Ubuntu环境下使用Docker的Hadoop镜像搭建MapReduce
目录
- 一、安装docker
- 二、安装docker的Ubuntu,Centos镜像
- 三、安装Java和Scala
- 四、安装SSH
- 五、创建容器
- 六、安装 Hadoop
- 七、Hadoop配置
- 八、MapReduce计算
- 总结
一、安装docker
(1)更换国内软件源
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
sudo sed -i 's/archive.ubuntu.com/mirrors.ustc.edu.cn/g' /etc/apt/sources.list
sudo apt update
(2)安装需要的包
sudo apt install apt-transport-https ca-certificates software-properties-common curl
(3)添加 GPG 密钥,并添加 Docker-ce 软件源
curl -fsSL https://mirrors.ustc.edu.cn/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://mirrors.ustc.edu.cn/docker-ce/linux/ubuntu \
$(lsb_release -cs) stable"
(4)添加成功后更新软件包缓存
sudo apt update
(5)安装 Docker-ce
sudo apt install docker-ce
(6)设置开机自启动并启动 Docker-ce(安装成功后默认已设置并启动,可忽略)
sudo systemctl enable docker
sudo systemctl start docker
(7)hello world验证:
$ sudo docker run hello-world
(8)添加当前用户到 docker 用户组,可以不用 sudo 运行 docker
sudo groupadd docker
sudo usermod -aG docker $USER
如果出现错误可以参考
docker安装错误的解决方案
二、安装docker的Ubuntu,Centos镜像
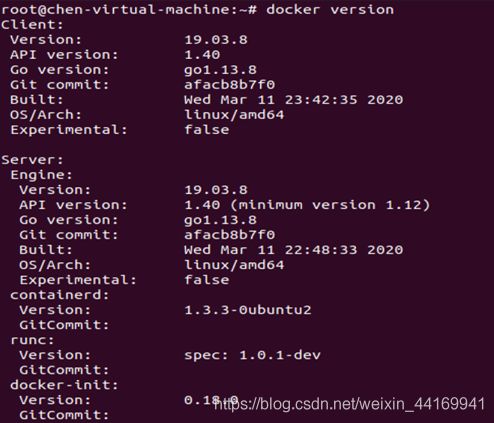
查看docker,使用
docker version
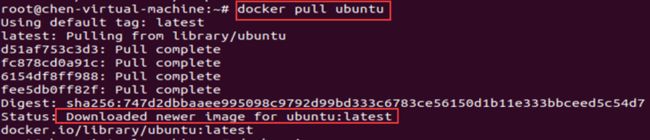
使用
docker pull Ubuntu
查看docker的镜像库
docker images
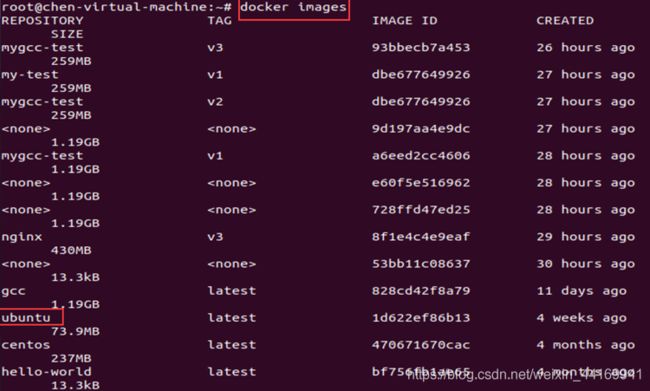
验证docker的Ubuntu镜像
![]()
拉取centos:latest镜像,使用
docker pull daocloud.io/library/centos:latest

查看镜像
docker images
![]()
三、安装Java和Scala
刷新源
apt-get update

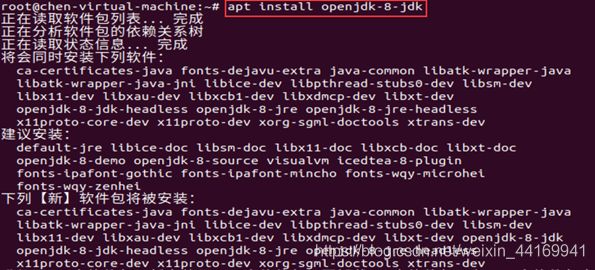
下载java 8
apt install openjdk-8-jdk
查看安装是否成功
java -version

安装Scala
apt install scala
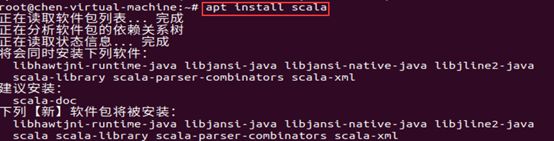
使用scala检查
scala

四、安装SSH
更新软件源
apt-get update

安装SSH
apt-get install openssh-server
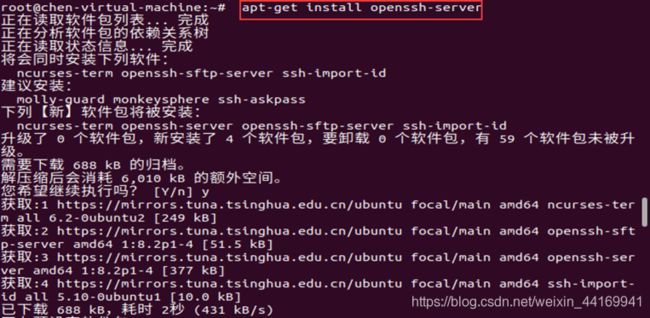
可能会出现一些问题:
在安装SSH时因为该软件包正处于非常不稳定的状态,所以要先进行安装
1.将info文件夹更名
sudo mv /var/lib/dpkg/info /var/lib/dpkg/info_old
2.再新建一个新的info文件夹
sudo mkdir /var/lib/dpkg/info
sudo apt-get -f install
3.更新
sudo apt-get update
4.执行完上一步操作后会在新的info文件夹下生成一些文件,现将这些文件全部移到info_old文件夹下
sudo mv /var/lib/dpkg/info/* /var/lib/dpkg/info_old
5.把自己新建的info文件夹删掉
sudo rm -rf /var/lib/dpkg/info
6.把以前的info文件夹重新改回名字
sudo mv /var/lib/dpkg/info_old /var/lib/dpkg/info

问题解决,重新安装

检查SSH是否成功启动
ps -e|grep ssh

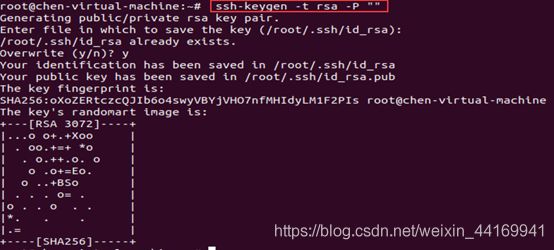
生成秘钥
ssh-keygen -t rsa -p ""
将公钥追加到 authorized_keys 文件中
cat .ssh/id_rsa.pub >> .ssh/authorized keys
![]()
启动 SSH 服务
五、创建容器
创建容器时需要设置固定IP,所以先要在docker使用如下命令创建固定IP的子网
docker network create --subnet=172.18.0.0/16 netgroup
![]()
docker的子网创建完成之后就可以创建固定IP的容器
#cluster-master
docker run -d --privileged -ti -v /sys/fs/cgroup:/sys/fs/cgroup --name cluster-master -h cluster-master --net netgroup --ip 172.18.0.2 daocloud.io/library/centos /usr/sbin/init
#cluster-slaves
docker run -d --privileged -ti -v /sys/fs/cgroup:/sys/fs/cgroup --name cluster-slave1 -h cluster-slave1 --net netgroup --ip 172.18.0.3 daocloud.io/library/centos /usr/sbin/init
docker run -d --privileged -ti -v /sys/fs/cgroup:/sys/fs/cgroup --name cluster-slave2 -h cluster-slave2 --net netgroup --ip 172.18.0.4 daocloud.io/library/centos /usr/sbin/init
docker run -d --privileged -ti -v /sys/fs/cgroup:/sys/fs/cgroup --name cluster-slave3 -h cluster-slave3 --net netgroup --ip 172.18.0.5 daocloud.io/library/centos /usr/sbin/init


查看容器并登录
docker ps -a

登录到master容器
![]()
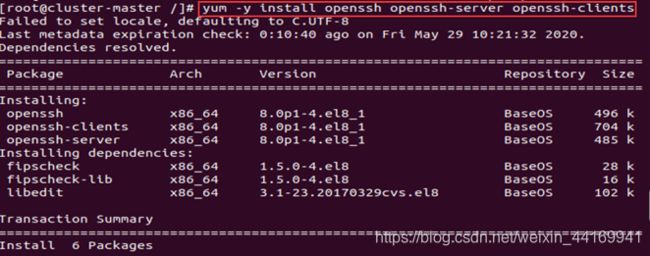
安装openssh 使用
yum -y install openssh openssh-server openssh-clients
将原来的StrictHostKeyChecking ask
设置StrictHostKeyChecking为no
保存

退出重新登录slave1,slave2,slave3
![]()
同上操作安装openssh ,三次安装分别对slave1,slave2,slave3
yum -y install openssh openssh-server openssh-clients
systemctl start sshd
在master机上执行ssh-keygen -t rsa并一路回车,完成之后会生成~/.ssh目录,目录下有id_rsa(私钥文件)和id_rsa.pub(公钥文件),再将id_rsa.pub重定向到文件authorized_keys

通过ping id来测试,是否能连上各个容器




在/etc/hosts上,增加ip和节点
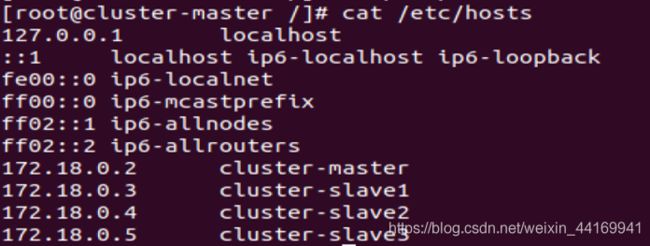
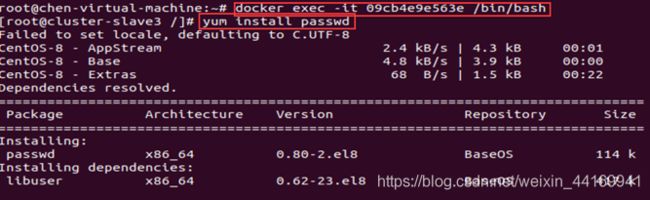
依次进入每一个容器,进行
yum install passwd
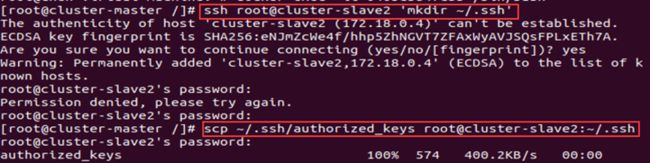
然后修改初始密码,进行秘钥分发

将秘钥进行分发
ssh root@cluster-slave1 'mkdir ~/.ssh'
scp ~/.ssh/authorized_keys root@cluster-slave1:~/.ssh
ssh root@cluster-slave2 'mkdir ~/.ssh'
scp ~/.ssh/authorized_keys root@cluster-slave2:~/.ssh
ssh root@cluster-slave3 'mkdir ~/.ssh'
scp ~/.ssh/authorized_keys root@cluster-slave3:~/.ssh
六、安装 Hadoop
安装vim
apt install vim

安装 net-tools
apt install net-tools
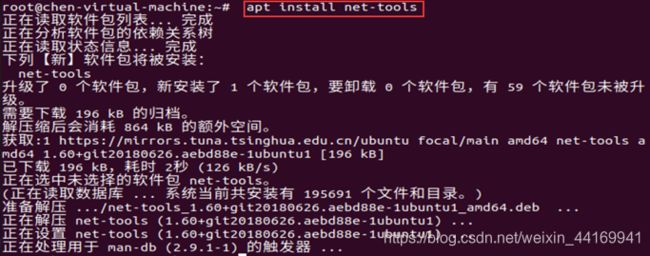
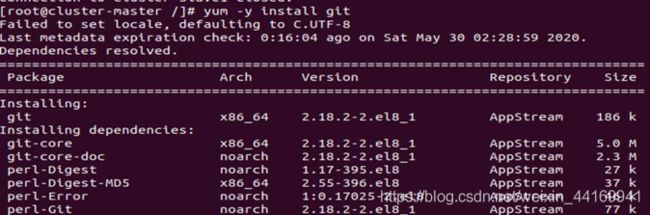
安装git,便于后续配置
yum -y install git
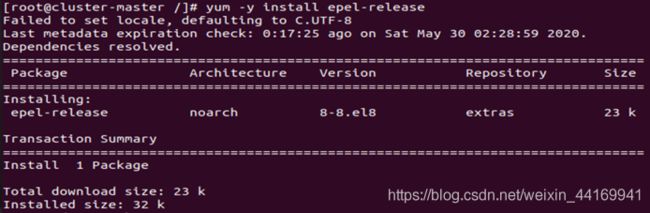
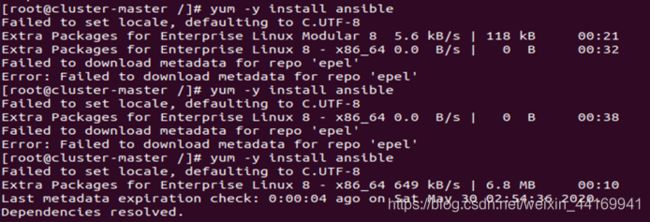
安装Ansible
yum -y install epel-release
yum -y install ansible
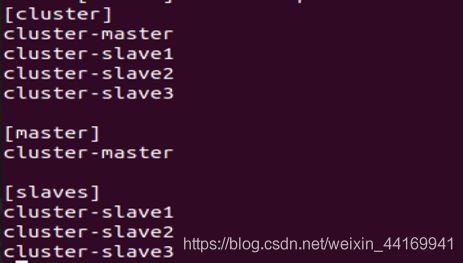
修改ansible的hosts配置文件
![]()
然后在~/.bashrc追加指令,修改docker 的/etc/hosts
![]()
:>/etc/hosts
cat >>/etc/hosts<执行配置文件,有hosts文件已经修改;最后分发.bashrc至集群slave下

![]()
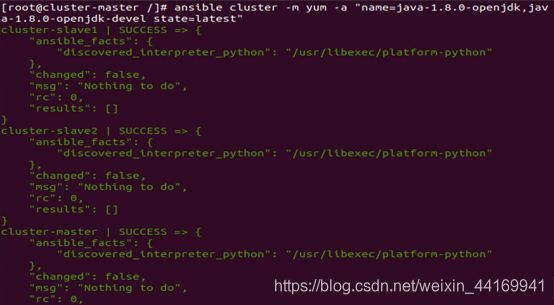
使用ansible在在集群中安装openjdk
ansible cluster -m yum -a "name=java-1.8.0-openjdk,java-1.8.0-openjdk-devel state=latest"
安装Hadoop 2.7,从清华源拉取
Wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.4/hadoop-2.7.4.tar.gz
解压安装包,并创建链接文件
mkdir /home/hadoop
cd /home/hadoop/
mkdir tmp hdfs hdfs/data hdfs/name
mv /opt/hadoop-2.7.7.tar.gz /home/Hadoop
tar zxvf hadoop-2.7.7.tar.gz
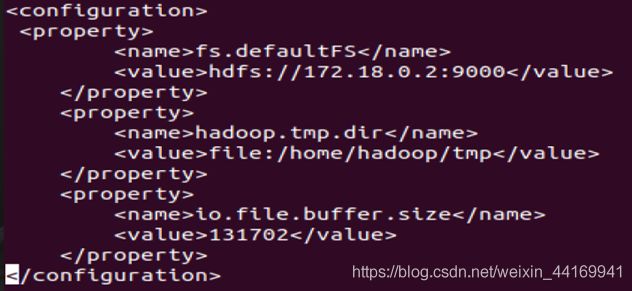
配置MapReduce文件
vi /home/hadoop/hadoop-2.7.7/etc/hadoop/core-site.xml
vi /home/hadoop/hadoop-2.7.7/etc/hadoop/hdfs-site.xml

vi /home/hadoop/hadoop-2.7.7/etc/hadoop/mapred-site.xml
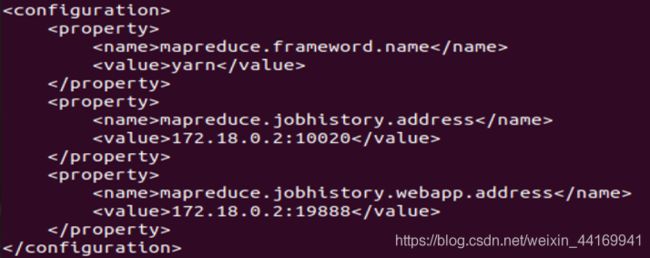
vi /home/hadoop/hadoop-2.7.7/etc/hadoop/yarn-site.xml


七、Hadoop配置
来检查是否安装成功
hadoop version

出现问题,打开vi vi /home/hadoop/hadoop-2.7.7/bin/hadoop
是第20行,bin=which $0,需要安装which
yum install -y which

再次检查

安装成功!
在master节点上运行如下命令,格式化namenode
/home/hadoop/hadoop-2.7.7/bin/hdfs namenode -format

在master节点上运行如下命令,启动Hadoop集群
/home/hadoop/hadoop-2.7.7/sbin/start-all.sh

输入jps命令,可以查看Hadoop相关服务的运行状态


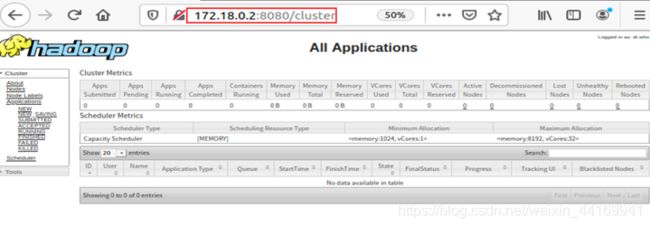
通过Web界面查看Hadoop状态
访问http://172.18.0.2:8080/页面,可以查看集群状态
访问http://172.18.0.2:50070页面,可以查看详细信息

运行如下命令可以停止Hadoop服务
/home/hadoop/hadoop-2.7.7/sbin/stop-all.sh
八、MapReduce计算
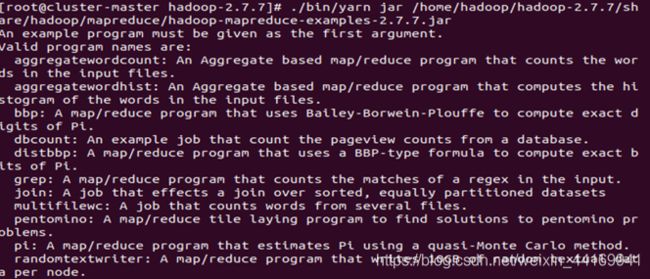
在hadoop中运行Mapreduce的样例
./bin/yarn jar /home/hadoop/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar
然后将数据打包成txt,并存到hdfs的/input/date上
![]()
![]()

然后在java编写需要运行的jar包
package avg;
import common.TemperatureMapper;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class AvgTemperature {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
if (args.length != 2) {
System.err.println("Usage: AvgTemperature );
System.exit(-1);
}
Job job = Job.getInstance();
job.setJarByClass(AvgTemperature.class);
job.setJobName("MapReduce求气温平均值");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(AvgTemperatureMapper.class);
job.setReducerClass(AvgTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
package avg;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class AvgTemperatureMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private static final int MISSING = 9999;
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String year = line.substring(15, 19);
int airTemperature;
if (line.charAt(87) == '+') {
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
}
String quality = line.substring(92, 93);
if (airTemperature != MISSING && quality.matches("[01459]")) {
context.write(new Text(year), new IntWritable(airTemperature));
}
}
}
package avg;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class AvgTemperatureReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
double sum = 0;
long num = 0;
for (IntWritable value : values) {
sum = sum + Double.parseDouble(value.toString());
num++;
}
// 平均值
int avgValue = (int) (sum / num);
context.write(key, new IntWritable(avgValue));
}
}
打包成为jar包,并导入hadoop集群中
![]()
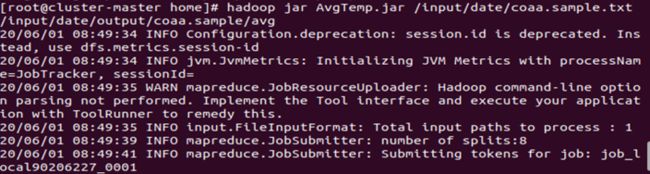
使用
hadoop jar AvgTemp.jar /input/date/coaa.sample.txt /input/date/output/coaa.sample/avg
启动hadoop集群继续计算
进行map过程
对结果进行查看
hadoop fs -cat /input/date/output/coaa.sample/avg/part-r-00000

![]()
总结
在分布式计算中,MapReduce框架负责处理了并行编程里分布式存储、工作调度,负载均衡、容错处理以及网络通信等复杂问题,现在我们把处理过程高度抽象为Map与Reduce两个部分来进行阐述,其中Map部分负责把任务分解成多个子任务,Reduce部分负责把分解后多个子任务的处理结果汇总起来,具体设计思路如下。
(1)Map过程需要继承org.apache.hadoop.mapreduce包中Mapper类,并重写其map方法。通过在map方法中添加两句把key值和value值输出到控制台的代码,可以发现map方法中输入的value值存储的是文本文件中的一行,而输入的key值存储的是该行的首字母相对于文本文件的首地址的偏移量。然后用StringTokenizer类将每一行拆分成为一个个的字段,把截取出需要的字段设置为key,并将其作为map方法的结果输出。
(2)Reduce过程需要继承org.apache.hadoop.mapreduce包中Reducer类,并重写其reduce方法。Map过程输出的
在main()主函数中新建一个Job对象,由Job对象负责管理和运行MapReduce的一个计算任务,并通过Job的一些方法对任务的参数进行相关的设置。本实验是设置使用将继承Mapper的doMapper类完成Map过程中的处理和使用doReducer类完成Reduce过程中的处理。还设置了Map过程和Reduce过程的输出类型:key的类型为Text,value的类型为IntWritable。任务的输出和输入路径则由字符串指定,并由FileInputFormat和FileOutputFormat分别设定。完成相应任务的参数设定后,即可调用job.waitForCompletion()方法执行任务,其余的工作都交由MapReduce框架处理。