浅谈Java的函数式接口
Java函数式接口的基本操作
JDK1.8发布已经是六年前的事情了,然而依然还有许多项目尚未迁移到这个版本,以至于JDK8的特性还被人们称为是“新特性”,其中最为人们所熟知的就是函数式编程接口了。它可以简化代码的设计,但相对的,也会使得代码的可读性变差。
在Java中可以使用一个注解来声明这个接口:
@FunctionalInterface
public interface Func<R, T> {
R operater(T t1, T t2);
}之后,把一个lambda表达式作为参数传入到传递给sub,这个sub就可以看作是一个函数:
public class Operat {
public static Integer operator(Integer x, Integer y, OperFunction<Integer, Integer> sub) {
return sub.operater(x, y);
}
public static void main(String[] args) {
System.out.println(operator(20, 5, (x, y) -> x - y)); //计算20-5的值,输出15
}当然,如果不去使用@FunctionalInterface注解这个接口,该接口仍然是一个函数式接口,但是如果不这么做,编译器就不会自动对该接口进行检查,这样就不能确保该接口中只有一个抽象方法。
不过,在实际应用中我们很少会手动去实现这个接口,因为JDK为我们提供了默认的接口:
Consumer<T> void accept(T t) //有入参,无返回值
Supplier<T> T get() //无入参,有返回值
Function<T, R> R apply<T t> //有入参,有返回值
Pridicate<T> boolean test(T t) //有入参,有返回值 有了这几个接口,我们就可以做一些花式操作了。最简单的,比如可以直接声明一个函数类型的变量,然后调用接口中的抽象方法,即可完成lambda表达式的运算:
Function<Integer, Integer> func = p -> p * 100;
System.out.println(func.apply(10)); //输出1000当我们看到“Consumer”和“Supplier”这两个接口的时候,会有一种亲切感:这不就是老生常谈的生产者和消费者吗?而接口的设计也正如其名,一个没有入参,一个没有出参。Consumer接口可以用来作为回调,比如发送一些消息:
public class Demo {
public static void sendMessage(String msg, Consumer < String > consumer) {
consumer.accept(msg);
}
public static void main(String[] args) {
Consumer<String> consumer = (obj) -> {
System.out.println(obj);
System.out.println("调用接口打印");
};
sendMessage("打印信息", consumer);
}
}
//输出:
//打印信息
//调用接口打印这个obj就是传入的字符串对象“打印信息”,consumer作为一个回调函数,在处理其他逻辑的时候顺带帮我们打印出了一些必要的日志信息。该方法最典型的应用在于,当我们打开JDK8中List的forEach()方法时,发现它用的就是Consumer这个接口:
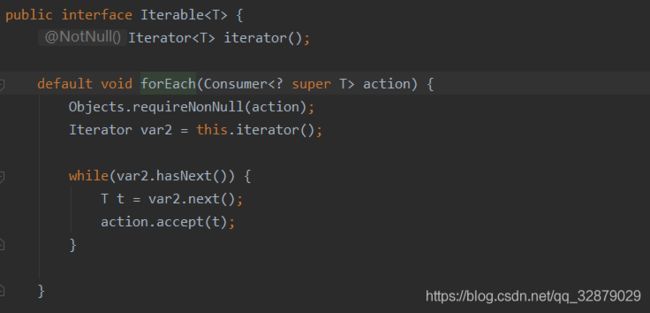
接下来,是名为“Supplier”的生产者方法,它不接受参数,却有一个返回值。作为回调,可以利用这个接口实现工厂模式。比如我们有一个User类,并实现了基本的set和get方法:
public class User {
int age;
String name;
public User(){
}
public User(int age, String name){
this.age = age;
this.name = name;
}
public void setAge(int age) {
this.age = age;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public String getName() {
return name;
}
}如果我们需要在不同的地方去初始化相应的实例,并且希望给每一个实例的设定一个默认的name属性,通常情况下需要调用多个set方法,或者修改对应的POJO类,但是通过利用Supplier接口,就可以实现“一处修改,到处运行”,完成了解耦:
public class Sup {
public static Student newStudent(Supplier<Student> supplier){
return supplier.get();
}
public static void main(String[] args){
Supplier<Student> supplier = ()->{
Student student = new Student();
student.setName("name");
return student;
};
Student student = newStudent(supplier);
System.out.println(student);
}
}
//输出Student{age=0, name='name'}最后是predicate接口,它返回一个bool类型的变量,通过这个接口可以作出一些断言:
Predicate<String> pre = obj->obj.startsWith("a");
System.out.println(pre.test("dddc"));
//输出false函数式接口与stream的混合使用
在JDK8中新增了stream的操作,它通过将集合转换为流式的元素队列,通过声明式的方式,对集合中的每一个元素进行并行或者串行的处理。听到这样的叙述,也会有种很熟悉的感觉,比如我们会经常在python里面使用map和filter方法:
>>> list(map(lambda x: x**2, [1, 2, 3, 4, 5]))
[1, 4, 9, 16, 25]
>>> list(filter(lambda x: x % 2 = 1, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]))
[1, 3, 5, 7, 9]这是非常简单的操作,操作的结果也非常直观,分别是“映射”和“过滤”。在第二个filter函数中传入的匿名函数也可以看作是一个bool类型的变量,这和JDK里面pridicate接口的作用是非常相似的,而在Java8中,同样可以通过数据流来完成同样的操作:
List<Integer> a = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> b = a.stream().map(obj->obj*obj).collect(Collectors.toList());
List<Integer> c = a.stream().filter(obj->obj % 2 == 1).collect(Collectors.toList());
System.out.println(b);
System.out.println(c);
//输出[1, 4, 9, 16, 25]
//输出[1, 3, 5]虽然在Java中这还算是一个比较新的特性,但在Python里面这种写法已经不那么常见了,因为列表推导或者字典推导可以更加高效地完成相同地操作:
>>> [i**2 for i in range(1, 6)]
[1, 4, 9, 16, 25]
>>> [i for i in range(1, 6) if i % 2 == 1]
[1, 3, 5]别忘了在Python和Java中一切都是对象,这两个方法当然也可以作用于对象。试想这样一个场景:在前后端分离的环境下,后端需要对用户的密码进行验证,而前端则不能将用户的密码进行展示,通常后端维护一个User对象,具备用户名和密码等属性,而后端将信息交给前端去渲染地时候,就要使用另外一个不具有密码属性的对象UserDTO:
List<UserDTO> userDtoList = userList.stream().map(obj->{
UserDTO userDTO = new UserDTO(obj.getName());
return userDTO;
})这里,obj传进来代表着User对象,其具有用户名和密码两个属性,而在匿名函数中,我们初始化了UserDTO对象,其不具有密码属性,使用getName方法仅仅对name属性进行初始化。这样在返回给前端的时候,就可以对密码信息进行隐藏。
如果我们打开filter方法的源码,会发现里面的形参正是之前所说的Pridicate接口:
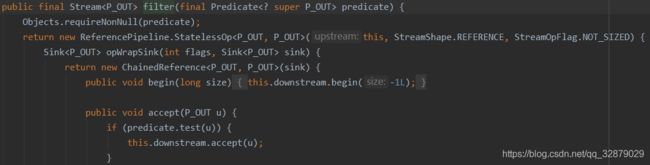
这里顺带说一句,如果想要使用不同的集合类型去接收处理之后的数据流,可以用以下的接口:
Set<Integer> c = a.stream().filter(obj->obj % 2 == 1).collect(Collectors.toCollection(TreeSet::new));这样,就能把List对象转化为Set对象,从而起到了去重的功效。不过TreeSet并不是线程安全的,所以在并行操作的情况下会发生异常,使用线程安全的集合,可以用CopyOnWriteArraySet来替代。
stream的其他操作和引发的联想
拼接
stream还提供了一些其他的基本接口,比如字符串的拼接:
List<String> sl = Arrays.asList("我", "爱", "你");
String s = sl.stream().collect(Collectors.joining("-","[","]"));
System.out.println(s);
//输出[我-爱-你]joining方法的第一个参数是分隔符,第二和第三个参数分别是字符串的首字母和尾字母。如果让我们设计一个小说网站,假如一个小说有1000个章节,难道需要每一个章节的标题都定义一个字段吗?这也太恐怖了吧!这时候,就可以把字符串拼接起来返回给前端,前端拿到之后再把它分割和展示。
分组
stream还有两个接口是partitioningBy和groupBy,熟悉数据库的人对于这两个名词一定不陌生。尽管分组(group by)这个名字是借用SQL数据库语言的命令,但是其理念更加接近发明R语言框架的Hadley Wickham的观点:分割(split)、应用(apply)、和组合(combine)。下面是一个例子:
List<String> s2 = Arrays.asList("Java", "PHP", "Python", "Prolog");
Map<Boolean, List<String>> map = s2.stream().collect(Collectors.partitioningBy(obj->obj.length()>4));
System.out.println(map);
//输出{false=[Java, PHP], true=[Python, Prolog]}输出的结果里面包含了true和false的断言,那么我们不难猜出,这个方法一定是传入了pridicate接口,如果有兴趣的话可以自行点进去看一看。
至于groupBy方法,我们借用上文中使用到的User类,在一个List中初始化几个User实例,然后调用该方法对这些用户进行分组:
public class Group {
public static void main(String[] args) {
List<Student> userList = Arrays.asList(new User(10, "Bob"),
new User(12, "Tom"),
new User(11, "Jack"),
new User(15, "Lili"),
new User(12, "Zack"),
new User(11, "Ann")
);
Map<Integer, List<Student>> map = userList.stream().collect(Collectors.groupingBy(User::getAge));
map.forEach((key, value)->{
System.out.println("-------------");
System.out.println(key);
value.forEach(System.out::println);
});
}
}
/*输出
-------------
10
User{age=10, name='Bob'}
-------------
11
User{age=11, name='Jack'}
User{age=11, name='Ann'}
-------------
12
User{age=12, name='Tom'}
User{age=12, name='Zack'}
-------------
15
User{age=15, name='Lili'}
*/这样,我们就可以直观地看出不同年龄分别有哪些人了。
统计
stream还有一个summarizing的接口,用于统计数据。我们依然使用上文中的这些用户实例,来构建一个新的集合:
IntSummaryStatistics intSummaryStatistics = studentsList.stream().collect(Collectors.summarizingInt(Student::getAge));
System.out.println(intSummaryStatistics.getMax());
System.out.println(intSummaryStatistics.getAverage());
System.out.println(intSummaryStatistics.getMin());
System.out.println(intSummaryStatistics.getCount());
System.out.println(intSummaryStatistics.getSum());
/*输出
15
11.833333333333334
10
6
71
*/由此,我们就使用Java接口实现了数据库的统计功能。之前,我们经常会在使用Python的Pandas包时使用到类似的接口,比如:
>>> import numpy as np
>>> import pandas as pd
>>> rng = np.random.RandomState(0)
>>> df = pd.DataFrame({
'key': ['A', 'B', 'C', 'A', 'B', 'C'],
'data1': range(6),
'data2': rng.randint(0, 10, 6)},
columns=['key', 'data1', 'data2'])
key data1 data2
0 A 0 5
1 B 1 0
2 C 2 3
3 A 3 3
4 B 4 7
5 C 5 9
>>> def filter_func(x):
return x['data2'].std() > 4
>>> print(df.groupby('key').std())
>>> print(df.groupby('key').filter(filter_func))
data1 data2
key
A 2.12132 1.414214
B 2.12132 4.949747
C 2.12132 4.242641
key data1 data2
1 B 1 0
2 C 2 3
4 B 4 7
5 C 5 9
在这里,我们首先构建了一个随机的数据表,然后定义了一个筛选函数,返回一个bool值,判断标准差是否大于4。由于A组data2的标准差不大于4,所以在数据表中被舍弃了。这个filter_func函数本质上也可以看作是匿名的函数,写成lambda的形式也是可以的。不过,我在Java的IntSummaryStatistics类中并没有找到计算标准差相关的接口,它仅仅是提供了一些简单的统计方法。
聚合
MapReduce直译为“映射-减少”,其本质是一种分而治之的思想。它可以根据一定的规则,将stream中的元素计算并返回一个唯一的值。下面是一个累加器的例子:
int value = Stream.of(1, 2, 3, 4, 5).reduce(0, Integer::sum);
//value = 1 + 2 + 3 + 4 + 5每一次循环都会将前两个数操作的结果与第三个数进行操作,并直到整个集合迭代完毕。
无独有偶,我们在Python的numpy库中可以看到类似的操作:
>>> import numpy as np
>>> np.add.reduce(np.arange(1, 6))
15甚至,你还可以在spark里面看到类似的接口:
val input = sc.parallelize(List(1, 2, 3, 4))
val result = input.map(x => x * x)
println(result.collect().mkString(","))
//输出 1, 4, 9, 16
val sum = input.reduce((x, y) => x + y)
//输出10函数式接口体现的是一种数据映射的思想,它所关心的并不是做事的先后顺序,而是“开始”与“结束”的状态,就如同我们在遍历一棵二叉树的时候使用递归的方法一样。它可以简化程序设计的步骤,但有时也会使得程序变得不那么容易阅读。