AKKA:大数据下的并发编程模型
在大数据如日中天的当今,开发中只会调用 API 是远远不够的,火热的 Spark、Flink 被越来越多的人掌握,这就驱使技术人员向技术中更深层次的知识去挖掘,今天我们就一起聊聊分布式计算和通信实现技术 AKKA,到底依靠哪些优势被 Spark 和 Flink 所使用。
在本场 Chat 中,一万多字中会讲到如下内容:
- Akka 介绍、Actor 模型入门
- Actor 工作机制、消息传递、应用实例
- Akka 网络编程:理论讲解
- Akka 网络编程:手敲代码
- Spark 使用 Akka 实现进程通讯
适合人群: 对 Akka 有兴趣及深入大数据技术的技术人员
1 Akka 介绍
Akka 是 JAVA 虚拟机 JVM 平台上构建高并发、分布式和容错应用的工具包和运行时,你可以理解成 Akka 是编写并发程序的框架。
Akka 用 Scala 语言写成,同时提供了 Scala 和 JAVA 的开发接口。
Akka 主要解决的问题是:可以轻松的写出高效稳定的并发程序,程序员不再过多的考虑线程、锁和资源竞争等细节。
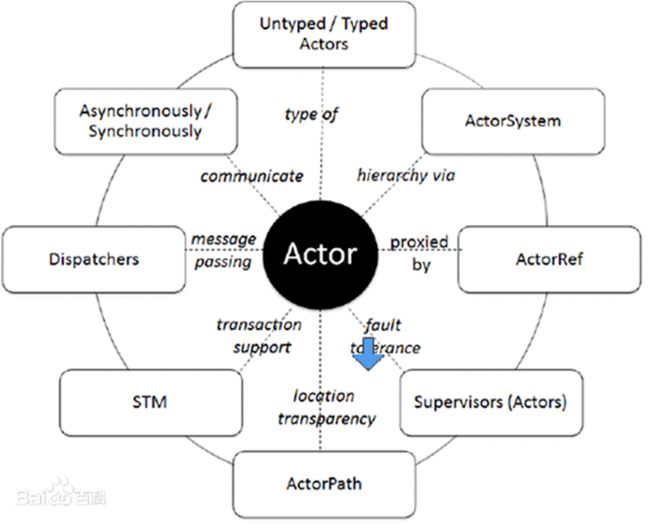
2 Akka 中 Actor(角色) 模型
处理并发问题关键是要保证共享数据的一致性和正确性,因为程序是多线程时,多个线程对同一个数据进行修改,若不加同步条件,势必会造成数据污染。但是当我们对关键代码加入同步条件 synchronized 后,实际上大并发就会阻塞在这段代码,对程序效率有很大影响。
若是用单线程处理,不会有数据一致性的问题,但是系统的性能又不能保证。
Actor 模型的出现解决了这个问题,简化并发编程,提升程序性能。 你可以这里理解:Actor 模型是一种处理并发问题的解决方案,很牛!
3 Akka 中 Actor 模型
 对上面的 Actor 模型做了说明和小结
对上面的 Actor 模型做了说明和小结
Akka 处理并发的方法基于 Actor 模型(示意图)
在基于 Actor 的系统里,所有的事物都是 Actor,就好像在面向对象设计里面所有的事物都是对象一样。
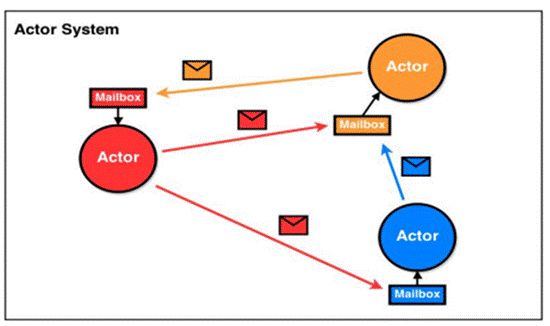
Actor 模型是作为一个并发模型设计和架构的。Actor 与 Actor 之间只能通过消息通信[消息的发送必须通过 ActorRef 发送],如图的信封
Actor 与 Actor 之间只能用消息进行通信,当一个 Actor 给另外一个 Actor 发消息,消息是有顺序的(消息队列),只需要将消息投寄的相应的邮箱即可
怎么处理消息是由接收消息的 Actor 决定的,发送消息 Actor 可以等待回复,也可以异步处理[ajax]
ActorSystem 的职责是负责创建并管理其创建的 Actor, ActorSystem 是单例的[工厂模式],一个 JVM 进程中有一个即可,而 Actor 是可以有多个的
Actor 模型是对并发模型进行了更高的抽象
Actor 模型是异步、非阻塞、高性能的事件驱动编程模型 [案例:说明什么是异步、非阻塞,最经典的案例就是 ajax 异步请求处理 ]
Actor 模型是轻量级事件处理(1GB 内存可容纳百万级别个 Actor),因此处理大并发性能高
4 Actor 模型工作机制说明
4.1 示意图
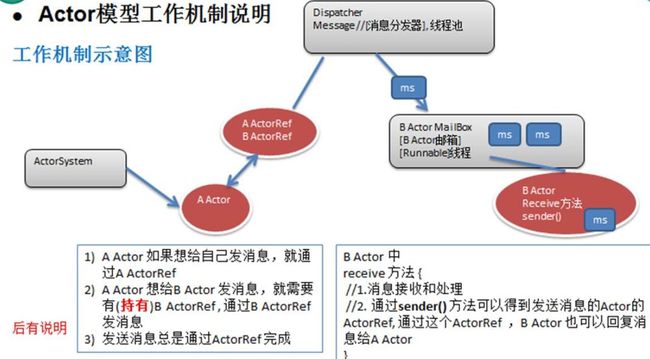
4.2 Actor 模型工作机制说明(对照工作机制示意图理解)
ActorySystem 创建 Actor
ActorRef:可以理解成是 Actor 的代理或者引用。消息是通过 ActorRef 来发送,而不能通过 Actor 发送消息,通过哪个 ActorRef 发消息,就表示把该消息发给哪个 Actor
消息发送到 Dispatcher Message (消息分发器),它得到消息后,会将消息进行分发到对应的 MailBox。(注: Dispatcher Message 可以理解成是一个线程池, MailBox 可以理解成是消息队列,可以缓冲多个消息,遵守 FIFO)
Actor 可以通过 receive 方法来获取消息,然后进行处理。
4.3 Actor 间传递消息机制(对照工作机制示意图理解)
每一个消息就是一个 Message 对象。Message 继承了 Runable, 因为 Message 就是线程类。
从 Actor 模型工作机制看上去很麻烦,但是程序员编程时只需要编写 Actor 就可以了,其它的交给 Actor 模型完成即可。
A Actor 要给 B Actor 发送消息,那么 A Actor 要先拿到(也称为持有) B Actor 的 代理对象 ActorRef 才能发送消息
5 Actor 模型快速入门
5.1 应用实例需求
编写一个 Actor,比如 SayHelloActor
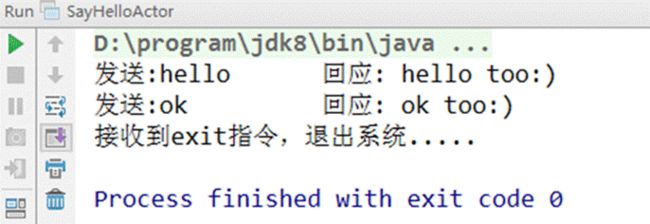
SayHelloActor 可以给自己发送消息,如图
要求使用 Maven 的方式来构建项目,这样可以很好的解决项目开发包的依赖关系。(AKKA 版本需要和 Scala 版本对应,使用 Maven 可以解决问题)
代码实现和说明
package com.test.akka.actorimport akka.actor.{Actor, ActorSystem, Props}class SayHelloActor extends Actor { //type Receive = PartialFunction[Any, Unit] override def receive: Receive = { case "start" => println("actor 开始运行...") case "hello" => println("hello too:)") case "fish" => println("<・)))><< 鱼") case "cat" => println("(>^ω^<)喵..") //如何让 actor 停止 case "exit" => { println("准备退出~~") context.stop(self) // 停止当前的 actor context.system.terminate() // 停止 ActorSystem. } }}object SayHelloActorDemo { def main(args: Array[String]): Unit = { //1 创建一个 ActorSystem val actorFactory = ActorSystem("actorFactory") //2.通过 actorFactory 创建需要的 actor //说明 //1. "SayHelloActor" 这个是 actor 的名字,有程序员指定. //2. Props[SayHelloActor] 是使用反射机制创建了 SayHelloActor 的实例 //3. sayHelloActorRef : 是创建的 SayHelloActor 的引用, 代理(proxy) val sayHelloActorRef = actorFactory.actorOf(Props[SayHelloActor],"SayHelloActor") sayHelloActorRef ! "start" sayHelloActorRef ! "hello" sayHelloActorRef ! "fish" sayHelloActorRef ! "cat" sayHelloActorRef ! "exit" }}5.2 对上面的代码进行小结和说明
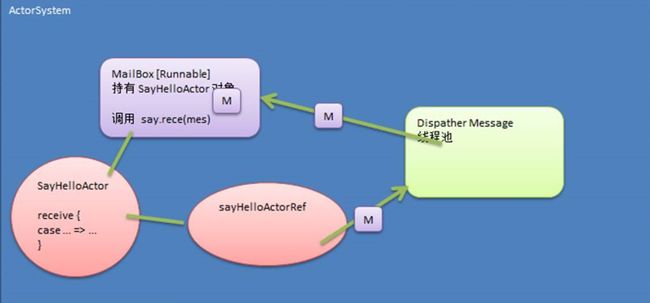
6 Actor 模型应用实例-- Actor 间通讯
6.1 应用实例需求
编写 2 个 Actor ,分别是 AActor 和 BActor
AActor 和 BActor 之间可以相互发送消息,

加强对 Actor 传递消息机制的理解
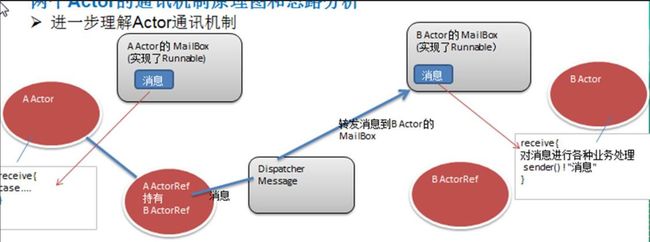
6.2 两个 Actor 的通讯机制原理图和思路分析
- 先编写 BActor,因为它会被 AActor 使用
- AActor 先出招,BActor 收到消息后,通过 sender() ! "消息"
6.3 代码实现

//AActor.scalapackage com.test.akka.actorsimport akka.actor.{Actor, ActorRef}//AActor 先出招class AActor(iBActorRef:ActorRef) extends Actor{ val bActorRef = iBActorRef var count = 0 override def receive: Receive = { case "start" => { println("AActor 启动") println("stark ok") println("我打") //发给 BActor bActorRef ! "我打" } case "我打" => { count += 1 println(s"AActor(黄飞鸿) 挺猛 看我佛山无影脚 第${count}脚") Thread.sleep(1000) bActorRef ! "我打" } }}//BActor.scalapackage com.test.akka.actorsimport akka.actor.Actorclass BActor extends Actor{ var count = 0 override def receive:Receive = { case "我打" => { count += 1 println(s"BActor(乔峰) 厉害 看我降龙十八掌 第${count}掌") Thread.sleep(1000) sender() ! "我打" } }}//ActorGame.scalapackage com.test.akka.actorsimport akka.actor.{ActorRef, ActorSystem, Props}object ActorGame extends App{ //1. ActorSystme val actorfactory = ActorSystem("actorfactory") val bActorRef: ActorRef = actorfactory.actorOf(Props[BActor],"BActor") val aActorRef: ActorRef = actorfactory.actorOf(Props(new AActor(bActorRef)), "AActor") //做一个要求:当 100 招,就退出.. aActorRef ! "start"}8 Akka 网络编程基本介绍
Akka 支持面向大并发后端服务程序,网络通信这块是服务端程序重要的一部分。
8.1 网络编程有两种:

TCP socket 编程,是网络编程的主流。之所以叫 Tcp socket 编程,是因为底层是基于 tcp/ip 协议 的. 比如: QQ 聊天
b/s 结构的 http 编程,我们使用浏览器去访问服务器时,使用的就是 http 协议,而 http 底层依旧是用 tcp socket 实现的。 比如: 京东商城 【属于 web 编程范畴,核心的协议是 http,底层是 tcp/ip 协议 (协议簇)】
8.2 OSI 与 tcp/ip 参考模型 (推荐 tcp/ip 协议 3 卷)
 推荐一部书,《tcp/ip 协议》和《Unix 高级编程》
推荐一部书,《tcp/ip 协议》和《Unix 高级编程》
8.3 ip 地址
概述:每个 internet 上的主机和路由器都有一个 ip 地址,它包括网络号和主机号,ip 地址有 ipv4(32 位) 或者 ipv6(128 位),可以通过 ipconfig 来查看。
8.4 端口 (port)--介绍
我们这里所指的端口不是指物理意义上的端口,而是特指 TCP/IP 协议中的端口,是逻辑意义上的端口。如果把 IP 地址比作一间房子,端口就是出入这间房子的门。真正的房子只有几个门,但是一个 IP 地址的端口 可以有 65535(即:256×256-1)个之多!端口是通过端口号来标记的。(端口号 0:保留 Reserved)
8.5 端口(port)--分类
0 号是保留端口
1-1024 是固定端口 [有名端口/ 名花有主 ],即被某些程序固定使用,一般程序员不使用。
22: SSH 远程登录协议 23: telnet 使用 21: ftp 使用 25: smtp 服务使用 80: iis 使用 7: echo 服务
1025-65535 是动态端口 [纯净版,关闭不需要端口,sshd [改一个] ]
这些端口,程序员可以使用 netstat -anb
8.6 端口(port)-使用注意
在计算机(尤其是做服务器)要尽可能的少开端口
一个端口只能被一个程序监听(80 但是一个端口可以连接多个客户端)
如果使用 netstat –an 可以查看本机有哪些端口在监听
可以使用 netstat –anb 来查看监听端口的 pid,在结合任务管理器关闭不安全的端口
8.7 网络拓扑
以下我们将 tcp socket 编程,简称 socket 编程。
下图为 socket 编程中客户端和服务器的网络分布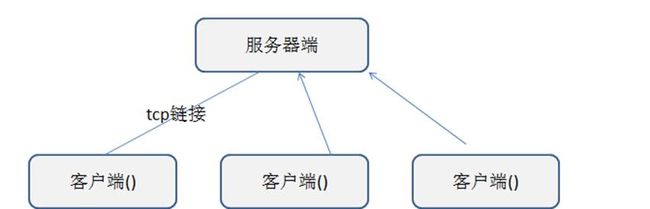
9 Akka 网络编程--小黄鸡客服
9.1 需求分析
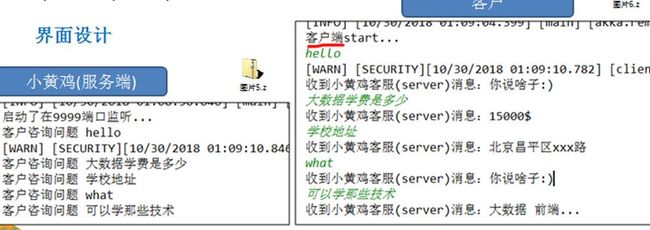
服务端进行监听(9999)
客户端可以通过键盘输入,发送咨询问题给小黄鸡客服(服务端)
小黄鸡(服务端) 回答客户的问题
9.2 界面设计
9.3 程序的框架图
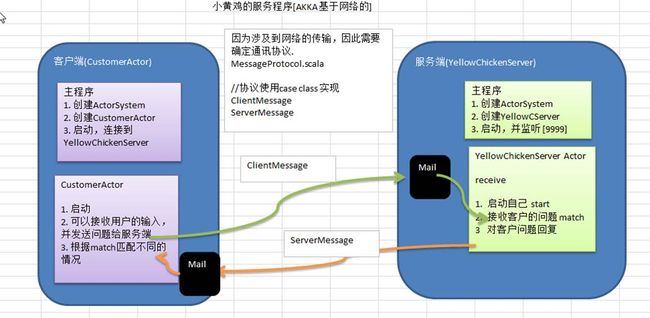
9.4 代码实现
MessageProtocol.scala
package com.test.akka.yellowchickenserver.common1. mes 会称为 样例类的只读属性//ClientMessage 客户端发送给服务器的协议数据(对象)case class ClientMessage(mes:String)//ServerMessage 服务端会送给客户端的协议数据(对象)case class ServerMessage(mes:String)YellowChickenServer.scala
package com.test.akka.yellowchickenserver.serverimport akka.actor.{Actor, ActorRef, ActorSystem, Props}import com.test.akka.yellowchickenserver.common.{ClientMessage, ServerMessage}import com.typesafe.config.ConfigFactoryclass YellowChickenServer extends Actor{ override def receive:Receive = { case "start" => { println("小黄 开始监听程序,可以咨询问题~~") } case ClientMessage(mes) => { //怎么匹配他的内容 println("客户咨询的问题是" + mes) mes match { case "大数据学费" => { sender() ! ServerMessage("20000RMB") } case "地址" => { sender() ! ServerMessage("北京昌平 XX 楼 111 号") } case "课程" => { sender() ! ServerMessage("JavaEE Python 前端 大数据") } case _ => { sender() ! ServerMessage("你说的啥子~~") } } } }}object YellowChickenServer extends App{ //创建 ActorSystem //因为这时,我们需要监听网络,所以使用如下方法创建工厂 //Config 就是我们的网络配置 ip , port.. //def apply(name: String, config: Config): ActorSystem = apply(name, Option(config), None, None) val host = "127.0.0.1" //ip4 val port = 9999 //Config 就是我们的网络配置 ip , port.. // val config = ConfigFactory.parseString( s""" |akka.actor.provider="akka.remote.RemoteActorRefProvider" |akka.remote.netty.tcp.hostname=$host |akka.remote.netty.tcp.port=$port """.stripMargin) val serverActorSystem = ActorSystem("Server",config) val yellowChickenServerRef: ActorRef = serverActorSystem.actorOf(Props[YellowChickenServer],"YellowChickenServer") //akka.tcp://[email protected]:9999 就是 Actor 路径 yellowChickenServerRef ! "start"}CustomerActor.scala
package com.test.akka.yellowchickenserver.clientimport akka.actor.{Actor, ActorRef, ActorSelection, ActorSystem, Props}import com.test.akka.yellowchickenserver.common.{ClientMessage, ServerMessage}import com.typesafe.config.ConfigFactoryimport scala.io.StdInclass CustomerActor extends Actor { //我们这里需要持有 Server 的 Ref var yellowChickenServerRef: ActorSelection = _ //preStart , 在启动 Actor 之前会先运行,因此变量,初始化写入 preStart override def preStart(): Unit = { //println("preStart") //说明 //1. 在 AKKA 的 Actor 模型中, 认为 每个 Actor 都是一个资源(角色),通过一个 Path 来定位一个 actor //2. path 的组成 akka.tcp://Server 的 actorfactory 名字@ServerIp:Server 的 port/user/ServerActor 名字 yellowChickenServerRef = context.actorSelection("akka.tcp://[email protected]:9999/user/YellowChickenServer") } override def receive: Receive = { case "start" => { println("客户端启动,可以咨询问题~~") } case mes: String => { //将 mes 发送给 Server yellowChickenServerRef ! ClientMessage(mes) } case ServerMessage(mes) => { println("收到小黄鸡客服回复的消息: " + mes) } }}object CustomerActor extends App { //编写必要的配置信息 val serverHost = "127.0.0.1" val serverPort = 9999 val clientHost = "127.0.0.1" val clientPort = 10000 val config = ConfigFactory.parseString( s""" |akka.actor.provider="akka.remote.RemoteActorRefProvider" |akka.remote.netty.tcp.hostname=$clientHost |akka.remote.netty.tcp.port=$clientPort """.stripMargin) //创建 CustomerActor val clientActorSystem = ActorSystem("Client", config) val customerActorRef: ActorRef = clientActorSystem.actorOf(Props[CustomerActor], "CustomerActor") customerActorRef ! "start" println("可以咨询问题了") while (true) { val mes = StdIn.readLine() customerActorRef ! mes //先发给自己,然后让 CustomerActor 发 }}10 Spark Master Worker 进程通讯项目
10.1 项目意义
深入理解 Spark 的 Master 和 Worker 的通讯机制
为了方便同学们看 Spark 的底层源码,命名的方式和源码保持一致。(如:通讯消息类命名就是一样的)
加深对主从服务心跳检测机制(HeartBeat)的理解,方便以后 Spark 源码二次开发。
10.2 项目需求分析
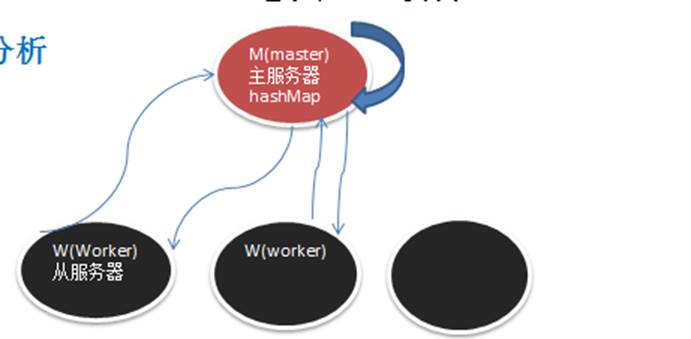
worker 注册到 Master,Master 完成注册,并回复 worker 注册成功(注册功能)
worker 定时发送心跳(3),并在 Master 接收到
Master 接收到 worker 心跳后,要更新该 worker 的最近一次发送心跳的时间
给 Master 启动定时任务,定时检测注册的 worker 有哪些没有更新心跳,并将其从 hashmap 中删除
master worker 进行分布式部署(Linux 系统)->如何给 maven 项目打包->上传 linux 并运行
10.3 实现功能 1-Worker 完成注册
功能说明
worker 注册到 Master,Master 完成注册,并回复 worker 注册成功
思路分析
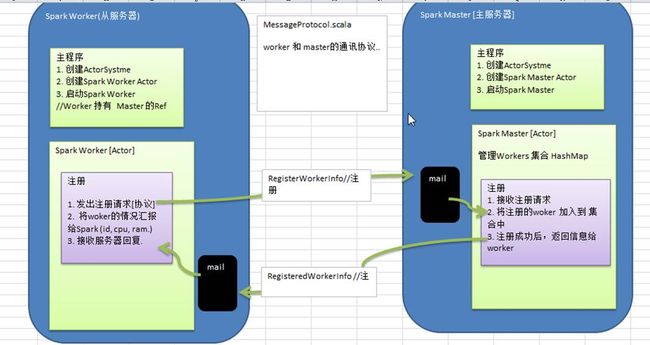
代码实现
//MessageProtocol.scalapackage com.test.akka.sparkmasterworker.common//样例类, 注册的协议,包含 id ,cpu, ram(内存)case class RegisterWorkerInfo(id: String, cpu: Int, ram: Int)//WorkerInfo 是用于保存 worker 信息的对象, 它不在网络传输,他是普通类//后面会加入扩展内容,比如心跳时间class WorkerInfo(val id: String, val cpu: Int, val ram: Int) { //默认的心跳时间 var lastHeartBeatTime:Long = System.currentTimeMillis()}//如果注册成功后,返回的协议信息,因为不需要属性,因此我直接使用的 case object//后面直接返回的是 RegisteredWorkerInfo 对象: 类型 RegisteredWorkerInfo$case object RegisteredWorkerInfo//SparkMaster.scalapackage com.test.akka.sparkmasterworker.masterimport akka.actor.{Actor, ActorRef, ActorSystem, Props}import com.test.akka.sparkmasterworker.common.{RegisterWorkerInfo, RegisteredWorkerInfo, WorkerInfo}import com.typesafe.config.ConfigFactoryimport scala.collection.mutableclass SparkMaster extends Actor { //定义一个 hashMap,存放所有的 workers 信息 val workers = mutable.HashMap[String, WorkerInfo]() override def receive = { case "start" => { println("spark master 启动,在 10000 监听..") } case RegisterWorkerInfo(id, cpu, ram) => { //注册 //先判断是否已经有 id if (!workers.contains(id)) { //创建 WorkerInfo val workerInfo = new WorkerInfo(id, cpu, ram) workers += (id -> workerInfo) //workers += ((id,workerInfo)) //回复成功! sender() ! RegisteredWorkerInfo println(s"workerid= $id 完成注册~") } } }}object SparkMaster extends App { val masterHost = "127.0.0.1" val masterPort = 10000 val config = ConfigFactory.parseString( s""" |akka.actor.provider="akka.remote.RemoteActorRefProvider" |akka.remote.netty.tcp.hostname=$masterHost |akka.remote.netty.tcp.port=$masterPort """.stripMargin) //创建 ActorSystem // "SparkMaster" actorFactory 名字,程序指定 val sparkMasterActorSystem = ActorSystem("SparkMaster", config) //创建 SparkMaster 和 引用 val sparkMaster01Ref: ActorRef = sparkMasterActorSystem.actorOf(Props[SparkMaster], "SparkMaster01") sparkMaster01Ref ! "start"}//SparkWorker.scalapackage com.test.akka.sparkmasterworker.workerimport java.util.UUIDimport akka.actor.{Actor, ActorRef, ActorSelection, ActorSystem, Props}import com.test.akka.sparkmasterworker.common.{RegisterWorkerInfo, RegisteredWorkerInfo}import com.test.akka.sparkmasterworker.master.SparkMaster.{masterHost, masterPort}import com.typesafe.config.ConfigFactoryclass SparkWorker(masterHost:String,masterPort:Int) extends Actor{ var masterProxy: ActorSelection = _ val id = UUID.randomUUID().toString override def preStart(): Unit = { masterProxy = context.actorSelection(s"akka.tcp://SparkMaster@${masterHost}:${masterPort}/user/SparkMaster01") } override def receive = { case "start" => { println("spark worker 启动..") //发出注册的请求 masterProxy ! RegisterWorkerInfo(id, 8, 8 * 1024) } case RegisteredWorkerInfo => { println(s"收到 master 回复消息 workerid= $id 注册成功") } }}object SparkWorker extends App{ val (masterHost,masterPort,workerHost,workerPort) = ("127.0.0.1",10000,"127.0.0.1",10001) val config = ConfigFactory.parseString( s""" |akka.actor.provider="akka.remote.RemoteActorRefProvider" |akka.remote.netty.tcp.hostname=$workerHost |akka.remote.netty.tcp.port=$workerPort """.stripMargin) val sparkWorkerActorSystem = ActorSystem("SparkWorker",config) val sparkWorkerActorRef: ActorRef = sparkWorkerActorSystem.actorOf(Props(new SparkWorker(masterHost, masterPort)), "SparkWorker-01") sparkWorkerActorRef ! "start"}10.4 实现功能 2-Worker 定时发送心跳
功能说明
worker 定时发送心跳给 Master,Master 能够接收到,并更新 worker 上一次心跳时间
代码实现
//MessageProtocol.scala//worker 在注册成功后,通过定时器,每隔 3s 发送一个消息给自己//SendHeartBeatcase object SendHeartBeat//当定时器发送了一个 SendHeartBeat 消息后,worker 发送一个消息// (HearBeat(id: String))给 Mastercase class HeartBeat(id: String)//SparkWorker.scalaoverride def receive = { case "start" => { println("spark worker 启动..") //发出注册的请求 masterProxy ! RegisterWorkerInfo(id, 8, 8 * 1024) } case RegisteredWorkerInfo => { println(s"收到 master 回复消息 workerid= $id 注册成功") //启动一个定时器. import context.dispatcher //说明 //1.schedule 创建一个定时器 //2.0 millis, 延时多久才执行, 0 表示不延时,立即执行 //3. 3000 millis 表示每隔多长时间执行 3 秒 //4. self 给自己发送 消息 //5. SendHeartBeat 消息 context.system.scheduler.schedule(0 millis, 3000 millis, self, SendHeartBeat) } case SendHeartBeat => { println(s"workerid= $id 发出心跳~") masterProxy ! HeartBeat(id) } }//SparkMaster.scalacase HeartBeat(id) => { //更新 id 对应的 worker 的心跳 if (workers.contains(id)) { workers(id).lastHeartBeatTime = System.currentTimeMillis() println(s"workerid=$id 更新心跳成功~") } }10.5 实现功能 3-Master 启动定时任务,定时检测注册的 worker
功能说明
功能要求:Master 启动定时任务(10秒),定时检测注册的 worker 有哪些没有更新心跳,已经超时的 worker(6 秒),将其从 hashmap 中删除掉
思路分析
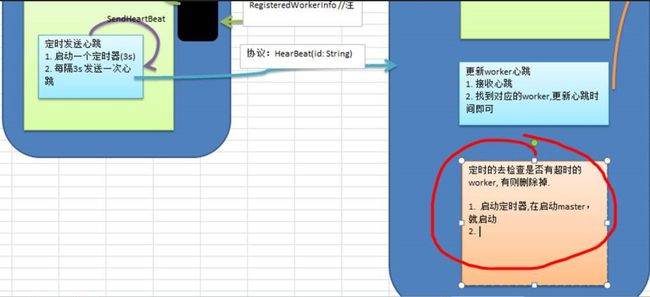
代码实现
//SparkMaster.scalaoverride def receive = { case "start" => { println("spark master 启动,在 10000 监听..") self ! StartTimeOutWorker } case RegisterWorkerInfo(id, cpu, ram) => { //注册 //先判断是否已经有 id if (!workers.contains(id)) { //创建 WorkerInfo val workerInfo = new WorkerInfo(id, cpu, ram) workers += (id -> workerInfo) //workers += ((id,workerInfo)) //回复成功! sender() ! RegisteredWorkerInfo println(s"workerid= $id 完成注册~") } } case HeartBeat(id) => { //更新 id 对应的 worker 的心跳 if (workers.contains(id)) { workers(id).lastHeartBeatTime = System.currentTimeMillis() println(s"workerid=$id 更新心跳成功~") } } case StartTimeOutWorker =>{ //启动定时器 import context.dispatcher context.system.scheduler.schedule(0 millis, 10000 millis, self, RemoveTimeOutWorker) } case RemoveTimeOutWorker => { //定时清理超时 6s 的 worker,scala //获取当前的时间 val currentTime = System.currentTimeMillis() val workersInfo = workers.values //获取到所有注册的 worker 信息 //先将超时的一次性过滤出来,然后对过滤到的集合一次性删除 workersInfo.filter( currentTime - _.lastHeartBeatTime > 6000 ).foreach(workerInfo=>{ workers.remove(workerInfo.id) }) printf("当前有%d 个 worker 存活\n", workers.size) } }10.6 实现功能 4-Master,Worker 的启动参数运行时指定
功能说明
功能要求:Master,Worker 的启动参数运行时指定,而不是固定写在程序中的
代码实现
object SparkMaster extends App { //要求启动时,我们从外部输入三个参数 if (args.length != 3) { println("启动参数不正确 ") } val masterHost = args(0) val masterPort = args(1) val masterName = args(2) //SparkWorker.scala if (args.length != 6) { println("参数格式不正确 ") } val (masterHost,masterPort,masterName,workerHost,workerPort,workerName) = (args(0),args(1),args(2),args(3),args(4),args(5)) 10.7 对开发的 SparkMaster 和 SparkWorker 打包.jar , 部署到不同的 Linux 服务器,并运行
我这里直接在 windows 演示,同学们可以上传到自己的 3 台 linux 并并行
打包的步骤
修改 pom.xml 指定主类
com.test.akka.sparkmasterworker.master.SparkMaster
出 maven 的打包的界面
找到 lifecycle,双击 package 即可
打包后,到 target 去找 jar 即可
给 SparkWorker 打包的流程和前面完全一样,但是需要先 clean
测试和指令
 java -jar SparkWorker.java 127.0.0.1 10000 SparkMaster01 127.0.0.1 10001 SparkWorker01
java -jar SparkWorker.java 127.0.0.1 10000 SparkMaster01 127.0.0.1 10001 SparkWorker01
阅读全文: http://gitbook.cn/gitchat/activity/5de88c119a74cc327f167a48
您还可以下载 CSDN 旗下精品原创内容社区 GitChat App ,阅读更多 GitChat 专享技术内容哦。
