SpringBoot使用Jsoup处理Xss攻击,包括RequestBody处理 (包括Jsoup的坑)
一 Jsoup
在处理xss攻击的时候,以前都是自己将特殊字符和敏感属性进行转义或替换,代码十分繁杂,这几天在网上找到了一个比较好的框架:Jsoup, 它可以让java能对Html标签做各种各样的处理,其中就有处理非法标签和属性的api.
Jsoup官网介绍如下:
jsoup实现WHATWG HTML5规范,并将HTML解析为与现代浏览器相同的DOM。
- 从URL,文件或字符串中刮取和解析 HTML
- 使用DOM遍历或CSS选择器查找和提取数据
- 操纵 HTML元素,属性和文本
- 清除用户提交的内容以防止安全白名单,以防止XSS攻击
- 输出整洁的HTML
依赖:
<dependency>
<groupId>org.jsoupgroupId>
<artifactId>jsoupartifactId>
<version>1.11.3version>
dependency>
二 写一个过滤器
在琢磨这个xss攻击拦截的时候,想了好几种方式, 包括spring 的拦截器, spring 的Aop, 但是最后发现还是Filter比较合适
1. Filter
package com.zgd.web.filter.xss;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Configuration;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
/**
* @Author: zgd
* @Date: 18/09/26 17:10
* @Description:
*/
@WebFilter(filterName = "xssFilter", urlPatterns = {"*.json"})
@Slf4j
@Configuration
public class XssRequestFilter implements Filter {
private static List<String> MATCH_WORD = new ArrayList<>();
static {
MATCH_WORD.add("SAVE");
MATCH_WORD.add("UPDATE");
MATCH_WORD.add("INSERT");
MATCH_WORD.add("SET");
}
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain filterChain) throws IOException, ServletException {
if (request instanceof HttpServletRequest){
HttpServletRequest hsr = (HttpServletRequest) request;
String s = hsr.getRequestURL().toString().toUpperCase();
//涉及保存操作的进行xss过滤
boolean b = MATCH_WORD.stream().anyMatch(w -> s.contains(w));
if (b){
request = new XssHttpServletRequestWrapper((HttpServletRequest) request);
}
}
filterChain.doFilter(request, response);
}
@Override
public void destroy() {
}
}
因为这里我不想所有请求都经过xss过滤处理, 所以就把请求路径中,含有"save",“update”,“set”,"insert"的这些入库保存的一些接口来进行过滤
2. wrapper 包装类
我们写的这个Filter过滤类, 目的就是为了将原生的HttpServletRequest, 包装成我们自己的XssRequest,这样我们在web层获取参数的时候,都是从包装的reqeust中获取加工后的参数.
package com.zgd.web.filter.xss;
import com.zgd.common.util.JsoupUtil;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.ArrayUtils;
import javax.servlet.ReadListener;
import javax.servlet.ServletInputStream;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletRequestWrapper;
import java.io.*;
import java.nio.charset.Charset;
import java.util.stream.Stream;
/**
* @Author: zgd
* @Date: 18/09/26 20:05
* @Description:
*/
@Slf4j
public class XssHttpServletRequestWrapper extends HttpServletRequestWrapper {
private HttpServletRequest orgRequest = null;
//判断是否是上传 上传忽略
boolean isUpData = false;
public XssHttpServletRequestWrapper(HttpServletRequest request) {
super(request);
orgRequest = request;
String contentType = request.getContentType();
if (null != contentType) {
isUpData = contentType.startsWith("multipart");
}
}
/**
* 覆盖getParameter方法,将参数名和参数值都做xss过滤。
* 如果需要获得原始的值,则通过super.getParameterValues(name)来获取
* getParameterNames,getParameterValues和getParameterMap也可能需要覆盖
*/
@Override
public String getParameter(String name) {
String value = super.getParameter(name);
if (value != null) {
value = JsoupUtil.clean(value);
}
return value;
}
/**
* 覆盖getParameterValues方法
* 如果需要获得原始的值,则通过super.getParameterValues(name)来获取
*/
@Override
public String[] getParameterValues(String name) {
String[] values = super.getParameterValues(name);
if (ArrayUtils.isNotEmpty(values)) {
values = Stream.of(values).map(s -> JsoupUtil.clean(name)).toArray(String[]::new);
}
return values;
}
/**
* 覆盖getHeader方法,将参数名和参数值都做xss过滤。
* 如果需要获得原始的值,则通过super.getHeaders(name)来获取
* getHeaderNames 也可能需要覆盖
*/
@Override
public String getHeader(String name) {
String value = super.getHeader(name);
if (value != null) {
value = JsoupUtil.clean(value);
}
return value;
}
@Override
public ServletInputStream getInputStream() throws IOException {
if (isUpData) {
return super.getInputStream();
} else {
//处理原request的流中的数据
byte[] bytes = inputHandlers(super.getInputStream()).getBytes();
final ByteArrayInputStream bais = new ByteArrayInputStream(bytes);
return new ServletInputStream() {
@Override
public int read() throws IOException {
return bais.read();
}
@Override
public boolean isFinished() {
return false;
}
@Override
public boolean isReady() {
return false;
}
@Override
public void setReadListener(ReadListener readListener) {
}
};
}
}
public String inputHandlers(ServletInputStream servletInputStream) {
StringBuilder sb = new StringBuilder();
BufferedReader reader = null;
try {
reader = new BufferedReader(new InputStreamReader(servletInputStream, Charset.forName("UTF-8")));
String line = "";
while ((line = reader.readLine()) != null) {
sb.append(line);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (servletInputStream != null) {
try {
servletInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
String finl = JsoupUtil.cleanJson(sb.toString());
return finl;
}
}
在这个wrapper包装类中,我对一些常用的获取参数的方法都进行了重写. 使用JsoupUtil.clean(value)进行了处理,这个JsoupUtil就是的重点
3. JsoupUtil
package com.zgd.common.util;
/**
* @Author: zgd
* @Date: 18/09/26 20:13
* @Description:
*/
import lombok.extern.slf4j.Slf4j;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.safety.Whitelist;
import java.io.*;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 描述: 过滤和转义html标签和属性中的敏感字符
*/
@Slf4j
public class JsoupUtil{
/**
* 标签白名单
* relaxed() 允许的标签:
* a, b, blockquote, br, caption, cite, code, col, colgroup, dd, dl, dt, em, h1, h2, h3, h4,
* h5, h6, i, img, li, ol, p, pre, q, small, strike, strong, sub, sup, table, tbody, td, tfoot, th, thead, tr, u, ul。
* 结果不包含标签rel=nofollow ,如果需要可以手动添加。
*/
static Whitelist WHITELIST = Whitelist.relaxed();
/**
* 配置过滤化参数,不对代码进行格式化
*/
static Document.OutputSettings OUTPUT_SETTINGS = new Document.OutputSettings().prettyPrint(false);
/**
* 设置自定义的标签和属性
*/
static {
/**
* addTags() 设置白名单标签
* addAttributes() 设置标签需要保留的属性 ,[:all]表示所有
* preserveRelativeLinks() 是否保留元素的URL属性中的相对链接,或将它们转换为绝对链接,默认为false. 为false时将会把baseUri和元素的URL属性拼接起来
*/
WHITELIST.addAttributes(":all","style");
WHITELIST.preserveRelativeLinks(true);
}
public static String clean(String s) {
/**
* baseUri ,非空
* 如果baseUri为空字符串或者不符合Http://xx类似的协议开头,属性中的URL链接将会被删除,如会变成
* 如果WHITELIST.preserveRelativeLinks(false), 会将baseUri和属性中的URL链接进行拼接
*/
log.info("[xss过滤标签和属性] [原字符串为] : {}",s);
String r = Jsoup.clean(s, "http://base.uri", WHITELIST, OUTPUT_SETTINGS);
log.info("[xss过滤标签和属性] [过滤后的字符串为] : {}",r);
return r;
}
/**
* 处理Json类型的Html标签,进行xss过滤
* @param s
* @return
*/
public static String cleanJson(String s) {
//先处理双引号的问题
s = jsonStringConvert(s);
return clean(s);
}
/**
* 将json字符串本身的双引号以外的双引号变成单引号
* @param s
* @return
*/
public static String jsonStringConvert(String s) {
log.info("[处理JSON字符串] [将嵌套的双引号转成单引号] [原JSON] :{}",s);
char[] temp = s.toCharArray();
int n = temp.length;
for (int i = 0; i < n; i++) {
if (temp[i] == ':' && temp[i + 1] == '"') {
for (int j = i + 2; j < n; j++) {
if (temp[j] == '"') {
//如果该字符为双引号,下个字符不是逗号或大括号,替换
if (temp[j + 1] != ',' && temp[j + 1] != '}') {
//将json字符串本身的双引号以外的双引号变成单引号
temp[j] = '\'';
} else if (temp[j + 1] == ',' || temp[j + 1] == '}') {
break;
}
}
}
}
}
String r = new String(temp);
log.info("[处理JSON字符串] [将嵌套的双引号转成单引号] [处理后的JSON] :{}",r);
return r;
}
public static void main(String[] args) {
String s = "test![]() +
"onclick=function src=\"https://www.xxx.png\" title=\"\" width=\"100%\" alt=\"\"/>" +
"
+
"onclick=function src=\"https://www.xxx.png\" title=\"\" width=\"100%\" alt=\"\"/>" +
"
电饭锅进口量的说法
————————
大幅度发
" +
"sd
dsf
"
+
"撒地方似懂非懂
" +
"撒地方
" +
"撒旦法
";
System.out.println(clean(s));
}
}
首先Whitelist.relaxed()是指标签的白名单, 在这个白名单外的其他标签将会被替换为空字符串
除了Whitelist.relaxed(),还有下面几种预设的可以选择.
官网Whitelist介绍

- Whitelist.none()
仅允许文本节点:将剥离所有HTML。 - Whitelist.basic()
允许a, b, blockquote, br, cite, code, dd, dl, dt, em, i, li, ol, p, pre, q, small, span, strike, strong, sub, sup, u, ul和适当的属性 - Whitelist.simpleText()
此白名单只允许简单的文本格式: b, em, i, strong, u。 - Whitelist.basicWithImages()
此白名单允许使用相应的文本标签Whitelist.basic(),并且还允许 img带有适当属性的标签 src指向 http或 https。
除了上面的预设,我们还可以自己添加白名单标签:
//将允许标签添加到白名单。(如果不允许使用标签,则会从HTML中删除它。)
public Whitelist addTags(String ... tags)
添加白名单属性
public Whitelist addAttributes(String tag,String ... attributes)
//例如:a标签上的addAttributes("a", "href", "class")允许href和class属性
5. 测试xss攻击
String l = "alert(2); /)
 test"
test"
;
System.out.println(clean(l));
结果:
alert(2);![]()
![]() test
test
Jsoup的几个坑
- Jsoup会对不在白名单的标签进行删除处理, 而且如果标签没有闭合, 会将这个标签一直删除到闭合为止
String l = "span标签 一级标题
";
System.out.println(clean(l));
返回结果 (将不匹配的也去掉了)
span标签一级标题
这个问题在json请求中格外严重
String l = "{\"name\":\"zgdspan标签 一级标题
\"}";
System.out.println(clean(l));
结果: 已经完全错误了
{"name":"zgdspan标签一级标题
"}
- Jsoup处理后,a标签的
href属性丢失
比如我们处理:
String l = "test"
;
System.out.println(clean(l));
结果却是:
<p><a>testa>
就算加上whitelist.addAttributes("a","href")也无济于事
最后发现了这个:
whitelist.preserveRelativeLinks(true);
public Whitelist preserveRelativeLinks(boolean preserve)
是否保留元素的URL属性中的相对链接,或将它们转换为绝对链接,默认为false. 为false时将会把baseUri和元素的URL属性拼接起来
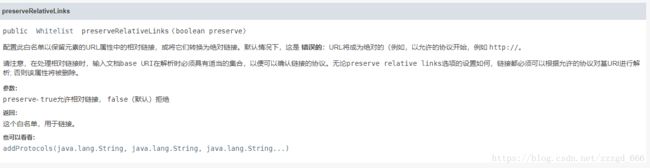
baseUri也就是api中的
static String clean(String bodyHtml, String baseUri, Whitelist whitelist, Document.OutputSettings outputSettings)
代码:
//按理来说,baseUri应该填写工程的Uri
String r = Jsoup.clean(s, "http://base.uri", WHITELIST, OUTPUT_SETTINGS);
如果baseUri为空字符串或者不符合Http://xx类似的协议开头,属性中的URL链接将会被删除,如会变成
如果WHITELIST.preserveRelativeLinks(false), 会将baseUri和属性中的URL链接进行拼接
测试几种情况:
String l = ";
System.out.println(clean(l));
- baseUri = “”, preserveRelativeLinks(false)
结果:
- baseUri = “”, preserveRelativeLinks(true)
结果:
- baseUri = “xxx”, preserveRelativeLinks(true)
结果:
- baseUri = “xxx”, preserveRelativeLinks(false)
结果:
- baseUri = “http://baseUri/” , preserveRelativeLinks(false)
结果:
- baseUri = “http://baseUri/” , preserveRelativeLinks(true)
结果:
总结:
-
标签中的URL链接, 以白名单中的协议名(
http://,https://…)开头的时候, 永远都存在 -
标签中的URL链接不满足白名单中的协议名(
http://,https://…)开头的时候:- baseUri不满足
http://xxx和https://等协议名开头的时候, 不管preserveRelativeLinks设置true还是false, 都会删除href属性 - 当baseUri满足协议名开头的时候, preserveRelativeLinks为true的时候, 保留href不作处理 , 为false的时候会拼接参数
- baseUri不满足
综上所述, 设置一个类似http://base.uri的baseUri, preserveRelativeLinks设置为true就可以保证所有URL不会删除