数据分析技术:结构方程模型;想要“追求”,了解是第一步
基础准备
上篇推送,我们正式开启了AMOS软件应用的介绍。看过上篇文章的朋友知道AMOS软件是用于处理结构方程模型的,文章也简要介绍了结构方程模型可以细分成测量模型和结构模型,以及AMOS软件分析结构方程模型的原理,大家可以点击下方链接回顾:
-
AMOS软件介绍开篇;草堂君给数据分析学习者的几点建议
今天这篇文章,草堂君将详细介绍结构方程模型的基本概念、分析原理和注意事项。首先从结构方程模型的基本概念开始,结构方程模型可以分成两部分:测量模型和结构模型。
测量模型
在社会科学研究领域,有很多概念是无法直接测量和观测的,例如人们的焦虑、态度、动机、工作压力、满意度等等,它们都是抽象的概念。
上篇文章举过相亲的例子,女孩相亲结束回家,家人问其是否对男孩满意,女孩的满意度就是一个抽象概念,是女孩对男孩所有外在的,能够测量和量化条件的综合反应,这些条件包括男孩的家庭背景、工作、学历、身高、长相等等。在这个例子中,女孩满意度是抽象概念,无法直接测量,在结构方程模型中称为潜在变量或构成变量;而男孩的身高、工作和学历等是能够直接测量和量化的,称为测量变量或观察变量。女孩了解越多男孩的现实条件,女孩对男孩的满意程度就越真实,越可靠。可以最大程度避免嫁后悔的情况出现(社会很现实,很残酷,男同胞们努力)。

一般来说,每个潜在变量对应的观察变量数目至少要两个(想想如果只有一个,那就可以直接测量了)。潜在变量是两个以上测量变量的综合反应,反过来,潜在变量也能够在一定程度上解释测量变量的数值高低变化。例如,女孩对男孩的综合满意度,可以在一定程度上解释女孩对男孩家庭背景,身高和学历等条件的满意度,需要注意,这里不是完全解释,是一定程度的解释,也就意味着还有不能解释的残差。由潜在变量和测量变量组成的解释模型就称为测量模型,如下图所示:
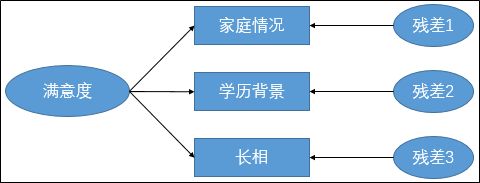
上图就是用AMOS软件的测量模型画法。椭圆形代表不能直接测量的变量,包括满意度和残差,而测量变量用矩形表示。注意箭头的方向,箭头的终点表示因变量,箭头的起点表示自变量。上图的测量模型可以表述为综合满意度可以在一定程度上解释男孩的家庭情况,学历背景和长相等,公式表达如下:

从上面的公式可以看出,满意度是家庭情况、学历背景和长相的共同解释变量。有些时候,潜在变量也可以是测量变量的共同影响变量。潜在变量到底是解释变量还是影响变量,这是由潜在变量在模型中扮演原因角色还是结果角色,上述案例明显是结果角色。不管潜在变量扮演什么角色,在测量模型中,潜在变量是自变量,测量变量是因变量。
结构模型
结构模型研究的是变量(包括潜在变量和测量变量)之间的线性回归方程,变量之间的关系交错,线性回归方程数目多。回顾草堂君前面推送的路径分析文章案例(点击文章链接回顾:数据分析方法:路径分析入门;数据分析需要剥丝抽茧的耐心!),现在有四个测量变量(矩形),分析者根据实际情况,画出了下面的路径图。

上面的路径图实际上可以写成两个线性回归方程。由路径图分解线性回归方程时,可以找因变量个数(箭头的终点),有多少个因变量就有多少个线性回归方程。如果直接按照路径图分解的线性回归方程,一个一个的拟合,那么需要花费大量的时间。
![]()
采用AMOS进行分析,软件将会根据分析者画出的路径图,将复杂的相关关系拆解成数个线性回归模型(路径分析只考虑线性相关关系),所有拆解的线性回归模型总体就称为结构模型,然后直接进行拟合,可以节省大量的时间。
结构方程模型
在AMOS中,将测量模型和结构模型都画在一起,如下图所示。需要注意,所有因变量都需要加上残差项。此外,需要明确,结构方程模型图的绘制是分析者以实际经验为基础绘制出来的,至于模型是否成立,需要采集数据加以验证。
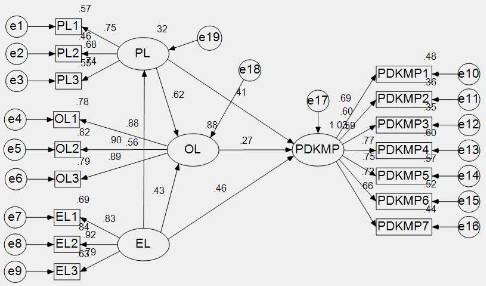
由此可知,AMOS的结构方程模型分析是一种验证性分析,而非探索性分析。通过问卷采集的数据能够很好的拟合结构方程模型,那么说明分析者的关系假设是成立的,反之则不成立。那么如何判断拟合效果呢?
通过采集的数据,两两变量之间都能够计算协方差(相关系数),因为是两两变量之间产生的,因此这些协方差能够写成矩阵的形式,如下图(左)所示,Cov代表协方差,Var代表方差。这个表格以黄色对角线为分解,两半边是对称的。

AMOS模型将左边的实际变量关系与右边的拟合变量关系进行对比,两者差值平方和组成的统计量是服从卡方分布的,从而能够通过卡方分布对结构方程模型的拟合效果作出检验,如果差异达到超过设定的界限(设定显著性对应的界限值),说明模型的拟合效果不佳,反之则认为模型的拟合效果良好。需要注意,模型拟合效果好,不代表路径图中每个箭头标注的变量关系都成立,具体的变量之间的假设关系是否成立,还需要看回归系数的检验结果(T检验结果)。
对T检验和卡方检验知识不熟悉或遗忘的朋友,可以回顾统计基础导航页或SPSS导航页(公众号首页下方的导航栏获取)。
结构方程的样本量
有很多的朋友询问过草堂君关于问卷发放量的问题,这个问题没有精确答案,只有学者的通常做法。可以从上面介绍的结构方程模型的原理为切入点,到底样本量多大才合适?
结构方程模型效果的判断是通过实际和拟合的方差协方差矩阵(或相关系数矩阵,两者可以互推)的对比得出来的。从相关角度来看,样本量越大,相关关系越符合实际;从对比角度来看,样本量越大,卡方检验的结果为显著(小于0.05)就越容易;因此,样本量的选择是一个互相平衡的问题,没有定论。
一般的学者认为样本量在200到500之间是合适的。也有学者从量表数据是否服从多元正态分布出发,认为如果总体服从多元正态分布,那么样本量只需取到量表题项的5倍即可(量表有15题,样本量为75),如果不服从,则要取到10倍到15倍,且不少于200。由此可见,样本量取到200以上是得到大多数学者认同的,如果题项较多,可以按照10到15倍的比例决定样本量。
QQ群提供AMOS软件和未来案例数据下载,群号在下方温馨提示,也可以直接扫描二维码入群。想一步一步学习的朋友,赶紧下载安转,跟着草堂君循序渐进学习吧。
温馨提示:
-
数据分析课程私人定制,一对一辅导,添加微信(possitive2)咨询!
-
生活统计学QQ群:134373751,用于分享文章提到的各种案例资料、软件、数据文件等。支持各种资料的直接下载和百度云盘下载。
-
生活统计学微信交流群,用于各自行业的数据研究项目及其成果交流分享;由于人数大于100人,请添加微信possitive2,拉您入群。
-
数据分析咨询,请点击首页下方“互动咨询”板块,获取咨询流程!
