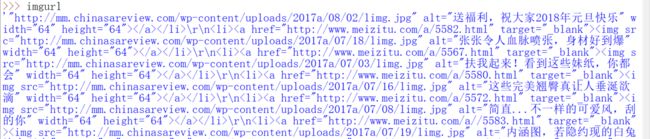
imgurl不应该这么长而应该只是一个网页才对,这是因为爬到的和F12显示的不一样,注意爬到的后面是alt。改一下即可。还有一点需要注意的是注意前后都多了一个单引号,这个也要去除。方法有很多。我用的只是一种
最后成功了。

但是有的朋友是不会满足一张图片的,我们来改程序多爬几张,建一个文件夹保存在里面。假如我下载的图片数量比较多,那么我就得打开两次网站,因为一个网站的图片数量有限。这样爬到的其实是边上的图,不是那些大图,边上图一共11张,在网页源码的位置是在那10张大图之前的,并且前面是一样的,一个网页一共有21张图。这是边上的11张图,图片网址后面是alt

那十张大图的代码在后面,是以style结尾的。

但是其实我们可以把结束条件放宽,所以这不是一个问题。问题在于如何得到不一样的url。点击下面的2,进入一个新的页面。
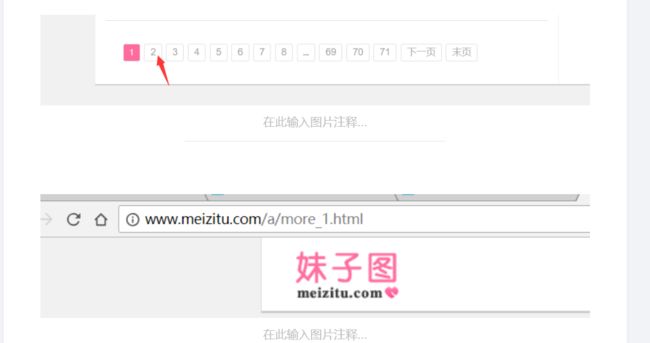
检查一种图片的代码

是alt结尾的。再点击下面的2,进入新的页面,主要是注意url的变化。
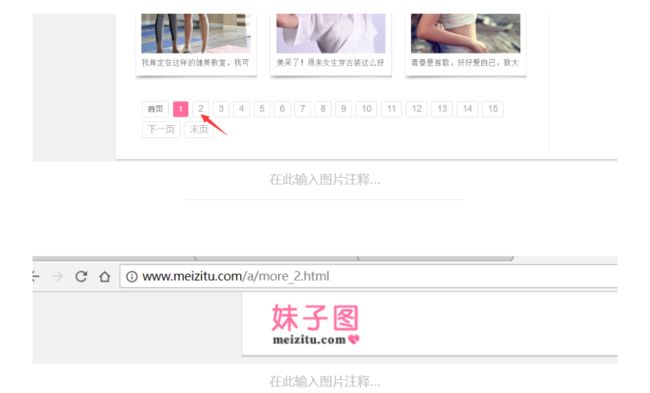
到这里已经踩点完毕了。可以开始编程了,上面的网页一页上有50张图片(你可以自己去数一数),我们为了打开两张新的网页,就下载100张图片。


运行一波

有些图片内容还是有点过激,就看下小图吧。
这个网站有没有检查访问频率的我不太清楚,如果你想胃口很大,比如你想下载几千张,几万张,那么你访问的频率就会很快,这时候我们说过有两种处理方法,第一种是延时,前面演示过,比较简单,这里就只尝试用代理ip的代码。只需要把前面的代码结合起来,改几个地方就可以了。看起来就是这样子的。


可能会出现这种问题

也是正常现象,有的代理ip不好用。下面开始学习正则表达式了。
正则表达式之初见
介绍正则表达式之前,我想先介绍一个beautiful soup第三方模块
看过我前面设置pip为环境变量的应该知道怎么安装最快。就只需要在命令行输入一句。pip install BeautifulSoup4就ok了

安装在这里
这里有一个不错的网址https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/index.html,这个网站说的还是比较详细的。这个网址也说了还需要按一个lxml的模块。如果有错误,到这个网站https://jingyan.baidu.com/article/ad310e80feaac71849f49e98.html。其中第二步在python3.7里是会报错的,不过没关系。到
下载划线部分之后,按照上面网址后面去做即可,亲测可行,不过安的这个lxml应该只适合我这版python,不同版本python安的是不一样的。是可行的。

安装终于结束了。这个模块我觉得网站说的很详细了,我下面就试几下吧。在我们上面某一个爬取代理ip地程序上进行一些测试。
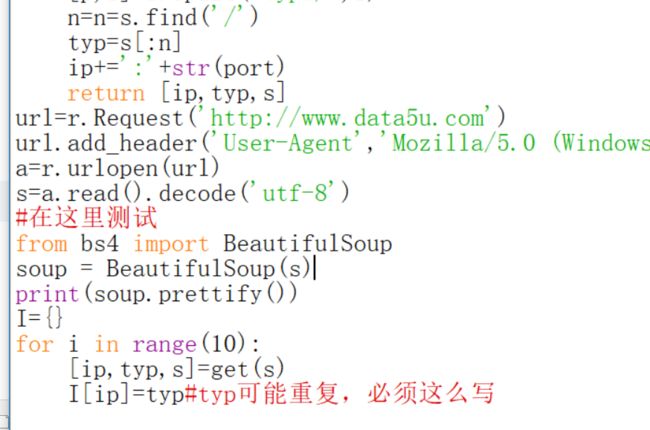
结果
这个红的不是错误只是一个警告而已,说的意思就是我们没有指定解释器,于是它自己匹配了一个HTML parse这个解释器。可能在其它操作系统和其它环境下,会用不同的解释器。prettiy是修饰的意思,大概就是下面的意思,这个没有帮助。

至于文件句柄,可以戳https://www.zhihu.com/question/20458721,百度百科是这样说的

改tag,name的时候,我举个下面的例子吧
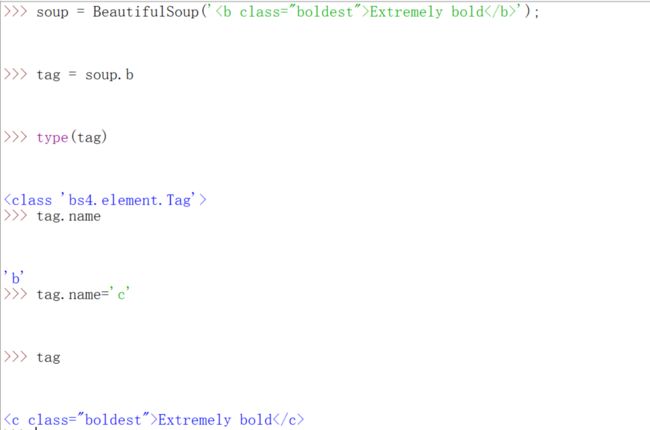
改了一下b就全部变成c了。其他的操作请自己看,用到的时候再说,我觉得那个网站讲的是真不错了。还有下面几个学习lxml模块的网站https://blog.csdn.net/kikaylee/article/details/56842194
https://blog.csdn.net/tanzuozhev/article/details/50442243
https://cuiqingcai.com/2621.html
https://blog.csdn.net/u011546871/article/details/76047537
都是不错的,lxml不仅是个解释器,还有和前面的BeautifulSoup4模块用法有点相似的功能,大家也请自学一下,只不过我下面都用的是BeautifulSoup4而已,这不代表lxml完成不了功能。下面赶紧进入今天的主角,正则表达式。为了让你们可以更容易地看懂课后练习,这一讲先学完正则表达式再去看那些题。关于正则表达式有一个很好的网站推荐给你们。https://www.cnblogs.com/deerchao/archive/2006/08/24/zhengzhe30fengzhongjiaocheng.html。如果你对上面的网站没有兴趣,你一定要下载 那个博主自己开发的正则表达式测试器,非常好用,下载地址http://deerchao.net/tools/regester/index.htm。什么是正则表达式呢?


总结一下的话其实就是匹配字符的一些规则用代码来描述就是正则表达式,它就像是一个过滤器filter,从字符串筛选出你想要的符合某种规则的子字符串。只不过filter的格式和我们即将用到的re.search是这样的(当然re不止这一个函数,为什么拿它作为例子入门呢?只是因为我看的很多教程都是从它开始而已,re的其他函数后面还会介绍到)
filter的第一个参数必须是一个函数。而下面我们会看到正则表达式如何书写。我们先来简单的几个字符匹配例子。再推荐一个网站https://www.cnblogs.com/tina-python/p/5508402.html。re.search里面额flags有什么作用呢?

废话不多说,先来试试。

看到pattern字符串前面一般都加上r,上面的代码帮助你复习了一下r的作用,加上r也就是避免出现一些转义字符带来的麻烦。返回的Span是一个索引的范围(0,1)就是索引值是0,match返回的就是查到的结果。如果没有匹配到就返回None,也就是什么都不显示。如果re只有这么点本事的话,字符串的find就很不服气了,哇,凭什么你就可以有这么高大上的名字?我一样可以实现你的功能啊,只不过我返回的是起始地索引值而已


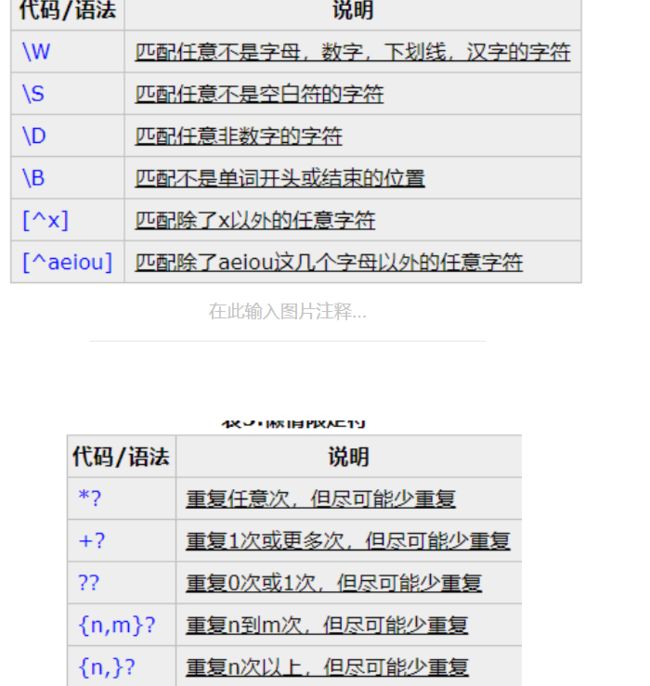
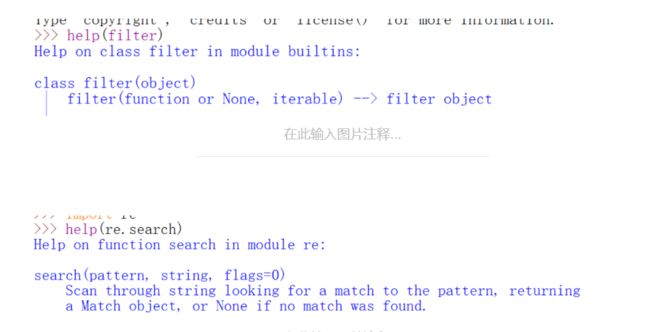
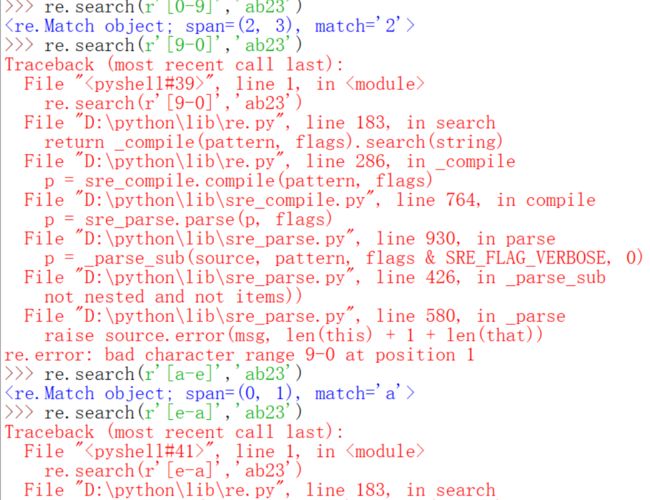
然后find就无计可施了或者说很麻烦了。这节课先来讲解几个基础的元字符,首先这些元字符之所以单列出来是因为它们无法匹配自身,它们定义了字符类,子组匹配和重复次数等。先用点,中括号,大括号来举例子。从下面的图可以看到,如果仅仅在pattern里写r'.',它匹配到的是a,这体现的是r'.'可以匹配任何除了换行符的任意字符,而如果要匹配点呢?只需要在前面加一个\,就可以消除点的特殊含义了,就可以匹配到点了,中括号里面存放的是需要匹配的字符的集合,只有后面出现了中括号里面的任意一个就会匹配,匹配的规则不是按照中括号里字符的先后,而是在你要查找字符串里出现的先后,也就是索引值从0开始增大的顺序,其实也就是从字符串最左到最右。大括号里面表示的是重复的次数。如果前面要重复的字符有多个,字符都用小括号括起来,下面都可以找到对应的例子。
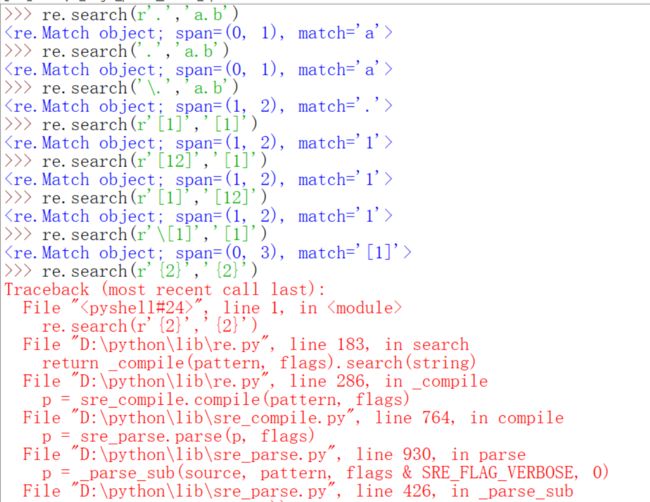
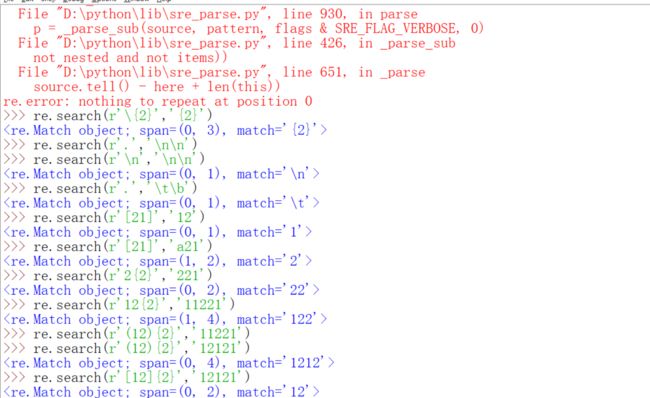
最后一行可能需要说明一下,[12]{2}的意思是什么呢?结果为什么是'12'呢?其实完全等价于[12][12],这你就会理解为什么是'12'了,也就是说{2}的优先级高一些,试想如果[12]的优先级高,那么结果要么是11,要么是22。还可以用形如0-9来表示0到9的字符。
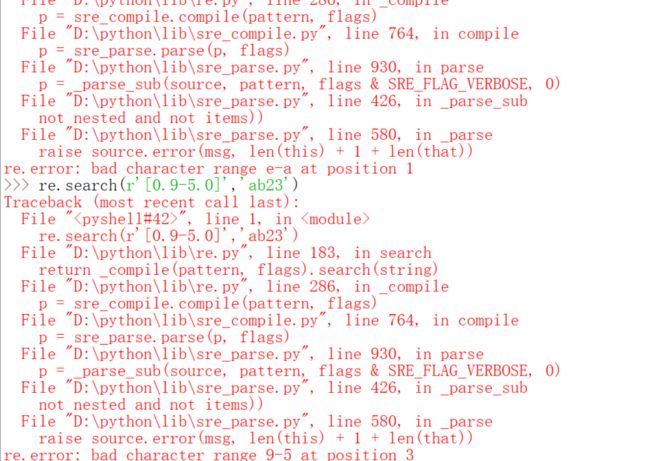

-只有在[]里才可以用,并且对字母也可以用,因为都是字符,所以是转换为ASCII码的(其实是Unicode编码,前面也说过Unicode编码前面是和ASCII码一样的),只要符合ASCII码的顺序都可以,必须保证后面比前面大,而且你在[]里写小数是没有意义的,因为一个小数超过了一个字符。{}里的规则上面的元字符表里有。这一讲下面还要用到一个\d,目前只用到了这些,当然还有很多没讲到元字符的注意事项,不过,我们先来应用一下。我们来简化一下爬取代理ip的程序。那么首先我们需要写一个匹配ip的正则表达式。你可以自己先想一想,如果实在想不出来,可以百度一下或者去http://deerchao.net/tutorials/regex/common.htm。你下面会体会到用了正则表达式的程序和前面用字符串各种麻烦方法对比之下有多么简单,而且用字符串的方法通用性比较差,你爬这个网站可以用,另一个可能就不行,如果有一天网站的程序员改了一下代码,也不能用了,但也不是说用正则表达式就一劳永逸,但是通用性比字符串高一些,而且代码简单。写代码之前我们必须意识到一个问题,首先就是re.search返回的还不是我们想要的东西,这一点好办,我们可以调用它的group方法来返回匹配到的字符串,还有一个就是search是一个一个找,太慢了,有没有直接一下子全都找到的?是有的,就是findall,下面先演示一下,然后写代码修改爬代理ip的程序,我们下面的程序没有设置想要的代理ip数字,其实感觉也没有必要,多多益善嘛,还有一点需要说明的事,下面的代码在爬取代理ip类型的时候用到了‘美丽的汤’模块,由于我让你们自学,我只会做简单的解释,其实我可以不解释的,就害怕有的人没看,最后就变成了死记硬背代码格式,这不是我想看到的。

由于图片的数目限制,这一讲先到这里。下一讲会处理以前的所有练习题和我问题。在将要达到高潮的时候结束,是不是有点吊人胃口呢?因为我分别在7,11,14,18,25号都有考试,时间还是有点紧张的。所以下一次更新预计就在26号了。
我以前是会给代码的百度云链接的,但是后来想了想,还是你们一行一行的去敲,一行一行地理解代码的含义才是最好的学习方法,眼高手低从来都不是好的学习方法,也从来只是纸上谈兵,根本发现不了实际的问题,古语云:纸上得来终觉浅,绝知此事要躬行。我最痛恨的就是死记硬背,我们学理工的从来都是要理解性记忆,而不是死记硬背,何况有一些前人总结的经验公式,都不需要背,用到的时候查就行。