awk笔记:使用awk进行文本处理
1.前言
在linux下开发,因为经常需要分析项目的日志文件,以此来查找软件功能可能的异常点,经同事的介绍慢慢接触了linux下的三大利器:grep,sed,awk,特通过以下例子来总结下自己的学习结果;
2.需求说明
从文本文件内筛选出起始点坐标和结束点坐标,并将此结果数据构造sql语句,最后使用sql将数据插入到对应表中;
操作步骤大体如下:
a.筛选出坐标信息;
b.过滤数据:包括删除重复行,去掉异常数据;
c.构造sql语句;
d.导入;
3.实现
a.文件名为combine.log,其内容如下图所示
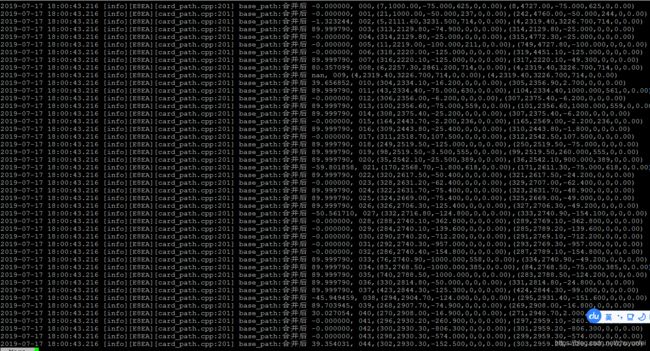
需要将其中的坐标信息如(2375.40,-25.200),(2375.40,-6.200)数据给筛选出来;
b.筛选出坐标数据,我们先筛选出包含坐标的数据:
$cat combine.log | awk '{ print $6 }' | more
执行以上命令后的结果如下图所示:

PS:根据观察a中的数据,可知坐标数据都在第6列里,通过awk的$6,将这一列数据提出来并输出到管道,将其作为下一步需要处理的数据来源;
c.利用awk按空格识别列的策略,对数据进行如下处理:
1)将逗号(,)替换为空格,使用sed进行处理;语句如下
$sed 's/\,/\ /g'
2)过滤掉其中重复的行;语句如下:
$awk '!a[$0]++'
3)去掉其中坐标列数据异常值为“-nan”的数据;语句如下:
awk '$3!="-nan" {print $0}'
比对未处理和处理后的数据记录数:
没有过滤之前,筛选出的记录数,如下图所示:
![]()
通过增加筛选条件后的记录数,如下图所示:
![]()
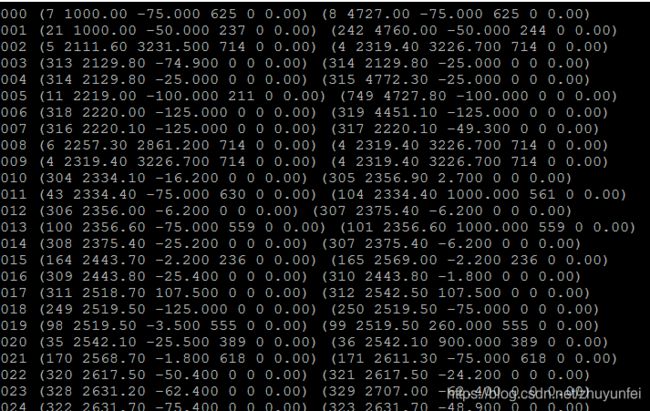
执行如下筛选语句
cat combine.log | awk '{print $6}' | sed 's/\,/\ /g' | awk '!a[$0]++' | awk '$3!="-nan" {print $0}' | more
结果如下图所示:
d.获取坐标数据并进行简单处理,以便后续构造sql语句;
1)获取数据,将第3,4列和第9,10列数据筛选出来;
awk '{printf("%s,%s %s,%s\n",$3,$4,$9,$10)}'
2)将坐标拼成形如(x,y)的字符串;
awk '{printf("\"%s\" \"%s\"\n"),$1,$2}'
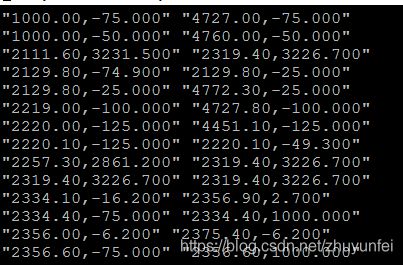
查看如下命令查看筛选后的结果:
cat combine.log | awk '{print $6}' | sed 's/\,/\ /g' | awk '!a[$0]++' | awk '$3!="-nan" {print $0}' |awk '{printf("%s,%s %s,%s\n",$3,$4,$9,$10)}'| awk '{printf("\"%s\" \"%s\"\n"),$1,$2}'| more
数据如下图所示:
e.构造sql语句,并将结果保存到文件;
awk '{printf("insert into dat_reader_path_combine(start_point,end_point) values(%s,%s);\n",$1,$2)}'
执行以下完整语句:
cat combine.log | awk '{print $6}' | sed 's/\,/\ /g' | awk '!a[$0]++' | awk '$3!="-nan" {print $0}' |awk '{printf("%s,%s %s,%s\n",$3,$4,$9,$10)}'| awk '{printf("\"%s\" \"%s\"\n"),$1,$2}'| awk '{printf("insert into dat_reader_path_combine(start_point,end_point) values(%s,%s);\n",$1,$2)}' > combine.sql
查看conbine.sql的内容,如下图所示:
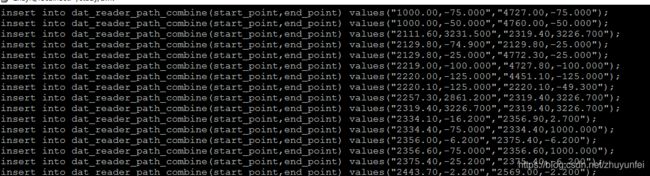
使用生成的combine.sql在数据库内执行后的结果,如下图所示:
4.总结
a.使用awk可以非常简答的删除筛选数据内的重复行;
b.使用awk的printf函数将坐标数据组成想要的字符串;
c.使用sed进行字符的查找替换;
d.利用awk按空格分隔数据的方式,进行数据的获取;
5.测试数据文件
链接: https://pan.baidu.com/s/1OUjsCGsG0o_8yr8AdxB6_A 提取码: neym