Kafka性能监控与优化
一 、性能监控
1 查看机器负载top:
右上角 load average 的 3 个值 1.29 ,0.74, 1.34 代表过去1分钟、5分钟 、15分钟load average
假如 load值为5.2, cpu核数为4 ,均值1.3>1 ,则存在进程抢不到CPU。 如下值1.29说明负载较小,均负载在1.29/4 = 0.32
如果load值越来越大,说明负载持续增加
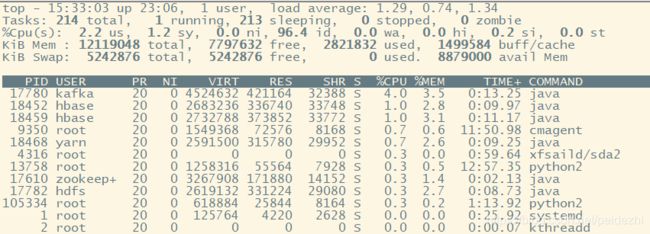
第三行cpu(s)表示用户进程使用CPU时间总的占比平均值。
如下图12个Core, 所有us求和取平均值, 及cpu(s)= 400/12 =34%
top +1即可查看

清单中的 %CPU, 上次更新到现在的CPU时间占用百分比。
%CPU显示的是进程占用一个核的百分比,而不是整个cpu(8核)的百分比,有时候可能大于100,那是因为该进程启用了多线程占用了多个核心,所以有时候我们看该值得时候会超过100%,但不会超过总核数*100。
2 kafka GC日志路径查看。
kafka的GC日志:/run/cloudera-scm-agent/process/150-kafka-KAFKA_BROKER
日志文件名类似:kafkaServer-gc.log
GC说明,参看 https://blog.csdn.net/qq_38157516/article/details/80451599
https://blog.csdn.net/xiaodu93/article/details/61926114
http://www.knowsky.com/957110.html
2.1 FULL GC频率和时长
长时间的停顿会令 Broker 端抛出各种超时异常。
2.2 活跃对象大小
这个指标是你设定堆大小的重要依据,同时它还能帮助你细粒度地调优 JVM 各个代的堆大小。
活跃对象大小,即经过FULL GC后,老年代还剩余的存活对象大小(可以取多次平均值)。
如果FULL GC后剩余对象500M存活,设置老年代堆大小设置成该数值的 1.5 倍或 2 -3倍,即大约 1.0GB比较安全。
newRatio参数,设定了新生代和老年代比值,默认值为2(old/new). 一般设置为老年存活对象的1.2到2倍
永久代设置1.2-2倍。
具体设置建议,参考:https://blog.csdn.net/zfgogo/article/details/81260172
如果频繁FULL GC, 可以开启 G1 的 -XX:+PrintAdaptiveSizePolicy 开关(默认的 GC 收集器设置为 G1),让 JVM 告诉你到底是谁引发了 Full GC。
2.3 应用线程总数。这个指标帮助你了解 Broker 进程对 CPU 的使用情
3 集群监控
3.1 检查broker是否启动。
并且查看端口是否建立监听。
3.2 broker关键日志查看
1)监控 kafka ,log compaction线程是否正常运行。
2)副本拉取消息的线程,通常以 ReplicaFetcherThread 开头
线程挂掉,不再从 Leader 副本拉取消息,因而 Follower 副本的 Lag 会越来越大。
上述异常,立即查看kafka 日志信息
一般日志路径:/var/log/kafka/kafka-broker-hadoop001.log
3.3 Broker 端的关键 JMX 指标
1)BytesIn/BytesOut:即 Broker 端每秒入站和出站字节数。你要确保这组值不要接近你的网络带宽,否则这通常都表示网卡已被“打满”,很容易出现网络丢包的情形
2) NetworkProcessorAvgIdlePercent:即网络线程池线程平均的空闲比例。通常来说,你应该确保这个 JMX 值长期大于 30%。如果小于这个值,就表明你的网络线程池非常繁忙,你需要通过增加网络线程数或将负载转移给其他服务器的方式,来给该 Broker 减负。
3)RequestHandlerAvgIdlePercent:即 I/O 线程池线程平均的空闲比例。同样地,如果该值长期小于 30%,你需要调整 I/O 线程池的数量,或者减少 Broker 端的负载。
4)UnderReplicatedPartitions:即未充分备份的分区数。所谓未充分备份,是指并非所有的 Follower 副本都和 Leader 副本保持同步。一旦出现了这种情况,通常都表明该分区有可能会出现数据丢失。因此,这是一个非常重要的 JMX 指标。
注意: 如果某个leader replication存在UnderReplicated的分区,则出现了较严重问题。
under replicated分区是指fellow分区同步leader replication超过了replica.lag.time.max.ms设置值(CDH默认10s),将从副本中移除。
offline partion是只某个分区的所有分区不可用。 under relicated是 分区的部分副本不可用。
5)ISRShrink/ISRExpand:即 ISR 收缩和扩容的频次指标。如果你的环境中出现 ISR 中副本频繁进出的情形,那么这组值一定是很高的。这时,你要诊断下副本频繁进出 ISR 的原因,并采取适当的措施。
6)ActiveControllerCount:即当前处于激活状态的控制器的数量。正常情况下,Controller 所在 Broker 上的这个 JMX 指标值应该是 1,其他 Broker 上的这个值是 0。如果你发现存在多台 Broker 上该值都是 1 的情况,一定要赶快处理,处理方式主要是查看网络连通性。这种情况通常表明集群出现了脑裂。脑裂问题是非常严重的分布式故障,Kafka 目前依托 ZooKeeper 来防止脑裂。但一旦出现脑裂,Kafka 是无法保证正常工作的
其它监控指标还有很多,可以按需官网查询集成到监控平台。
3.4 kafka客户端监控
1) 客户端ping kafka服务器,看下RTT,往返花费时间。太长,网络速度问题必须解决。
2)kafka-producer-network-thread 开头的线程是你要实时监控的。
它是负责实际消息发送的线程。一旦它挂掉了,Producer 将无法正常工作,但你的 Producer 进程不会自动挂掉,因此你有可能感知不到
3)Producer 角度,你需要关注的 JMX 指标是 request-latency,即消息生产请求的延时。这个 JMX 最直接地表征了 Producer 程序的 TPS
4)对于消费者而言,心跳线程事关 Rebalance,也是必须要监控的一个线程。
它的名字以 kafka-coordinator-heartbeat-thread 开头。
5) 从 Consumer 角度来说,records-lag 和 records-lead 是两个重要的 JMX 指标。
它们直接反映了 Consumer 的消费进度
records-lag: 滞后程度,就是指消费者当前落后于生产者的程度。比方说,Kafka 生产者向某主题成功生产了 100 万条消息,你的消费者当前消费了 80 万条消息,那么我们就说你的消费者滞后了 20 万条消息,即 Lag 等于 20 万。
records-lead: 指消费者最新消费消息的位移与分区当前第一条消息位移的差值。
监控方法:
a)使用 Kafka 自带的命令行工具 kafka-consumer-groups 脚本。
$ bin/kafka-consumer-groups.sh --bootstrap-server
![]()
b)使用 Kafka Java Consumer API 编程。
c)使用 Kafka 自带的 JMX 监控指标。
kafka.consumer:type=consumer-fetch-manager-metrics,client-id=“{client-id}”的 JMX 指标,里面有很多属性。
可以针对分区级别:
JMX 名称为:kafka.consumer: type=consumer-fetch-manager-metrics,partition=“{partition}”,topic=“{topic}”,client-id=“{client-id}”
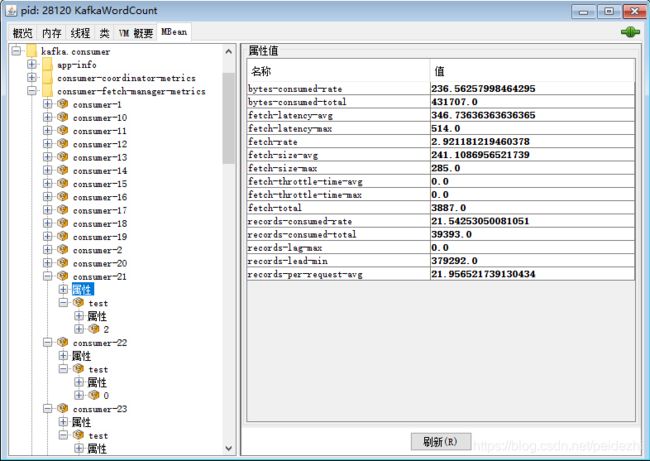
使用jconsole监控截图:(jdk_home/bin/jconsole)
JMX 方式只能监控客户端即counsumer所在节点。当主题较多,消费者较多时,监控不是很方便。
如果监控kafka主题、分区、数据流入流出、调整分区数、Lag等kafka manager比较直观好看,不推荐kafka tool,不方便会卡顿。
如果要监控内存、线程安全、进程,Lag、Lead等的话,就会使用jconsole和jvisualvm,另外,有利于排查kafka是否存在死锁问题。
6)如果你使用了 Consumer Group,那么有两个额外的 JMX 指标需要你关注下,一个是 join rate,另一个是 sync rate。
它们说明了 Rebalance 的频繁程度。如果在你的环境中,它们的值很高,那么你就需要思考下 Rebalance 频繁发生的原因了。
二、Kafka性能优化
1 应用层面优化。
1.1)增加吞吐量:
a)Broker 端
num.replica.fetchers
表示的是 Follower 副本用多少个线程来拉取消息,默认使用 1 个线程。如果你的 Broker 端 CPU 资源很充足,不妨适当调大该参数值,加快 Follower 副本的同步速度。增加这个值后,你通常可以看到 Producer 端程序的吞吐量增加。
调优GC参数
避免经常性的 Full GC,目前不论是 CMS 收集器还是 G1 收集器,其 Full GC 采用的是 Stop The World 的单线程收集策略,非常慢,因此一定要避免。
b) Producer 端
batch.size
目前它们的默认值都偏小,特别是默认的 16KB 的消息批次大小一般都不适用于生产环境。设置512k-1M
linger.ms
适当增加 10-100.默认值0
compression.type = lz4 或zstd , 减小网络IO
acks=1或0
增加buffer.memory
当多个线程共享一个producer实例时,由于公用缓存,就可能会碰到缓冲区不够用的情形。倘若频繁地遭遇 TimeoutException:Failed to allocate memory within the configured max blocking time 这样的异常,那么你就必须显式地增加 buffer.memory 参数值
c) Consumer端
I)采用多consumer进程或线程
II) 增加fetch.min.bytes参数,默认1字节,调大为1K或更大
表示只要 Kafka Broker 端积攒了 1 字节的数据,就可以返回给 Consumer 端,
1.2)减小延时:
延时和吞吐量有时有些互斥,说一要视情况调整:
a)在Broker 端,
依然要增加 num.replica.fetchers 值以加快 Follower 副本的拉取速度,减少整个消息处理的延时
b)在 Producer 端
设置 linger.ms=0,我们希望消息尽快地被发送出去,因此不要有过多停留
同时不要启用压缩。因为压缩操作本身要消耗 CPU 时间,会增加消息发送的延时。另外,最好不要设置 acks=all。我们刚刚在前面说过,Follower 副本同步往往是降低 Producer 端吞吐量和增加延时的首要原因。
c)在 Consumer 端,
我们保持 fetch.min.bytes=1 即可,也就是说,只要 Broker 端有能返回的数据,立即令其返回给 Consumer,缩短 Consumer 消费延时。
2) JVM优化
3)OS优化
a)在操作系统层面,你最好在挂载(Mount)文件系统时禁掉 atime 更新。记录 atime 需要操作系统访问 inode 资源,而禁掉 atime 可以避免 inode 访问时间的写入操作,减少文件系统的写操作数。你可以执行 mount -o noatime 命令进行设置
b)文件系统,我建议你至少选择 ext4 或 XFS。ZFS最新的据说更好
c)swap 空间的设置。 个人建议将 swappiness 设置成一个很小的值,比如 1~10 之间
d)ulimit -n 和 vm.max_map_count。前者如果设置得太小,你会碰到 Too Many File Open 这类的错误,而后者的值如果太小,在一个主题数超多的 Broker 机器上,你会碰到 OutOfMemoryError:Map failed 的严重错误,因此,我建议在生产环境中适当调大此值,比如将其设置为 655360。具体设置方法是修改 /etc/sysctl.conf 文件,增加 vm.max_map_count=655360,保存之后,执行 sysctl -p 命令使它生效。
e) 操作系统页缓存大小
给 Kafka 预留的页缓存越大越好,最小值至少要容纳一个日志段的大小,也就是 Broker 端参数 log.segment.bytes 的值,该值默认1G。
实际上 page cache大小不用设置,默认读写文件都会用到,当内存不够时,作为应急,cache和buffer内存可以释放。
但是有些参数是可以控制其工作方式。
free 命令可以查看 cache(page cache) 和 buffer(buffer cache)缓存使用大小。新版本linux将两者合二为一显示了。
概念参考:https://blog.csdn.net/lqglqglqg/article/details/82313966
https://blog.csdn.net/jasonchen_gbd/article/details/80151328
II) 控制page cache参数: ls /proc/sys/vm
如下几个参数对page cache大小有影响:
vm.dirty_background_bytes = 0
vm.dirty_background_ratio = 10
vm.dirty_bytes = 0
vm.dirty_expire_centisecs = 3000
vm.dirty_ratio = 30
vm.dirty_writeback_centisecs = 500
1)dirty_writeback_centisecs , dirty_expire_centisecs
后台进程pdflush或flush-n:m负责异步将写操作writeback到磁盘。这个进程每个dirty_writeback_centisecs(默认值500,即5s)厘秒唤醒然后执行一次。他会检查这些脏页面的时间是不是超时了,超时的会被写磁盘。超时时间就是dirty_expire_centisecs(30s), 加大此值可以增加page cache大小
2)dirty_background_bytes与dirty_background_ratio(默认10%)
参数意义:当脏页所占的百分比(相对于系统总内存)达到dirty_background_ratio或者
脏页所占的内存数量超过dirty_background_bytes时,内核的pdflush线程开始回写脏页。
注意:dirty_background_bytes参数和dirty_background_ratio参数是相对的,只能指定其中一个,另一个参数的值自动清零
3)dirty_bytes与dirty_ratio(默认30%)
如果dirty_background_bytes与dirty_background_ratio还不能有效发挥作用,导致脏页面比例持续升高,并且超过了dirty_ratio,那么那么执行write的那个用户态进程自己会block住,等待pdflush干完活再唤起。在写入超大时,即时内核的pdflush线程满足dirty_background_ratio开始回收了,也可能立马超过dirty_background_ratio到达dirty_ratio。
4)drop_caches
向/proc/sys/vm/drop_caches文件中写入数值可以使内核释放page cache,dentries和inodes缓存所占的内存。生产环境不要用。
只释放pagecache:
echo 1 > /proc/sys/vm/drop_caches
只释放dentries和inodes缓存:
echo 2 > /proc/sys/vm/drop_caches
释放pagecache、dentries和inodes缓存:
echo 3 > /proc/sys/vm/drop_caches
这个操作不是破坏性操作,脏的对象(比如脏页)不会被释放,因此要首先运行sync命令。
5)vfs_cache_pressure
控制内核回收dentry和inode cache内存的倾向。
默认值是100,内核会根据pagecache和swapcache的回收情况,让dentry和inode cache的内存占用量保持在一个相对公平的百分比上。
减小vfs_cache_pressure会让内核更倾向于保留dentry和inode cache。当vfs_cache_pressure等于0,在内存紧张时,内核也不会回收dentry和inode cache,这容易导致OOM。
如果vfs_cache_pressure的值超过100,内核会更倾向于回收dentry和inode cache。
6)min_free_kbytes
这个参数用来指定强制Linux VM保留的内存区域的最小值,单位是kb。VM会使用这个参数的值来计算系统中每个低端内存域的watermark[WMARK_MIN]值。每个低端内存域都会根据这个参数保留一定数量的空闲内存页。
一部分少量的内存用来满足PF_MEMALLOC类型的内存分配请求。如果进程设置了PF_MEMALLOC标志,表示不能让这个进程分配内存失败,可以分配保留的内存。并不是所有进程都有的。kswapd、direct reclaim的process等在回收的时候会设置这个标志,因为回收的时候它们还要为自己分配一些内存。有了PF_MEMALLOC标志,它们就可以获得保留的低端内存。
如果设置的值小于1024KB,系统很容易崩溃,在负载较高时很容易死锁。如果设置的值太大,系统会经常OOM。