14. Linux系统服务管理
目录
14.1 Linux系统服务
服务的分类
查询已经安装的服务和区分服务
14.2 linux端口
查询系统中已经启动的服务
14.3 Linux独立服务管理
独立服务的启动管理
独立服务的自启动管理
14.4 Linux基于xinetd服务的管理
基于 xinetd 服务的启动
基于xientd 服务的自启动
14.5 Linux源码包服务管理
源码包服务的启动管理
源码包服务的自启动管理
让源码包服务被服务管理命令识别
14.6 Linux常见服务类别及功能
14.7 影响Linux系统性能的因素有哪些?
CPU
内存
磁盘读写(I/O)能力
网络带宽
14.8 Linux分析系统性能(sar命令)
14.9 Linux如何查看CPU运行状态?
Linux CPU性能分析:vmstat命令
Linux CPU性能分析:sar命令
Linux CPU性能分析:iostat命令
Linux CPU性能分析:uptime命令
14.10 Linux如何查看内存的使用情况?
Linux查看内存使用情况:free命令
Linux查看内存使用情况:vmstat命令
Linux查看内存使用情况:sar命令
14.11 Linux如何查看硬盘的读写性能?
Linux查看硬盘读写性能:sar -d命令
Linux查看硬盘读写性能:iostat -d命令
Linux查看硬盘读写性能:vmstat -d命令
什么是系统服务?服务是在后台运行的应用程序,并且可以提供一些本地系统或网络的功能。
那么,Linux 中常见的服务有那些,这些服务怎么分类,服务如何启动,服务如何自启动,服务如何查看?这些就是本章要解决的主要问题。
其实服务管理并不难,但是 Linux 中服务的分类比较多,而且每种服务又有多种启动和自启动方法,所以容易混淆。同时,常见网络服务的端口号也是必须掌握的基础知识。
14.1 Linux系统服务
我们知道,系统服务是在后台运行的应用程序,并且可以提供一些本地系统或网络的功能。我们把这些应用程序称作服务,也就是 Service。不过,我们有时会看到 Daemon 的叫法,Daemon 的英文原意是"守护神",在这里是"守护进程"的意思。
那么,什么是守护进程?它和服务又有什么关系呢?守护进程就是为了实现服务、功能的进程。比如,我们的 apache 服务就是服务(Service),它是用来实现 Web 服务的。那么,启动 apache 服务的进程是哪个进程呢?就是 httpd 这个守护进程(Daemon)。也就是说,守护进程就是服务在后台运行的真实进程。
如果我们分不清服务和守护进程,那么也没有什么关系,可以把服务与守护进程等同起来。在 Linux 中就是通过启动 httpd 进程来启动 apache 服务的,你可以把 httpd 进程当作 apache 服务的别名来理解。
服务的分类
Linux 中的服务按照安装方法不同可以分为 RPM 包默认安装的服务和源码包安装的服务两大类。其中,RPM 包默认安装的服务又因为启动与自启动管理方法不同分为独立的服务和基于 xinetd 的服务。服务分类的关系图如图 1 所示。

图 1 服务分类的关系图
我们知道,Linux 中常见的软件包有两种:一种是 RPM 包;另一种是源码包。那么,通过 RPM 包安装的系统服务就是 RPM 包默认安装的服务(因为 Linux 光盘中全是 RPM 包,Linux 系统也是通过 RPM 包安装的,所以我们把 RPM 包又叫作系统默认包),通过源码包安装的系统服务就是源码包安装的服务。
源码包是开源的,自定义性强,通过编译安装更加适合系统,但是安装速度较慢,编译时容易报错。RPM 包是经过编译的软件包,安装更快速,不易报错,但不再是开源的。
以上这些特点都是软件包本身的特点,但是软件包一旦安装到 Linux 系统上,它们的区别是什么呢?
最主要的区别就是安装位置不同,源码包安装到我们手工指定的位置当中,而 RPM 包安装到系统默认位置当中(可以通过"rpm -ql 包名"命令查询)。也就是说,RPM 包安装到系统默认位置,可以被服务管理命令识别;但是源码包安装到手工指定位置,当然就不能被服务管理命令识别了(可以手工修改为被服务管理命令识别)。
所以,RPM 包默认安装的服务和源码包安装的服务的管理方法不同,我们把它们当成不同的服务分类。服务分类说明如下。
RPM 包默认安装的服务。这些服务是通过 RPM 包安装的,可以被服务管理命令识别。
这些服务又可以分为两种:
- 独立的服务:就是独立启动的意思,这种服务可以自行启动,而不用依赖其他的管理服务。因为不依赖其他的管理服务,所以,当客户端请求访问时,独立的服务响应请求更快速。目前,Linux 中的大多数服务都是独立的服务,如 apache 服务、FTP 服务、Samba 服务等。
- 基于 xinetd 的服务:这种服务就不能独立启动了,而要依靠管理服务来调用。这个负责管理的服务就是 xinetd 服务。xinetd 服务是系统的超级守护进程,其作用就是管理不能独立启动的服务。当有客户端请求时,先请求 xinetd 服务,由 xinetd 服务去唤醒相对应的服务。当客户端请求结束后,被唤醒的服务会关闭并释放资源。这样做的好处是只需要持续启动 xinetd 服务,而其他基于 xinetd 的服务只有在需要时才被启动,不会占用过多的服务器资源。但是这种服务由于在有客户端请求时才会被唤醒,所以响应时间相对较长。
源码包安装的服务。这些服务是通过源码包安装的,所以安装位置都是手工指定的。由于不能被系统中的服务管理命令直接识别,所以这些服务的启动与自启动方法一般都是源码包设计好的。每个源码包的启动脚本都不一样,一般需要查看说明文档才能确定。
查询已经安装的服务和区分服务
我们已经知道 Linux 服务的分类了,那么应该如何区分这些服务呢?首先要区分 RPM 包默认安装的服务和源码包安装的服务。源码包安装的服务是不能被服务管理命令直接找到的,而且一般会安装到 /usr/local/ 目录中。
也就是说,在 /usr/local/ 目录中的服务都应该是通过源码包安装的服务。RPM 包默认安装的服务都会安装到系统默认位置,所以是可以被服务管理命令(如 service、chkconfig)识别的。
其次,在 RPM 包默认安装的服务中怎么区分独立的服务和基于 xinetd 的服务?这就要依靠 chkconfig 命令了。chkconfig 是管理 RPM 包默认安装的服务的自启动的命令,这里仅利用这条命令的查看功能。使用这条命令还能看到 RPM 包默认安装的所有服务。命令格式如下:
[root@localhost ~]# chkconfig --list [服务名]
选项:
- --list:列出 RPM 包默认安装的所有服务的自启动状态;
例如:
[root@localhost ~]# chkconfig -list
#列出系统中RPM包默认安装的所有服务的自启动状态
abrt-ccpp 0:关闭 1:关闭 2:关闭 3:启用 4:关闭 5:启用 6:关闭
abrt-oops 0:关闭 1:关闭 2:关闭 3:启用 4:关闭 5:启用 6:关闭
…省略部分输出…
udev-post 0:关闭 1:启用 2:启用 3:启用 4:启用 5:启用 6:关闭
ypbind 0:关闭 1:关闭 2:关闭 3:关闭 4:关闭 5:关闭 6:关闭
这条命令的第一列为服务的名称,后面的 0~6 代表在不同的运行级别中这个服务是否开启时自动启动。这些服务都是独立的服务,因为它们不需要依赖其他任何服务就可以在相应的运行级别启动或自启动。但是没有看到基于 xinetd 的服务,那是因为系统中默认没有安装 xinetd 这个超级守护进程,需要我们手工安装。
安装命令如下:
[root@localhost ~]# rpm -ivh /mnt/cdrom/Packages/ xinetd-2.3.14-34.el6.i686.rpm
Preparing...
###############
[100%]
1:xinetd
###############
[100%]
#xinetd超级守护进程
这里需要注意的是,在 Linux 中基于 xinetd 的服务越来越少,原先很多基于 xinetd 的服务在新版本的 Linux 中已经变成了独立的服务。安装完 xinetd 超级守护进程之后,我们再查看一下,命令如下:
[root@localhost ~]# chkconfig --list
abrt-ccpp 0:关闭 1:关闭 2:关闭 3:启用 4:关闭 5:启用 6:关闭
abrt-oops 0:关闭 1:关闭 2:关闭 3:启用 4:关闭 5:启用 6:关闭
…省略部分输出…
udev-post 0:关闭 1:启用 2:启用 3:启用 4:启用 5:启用 6:关闭
xinetd 0:关闭 1:关闭 2:关闭 3:启用 4:启用 5:启用 6:关闭
ypbind 0:关闭 1:关闭 2:关闭 3:关闭 4:关闭 5:关闭 6:关闭
基于 xinetd 的服务:
chargen-dgram:关闭
chargen-stream:关闭
cvs:关闭
daytime-dgram:关闭
daytime-stream:关闭
discard-dgram:关闭
discard-stream:关闭
echo-dgram:关闭
echo-stream:关闭
rsync:关闭
tcpmux-server:关闭
time-dgram:关闭
time-stream:关闭
在刚刚的独立的服务之下出现了一些基于 xinetd 的服务,这些服务没有自己的运行级别,因为它们不是独立的服务,到底在哪个运行级别可以自启动,则要看 xinetd 服务是在哪个运行级别自启动的。
14.2 linux端口
服务是给系统提供功能的,在系统中除了有系统服务,还有网络服务。而每个网络服务都有自己的端口,一般端口号都是固定的。那么,什么是端口呢?
我们知道,IP 地址是计算机在互联网上的地址编号,每台联网的计算机都必须有自己的 IP 地址,而且必须是唯一的,这样才能正常通信。也就是说,在互联网上是通过 IP 地址来确定不同计算机的位置的。
大家可以把 IP 地址想象成家庭的"门牌号码",不管你住的是大杂院、公寓楼还是别墅,都有自己的门牌号码,而且门牌号码是唯一的。
如果知道了一台服务器的 IP 地址,我们就可以找到这台服务器。但是这台服务器上有可能搭建了多个网络服务,比如 WWW 服务、FTP 服务、Mail 服务,那么我们到底需要服务器为我们提供哪个网络服务呢?这时就要靠端口(Port)来区分了,因为每个网络服务对应的端口都是固定的。
比如,WWW 服务对应的端口是 80,FTP 服务对应的端口是 20 和 21,Mail 服务对应的端口是 25 和 110。也就是说,IP 地址可以想象成"门牌号码",而端口可以想象成"家庭成员",找到了 IP 地址只能找到你们家,只有找到了端口,寄信时才能找到真正的收件人。
为了统一整个互联网的端口和网络服务的对应关系,以便让所有的主机都能使用相同的机制来请求或提供服务,同一个服务使用相同的端口,这就是协议。
计算机中的协议主要分为两大类:
- 面向连接的可靠的TCP协议(Transmission Control Protocol,传输控制协议);
- 面向无连接的不可靠的UDP协议(User Datagram Protocol,用户数据报协议);
这两种协议都支持 216,也就是 65535 个端口。这么多端口怎么记忆呢?系统给我们提供了服务与端口的对应文件 /etc/services。 查看—下:
[root@localhost ~]#vi /etc/services
…省略部分输出…
ftp-data 20/tcp
ftp-data 20/udp
# 21 is registered to ftp, but also used by fsp
ftp 21/tcp
ftp 21/udp
fsp fspd
#FTP服务的端口
…省略部分输出…
smtp 25/tcp mail
smtp 25/udp mail
#邮件发送信件的端口
…省略部分输出…
http 80/tcp www www-http #WorldWideWeb HTTP
http 80/udp www www-http #HyperText Transfer Protocol
#WWW服务的端口
…省略部分输出…
pop3 110/tcp pop-3
# POP version 3
pop3 110/udp pop-3
#邮件接收信件的端口
…省略部分输出…
网络服务的端口能够修改吗?当然是可以的,不过一旦修改了端口,那么客户机在访问服务器时很难知道服务器对应的端口是什么,也就不能正确地获取服务了。所以,除非在实验环境下,否则不要修改网络服务对应的端口。
查询系统中已经启动的服务
既然每个网络服务对应的端口是固定的,那么是否可以通过查询服务器中开启的端口,来判断当前服务器开启了哪些服务?
当然是可以的。虽然判断服务器中开启的服务还有其他方法(如通过ps命令),但是通过端口的方法查看最为准确。命令格式如下:
[root@localhost ~]# netstat 选项
选项:
- -a:列出系统中所有网络连接,包括已经连接的网络服务、监听的网络服务和 Socket 套接字;
- -t:列出 TCP 数据;
- -u:列出 UDF 数据;
- -l:列出正在监听的网络服务(不包含已经连接的网络服务);
- -n:用端口号来显示而不用服务名;
- -p:列出该服务的进程 ID (PID);
举个例子:
[root@localhost ~]# netstat -tlunp
#列出系统中所有已经启动的服务(已经监听的端口),但不包含已经连接的网络服务
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:53575 0.0.0.0:*
LISTEN
1200/rpc.statd
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 1181/rpcbind
tcp 0 0 0.0.0.0:22 O.O.O.O:* LISTEN 1405/sshd
tcp 0 0127.0.0.1:631 O.O.O.O:* LISTEN 1287/cupsd
tcp 0 0 127.0.0.1:25 O.O.O.O:* LISTEN 1481/master
tcp 0 0 :::57454 :::* LISTEN 1200/rpc.statd
tcp 0 0 :::111 :::* LISTEN 1181/rpcbind
tcp 0 0 :::22 :::* LISTEN 1405/sshd
tcp 0 0 ::1:631 :::* LISTEN 1287/cupsd
tcp 0 0 ::1:25 :::* LISTEN 1481/master
udp 0 0 0.0.0.0:58322 0.0.0.0:* 1276/avahi-daemon
udp 0 0 0.0.0.0:5353 O.O.O.O:* 1276/avahi-daemon
udp 0 0 0.0.0.0:111 O.O.O.O:* 1181/rpcbind
udp 0 0 0.0.0.0:631 O.O.O.O:* 1287/cupsd
udp 0 0 0.0.0.0:56459 0.0.0.0:* 1200/rpc.statd
udp 0 0 0.0.0.0:932 O.O.O.O:* 1181/rpcbind
udp 0 0 0.0.0.0:952 O.O.O.O:* 1200/rpc.statd
udp 0 0 :::111 :::* 1181/rpcbind
udp 0 0 :::47858 :::* 1200/rpc.statd
udp 0 0 :::932 :::* 1181/rpcbind
执行这条命令会看到服务器上所有已经开启的端口,也就是说,通过这些端口就可以知道当前服务器上开启了哪些服务。
解释一下命令的执行结果:
- Proto:数据包的协议。分为 TCP 和 UDP 数据包;
- Recv-Q:表示收到的数据已经在本地接收缓冲,但是还没有被进程取走的数据包数量;
- Send-Q:对方没有收到的数据包数量;或者没有 Ack 回复的,还在本地缓冲区的数据包数量;
- Local Address:本地 IP : 端口。通过端口可以知道本机开启了哪些服务;
- Foreign Address:远程主机:端口。也就是远程是哪个 IP、使用哪个端口连接到本机。由于这条命令只能查看监听端口,所以没有 IP 连接到到本机;
- State:连接状态。主要有已经建立连接(ESTABLISED)和监听(LISTEN)两种状态,当前只能查看监听状态;
- PID/Program name:进程 ID 和进程命令;
再举个例子:
[root@localhost ~]# netstat -an
#查看所有的网络连接,包括已连接的网络服务、监听的网络服务和Socket套接字
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:53575 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN
tcp 0 0 192.168.0.210:22 192.168.0.105:4868 ESTABLISHED
tcp 0 0 :::57454 :::* LISTEN
...省略部分输出...
udp 0 0 :::932 :::*
Active UNIX domain sockets (servers and established)
Proto RefCnt Flags Type State I-Node Path
#Socket套接字输出,后面有具体介绍
Unix 2 [ ACC ] STREAM LISTENING 11712 /var/run/dbus/system_bus_socket
unix 2 [ ACC ] STREAM LISTENING 8450 @/com/ubuntu/upstart unix 7. [ ] DGRAM 8651 @/org/kernel/udev/udevd
unix 2 [ ACC ] STREAM LISTENING 11942 @/var/run/hald/dbus-b4QVLkivf1
...省略部分输出...
执行"netstat -an"命令能査看更多的信息,在 Stated 中也看到了已经建立的连接(ESTABLISED)。这是 ssh 远程管理命令产生的连接,ssh 对应的端口是 22。
而且我们还看到了 Socket 套接字。在服务器上,除网络服务可以绑定端口,用端口来接收客户端的请求数据外,系统中的网络程序或我们自己开发的网络程序也可以绑定端口,用端口来接收客户端的请求数据。这些网络程序就是通过 Socket 套接字来绑定端口的。也就是说,网络服务或网络程序要想在网络中传递数据,必须利用 Socke 套接字绑定端口,并进行数据传递。
使用"netstat -an"命令查看到的这些 Socke 套接字虽然不是网络服务,但是同样会占用端口,并在网络中传递数据。
解释一下 Socket 套接字的输出:
- Proto:协议,一般是unix;
- RefCnt:连接到此Socket的进程数量;
- Flags:连接标识;
- Type:Socket访问类型;
- State:状态,LISTENING表示监听,CONNECTED表示已经建立连接;
- I-Node:程序文件的 i 节点号;
- Path:Socke程序的路径,或者相关数据的输出路径;
14.3 Linux独立服务管理
我们知道,RPM 包默认安装的服务分为独立的服务和基于 xinetd 的服务,本节来学习独立服务的管理。
独立服务的启动管理
独立的服务要想启动,主要有两种方法。
1) 使用/etc/init.d/目录中的启动脚本来启动独立的服务
既然所有独立服务的启动脚本都存放在 /etc/init.d/ 目录中,那么,调用这些脚本就可以启动独立的服务了。这种启动方式是推荐启动方式,命令格式如下:
[root@localhost ~]#/etc/init.d独立服务名 start| stop|status|restart|...
参数:
- start:启动服务;
- stop:停止服务;
- status:查看服务状态;
- restart:重启动服务;
我们以启动 RPM 包默认安装的 httpd 服务为例,命令如下:
[root@localhost ~]# /etc/init.d/httpd start
正在启动httpd:
[确定]
#启动httpd服务
[root@localhost ~]# /etc/init.d/httpd status
httpd (pid 13313)正在运行…
#查询httpd服务状态,并能够看到httpd服务的PID
[root@localhost ~]#/etc/init.d/httpd stop
停止 httpd:
[确定]
#停止httpd服务
[root@localhost ~]#/etc/init.d/httpd restart
停止httpd:
[失败]
正在启动httpd:
[确定]
重启动httpd服务
2) 使用service命令来启动独立的服务
在 CentOS 系统中,我们还可以依赖 service 命令来启动独立的服务。service 命令实际上只是一个脚本,这个脚本仍然需要调用 /etc/init.d/ 中的启动脚本来启动独立的服务。而且 service 命令是红帽系列 Linux 的专有命令,其他的 Linux 发行版本不一定拥有这条命令,所以我们并不推荐使用 service 命令来启动独立的服务。
service 命令格式如下:
[root@localhost ~]# service 独立服务名 start|stop|restart|...
例如:
[root@localhost ~]# service httpd restart
停止httpd:
[确定]
正在启动httpd:
[确定]
命令比输入 /etc/init_d/ 目录要稍微简单。service 命令还可以查看所有独立服务的启动状态,这是一个常用功能,命令格式如下:
[root@localhost ~]# service --status -all
选项:
- --status -all:列出所有独立服务的启动状态;
例如:
abrtd(pid 1505)正在运行…
abrt-dumpoops(pid 1513)正在运行…
acpid(pid 1312)正在运行...
…省略部分输出…
随着 httpd 服务的启动和停止,使用"netstat -tlun"命令就会看到 80 端口出现和消失。这也就说明 apache 服务绑定的口就是 80,所以我们可以端口是否在服务器中出现来判断 apache 服务是否启动。
独立服务的自启动管理
自启动指的是在系统之后,服务是否随着系统的启动而自动启动。如果启动了某个服务,那么这个服务会在系统重启之后启动吗?
答案是不知道,因为启动命令只负责启动服务,而和服务的自启动完全没有关系。同样地,自启动命令只管服务是否会在系统重启之后启动,而和当前系统中的服务是否启动没有关系。
独立服务的自启动方法有三种,我们分别来学习。
1) 使用 chkconfig 服务自启动管理命令
第一种方法是利用 chkconfig 服务自启动管理命令来管理独立服务的自启动,这条命令的用法如下:
[root@localhost ~]# chkconfig --list
使用 chkconfig 命令除了可以查看所有 RPM 包默认安装服务的自启动状态,也可以修改和设置 RPM 包默认安装服务的自启动状态,只是独立的服务和基于 xinetd 的服务的设定方法稍有不同。我们先来看看独立的服务如何设置。命令格式如下:
[root@localhost ~]# chkconfig [--level 运行级别][独立服务名][on|off]
#选项:
- --level: 设定在哪个运行级别中开机自启动(on),或者关闭自启动(off);
例如:
[root@localhost ~]# chkconfig --list | grep httpd
httpd 0:关闭 1:关闭 2:关闭 3:关闭 4:关闭 5:关闭 6:关闭
#查询httpd的自启动状态。所有的级别都是不自启动的
[root@localhost ~]# chkconfig --level 2345 httpd on
#设置apache服务在进入2、3、4、5级别时自启动
[root@localhost ~]# chkconfig --list | grep httpd
httpd 0:关闭 1:关闭 2:启用 3:启用 4:启用 5:启用 6:关闭
#查询apache服务的自启动状态。发现在2、3、4、5这4个运行级别中变为了"启用"
还记得 0~6 这 7 个 Linux 的运行级别吗?如果在 0~6 这 7 个运行级别中服务都显示"关闭",则该服务不自启动。如果在某个运行级别中显示"启用",则代表在进入这个运行级别时,该服务开机自启动。
服务的自启动方法和服务的启动方法是不通用的,我们做一个实验验证一下。命令如下:
[root@localhost ~]# /etc/init.d/httpd status
httpd已停
#查询apache服务状态,是已经停止的
[root@localhost ~]# chkconfig --level 2345 httpd on
#设置apache服务在进入2、3、4、5级别时自启动
[root@localhost ~]# chkconfig --list|grep httpd
httpd 0:关闭 1:关闭 2:启用 3:启用 4:启用 5:启用 6:关闭
#查看一下,自启动已经生效
[root@localhost ~]#/etc/init.d/httpd status
httpd已停
#但是apache服务在当前系统中还是关闭的
大家看到了吗?虽然 apach 被设置为自启动,但是当前系统中的 apache 是没有启动的,所以启动和自启动是独立的。
2) 修改 /etc/rc.d/rc.local 文件,设置服务自启动
第二种方法就是修改 /etc/rc.d/rc.local 文件,在文件中加入服务的启动命令。这个文件是在系统启动时,在输入用户名和密码之前最后读取的文件(注意:/etc/rc.d/rc.loca和/etc/rc.local 文件是软链接,修改哪个文件都可以)。这个文件中有什么命令,都会在系统启动时调用。
如果我们把服务的启动命令放入这个文件,这个服务就会在开机时自启动。命令如下:
[root@localhost ~]#vi /etc/rc.d/rc.local
#!/bin/sh
#
#This script will be executed *after* all the other init scripts.
#You can put your own initialization stuff in here if you don't want to do the full Sys V style init stuff.
touch /var/lock/subsys/local
/etc/rc.d/init.d/httpd start
#在文件中加入apache的启动命令
这样,只要重启之后,apache 服务就会开机自启动了。推荐大家使用这种方法管理服务的自启动,有两点好处:
- 第一,如果大家都采用这种方法管理服务的自启动,当我们碰到一台陌生的服务器时,只要查看这个文件就知道这台服务器到底自启动了哪些服务,便于集中管理。
- 第二,chkconfig 命令只能识别 RPM 包默认安装的服务,而不能识别源码包安装的服务。 源码包安装的服务的自启动也是通过 /etc/rc.d/rc.local 文件实现的,所以不会出现同一台服务器自启动了两种安装方法的同一个服务。
还要注意一下,修改 /etc/rc.d/rc.local 配置文件的自启动方法和 chkconfig 命令的自启动方法是两种不同的自启动方法。所以,就算通过修改 /etc/rc.d/rc.local 配置文件的方法让某个独立的服务自启动了,执行"chkconfig --list"命令并不到有什么变化。
3) 使用 ntsysv 命令管理自启动
第三种方法是使用 ntsysv 命令调用窗口模式来管理服务的自启动,非常简单。命令格式如下:
[root@localhost ~]# ntsysv [--level 运行级别]
选项:
- --level 运行级别:可以指定设定自启动的运行级别;
例如:
[root@localhost ~]# ntsysv --level 235
#只设定2、3、5级别的服务自启动
[root@localhost ~]# ntsysv
#按默认的运行级别设置服务自启动
执行命令后,会和 setup 命令类似,出现命令界面,如图 1 所示。

图 1 ntsysv命令界面
这个命令的操作是这样的:
- 上下键:在不同服务之间移动;
- 空格键:选定或取消服务的自启动。也就是在服务之前是否输入"*";
- Tab键:在不同项目之间切换;
- F1键:显示服务的说明;
需要注意的是,ntsysv 命令不仅可以管理独立服务的自启动,也可以管理基于 xinetd 服务的自启动。也就是说,只要是 RPM 包默认安装的服务都能被 ntsysv 命令管理。但是源码包安装的服务不行。
这样管理服务的自启动多么方便,为什么还要学习其他的服务自启动管理命令呢? ntsysv 命令虽然简单,但它是红帽系列 Linux 的专有命令,其他的 Linux 发行版本不一定拥有这条命令,而且条命令也不能管理源码包安装的服务,所以我们推荐大家使用 /etc/rc.d/rc.local 文件来管理服务的自启动。
14.4 Linux基于xinetd服务的管理
本节学习基于 xinetd 服务的管理方法。基于 xinetd 的服务同样有启动管理和自启动管理之分,而且不管是启动管理还是自启动管理,都只有一种方法,相比独立的服务简单一些。
基于 xinetd 服务的启动
基于 xinetd 的服务没有自己独立的启动脚本程序,是需要依赖 xinetd 的启动脚本来启动的。xinetd 本身是独立的服务,所以 xinetd 服务自己的启动方法和独立服务的启动方法是一致的。
但是,所有基于 xinetd 这个超级守护进程的其他服务就不是这样的了,必须修改该服务的配置文件,才能启动基于 xinetd 的服务。所有基于 xinetd 服务的配置文件都保存在 /etc/xinetd.d/ 目录中。
我们使用 Telnet 服务来举例。Telnet 服务是用来进行系统远程管理的,端口是 23。不过需要注意的是,Telnet 服务的远程管理数据在网络中是明文传输的,非常不安全,所以在生产服务器上是不建议启动 Telnet 服务的。在生产服务器上,远程管理使用的是 ssh 协议,ssh 协议是加密的,更加安全。
Telnet 服务也是分为"客户端/服务器端"的,其中服务器端是用来启动 Telnet 服务的,并不安全;客户端是用来连接服务器端或测试服务器的端口是否开启的,在实际工作中我们主要使用 Telnet 客户端来测试远程服务器开启了哪些端口。
客户端的命令格式如下:
[root@localhost ~]# telnet 服务器 IP
#连接并管理远程服务器,因为数据明文传输,所以不安全
[root@localhost ~]# telnet 服务器IP 端口
#测试远程服务器的端口是否开启。如果能够正常连接,则证明该端口是开启的
例如:
[root@localhost ~]# telnet 192.168.0.210 22
#测试一下192.168.0.210这台服务器上的22(ssh服务)端口是否打开
#连接成功后,退出时使用"Ctrl+]"快捷键回到telnet交互模式,再输入"quit"退出
虽然 Telnet 服务不安全,但 Telnet 服务是基于 xinetd 的服务,我们使用 Telnet 服务来学习一下基于 xinetd 服务的启动管理。在目前的 Linux 系统中,Telnet 的服务器端都是不安装的,如果进行测试,则需要手工安装。安装命令如下:
[root@localhost ~]#rpm-ivh/mnt/cdroin/Packages/telnet-server-0.17-47.el6.i686.rpm
[100%]
###############
Preparing...
1:telnet-server
###############
[100%]
#安装
[root@localhost ~]# chkconfig -list
#安装之后查询一下
…省略部分输出...
基于xinetd的服务:
chargen-dgram:关闭
chargen-stream:关闭
cvs:关闭
daytime-dgram:关闭
daytime-stream:关闭
discard-dgram:关闭
discard-stream:关闭
echo-dgram:关闭
echo-stream:关闭
rsync:关闭
tcpmux-server:关闭
telnet:关闭
time-dgram:关闭
time-stream:关闭
#Telnet服务已经安装,是基于xinetd的服务,自启动状态是关闭
接下来我们就要启动 Telnet 服务了。既然基于 xinetd 服务的配置文件都在 /etc/xinetd.d/ 目录中,那么 Telnet 服务的配置文件就是 /etc/xinetd.d/telnet。我们打开这个文件看看,如下:
[root@localhost ~]#vi /etc/xinetd.d/telnet
#default: on
#description: The telnet server serves telnet sessions; it uses \
#unencrypted username/password pairs for authentication.
service telnet
#服务的名称为telnet
{
flags = REUSE
#标志为REUSE,设定TCP/IP socket可重用
socketjtype = stream
#使用 TCP协议数据包
wait = no
#允许多个连接同时连接
user = root
#启动服务的用户为root
server = /usr/sbin/in.telnetd
#服务的启动程序
log_on_failure += USERID
#登录失败后,记录用户的ID
disable = yes
#服务不启动
}
如果想要启动 Telnet 服务,则只需要把 /etc/xinetd.d/telnet 文件中的"disable=yes"改为"disable=no"即可,"disable"代表取消,"disable=yes"代表取消是 yes,当然不启动服务;"disable=no"代表取消是 no,当然就是启动服务了。具体命令如下:
[root@localhost ~]#vi /etc/xinetd.d/telnet
#修改配置文件
service telnet {
…省略部分输出…
disable = no
#把 yes 改为no
}
[root@localhost ~]# service xinetd restart
#重启xinetd服务
停止 xinetd:
[确定]
正在启动xinetd:
[确定]
[root@localhost ~]# netstat -tlun|grep 23
tcp 0 0 :::23 :::* LISTEN
#查看端口,23端口启动,表示Telne服务已经启动了
基于 xinetd 服务的启动都是这样的,只需修改 /etc/xinetd.d/ 目录中的配置文件,然后重启 xientd 服务即可。
基于xientd 服务的自启动
基于 xinetd 服务的自启动管理有两种方法,分别是通过 chkconfig 命令管理自启动和通过 ntsysv 命令管理自启动。但是不能通过修改 /etc/rc.d/rc.local 配置文件来管理自启动,因为基于 xinetd 的服务没有自己的启动脚本程序。我们分别来看看。
1) 使用 chkconfig 命令管理自启动
chkconfig 自启动管理命令可以管理所有 RPM 包默认安装的服务,所以也可以用来管理基于 xinetd 服务的自启动。命令格式如下:
[root@localhost ~]# chkconfig 服务名 on|off
#基于xinetd的服务没有自己的运行级别,而依靠xinetd服务的运行级别,所以不用指定--level选项
例如:
[root@localhost ~]# chkconfig telnet on
#启动Telnet服务的自启动
[root@localhost ~]# chkconfig --list|grep telnet
telnet:启用
#查看服务的自启动,Telnet服务变为了"启用"
[root@localhost ~]# chkconfig telnet off
#关闭Telnet服务的自启动
[root@localhost ~]# chkconfig --list|grep telnet
telnet:关闭
#查看服务的自启动,Telnet服务变为了 "关闭"
2) 使用 ntsysv 命令管理自启动
ntsysv 命令既然可以管理所有 RPM 包默认安装的服务,当然也能管理基于 xinetd 的服务。命令的使用方法和管理独立的服务是一样的,这里就不再重复介绍了。
其实,如果我们仔细来看,就会发现基于 xinetd 服务的启动和自启动区分得并不严格。启动命令也会把服务设置为自启动,自启动命令也会把服务设置为启动。我们做一个实验看看,命令如下:
[root@localhost ~]# vi /etc/xinetd.d/telnet service telnet
{
disable = yes
...省略部分输出...
}
[root@localhost ~]# service xinetd restart
停止xinetd: [确定]
正在启动xinetd: [确定】
[root@localhost ~]# chkconfig telnet off
#先关闭Telnet服务的启动和自启动,保证不会对后面的实验产生影响
[root@localhost ~]# vi /etc/xinetd.d/telnet service telnet
{
disable = no
...省略部分输出...
}
[root@localhost ~]# service xinetd restart
停止xinetd: [确定]
正在启动xinetd: [确定】
#然后启动Telnet服务
[[email protected] ~] # chkconfig --list | grep telnet
telnet:启用
#看到了吗?我们一开始已经把Telnet服务的自启动关闭了。后面的实验虽然只启动了#Telnet服务,但是该服务自动变为了自启动状态
这个实验说明了基于 xinetd 服务的启动和自启动命令之间是通用的,在当前系统中启动了服务,服务的自启动也会开启;关闭了服务的自启动,当前系统中的服务也会关闭。
14.5 Linux源码包服务管理
本节我们先学习源码包服务的启动管理,再来学习源码包服务的自启动管理,最后学习如何让源码包服务被系统服务管理命令识别。
源码包服务的启动管理
源码包服务中所有的文件都会安装到指定目录当中,并且没有任何垃圾文件产生(Linux 的特性),所以服务的管理脚本程序也会安装到指定目录中。源码包服务的启动管理方式就是在服务的安装目录中找到管理脚本,然后执行这个脚本。
问题来了,每个服务的启动脚本都是不一样的,我们怎么确定每个服务的启动脚本呢?还记得在安装源码包服务时,我们强调需要査看每个服务的说明文档吗(一般是 INSTALL 或 READEM)?在这个说明文档中会明确地告诉大家服务的启动脚本是哪个文件。
我们用 apache 服务来举例。一般 apache 服务的安装位置是 /usr/local/apache2/ 目录,那么 apache 服务的启动脚本就是 /usr/local/apache2/bin/apachectl 文件(查询 apache 说明文档得知)。启动命令如下:
[root@localhost ~]# /usr/local/apache2/bin/apachectl start|stop|restart|...
#源码包服务的启动管理
例如:
[root@localhost ~]# /usr/local/apache2/bin/apachectl start
#会启动源码包安装的apache服务
注意,不管是源码包安装的 apache,还是 RPM 包默认安装的 apache,虽然在一台服务器中都可以安装,但是只能启动一因为它们都会占用 80 端口。
源码包服务的启动方法就这一种,比 RPM 包默认安装的服务要简单一些。
源码包服务的自启动管理
源码包服务的白启动管理也不能依靠系统的服务管理命令,而只能把标准启动命令写入 /etc/rc.d/rc.local 文件中。系统在启动过程中读取 /etc/rc.d/rc.local 文件时,就会调用源码包服务的启动脚本,从而让该服务开机自启动。命令如下:
[root@localhost ~]# vi /etc/rc.d/rc.local
#修改自启动文件
#!/bin/sh
#This script will be executed *after* all the other init scripts.
#You can put your own initialization stuff in here if you don11
#want to do the full Sys V style init stuff.
touch /var/lock/subsys/local /usr/local/apache2/bin/apachectl start
#加入源码包服务的标准启动命令,保存退出,源码包安装的apache服务就被设为自启动了
让源码包服务被服务管理命令识别
在默认情况下,源码包服务是不能被系统的服务管理命令所识别和管理的,但是如果我们做一些设定,则也是可以让源码包服务被系统的服务管理命令所识别和管理的。不过笔者并不推荐大家这样做,因为这会让本来区别很明确的源码包服务和 RPM 包服务变得容易混淆,不利于系统维护和管理。
我们做一个实验,看看如何把源码包安装的 apache 服务变为和 RPM 包默认安装的 apache 服务一样,可以被 service、chkconfig、ntsysv 命令所识别。实验如下:
1) 卸载RPM包默认安装的apache服务
[root@localhost ~]# yum -y remove httpd
#卸载RPM包默认安装的apache服务,避免对实验产生影响(在生产服务器上慎用yum卸载,因为这有可能造成服务器崩溃)
[root@localhost ~]# service httpd start httpd:未被识别的服务
#因为服务被卸载,所以service命令不能识别httpd服务
2) 安装源码包的apache服务,并启动
#安装源码包的apache服务
[root@localhost ~]# /usr/local/apache2/bin/apachect1 start
[root@localhost ~]# netstat -tlun | grep 80
tcp 0 0 :::80 :::* LISTEN
#启动源码包安装的apache服务,查看端口确定已经启动
3) 让源码包安装的apache服务能被service命令管理启动
[root@localhost ~]# ln -s /usr/local/apache2/bin/apachectl /etc/±nit.d/apache
#service命令其实只是在/etc/init.d/目录中查找是否有服务的启动脚本,所以我们只需要做一个软链接,把源码包的启动脚本链接到/etc/init.d/目录中,就能被service命令所管理了。为了照顾大家的习惯,我把软链接文件命名为apache,注意这不是RPM包默认安装的apache服务
[root@localhost ~]# service apache restart
#虽然RPM包默认安装的apache服务被卸载了,但是service命令也能够生效
4) 让源码包安装的apache服务能被chkconfig命令管理自启动
[root@localhost ~]# vi /etc/init.d/apache
#修改源码包安装的apache服务的启动脚本(注意此文件是软链接,所以修改的还是源码包启动脚本)
#!/bin/sh
#
#chkconfig: 35 86 76
#指定httpd脚本可以被chkconfig命令所管理
#格式是:chkconfig:运行级别 启动顺序 关闭顺序
#这里我们让apache服务在3和5级别中能被chkconfig命令所管理,启动顺序是S86,关闭顺序是K76
#(自定顺序,不要和系统中已有的启动顺序冲突)
#description: source package apache
#说明,内容随意
#以上两句话必须加入,才能被chkconfig命令所识别 ...省略部分输出...
[root@localhost ~]# chkconfig --add apache
#让chkconfig命令能够管理源码包安装的apache服务
[root01ocalhost ~]# chkconfig --list | grep apache
apache 0:关闭 1:关闭 2:关闭 3:关闭 4:关闭 5:关闭 6:关闭
#很神奇吧,虽然RPM包默认安装的apache服务被删除了,但是chkconfig命令可以管理源码包安装的tapache服务
5) 让ntsysv命令可以管理源码包安装的apache服务
#ntsysv 命令其实和 chkconfig 命令使用同样的管理机制,也就是说,ntsysv 已经可以进行源码包安装 apache 服务的自启动管理了,如图 1 所示
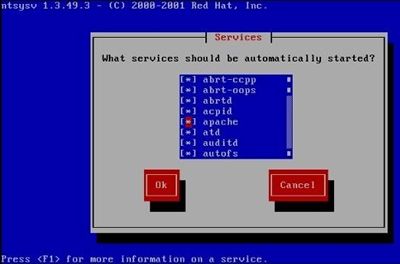
图 1 ntsysv 命令识别 apache
总结一下,如果想让源码包服务被service命令所识别和管理,则只需做一个软链接把启动脚本链接到 /etc/init.d/ 目录中即可。要想让源码包服务被 chkconfig 命令所是被,除了需要把服务的启动脚本链接到 /etc/init.d/ 目录中,还要修改这个启动脚本,在启动脚本的开头加入如下内容:
#chkconfig:运行级别 启动顺序 关闭
#description:说明
然后需要使用"chkconfig--add 服务名"的方式把服务加入 chkconfig 命令的管理中。命令格式如下:
[root@localhost ~]# chkconfig [选项][服务名]
选项:
- -add:把服务加入 chkconfig 命令的管理中;
- -del:把服务从 chkconfig 命令的管理中删除;
例如:
[root@localhost ~]# chkconfig -del httpd
#把apache服务从chkconfig命令的管理中删除
14.6 Linux常见服务类别及功能
Linux 中的服务数量非常多,我们在学习时一直使用 apache 服务作为实例。很多人会产生困惑:其他的服务都是干什么的呢?它们有什么作用呢?是不是必须启动的呢?
本节,我们就来介绍 Linux 中常见服务及它们各自的作用。
在生产服务器上,安装完 Linux 之后有一步重要的工作,就是服务优化。也就是关闭不需要的服务,只开启需要的服务。因为服务启动得越多,占用的系统资源就越多,而且被攻击的可能性也増加了。如果要进行服务优化,就需要知道这些服务都有什么作用,如表 1 所示。
| 服务名称 | 功能简介 | 建议 |
|---|---|---|
| acpid | 电源管理接口。如果是笔记本电脑用户,则建议开启,可以监听内核层的相关电源事件 | 开启 |
| anacron | 系统的定时任务程序。是 cron 的一个子系统,如果定时任务错过了执行时间,则可以通过 anacron 继续唤醒执行 | 关闭 |
| alsasound | alsa 声卡驱动。如果使用 alsa 声卡,则开启 | 关闭 |
| apmd | 电源管理模块。如果支持 acpid,就不需要 apmd,可以关闭 | 关闭 |
| atd | 指定系统在特定时间执行某个任务,只能执行一次。如果需要则开启,但我们一般使用 crond 来执行循环定时任务 | 关闭 |
| auditd | 审核子系统。如果开启了此服务,那么 SELinux 的审核信息会写入 /var/log/audit/ audit.log 文件;如果不开启,那么审核信息会记录在 syslog 中 | 开启 |
| autofs | 让服务器可以自动挂载网络中其他服务器的共享数据,一般用来自动挂载 NFS 服务。如果没有 NFS 服务,则建议关闭 | 关闭 |
| avahi-daemon | avahi 是 zeroconf 协议的实现,它可以在没有 DNS 服务的局域网里发现基于 zeroconf 协议的设备和服务。除非有兼容设备或使用 zeroconf 协议,否则关闭 | 关闭 |
| bluetooth | 蓝牙设备支持。一般不会在服务器上启用蓝牙设备,关闭它 | 关闭 |
| capi | 仅对使用 ISND 设备的用户有用 | 关闭 |
| chargen-dgram | 使用 UDP 协议的 chargen server。其主要提供类似远程打字的功能 | 关闭 |
| chargen-stream | 同上 | 关闭 |
| cpuspeed | 可以用来调整 CPU 的频率。当闲置时,可以自动降低 CPU 频率来节省电量 | 开启 |
| crond | 系统的定时任务,一般的 Linux 服务器都需要定时任务来协助系统维护。建议开启 | 开启 |
| cvs | 一个版本控制系统 | 关闭 |
| daytime-dgram | 使用 TCP 协议的 daytime 守护进程,该协议为客户机实现从远程服务器获取日期和时间的功能 | 关闭 |
| daytime-slream | 同上 | 关闭 |
| dovecot | 邮件服务中 POP3/IMAP 服务的守护进程,主要用来接收信件。如果启动了邮件服务则开启:否则关闭 | 关闭 |
| echo-dgram | 服务器回显客户服务的进程 | 关闭 |
| echo-stream | 同上 | 关闭 |
| firstboot | 系统安装完成后,有一个欢迎界面,需要对系统进行初始设定,这就是这个服务的作用。既然不是第一次启动了,则建议关闭 | 关闭 |
| gpm | 在字符终端 (ttyl~tty6) 中可以使用鼠标复制和粘贴,这就是这个服务的功能 | 开启 |
| haldaemon | 检测和支持 USB 设备。如果是服务器则可以关闭,个人机则建议开启 | 关闭 |
| hidd | 蓝牙鼠标、键盘等蓝牙设备检测。必须启动 bluetooth 服务 | 关闭 |
| hplip | HP 打印机支持,如果没有 HP 打印机则关闭 | 关闭 |
| httpd | apache 服务的守护进程。如果需要启动 apache,就开启 | 开启 |
| ip6tables | IPv6 的防火墙。目前 IPv6 协议并没有使用,可以关闭 | 关闭 |
| iptables | 防火墙功能。Linux 中的防火墙是内核支持功能。这是服务器的主要防护手段,必须开启 | 开启 |
| irda | IrDA 提供红外线设备(笔记本电脑、PDA’s、手机、计算器等)间的通信支持。建议关闭 | 关闭 |
| irqbalance | 支持多核处理器,让 CPU 可以自动分配系统中断(IRQ),提高系统性能。目前服务器多是多核 CPU,请开启 | 开启 |
| isdn | 使用 ISDN 设备连接网络。目前主流的联网方式是光纤接入和 ADSL,ISDN 己经非常少见,请关闭 | 关闭 |
| kudzu | 该服务可以在开机时进行硬件检测,并会调用相关的设置软件。建议关闭,仅在需要时开启 | 关闭 |
| lvm2-monitor | 该服务可以让系统支持LVM逻辑卷组,如果分区采用的是LVM方式,那么应该开启。建议开启 | 开启 |
| mcstrans | SELinux 的支持服务。建议开启 | 开启 |
| mdmonitor | 该服务用来监测 Software RAID 或 LVM 的信息。不是必需服务,建议关闭 | 关闭 |
| mdmpd | 该服务用来监测 Multi-Path 设备。不是必需服务,建议关闭 | 关闭 |
| messagebus | 这是 Linux 的 IPC (Interprocess Communication,进程间通信)服务,用来在各个软件中交换信息。建议关闭 | 关闭 |
| microcode _ctl | Intel 系列的 CPU 可以通过这个服务支持额外的微指令集。建议关闭 | 关闭 |
| mysqld | MySQL 数据库服务器。如果需要就开启;否则关闭 | 开启 |
| named | DNS 服务的守护进程,用来进行域名解析。如果是 DNS 服务器则开启;否则关闭 | 关闭 |
| netfs | 该服务用于在系统启动时自动挂载网络中的共享文件空间,比如 NFS、Samba 等。 需要就开启,否则关闭 | 关闭 |
| network | 提供网络设罝功能。通过这个服务来管理网络,建议开启 | 开启 |
| nfs | NFS (Network File System) 服务,Linux 与 Linux 之间的文件共享服务。需要就开启,否则关闭 | 关闭 |
| nfslock | 在 Linux 中如果使用了 NFS 服务,那么,为了避免同一个文件被不同的用户同时编辑,所以有这个锁服务。有 NFS 时开启,否则关闭 | 关闭 |
| ntpd | 该服务可以通过互联网自动更新系统时间.使系统时间永远准确。需要则开启,但不是必需服务 | 关闭 |
| pcscd | 智能卡检测服务,可以关闭 | 关闭 |
| portmap | 用在远程过程调用 (RPC) 的服务,如果没有任何 RPC 服务,则可以关闭。主要是 NFS 和 NIS 服务需要 | 关闭 |
| psacct | 该守护进程支持几个监控进程活动的工具 | 关闭 |
| rdisc | 客户端 ICMP 路由协议 | 关闭 |
| readahead_early | 在系统开启的时候,先将某些进程加载入内存整理,可以加快启动速度 | 关闭 |
| readahead_later | 同上 | 关闭 |
| restorecond | 用于给 SELinux 监测和重新加载正确的文件上下文。如果开启 SELinux,则需要开启 | 关闭 |
| rpcgssd | 与 NFS 有关的客户端功能。如果没有 NFS 就关闭 | 关闭 |
| rpcidmapd | 同上 | 关闭 |
| rsync | 远程数据备份守护进程 | 关闭 |
| sendmail | sendmail 邮件服务的守护进程。如果有邮件服务就开启;否则关闭 | 关闭 |
| setroubleshoot | 该服务用于将 SELinux 相关信息记录在日志 /var/log/messages 中。建议开启 | 开启 |
| smartd | 该服务用于自动检测硬盘状态。建议开启 | 开启 |
| smb | 网络服务 samba 的守护进程。可以让 Linux 和 Windows 之间共享数据。如果需要则开启 | 关闭 |
| squid | 代理服务的守护进程。如果需要则开启:否则关闭 | 关闭 |
| sshd | ssh 加密远程登录管理的服务。服务器的远程管理必须使用此服务,不要关闭 | 开启 |
| syslog | 日志的守护进程 | 开启 |
| vsftpd | vsftp 服务的守护进程。如果需要 FTP 服务则开启;否则关闭 | 关闭 |
| xfs | 这是 X Window 的字体守护进程,为图形界面提供字体服务。如果不启动图形界面,就不用开启 | 关闭 |
| xinetd | 超级守护进程。如果有依赖 xinetd 的服务,就必须开启 | 开启 |
| ypbind | 为 NIS (网络信息系统)客户机激活 ypbind 服务进程 | 关闭 |
| yum-updatesd | yum 的在线升级服务 | 关闭 |
14.7 影响Linux系统性能的因素有哪些?
评价 Linux 系统性能的好坏,大致可以从 Linux 完成任务的有效性、稳定性以及响应速度等方面进行考量。作为 Linux 系统管理员,可能经常会遇到系统不稳定、响应速度慢等问题。
例如,在 Linux 系统搭建了一个 Web 服务,就可能出现网页无法打开、打开速度慢等现象,而遇到这些问题时,有人可能会抱怨 Linux 系统不好,其实这些不过是表面现象。
要知道,操作系统在完成某个任务时,与系统自身设置、网络拓扑结构、路由设备、接入设备、物理线路等多个方面都密切相关,任何一个环节出现问题,都会影响整个系统的性能。
对于 Linux 系统来说,当运行应用程序出现问题时,要从应用程序本身、操作系统、服务器硬件和网络环境等方面综合排查,深度剖析问题出现在哪个部分,才能有针对性地解决。
那么,影响 Linux 系统性能的因素主要有哪些呢?
CPU
CPU 是操作系统稳定运行的根本,CPU 的速度与性能很大一部分决定了系统整体的性能,因此 CPU 数量越多、主频越高,服务器性能也就相对越好。
但亊实也并非完全如此,目前大部分 CPU 在同一时间内只能运行一个线程,超线程的处理器可以在同一时间运行多个线程,因而可以利用处理器的超线程特性提髙系统性能。
而在 Linux 系统下,只有运行 SMP 内核才能支持超线程,但是安装的 CPU 数量越多,从超线程获得的性能上的提高就越少。另外,Linux 内核会把多核的处理器当作多个单独的 CPU 来识别,例如两颗 4 核的 CPU 在 Linux 系统下会认为是 8 颗 CPU。
注意,从性能角度来讲,两颗 4 核的 CPU 和 8 颗单核的 CPU 并不完全等价,根据权威部门得出的测试结论,前者的整体性能要低于后者 25%〜30%。
在 Linux 系统中,邮件服务器、动态 Web 服务器等应用对 CPU 性能的要求相对较高,因此对于这类应用,要把 CPU 的配置和性能放在主要位置。
内存
内存的大小也是影响 Linux 性能的一个重要的因素。内存太小,系统进程将被阻塞,应用也将变得缓慢,甚至失去响应;内存太大,会导致资源浪费。
Linux 系统采用了物理内存和虚拟内存的概念,虚拟内存虽然可以缓解物理内存的不足,但是占用过多的虚拟内存,应用程序的性能将明显下降。要保证应用程序的高性能运行,物理内存一定要足够大,但不应过大,否则会造成内存资源的浪费。
例如,在一个 32 位处理器的 Linux 操作系统上,超过 8GB 的物理内存都将被浪费。因此,要使用更大的内存,建议安装 64 位的操作系统,同时开启 Linux 的大内存内核支持。
不仅如此,由于处理器寻址范围的限制,在 32 位 Linux 操作系统上,应用程序单个进程最大只能使用 2GB 的内存。这样即使系统有更大的内存,应用程序也无法“享”用,解决的办法就是使用 64 位处理器,安装 64 位操作系统,在 64 位操作系统下,可以满足所有应用程序对内存的使用需求,几乎没有限制。
对内存性能要求比较的应用有打印服务器、数据库服务器和静态 Web 服务器等,因此对于这类应用,要把内存大小放在主要位置。
磁盘读写(I/O)能力
磁盘的 I/O 能力会直接影响应用程序的性能。比如说,在一个需要频繁读写的应用中,如果磁盘 I/O 性能得不到满足,就会导致应用的停滞。
不过,好在现今的磁盘都采用了很多方法来提高 I/O 性能,比如常见的磁盘 RAID 技术。
RAID 的英文全称为 Redundant Array of Independent Disks,翻译成中文为独立磁盘冗余阵列,简称磁盘阵列。RAID 通过把多块独立的磁盘(物理硬盘)按不同方式组合起来,形成一个磁盘组(逻辑硬盘),从而提供比单个硬盘更高的 I/O 性能和数据冗余。
通过 RAID 技术组成的磁盘组,就相当于一个大硬盘,用户可以对它进行分区格式化、建立文件系统等操作,跟单个物理硬盘一模一样,惟一不同的是 RAID 磁盘组的 I/O 性能比单个硬盘要高很多,同时对数据的安全性也有很大提升。
有关 RAID 更多的介绍,可阅读《Linux RAID(磁盘列阵)完全攻略》一节做深入了解。
网络带宽
Linux 下的各种应用,一般都是基于网络的,因此网络带宽也是影响性能的一个重要因素,低速的、不稳定的网络将导致网络应用程序的访问阻塞;而稳定、高速的带宽,可以保证应用程序在网络上畅通无阻地运行。
幸运的是,现在的网络一般都是千兆带宽,或者光纤网络,带宽问题对应用程序性能造成的影响也在逐步降低。
通过对以上 4 个方面的讲述,不难看出,各个方面之间都是相互依赖的,不能孤立地从某个方面来排查问题。换句话说,当一个方面出现性能问题时,往往会引发其他方面出现问题。
例如,大量的磁盘读写势必消耗 CPU 和 I/O 资源,而内存的不足会导致频繁地进行内存页写入磁盘、磁盘写到内存的操作,造成磁盘 I/O 瓶颈,同时大量的网络流量也会造成 CPU 过载。总之,在处理性能问题时,应纵观全局,从各个方面进行综合考虑。
14.8 Linux分析系统性能(sar命令)
sar 命令很强大,是分析系统性能的重要工具之一,通过该命令可以全面地获取系统的 CPU、运行队列、磁盘读写(I/O)、分区(交换区)、内存、CPU 中断和网络等性能数据。
sar 命令的基本格式如下:
[root@localhost ~]# sar [options] [-o filename] interval [count]
此命令格式中,各个参数的含义如下:
- -o filename:其中,filename 为文件名,此选项表示将命令结果以二进制格式存放在文件中;
- interval:表示采样间隔时间,该参数必须手动设置;
- count:表示采样次数,是可选参数,其默认值为 1;
- options:为命令行选项,由于 sar 命令提供的选项很多,这里不再一一介绍,仅列举出常用的一些选项及对应的功能,如表 1 所示。
| sar命令选项 | 功能 |
|---|---|
| -A | 显示系统所有资源设备(CPU、内存、磁盘)的运行状况。 |
| -u | 显示系统所有 CPU 在采样时间内的负载状态。 |
| -P | 显示当前系统中指定 CPU 的使用情况。 |
| -d | 显示系统所有硬盘设备在采样时间内的使用状态。 |
| -r | 显示系统内存在采样时间内的使用情况。 |
| -b | 显示缓冲区在采样时间内的使用情况。 |
| -v | 显示 inode 节点、文件和其他内核表的统计信息。 |
| -n | 显示网络运行状态,此选项后可跟 DEV(显示网络接口信息)、EDEV(显示网络错误的统计数据)、SOCK(显示套接字信息)和 FULL(等同于使用 DEV、EDEV和SOCK)等,有关更多的选项,可通过执行 man sar 命令查看。 |
| -q | 显示运行列表中的进程数、进程大小、系统平均负载等。 |
| -R | 显示进程在采样时的活动情况。 |
| -y | 显示终端设备在采样时间的活动情况。 |
| -w | 显示系统交换活动在采样时间内的状态。 |
有关 sar 命令更多可用的选项及功能,可通过执行 man sar 命令查看。
【例 1】
如果想要查看系统 CPU 的整理负载状况,每 3 秒统计一次,统计 5 次,可以执行如下命令:
[root@localhost ~]# sar -u 3 5 Linux 2.6.32-431.el6.x86_64 (localhost) 10/25/2019 _x86_64_ (1 CPU) 06:18:23 AM CPU %user %nice %system %iowait %steal %idle 06:18:26 AM all 12.11 0.00 2.77 3.11 0.00 82.01 06:18:29 AM all 6.55 0.00 2.07 0.00 0.00 91.38 06:18:32 AM all 6.60 0.00 2.08 0.00 0.00 91.32 06:18:35 AM all 10.21 0.00 1.76 0.00 0.00 88.03 06:18:38 AM all 8.71 0.00 1.74 0.00 0.00 89.55 Average: all 8.83 0.00 2.09 0.63 0.00 88.46
此输出结果中,各个列表项的含义分别如下:
- %user:用于表示用户模式下消耗的 CPU 时间的比例;
- %nice:通过 nice 改变了进程调度优先级的进程,在用户模式下消耗的 CPU 时间的比例;
- %system:系统模式下消耗的 CPU 时间的比例;
- %iowait:CPU 等待磁盘 I/O 导致空闲状态消耗的时间比例;
- %steal:利用 Xen 等操作系统虚拟化技术,等待其它虚拟 CPU 计算占用的时间比例;
- %idle:CPU 空闲时间比例。
【例 2】
如果想要查看系统磁盘的读写性能,可执行如下命令:
[root@localhost ~]# sar -d 3 5 Linux 2.6.32-431.el6.x86_64 (localhost) 10/25/2019 _x86_64_ (1 CPU) 06:36:52 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util 06:36:55 AM dev8-0 3.38 0.00 502.26 148.44 0.08 24.11 4.56 1.54 06:36:55 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util 06:36:58 AM dev8-0 1.49 0.00 29.85 20.00 0.00 1.75 0.75 0.11 06:36:58 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util 06:37:01 AM dev8-0 68.26 6.96 53982.61 790.93 3.22 47.23 3.54 24.17 06:37:01 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util 06:37:04 AM dev8-0 111.69 3961.29 154.84 36.85 1.05 9.42 3.44 38.43 06:37:04 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util 06:37:07 AM dev8-0 1.67 136.00 2.67 83.20 0.01 6.20 6.00 1.00 Average: DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util Average: dev8-0 34.45 781.10 9601.22 301.36 0.78 22.74 3.50 12.07
此输出结果中,各个列表头的含义如下:
- tps:每秒从物理磁盘 I/O 的次数。注意,多个逻辑请求会被合并为一个 I/O 磁盘请求,一次传输的大小是不确定的;
- rd_sec/s:每秒读扇区的次数;
- wr_sec/s:每秒写扇区的次数;
- avgrq-sz:平均每次设备 I/O 操作的数据大小(扇区);
- avgqu-sz:磁盘请求队列的平均长度;
- await:从请求磁盘操作到系统完成处理,每次请求的平均消耗时间,包括请求队列等待时间,单位是毫秒(1 秒=1000 毫秒);
- svctm:系统处理每次请求的平均时间,不包括在请求队列中消耗的时间;
- %util:I/O 请求占 CPU 的百分比,比率越大,说明越饱和。
除此之外,如果想要查看系统内存使用情况,可以执行sar -r 5 3命令;如果要想查看网络运行状态,可执行sar -n DEV 5 3命令,等等。有关其它参数的用法,这里不再给出具体实例,有兴趣的读者可自行测试,观察运行结果。
14.9 Linux如何查看CPU运行状态?
CPU 是影响 Linux 性能的主要因素之一,本节将介绍几个可以用来查看 CPU 性能的命令。
Linux CPU性能分析:vmstat命令
vmstat 命令可以显示关于系统各种资源之间相关性能的简要信息,在 《Linux vmstat命令》一节中,我们已经对此命令的基本格式和用法做了详细的介绍,因此不再赘述,这里主要用它来看 CPU 的一个负载情况。
下面是 vmstat 命令在当前测试系统中的输出结果:
[root@localhost ~]# vmstat 2 3 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 8 247512 39660 394168 0 0 31 8 86 269 0 1 98 1 0 0 0 8 247480 39660 394172 0 0 0 0 96 147 4 0 96 0 0 0 0 8 247484 39660 394172 0 0 0 66 95 141 2 2 96 0 0
通过分析 vmstat 命令的执行结果,可以获得一些与当前 Linux 运行性能相关的信息。比如说:
- r 列表示运行和等待 CPU 时间片的进程数,如果这个值长期大于系统 CPU 的个数,就说明 CPU 不足,需要增加 CPU。
- swpd 列表示切换到内存交换区的内存数量(以 kB 为单位)。如果 swpd 的值不为 0,或者比较大,而且 si、so 的值长期为 0,那么这种情况下一般不用担心,不用影响系统性能。
- cache 列表示缓存的内存数量,一般作为文件系统缓存,频繁访问的文件都会被缓存。如果缓存值较大,就说明缓存的文件数较多,如果此时 I/O 中 bi 比较小,就表明文件系统效率比较好。
- 一般情况下,si(数据由硬盘调入内存)、so(数据由内存调入硬盘) 的值都为 0,如果 si、so 的值长期不为 0,则表示系统内存不足,需要增加系统内存。
- 如果 bi+bo 的参考值为 1000 甚至超过 1000,而且 wa 值较大,则表示系统磁盘 I/O 有问题,应该考虑提高磁盘的读写性能。
- 输出结果中,CPU 项显示了 CPU 的使用状态,其中当 us 列的值较高时,说明用户进程消耗的 CPU 时间多,如果其长期大于 50%,就需要考虑优化程序或算法;sy 列的值较高时,说明内核消耗的 CPU 资源较多。通常情况下,us+sy 的参考值为 80%,如果其值大于 80%,则表明可能存在 CPU 资源不足的情况。
总的来说,vmstat 命令的输出结果中,我们应该重点注意 procs 项中 r 列的值,以及 CPU 项中 us 列、sy 列和 id 列的值。
Linux CPU性能分析:sar命令
除了 vmstat 命令,sar 命令也可以用来检查 CPU 性能,它可以对系统的每个方面进行单独的统计。
注意,虽然使用 sar 命令会增加系统开销,不过这些开销是可以评估的,不会对系统性能的统计结果产生很大影响。
和 vmstat 命令一样,sar 命令的基本格式和用法已经在 《Linux sar命令》一节中做了详细的介绍,接下来直接学习如何使用 sar 命令查看 CPU 性能。
下面是 sar 命令对当前测试系统的 CPU 统计输出结果:
[root@localhost ~]# sar -u 3 5 Linux 2.6.32-431.el6.x86_64 (localhost) 10/28/2019 _x86_64_ (8 CPU) 04:02:46 AM CPU %user %nice %system %iowait %steal %idle 04:02:49 AM all 1.69 0.00 2.03 0.00 0.00 96.27 04:02:52 AM all 1.68 0.00 0.67 0.34 0.00 97.31 04:02:55 AM all 2.36 0.00 1.69 0.00 0.00 95.95 04:02:58 AM all 0.00 0.00 1.68 0.00 0.00 98.32 04:03:01 AM all 0.33 0.00 0.67 0.00 0.00 99.00 Average: all 1.21 0.00 1.35 0.07 0.00 97.37
此输出结果统计的是系统中包含的 8 颗 CPU 的整体运行状况,每项的输出都非常直观,其中最后一行(Average)是汇总行,是对上面统计信息的一个平均值。
需要指出的是,sar 输出结果中第一行包含了 sar 命令本身的统计消耗,因此 %user 列的值会偏高一点,但这并不会对统计结果产生很大影响。
另外,在一个多 CPU 的系统中,如果程序使用了单线程,就会出现“CPU 整体利用率不高,但系统应用响应慢”的现象,造成此现象的原因在于,单线程只使用一个 CPU,该 CPU 占用率为 100%,无法处理其他请求,但除此之外的其他 CPU 却处于闲置状态,进而整体 CPU 使用率并不高。
针对这个问题,可以使用 sar 命令单独查看系统中每个 CPU 的运行状态,例如:
[root@localhost ~]# sar -P 0 3 5 Linux 2.6.32-431.el6.x86_64 (localhost) 10/28/2019 _x86_64_ (8 CPU) 04:44:57 AM CPU %user %nice %system %iowait %steal %idle 04:45:00 AM 0 8.93 0.00 1.37 0.00 0.00 89.69 04:45:03 AM 0 6.83 0.00 1.02 0.00 0.00 92.15 04:45:06 AM 0 0.67 0.00 0.33 0.33 0.00 98.66 04:45:09 AM 0 0.67 0.00 0.33 0.00 0.00 99.00 04:45:12 AM 0 2.38 0.00 0.34 0.00 0.00 97.28 Average: 0 3.86 0.00 0.68 0.07 0.00 95.39
注意,sar 命令对系统中 CPU 的计数是从数字 0 开始的,因此上面执行的命令表示对系统中第一颗 CPU 的运行状态进行统计。如果想单独统计系统中第 5 颗 CPU 的运行状态,可以执行sar -P 4 3 5命令。
Linux CPU性能分析:iostat命令
iostat 命令主要用于统计磁盘 I/O 状态,但也能用来查看 CPU 的使用情况,只不过使用此命令仅能显示系统所有 CPU 的平均状态,无法向 sar 命令那样做具体分析。
使用 iostat 命令查看 CPU 运行状态,需要使用该命令提供的 -c 选项,该选项的作用是仅显示系统 CPU 的运行情况。例如:
[root@localhost ~]# iostat -c Linux 2.6.32-431.el6.x86_64 (localhost) 10/28/2019 _x86_64_ (8 CPU) avg-cpu: %user %nice %system %iowait %steal %idle 0.07 0.00 0.12 0.09 0.00 99.71
可以看到,此输出结果中包含的项和 sar 命令的输出项完全相同。
有关 iostat 命令的基本用法,由于不是本节重点,因为不再详细介绍。
Linux CPU性能分析:uptime命令
uptime 命令是监控系统性能最常用的一个命令,主要用来统计系统当前的运行状况。例如:
[root@localhost ~]# uptime 05:38:26 up 1:47, 2 users, load average: 0.12, 0.08, 0.08
该命令的输出结果中,各个数据所代表的含义依次是:系统当前时间、系统运行时长、当前登陆系统的用户数量、系统分别在 1 分钟、5 分钟和 15 分钟内的平均负载。
这里需要注意的是,load average 这 3 个输出值一般不能大于系统 CPU 的个数。例如,本测试系统有 8 个 CPU,如果 load average 中这 3 个值长期大于 8,就说明 CPU 很繁忙,负载很高,系统性能可能会受到影响;如果偶尔大于 8 则不用担心,系统性能一般不会受到影响;如果这 3 个值小于 CPU 的个数(如本例所示),则表示 CPU 是非常空闲的。
总的来说,本节介绍了 4 个可查看 CPU 性能的命令,但这些命令也仅能查看 CPU 是否繁忙、负载是否过大,无法知道造成这种现象的根本原因。因此,在明确判断出系统 CPU 出现问题之后,还要结合 top、ps 等命令,进一步检查出是哪些进程造成的。
另外要知道的是,引发 CPU 资源紧张的原因有多个,可能是应用程序不合理造成的,也可能是硬件资源匮乏引起的。因此,要学会具体问题具体分析,或者优化应用程序,或者增加系统 CPU 资源。
14.10 Linux如何查看内存的使用情况?
内存的管理和优化,是 Linux 系统性能优化的重要组成部分,换句话说,内存资源是否充足,会直接影响应用系统(包含操作系统和应用程序)的使用性能。
本节将介绍几个系统命令,通过它们,可以快速查看 Linux 系统中内存的使用状况。
Linux查看内存使用情况:free命令
free 是监控 Linux 内存使用状况最常用的命令之一,有关该命令的基本用法,已经在《Linux free命令》一节中做了详细介绍,所以不再赘述,这里重点给大家讲解如何使用 free 命令查看系统内存的使用情况。
下面是 free 命令在当前测试系统中的输出结果:
[root@localhost ~]# free -m total used free shared buffers cached Mem: 2004 573 1431 0 47 201 -/+ buffers/cache: 323 1680 Swap: 1983 0 1983
从输出结果可以看到,该系统共 2GB 内存,其中系统空闲内存还有 1431MB,并且 swap 交换分区还未使用,因此可以判断出当前系统的内存资源还非常充足。
除此之外,free 命令还可以实时地监控内存的使用状况,通过使用 -s 选项,可以实现在指定的时间段内不间断地监控内存的使用情况。例如:
[root@localhost ~]# free -m -s 5 total used free shared buffers cached Mem: 2004 571 1433 0 47 202 -/+ buffers/cache: 321 1683 Swap: 1983 0 1983 total used free shared buffers cached Mem: 2004 571 1433 0 47 202 -/+ buffers/cache: 321 1683 Swap: 1983 0 1983 #省略后续输出
要想实现动态地监控内存使用状况,除了使用 free 命令提供的 -s 选项,还可以借助 watch 命令。通过给 watch 命令后面添加需要运行的命令,watch 就会自行重复去运行这个命令(默认 2 秒执行一次),例如:
[root@localhost ~]# watch -n 3 -d free Every 3.0s: free Tue Oct 29 03:05:43 2019 total used free shared buffers cached Mem: 2052988 586504 1466484 0 49184 207360 -/+ buffers/cache: 329960 1723028 Swap: 2031608 0 2031608
上面执行的命令中,-n 选项用于执行重复执行的间隔时间,-d 选项用于在显示数据时,高亮显示变动了的数据。
Linux查看内存使用情况:vmstat命令
vmstat 命令在监控系统内存方面的功能很强大,有关此命令的基本用法,已经在《Linux vmstat命令》一节中做了详细介绍,这里重点讲解如何使用此命令查看内存的使用状况。
下面是执行 vmstat 命令的输出结果:
[root@localhost ~]# vmstat 2 3 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 1436128 53004 210744 0 0 7 0 13 14 0 0 100 0 0 1 0 0 1436112 53004 210744 0 0 0 0 128 226 0 0 100 0 0 0 0 0 1435988 53004 210744 0 0 0 0 144 220 1 0 99 0 0
对于内存的监控,我们只需要重点关注 swpd、si 和 so 这 3 列。从此输出结果可以看出,当前系统中,虚拟内存没有使用,硬盘和内存之间没有交换数据,可见内存资源处于空闲状态。
Linux查看内存使用情况:sar命令
sar 命令也可以用来监控 Linux 的内存使用状况,通过“sar -r”组合可以查看系统内存和交换空间的使用率。
有关 sar 命令的基本用法,可以阅读《Linux sar命令》一文做详细了解。
如下是执行“sar -r”命令的输出结果:
[root@localhost ~]# sar -r 2 3 Linux 2.6.32-431.el6.x86_64 (localhost) 10/29/2019 _x86_64_ (8 CPU) 04:54:20 AM kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit 04:54:22 AM 1218760 834228 40.63 53228 424908 738312 18.08 04:54:24 AM 1218744 834244 40.64 53228 424908 738312 18.08 04:54:26 AM 1218712 834276 40.64 53228 424908 738312 18.08 Average: 1218739 834249 40.64 53228 424908 738312 18.08
此输出结果中,各个参数表示的含义如下:
- kbmemfree:表示空闲的物理内存的大小;
- kbmemeused:表示已使用的物理内存的大小;
- %memused:表示已使用内存占总内存大小的百分比;
- kbbuffers:表示缓冲区所使用的物理内存的大小;
- kbcached:表示告诉缓存所使用的物理内存的大小;
- kbcommit 和 %commit:分别表示当前系统中应用程序使用的内存大小和百分比;
相比 free 命令,sar 命令的输出信息更加人性化,不仅给出了内存使用量,还给出了内存使用的百分比以及统计的平均值。比如说,仅通过 %commit 一项就可以得知,当前系统中的内存资源充足。
14.11 Linux如何查看硬盘的读写性能?
除了 CPU 和内存,硬盘读写(I/O)能力也是影响 Linux 系统性能的重要因素之一。本节将介绍几个可用来查看硬盘读写性能的系统命令,并教大家如何通过这些命令的输出结果,判断出当前系统中硬盘是否处于超负荷运转。
Linux查看硬盘读写性能:sar -d命令
《Linux sar命令》一节,已经对 sar 命令的基本用法做了详细的介绍,这里不再赘述,接下来主要讲解如何通过 sar -d 命令分析出硬盘读写的性能。
下面是执行 sar -d 命令的输出结果样例:
[root@localhost ~]# sar -d 3 5 Linux 2.6.32-431.el6.x86_64 (localhost) 10/25/2019 _x86_64_ (1 CPU) 06:36:52 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util 06:36:55 AM dev8-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 06:36:55 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util 06:36:58 AM dev8-0 1.00 0.00 12.00 12.00 0.00 0.00 0.00 0.00 06:36:58 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util 06:37:01 AM dev8-0 1.99 0.00 47.76 24.00 0.00 0.50 0.25 0.05 Average: DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util Average: dev8-0 1.00 0.00 19.97 20.00 0.00 0.33 0.17 0.02
结合以上输出结果,可以遵循如下标准来判断当前硬盘的读写(I/O)性能:
- 通常情况下 svctm 的大小和硬盘性能有关,其值小于 await。但需要注意的是,CPU、内存的负荷也会对 svctm 的值造成影响,过多的请求也会间接导致 svctm 值的增加。
- await 值通常会受到 svctm、I/O 队列长度以及 I/O 请求模式的影响,如果 svctm 的值和 await 很接近,则表示几乎没有 I/O 等待,当前硬盘的性能很好;如果 await 的值远高于 svctm,则表示 I/O 队列等待太长,系统上运行的应用程序将变慢,此时可以通过更换更快的硬盘来解决问题。
- %util 项也是衡量硬盘 I/O 性能的重要指标,即如果其值接近 100%,就表示硬盘产生的 I/O 请求太多,I/O 系统正在满负荷工作,长期这样会影响系统的性能。必要时,可以优化程序或者更换更大、更快的硬盘来解决这个问题。
Linux查看硬盘读写性能:iostat -d命令
通过执行 iostat -d 命令,也可以查看系统中硬盘的使用情况,如下是执行此命令的一个样例输出:
[root@localhost ~]# iostat -d 2 3 Linux 2.6.32-431.el6.x86_64 (localhost) 10/30/2019 _x86_64_ (8 CPU) Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn sda 5.29 337.11 9.51 485202 13690 Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn sda 1.00 8.00 16.00 16 32 Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn sda 0.00 0.00 0.00 0 0
此输出结果中,我们重点看后面 4 列,它们各自表示的含义分别是:
- Blk_read/s:表示每秒读取的数据块数;
- Blk_wrtn/s:表示每秒写入的数据块数;
- Blk_read:表示读取的所有块数;
- Blk_wrtn:表示写入的所有块数。
注意,此输出结果中,第一次输出的数据是系统从启动以来直到统计时的所有传输信息,从第二次输出的数据开始,才代表在指定检测时间段内系统的传输值。
根据 iostat 命令的输出结果,我们也可以从中判断出当前硬盘的 I/O 性能。比如说,如果 Blk_read/s 的值很大,就表示当前硬盘的读操作很频繁;同样,如果 Blk_wrtn/s 的值很大,就表示当前硬盘的写操作很频繁。对于 Blk_read 和 Blk_wrtn 的大小,没有一个固定的界限,不同的系统应用对应值的范围也不同。但如果长期出现超大的数据读写情况,通常是不正常的,一定程度上会影响系统性能。
不仅如此,iostat 命令还提供了统计指定硬盘 I/O 状况的方法,即使用 -x 选项。例如:
[root@localhost ~]# iostat -x /dev/sda 2 3 Linux 2.6.32-431.el6.x86_64 (localhost) 10/30/2019 _x86_64_ (8 CPU) avg-cpu: %user %nice %system %iowait %steal %idle 0.09 0.00 0.24 0.26 0.00 99.42 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util sda 2.00 0.56 2.92 0.44 206.03 7.98 63.56 0.03 9.99 5.31 1.79 avg-cpu: %user %nice %system %iowait %steal %idle 0.31 0.00 0.06 0.00 0.00 99.62 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 avg-cpu: %user %nice %system %iowait %steal %idle 0.50 0.00 0.06 0.00 0.00 99.44 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
此输出结果基本和 sar -d 命令的输出结果相同,需要额外说明的几个选项的含义如下:
- rrqm/s:表示每秒被合并的读操作数目(文件系统会对读取同一 block 块的请求进行合并)
- wrqm/s:表示每秒被合并的写操作数目;
- r/s:表示每秒完成读 I/O 设备的次数;
- w/s:表示每秒完成写 I/O 设备的次数;
- rsec/s:表示每秒读取的扇区数;
- wsec/s:表示每秒写入的扇区数;
Linux查看硬盘读写性能:vmstat -d命令
使用 vmstat 命令也可以查看有关硬盘的统计数据,例如:
[root@bogon ~]# vmstat -d 3 2 disk- ------------reads------------ ------------writes----------- -----IO------ total merged sectors ms total merged sectors ms cur sec sda 6897 4720 485618 71458 1256 1475 21842 9838 0 43 disk- ------------reads------------ ------------writes----------- -----IO------ total merged sectors ms total merged sectors ms cur sec sda 6897 4720 485618 71458 1256 1475 21842 9838 0 43
该命令的输出结果显示了硬盘的读(reads)、写(writes)以及 I/O 的使用状态。
以上主要讲解了如何通过命令查看当前系统中硬盘 I/O 的性能,其实影响硬盘 I/O 的因素是多方面的,例如应用程序本身、硬件设计、系统自身配置等等。
要想解决硬盘 I/O 的瓶颈,关键是要提高 I/O 子系统的执行效率。比如说,首先从应用程序上对硬盘读写性能进行优化,能够放到内存中执行的操作尽量别保存到硬盘里(内存读写效率要远高于硬盘读写效率);其次,还可以对硬盘存储方法进行合理规划,选择合适的 RAID 存储方式;最后,选择适合自身应用的文件系统,必要时可以使用裸设备提高硬盘的读写性能。
在裸设备上,数据可以直接读写,不必经过操作系统级别的缓存,还可以避免文件系统级别的维护开销(文件系统需要维护超级块、I-node 块等)以及操作系统的 cache 预读功能(减少了 I/O 请求)。