基于Lucene、TF-IDF、余弦相似性实现长文本相似度检测
什么是TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency),汉译为词频-逆文本频率指数。
TF指一个词出现的频率,假设在一篇文章中某个词出现的次数是n,文章的总词数是N,那么TF=n/N
逆文本频率指数IDF一般用于表示一个词的权重,其求解办法为IDFi=log(D/Dw),这里D指的是文本总量,Dw指的是词i在Dw篇文本中出现过。
这篇文章讲解的很详细《TF-IDF原理及使用》
什么是余弦相似
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。
对于二维空间,根据向量点积公式 ,显然可以得知:
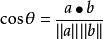
假设向量a、b的坐标分别为(x1,y1)、(x2,y2) 。则:
TF-IDF和余弦相似应用
这里有两篇文章讲解的非常清楚,我就不再多说了,直接上文章链接。
《TF-IDF与余弦相似性的应用(一):自动提取关键词》
《TF-IDF与余弦相似性的应用(二):找出相似文章》
下面就具体讲解下代码的实现。
添加Gradle依赖
用到了WebMagic爬虫框架、Jieba分词java版,Lucene、Apache等一些库
compile group: 'us.codecraft', name: 'webmagic-core', version: '0.7.3'
// https://mvnrepository.com/artifact/us.codecraft/webmagic-extension
compile group: 'us.codecraft', name: 'webmagic-extension', version: '0.7.3'
// https://mvnrepository.com/artifact/com.huaban/jieba-analysis
compile group: 'com.huaban', name: 'jieba-analysis', version: '1.0.2'
compile group: 'commons-io', name: 'commons-io', version: '2.6'
compile group: 'org.apache.lucene', name: 'lucene-core', version: '3.6.0'
compile group: 'org.apache.lucene', name: 'lucene-queryparser', version: '3.6.0'
爬取样本库并进行分词
因为测试算法的有效性需要大量的文本,我采用WebMagic爬虫框架,爬取华为应用市场的应用描述信息来当做样本库。
WebMaigc的使用请看《WebMagic爬取应用市场应用信息》。
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Selectable;
/**
* @author wzj
* @create 2018-07-17 22:06
**/
public class AppStoreProcessor implements PageProcessor
{
// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000);
public void process(Page page)
{
//获取名称
String name = page.getHtml().xpath("//p/span[@class='title']/text()").toString();
page.putField("appName",name );
String desc = page.getHtml().xpath("//div[@id='app_strdesc']/text()").toString();
page.putField("desc",desc );
if (page.getResultItems().get("appName") == null)
{
//skip this page
page.setSkip(true);
}
//获取页面其他链接
Selectable links = page.getHtml().links();
page.addTargetRequests(links.regex("(http://app.hicloud.com/app/C\\d+)").all());
}
public Site getSite()
{
return site;
}
public static void main(String[] args)
{
Spider.create(new AppStoreProcessor())
.addUrl("http://app.hicloud.com")
.addPipeline(new MyPipeline())
.thread(20)
.run();
}
}自定义Piple来保存爬取的应用数据,因为要对描述信息进行分词,需要对数据进行预处理,主要包含
- 通过正则去除中文特殊字符和标点符号 desc.replaceAll("[\\p{P}+~$`^=|<>~`$^+=|<>¥×]", "")
- 通过正则去除回车符、制表符等特殊符号 desc.replaceAll("\\t|\\r|\\n","");
- 通过正则去除空格 desc.replaceAll(" ","");
接着对数据进行分词,采用jieba分析java版进行分词处理
import com.huaban.analysis.jieba.JiebaSegmenter;
import org.apache.commons.io.IOUtils;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
import java.io.FileWriter;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
/**
* @author wzj
* @create 2018-07-17 22:16
**/
public class MyPipeline implements Pipeline
{
/**
* 保存文件的路径
*/
private static final String saveDir = "D:\\cache\\";
/**
* jieba分词java版
*/
private JiebaSegmenter segmenter = new JiebaSegmenter();
/*
* 统计数目
*/
private int count = 1;
/**
* Process extracted results.
*
* @param resultItems resultItems
* @param task task
*/
public void process(ResultItems resultItems, Task task)
{
String appName = resultItems.get("appName");
String desc = resultItems.get("desc");
//去除标点符号
desc = desc.replaceAll("[\\p{P}+~$`^=|<>~`$^+=|<>¥×]", "");
desc = desc.replaceAll("\\t|\\r|\\n","");
//去除空格
desc = desc.replaceAll(" ","");
List vecList = segmenter.sentenceProcess(desc);
StringBuilder stringBuilder = new StringBuilder();
for (String s : vecList)
{
stringBuilder.append(s + " ");
}
//去除最后一个空格
String writeContent = stringBuilder.toString();
if (writeContent.length() > 0)
{
writeContent = writeContent.substring(0,writeContent.length() - 1);
}
String appSavePath = Paths.get(saveDir, appName + ".txt").toString();
FileWriter fileWriter = null;
try
{
fileWriter = new FileWriter(appSavePath);
fileWriter.write(writeContent);
}
catch (IOException e)
{
e.printStackTrace();
}
finally
{
IOUtils.closeQuietly(fileWriter);
}
System.out.println(String.valueOf(count++) + " " + appName);
}
} 将爬取文本建立Lucene索引
需要指定文本文件路径和索引保存路径
/**
* 将所有的文档加入lucene中
* @throws IOException
*/
public void indexDocs() throws IOException
{
System.out.println("Number of files : " + docNumbers);
File[] listOfFiles = Paths.get(docPath).toFile().listFiles();
NIOFSDirectory dir = new NIOFSDirectory(new File(saveIndexPath));
IndexWriter indexWriter = new IndexWriter(dir,
new IndexWriterConfig(Version.LUCENE_36, new WhitespaceAnalyzer(Version.LUCENE_36)));
for (File file : listOfFiles)
{
//读取文件内容,并去除数字标点符号
String fileContent = fileReader(file);
fileContent = fileContent.replaceAll("\\d+(?:[.,]\\d+)*\\s*", "");
String docName = file.getName();
Document doc = new Document();
doc.add(new Field("docContent", new StringReader(fileContent), Field.TermVector.YES));
doc.add(new Field("docName", new StringReader(docName), Field.TermVector.YES));
indexWriter.addDocument(doc);
}
indexWriter.close();
System.out.println("Add document successful.");
}TF-IDF算法实现
首先计算已有文档的TF-IDF
/**
* 获取所有文档的tf-idf值
* @return 结果
* @throws IOException IOException
* @throws ParseException ParseException
*/
public HashMap> getAllTFIDF() throws IOException, ParseException
{
HashMap> scoreMap = new HashMap>();
IndexReader re = IndexReader.open(NIOFSDirectory.open(new File(saveIndexPath)), true);
for (int k = 0; k < docNumbers; k++)
{
//每一个文档的tf-idf
Map wordMap = new HashMap();
//获取当前文档的内容
TermFreqVector termsFreq = re.getTermFreqVector(k, "docContent");
TermFreqVector termsFreqDocId = re.getTermFreqVector(k, "docName");
String docName = termsFreqDocId.getTerms()[0];
int[] freq = termsFreq.getTermFrequencies();
String[] terms = termsFreq.getTerms();
int noOfTerms = terms.length;
DefaultSimilarity simi = new DefaultSimilarity();
for (int i = 0; i < noOfTerms; i++)
{
int noOfDocsContainTerm = re.docFreq(new Term("docContent", terms[i]));
float tf = simi.tf(freq[i]);
float idf = simi.idf(noOfDocsContainTerm, docNumbers);
wordMap.put(terms[i], (tf * idf));
}
scoreMap.put(docName, wordMap);
}
return scoreMap;
} 接着输入一段测试文本,在已有的文本库中进行查找,使用上面同样的方法计算出待查找文本的TF-IDF,具体的代码就不在贴出来。
最后余弦相似度来找出最相似的文本。
/**
* 计算余弦相似度
* @param searchTextTfIdfMap 查找文本的向量
* @param allTfIdfMap 所有文本向量
* @return 计算出当前查询文本与所有文本的相似度
*/
private static Map cosineSimilarity(Map searchTextTfIdfMap,HashMap> allTfIdfMap)
{
//key是相似的文档名称,value是与当前文档的相似度
Map similarityMap = new HashMap();
//计算查找文本向量绝对值
double searchValue = 0;
for (Map.Entry entry : searchTextTfIdfMap.entrySet())
{
searchValue += entry.getValue() * entry.getValue();
}
for (Map.Entry> docEntry : allTfIdfMap.entrySet())
{
String docName = docEntry.getKey();
Map docScoreMap = docEntry.getValue();
double termValue = 0;
double acrossValue = 0;
for (Map.Entry termEntry : docScoreMap.entrySet())
{
if (searchTextTfIdfMap.get(termEntry.getKey()) != null)
{
acrossValue += termEntry.getValue() * searchTextTfIdfMap.get(termEntry.getKey());
}
termValue += termEntry.getValue() * termEntry.getValue();
}
similarityMap.put(docName,acrossValue/(termValue * searchValue));
}
return similarityMap;
} 最后测试效果还不错,可以找出最相近的文本。
源码下载
Github地址:https://github.com/HelloKittyNII/DocSimilarityAlgorithm