在计算机设计之初,对内存中数据的处理也有不同的方式,(低位数据存储在低位地址处或者高位数据存储在低位地址处),然而,在通信的过程中(ISO/OSI模型和TCP/IP四层模型中),数据被一步步封装(然后加入信息首部),当传到目的段时,被一步步解封,然后获取数据。
从上面我们可以看出,数据在传输的过程中,一定有一个标准化的过程,也就是说:从主机a到主机b进行通信,
a的固有数据存储-------标准化--------转化成b的固有格式
如上而言:a或者b的固有数据存储格式就是自己的主机字节序,上面的标准化就是网络字节序(也就是大端字节序)
a的主机字节序----------网络字节序 ---------b的主机字节序
主机字节序:
就是自己的主机内部,内存中数据的处理方式,可以分为两种:
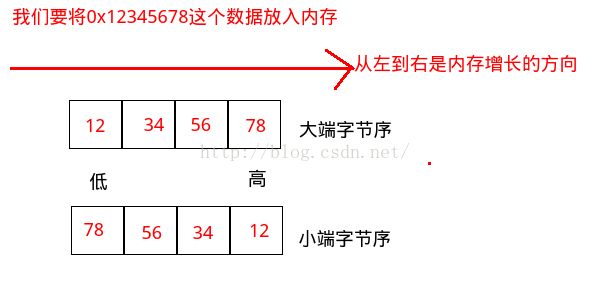
大端字节序(big-endian):按照内存的增长方向,高位数据存储于低位内存中
小端字节序(little-endian):按照内存的增长方向,高位数据存储于高位内存中
我们可以通过程序来验证一下我们的主机是大端字节序还是小端字节序:
1 #include2 3 int main() { 4 5 unsigned long a = 0x12345678; 6 unsigned char *p = (unsigned char *)(&a); 7 printf("主机字节序:%0x %0x %0x %0x\n", p[0], p[1], p[2], p[3]); 8 unsigned long b = htonl(a); //将主机字节序转化成了网络字节序 9 p = (unsigned char *)(&b); 10 printf("网络字节序:%0x %0x %0x %0x\n", p[0], p[1], p[2], p[3]); 11 return 0; 12 }
输出:
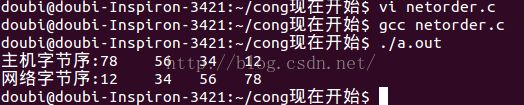
得出的结论是主机位小端字节序。
网络字节序:
网络字节序是TCP/IP中规定好的一种数据表示格式,它与具体的CPU类型、操作系统等无关,从而可以保证数据在不同主机之间传输时能够被正确解释。网络字节顺序采用big endian(大端)排序方式。
网络字节序和主机字节序之间的转换:
htons把unsigned short类型从主机序转换到网络序
htonl 把unsigned long类型从主机序转换到网络序
ntohs 把unsigned short类型从网络序转换到主机序
ntohl 把unsigned long类型从网络序转换到主机序
ip地址转换函数:
inet_pton是一个IP地址转换函数,可以在将IP地址在“点分十进制”和“二进制整数”之间转换而且,inet_pton和inet_ntop这2个函数能够处理ipv4和ipv6。算是比较新的函数了。(将本地字节序的点分十进制的ip地址转换为网络字节序的二进制的ip地址)