HDFS编程实践
目录:
前提
在VMware中查找虚拟机的IP地址
启动putty
启动Hadoop
登陆HDFS的Web界面
步骤
1、向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件(第一种实现方式)
2、向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件(第二种实现方式)
3、从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名
4、将HDFS中指定文件的内容输出到终端中
5、显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息
6、给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息
7、提供一个HDFS内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录
8、提供一个HDFS的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目录文件所在目录不存在则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否还删除该目录
9、向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的结尾
10、向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头(由于没有直接的命令可以操作,方法之一是先移动到本地进行操作,再进行上传覆盖)
11、删除HDFS中指定的文件
12、删除HDFS中指定的目录,由用户指定目录中如果存在文件时是否删除目录
13、在HDFS中,将文件从源路径移动到目的路径
14、编程实现一个类“MyFSDataInputStream”,该类继承“org.apache.hadoop.fs.FSDataInputStream”,要求如下:实现按行读取HDFS中指定文件的方法“readLine()”,如果读到文件末尾,则返回空,否则返回文件一行的文本。
参考文章
前提:
在VMware中查找虚拟机的IP地址
ifconfig -a //查找虚拟机的IP地址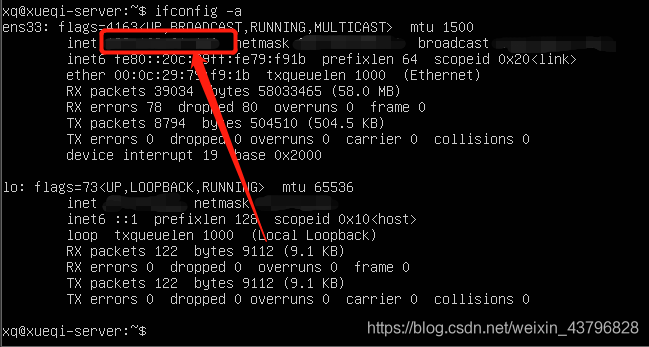
启动putty
启动Hadoop
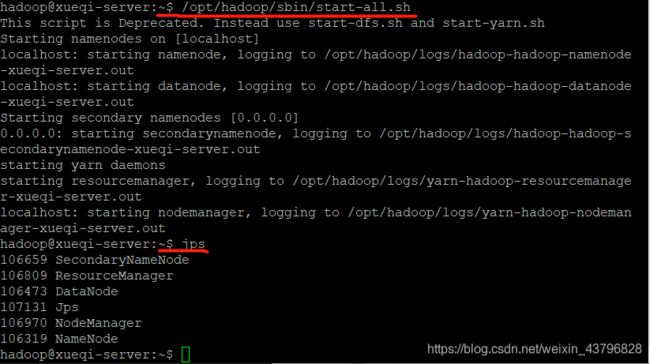
/opt/hadoop/sbin/start-all.sh //启动所有进程
jps //查看进程结果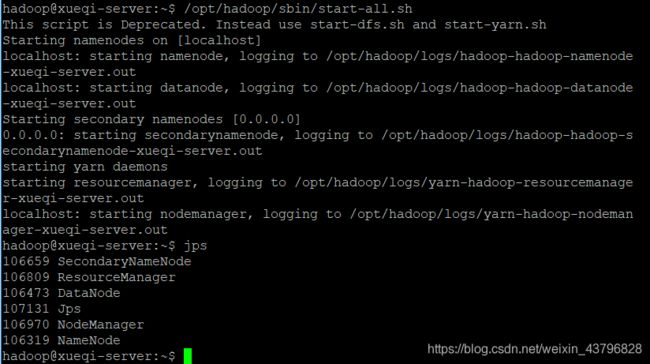
登陆HDFS的Web界面
http://192.164.85.124:50070 //“192.164.85.124”为“ifconfig-a”命令得到的虚拟机IP地址步骤:
1、向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件(第一种实现方式)
cd //首先回到主目录
ls //查看主目录下的文件
/opt/hadoop/bin/hadoop fs -ls //查看下HDFS下的文件
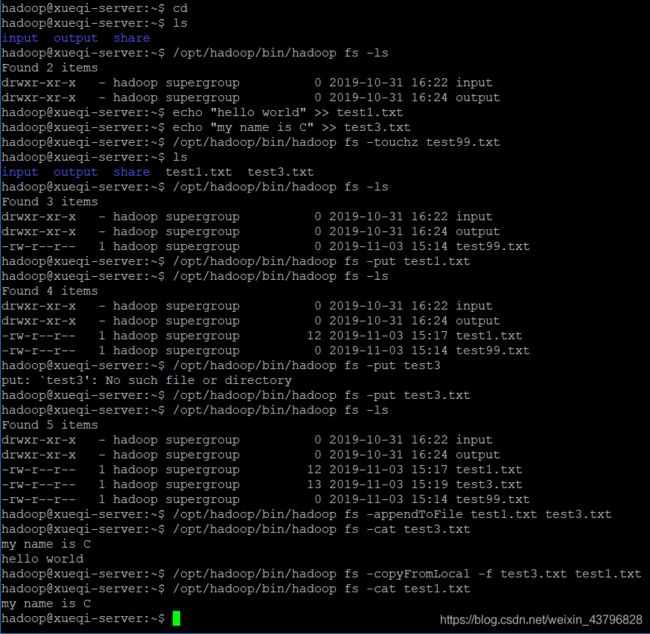
echo "hello world" >> test1.txt //在主目录下创建一个文本内容为“hello world”的test1.txt
echo "my name is C" >> test3.txt //在主目录下创建一个文本内容为“hello world”的test3.txt
/opt/hadoop/bin/hadoop fs -touchz test99.txt //在HDFS创建一个test99.txt的空文本文件
ls
/opt/hadoop/bin/hadoop fs -ls //查看下HDFS下的文件,看看是否创建成功
/opt/hadoop/bin/hadoop fs -put test1.txt //将本地的test1.txt上传到HDFS
/opt/hadoop/bin/hadoop fs -ls //查看下HDFS下的文件,看看是否上传成功
/opt/hadoop/bin/hadoop fs -put test3.txt //将本地的test3.txt上传到HDFS
/opt/hadoop/bin/hadoop fs -ls //查看下HDFS下的文件,看看是否上传成功
/opt/hadoop/bin/hadoop fs -appendToFile test1.txt test3.txt //将test1.txt追加到test3.txt
/opt/hadoop/bin/hadoop fs -cat test3.txt /查看下HDFS下的test3.txt文件,看看是否追加成功
/opt/hadoop/bin/hadoop fs -copyFromLocal -f test3.txt test1.txt //-f:强制的意思,如果没有,会报错“file exits”;用test3.txt的内容覆盖掉test1.txt的内容
/opt/hadoop/bin/hadoop fs -cat test1.txt /查看下HDFS下的test3.txt文件,看看是否覆盖成功
2、向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件(第二种实现方式)
if $(/opt/hadoop/bin/hadoop fs -test -e test1.txt); //判断HDFS中是否存在“test1.txt”
then $(/opt/hadoop/bin/hadoop fs -appendToFile test3.txt test1.txt); //若存在,则将本地的test3.txt追加到test1.txt文件的末尾。因为不存在,所以在HDFS中会新生成一个test1.txt,内容为追加后的内容
else $(/opt/hadoop/bin/hadoop fs -copyFromLocal -f test3.txt test1.txt); //-f:强制。若不存在,则用test3.txt的内容覆盖test1.txt的内容
fi
/opt/hadoop/bin/hadoop fs -cat test1.txt //这一步查看HDFS中test1的内容,意在验证test1.txt为追加后的内容
/opt/hadoop/bin/hadoop fs -rm test1.txt //删除test1.txt
/opt/hadoop/bin/hadoop fs -ls //查看是否删除
if $(/opt/hadoop/bin/hadoop fs -test -e test1.txt); //判断HDFS是否存在。。。
then $(/opt/hadoop/bin/hadoop fs -appendToFile test3.txt test1.txt); //存在,则。。。
else $(/opt/hadoop/bin/hadoop fs -copyFromLocal -f test3.txt test1.txt); //不存在,则。。。
fi
/opt/hadoop/bin/hadoop fs -cat test1.txt //意在验证test1.txt的内容是否为“my name is C”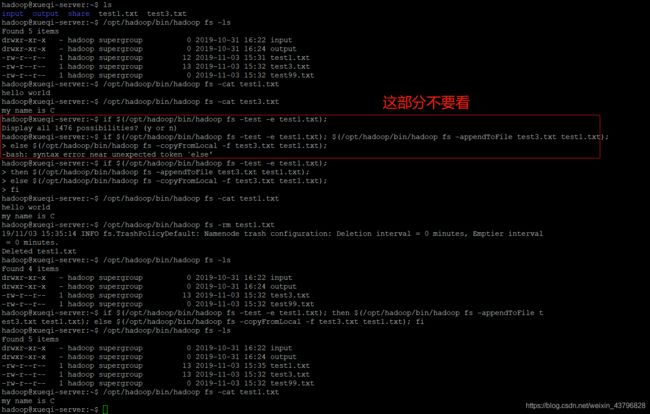
3、从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名
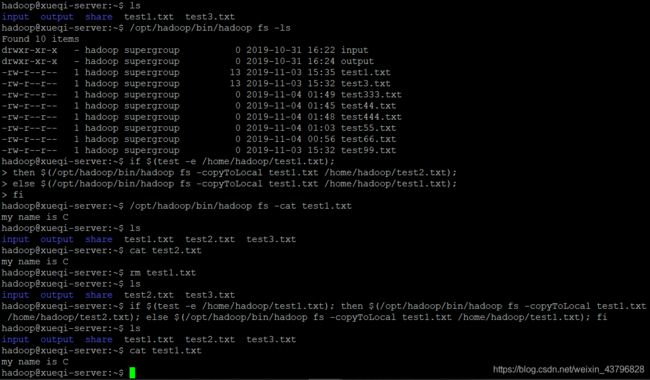
ls //查看本地文件
/opt/hadoop/bin/hadoop fs -ls //查看HDFS文件
if $(test -e /home/hadoop/test1.txt); //判断本地是否存在test1.txt
then $(/opt/hadoop/bin/hadoop fs -copyToLocal test1.txt /home/hadoop/test2.txt); //若存在,则将HDFS中的test1.txt复制为本地的test2.txt
else $(/opt/hadoop/bin/hadoop fs -copyToLocal test1.txt /home/hadoop/test1.txt); //若不存在,则将HDFS中的test1.txt复制为本地的test1.txt
fi
/opt/hadoop/bin/hadoop fs -cat test1.txt //查看HDFS中test1.txt内容
ls //查看本地文件
cat test2.txt //查看本地的test2.txt内容
rm test1.txt //删除本地的test1.txt
ls //查看本地文件,判断是否删除成功
if $(test -e /home/hadoop/test1.txt); //现在本地不存在test1.txt,预计执行的是else后续语句
then $(/opt/hadoop/bin/hadoop fs -copyToLocal test1.txt /home/hadoop/test2.txt);
else $(/opt/hadoop/bin/hadoop fs -copyToLocal test1.txt /home/hadoop/test1.txt);
fi
cat test1.txt //查看本地test1.txt的内容
4、将HDFS中指定文件的内容输出到终端中
/opt/hadoop/bin/hadoop fs -ls //查看HDFS中有哪些文件
/opt/hadoop/bin/hadoop fs -cat test1.txt //选择其中一个文件,输出其内容到终端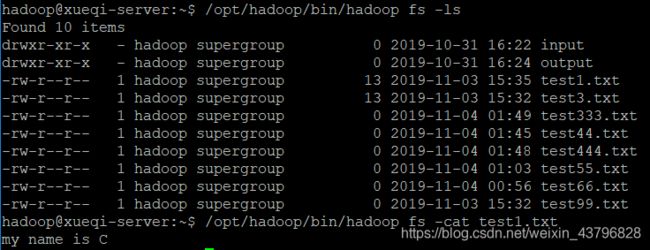
5、显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息
/opt/hadoop/bin/hadoop fs -ls //查看HDFS中有哪些文件
/opt/hadoop/bin/hadoop fs -ls -h test1.txt //显示指定文件的读写权限、大小、创建时间、路径等信息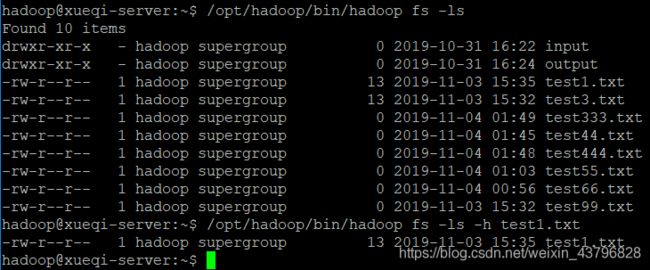
6、给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息
/opt/hadoop/bin/hadoop fs -ls -h /user/hadoop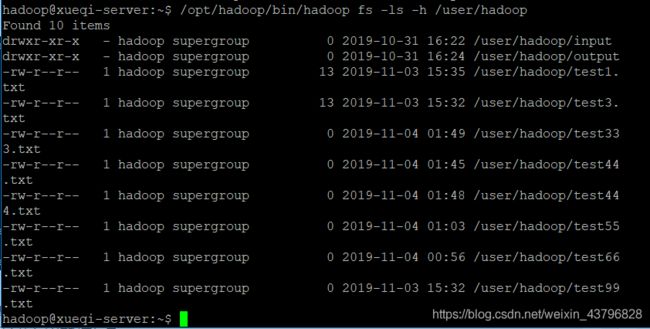
7、提供一个HDFS内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录
if $(/opt/hadoop/bin/hadoop fs -test -d /user/hadoop/test); //查看是否存在test目录
then $(/opt/hadoop/bin/hadoop fs -touchz /user/hadoop/test/test8888.txt ); //若存在,则在test目录下创建一个test8888.txt
else $(/opt/hadoop/bin/hadoop fs -mkdir -p /user/hadoop/test && /opt/hadoop/bin/hadoop fs -touchz /user/hadoop/test/test8888.txt); //若不存在,则先创建该目录,再到该目录下创建test888.txt
fi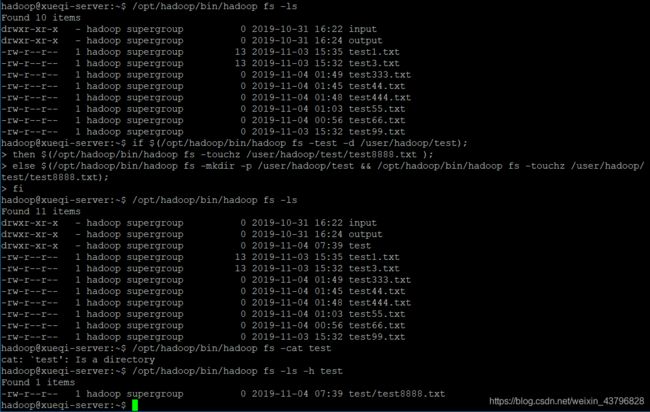
8、提供一个HDFS的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目录文件所在目录不存在则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否还删除该目录
/opt/hadoop/bin/hadoop fs -ls //查看HDFS中的文件
if $(/opt/hadoop/bin/hadoop fs -test -e /user/hadoop/test100); //HDFS是否存在这个目录
then $();
else $(/opt/hadoop/bin/hadoop fs -mkdir -p /user/hadoop/test100); //没有就自己建一个
fi
/opt/hadoop/bin/hadoop fs -ls //查看HDFS中的文件
if $(/opt/hadoop/bin/hadoop fs -test -e /user/hadoop/test100); //HDFS是否存在这个目录
then $(/opt/hadoop/bin/hadoop fs -rm -r /user/hadoop/test100); //存在就删除这个目录
fi
/opt/hadoop/bin/hadoop fs -ls //查看HDFS中的文件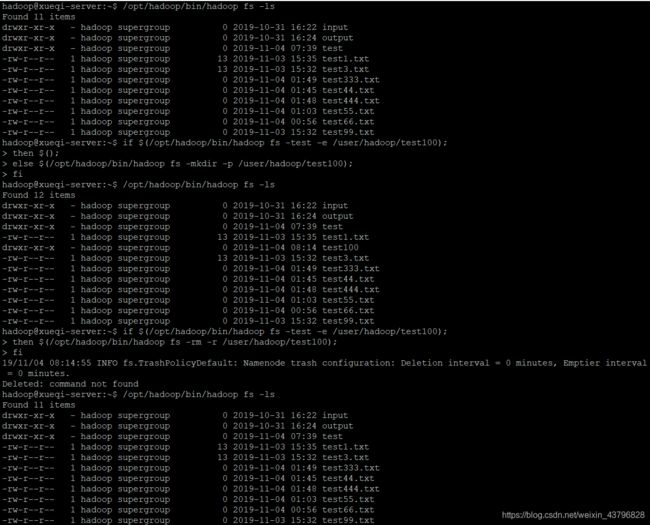
9、向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的结尾
/opt/hadoop/bin/hadoop fs -ls //查看HDFS的文件
ls //查看本地文件
/opt/hadoop/bin/hadoop fs -cat test1.txt //查看HDFS中的test1.txt
cat test3.txt //查看本地的test3.txt
/opt/hadoop/bin/hadoop fs -appendToFile test3.txt test1.txt //将本地文件test3.txt的内容追加到HDFS中的test1.txt中
/opt/hadoop/bin/hadoop fs -cat test1.txt //查看HDFS中的test1.txt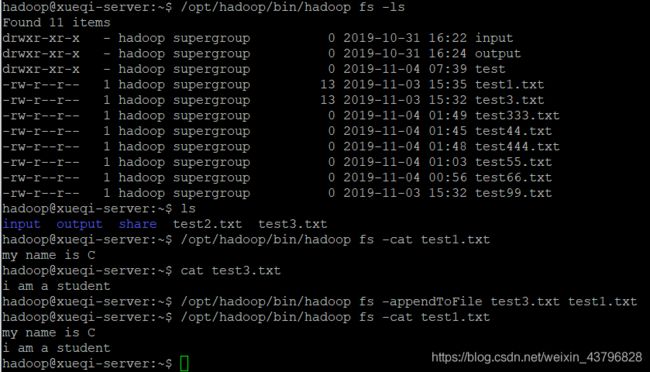
10、向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头
(由于没有直接的命令可以操作,方法之一是先移动到本地进行操作,再进行上传覆盖)
ls //查看本地主目录
/opt/hadoop/bin/hadoop fs -ls //查看HDFS文件
cat test3.txt //查看本地的test3.txt
/opt/hadoop/bin/hadoop fs -cat test1.txt //查看HDFS的test1.txt
/opt/hadoop/bin/hadoop fs -get test1.txt //下载HDFS的test1.txt到当前目录
cat test1.txt >> test3.txt //将test1.txt内容追加到test3.txt
/opt/hadoop/bin/hadoop fs -copyFromLocal -f test3.txt test1.txt //将test3.txt上传覆盖掉test1.txt
/opt/hadoop/bin/hadoop fs -ls //查看HDFS的文件
/opt/hadoop/bin/hadoop fs -cat test1.txt //查看HDFS中的test1.txt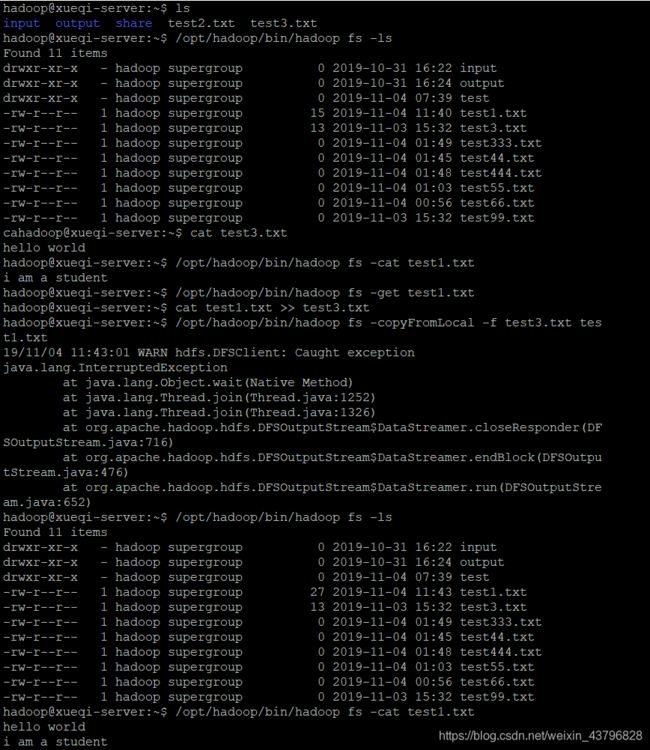
11、删除HDFS中指定的文件
/opt/hadoop/bin/hadoop fs -ls
/opt/hadoop/bin/hadoop fs -rm test55.txt 删除test55.txt
/opt/hadoop/bin/hadoop fs -ls
【文件夹可以使用rm -r来删除】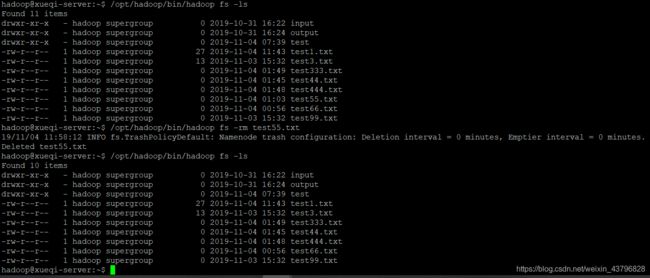
12、删除HDFS中指定的目录,由用户指定目录中如果存在文件时是否删除目录
/opt/hadoop/bin/hadoop fs -ls
/opt/hadoop/bin/hadoop fs -rmdir /user/hadoop/test5 //删除空目录“test5”
/opt/hadoop/bin/hadoop fs -ls
/opt/hadoop/bin/hadoop fs -rmdir /user/hadoop/test //删除非空目录“test”,这一步会提示“not empty”
/opt/hadoop/bin/hadoop fs -rm -r /user/hadoop/test //强制删除目录
/opt/hadoop/bin/hadoop fs -ls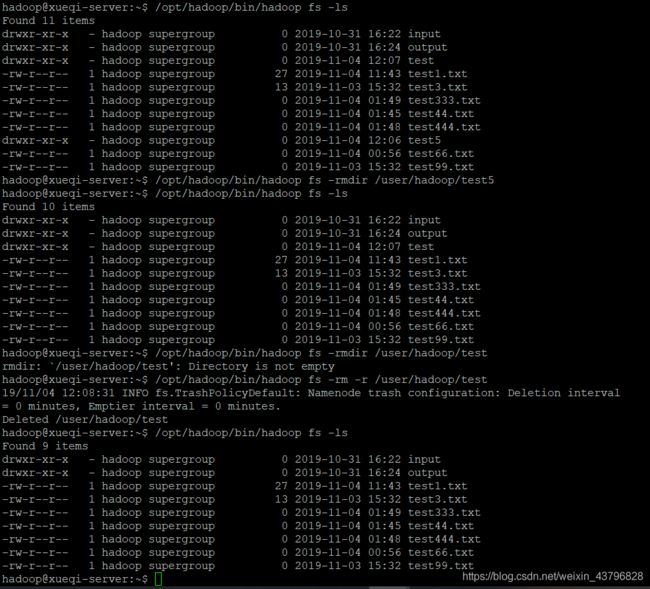
13、在HDFS中,将文件从源路径移动到目的路径
/opt/hadoop/bin/hadoop fs -mv test1.txt /user/hadoop/input/test2.txt //将HDFS上的test1.txt移动到input目录里并更名为“test2.txt”【test1.txt等价于/user/hadoop/test1.txt,似乎叫作“相对路径”】
/opt/hadoop/bin/hadoop fs -ls //查看HDFS的文件【也即/user/hadoop下的文件】
/opt/hadoop/bin/hadoop fs -ls -h /user/hadoop/input //看看input目录下是否存在test2.txt
/opt/hadoop/bin/hadoop fs -cat /user/hadoop/input/test2.txt //查看input目录下test2.txt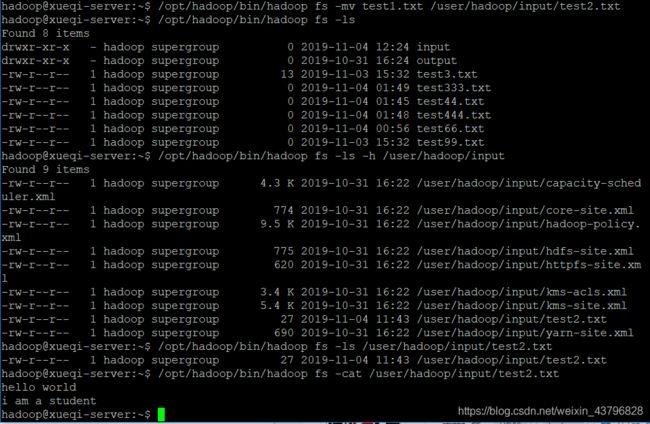
14、编程实现一个类“MyFSDataInputStream”,该类继承“org.apache.hadoop.fs.FSDataInputStream”,要求如下:实现按行读取HDFS中指定文件的方法“readLine()”,如果读到文件末尾,则返回空,否则返回文件一行的文本。
MyFSDataInputStream类代码如下,“Path file = new Path("test3");” 这一行代码很关键,在HDFS中寻找“test3”这个文件
import java.io.BufferedReader;
import java.io.InputStreamReader;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class MyFSDataInputStream
{
public static void main(String[] args)
{
try
{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
Path file = new Path("test3"); //这一行代码很关键,在HDFS中寻找“test3”这个文件
FSDataInputStream in = fs.open(file);
BufferedReader d = new BufferedReader(new InputStreamReader(in));
String content = d.readLine();
while(content!=null) //一行循环一次,然后输出内容,到最后一行输出完就停止
{
System.out.println(content);
content = d.readLine();
}
d.close();
fs.close();
}
catch (Exception e)
{
e.printStackTrace();
}
}
}cd /share
ls
/opt/hadoop/bin/hadoop fs -ls
vim test3 //从ls的结果知本地没有test3,所以会默认创建一个,test3就是上述代码在寻找的东西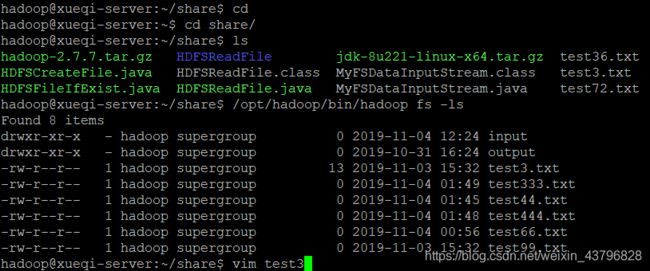
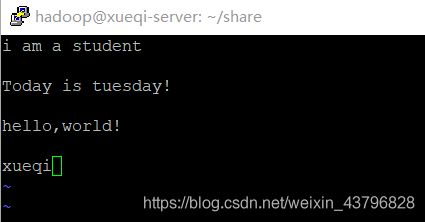
在test3中敲入一些文字(ESC + a切换到编辑模式)(ESC + “:” + wq为保存退出)
将本地的test3上传之HDFS并展示
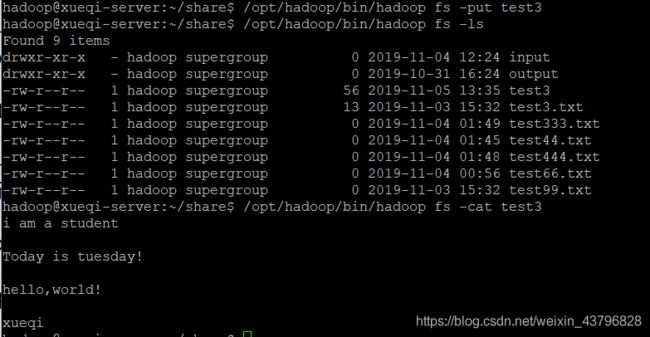
ls
vim MyFSDataInputStream.java //创建一个.java文件,随后将上述代码粘贴保存退出![]()
javac -classpath /opt/hadoop/share/hadoop/common/hadoop-common-2.7.7.jar MyFSDataInputStream.java //编译,编译成功后会出现MyFSDataInputStream.class文件
ls
HADOOP_CLASSPATH=. /opt/hadoop/bin/hadoop MyFSDataInputStream //运行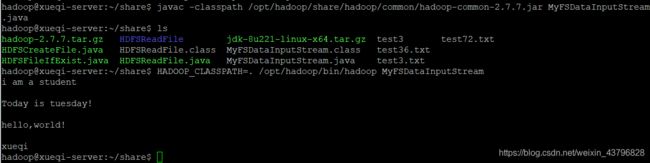
参考文章:
https://blog.csdn.net/fanfan4569/article/details/77823382
https://wenku.baidu.com/view/6d3235d70d22590102020740be1e650e52eacf16.html
https://blog.csdn.net/wozenmezhemeshuai/article/details/79937342
https://blog.csdn.net/T1DMzks/article/details/72593512?locationNum=5&fps=1
https://www.cnblogs.com/OZX143570/p/8947472.html