cypher相关
一、查询语法
1、单维度查询
MATCH
(node)-[relationship]->(node)
WHERE
(node|RELATIONSHIP)
RETURN
(node|RELATIONSHIP)举例:
查询实体
//n:Check的别名 LIMIT限制展示的节点数量
MATCH (n:Check) RETURN n LIMIT 10
查询关系
MATCH p=()-[:acompany_with]-() RETURN p LIMIT 10
查询实体和关系
MATCH
(n:Disease)-[:belongs_to]->(d:Department)
RETURN
n, d
LIMIT 10
带有where条件的查询
MATCH
(n:Disease)-[:belongs_to]->(d:Department)
WHERE
(d.name="内科")
RETURN
n, d
LIMIT 10
MATCH
(n:Disease)-[r:belongs_to]->(d:Department)
WHERE
(d.name="内科")
RETURN
n, r, d
LIMIT 10
2、多维度关系查询
MATCH
(d1:Disease)-[a:acompany_with]->(d2:Disease)-[b:belongs_to]->(d3:Department)
WHERE
d3.name = '内科'
RETURN
d1, a, d2, b, d3
LIMIT 10
3、正则查询
"~" 后面写正则表达式
MATCH (d:Disease) WHERE d.name=~'肺.*' RETURN d LIMIT 10
4、包含查询
MATCH (d:Disease) WHERE d.name CONTAINS '肺' RETURN d LIMIT 10
也可以自己写正则
MATCH (d:Disease) WHERE d.name=~'.*肺.*' RETURN d LIMIT 10
二、创建语法
1、创建实体和关系
创建不带属性的实体和关系
CREATE (p:Person)-[r:has_disease]->(d:Disease)
MATCH (p:Person)-[r:has_disease]->(d:Disease) RETURN p,r,d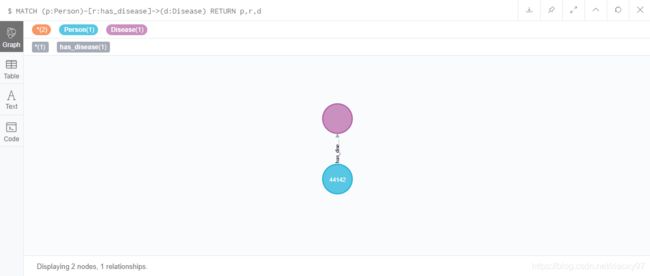
创建带有属性的实体和关系
CREATE (p:Person{name:"小宋"}) RETURN p
CREATE (p:Person{name:"小李"})-[r:has_disease{level:"严重"}]->(d:Disease{name:"发烧"})
MATCH (p:Person)-[r:has_disease]-(d:Disease) WHERE d.name="发烧" RETURN p,r,d
给没有关系的实体创建关系
MATCH (d1:Disease{name:"感冒"}),(d2:Disease{name:"发烧"}) CREATE (d1)-[r:has_symptom]->(d2) RETURN d1,r,d2
merge vs create
merge:若存在该条关系,则不重复创建;若不存在该条关系,则创建该条关系。
create:不管存不存在该条关系,都创建。所以当该条关系存在时,会重复创建该关系。
MATCH (d1:Disease{name:"感冒"}),(d2:Disease{name:"发烧"}) MERGE (d1)-[r:has_symptom]->(d2) RETURN d1,r,d2
MATCH (d1:Disease{name:"感冒"}),(d2:Disease{name:"发烧"}) MERGE (d1)-[r:acompany_with]->(d2) RETURN d1,r,d2
MATCH (d1:Disease{name:"感冒"}),(d2:Disease{name:"发烧"}) CREATE (d1)-[r:acompany_with]->(d2) RETURN d1,r,d2
2、创建类
为实体新增类别
MATCH (d:Disease{name:"感冒"}) SET d:Symptom RETURN d
3、创建属性
为实体添加属性
MATCH (d:Disease) WHERE d.name="感冒" SET d.后遗症="无" RETURN d

为关系添加属性
MATCH (d:Disease{name:"感冒"})-[r:has_symptom]-(s:Symptom{name:"流鼻涕"}) RETURN d,r,s
MATCH (d:Disease{name:"感冒"})-[r:has_symptom]-(s:Symptom{name:"流鼻涕"}) SET r.发作时间=1 RETURN d,r,s
三、删除语法
1、删除关系
MATCH (d1:Disease{name:"发烧"})-[r]-(d2:Disease{name:"感冒"}) RETURN d1,r,d2
MATCH (d1:Disease{name:"发烧"})-[r:acompany_with]-(d2:Disease{name:"感冒"}) DELETE r
MATCH (d1:Disease{name:"发烧"})-[r]-(d2:Disease{name:"感冒"}) RETURN d1,r,d2
2、删除实体
删除带有关系的实体
若直接删除该实体,会报错,提示该实体还存在关系。
MATCH (d:Disease{name:"发烧"}) DELETE d
//删除该实体及该实体带的所有关系
MATCH (d1)-[r]-(d2:Disease{name:"发烧"}) DELETE r,d2
删除孤立实体

MATCH (p:Person) WHERE p.name="小宋" DELETE p

3、删除类的所有实体
若类中的实体和其他类的实体存在关系,则不能直接单独删除该类。

首先删除跟其他类有关系的该类的实体及这些实体和其他类的关系,再删除和其他类没有关系的该类的实体。



4、删除属性
MATCH (d:Disease{name:"感冒"})-[r:has_symptom]-(s:Symptom{name:"流鼻涕"}) REMOVE r.发作时间 RETURN d,r,s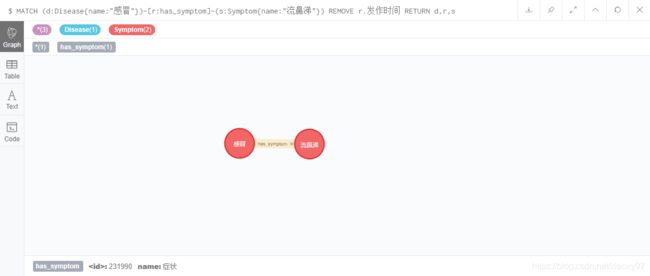
MATCH (d:Disease{name:"感冒"}) REMOVE d.后遗症 RETURN d
5、删除实体所属的类别
MATCH (d:Disease{name:"感冒"}) REMOVE d:Symptom RETURN d
四、更改语法
不能直接修改,只能先新增,后删除。
MATCH (n:User {name:"foo"})-[r:REL]->(m:User {name:"bar"})
CREATE (n)-[r2:NEWREL]->(m)
// copy properties, if necessary
SET r2 = r
WITH r
DELETE r
五、索引
索引是创建在属性上的,能提高查询速度。
创建索引
CREATE INDEX ON :Disease(name)
删除索引
DROP INDEX ON :Disease(name)
给某个属性创建唯一的索引
CREATE CONSTRAINT ON (d:Disease) ASSERT (d.name) IS UNIQUE删除创建的唯一索引
DROP CONSTRAINT ON (d:Disease) ASSERT (d.name) IS UNIQUE
六、复杂查询
1、三度关系内带条件的查询
2、最短路径查询
//SHORTESTPATH 最短路径语法,*..10 十度关系内的最短路径
MATCH (d1:Disease{name:"感冒"}),(d2:Disease{name:"肺炎"}),p=SHORTESTPATH((d1)-[*..10]-(d2)) RETURN d1,p,d2
查询所有最短路径
MATCH (d1:Disease{name:"感冒"}),(d2:Disease{name:"肺炎"}),p=ALLSHORTESTPATHS((d1)-[*..10]-(d2)) RETURN d1,p,d2