mybatis学习整理(用户手册)(完整的全面学习)
MyBatis 是什么?
MyBatis 是一款一流的支持自定义SQL、存储过程和高级映射的持久化框架。MyBatis 几乎消除了所有的JDBC 代码,也基本不需要手工去设置参数和获取检索结果。MyBatis 能够使用简单的XML 格式或者注解进行来配置,能够映射基本数据元素、Map 接口和POJOs(普通java 对象)到数据库中的记录。准备开始
所有的MyBatis 应用都以SqlSessionFactory 实例为中心。SqlSessionFactory 实例通过SqlSessionFactoryBuilder 来获得,SqlSessionFactoryBuilder 能够从XML 配置文件或者通过自定义编写的配置类(Configuration class),来创建一个SqlSessionFactory 实例。从XML 中创建SqlSessionFactory 实例
从XML 中创建SqlSessionFactory 实例非常简单。建议您使用类资源路径(classpathresource)来加载配置文件,但是您也能够使用任何方式,包括文本文件路径或者以file:// 开头URL 的方式。MyBatis 包括一个叫做Resources 的工具类(utility class),其中包含了一系列方法,使之能简单地从classpath 或其它地方加载配置文件。String resource = "org/mybatis/example/Configuration.xml";
Reader reader = Resources.getResourceAsReader(resource);
sqlMapper = new SqlSessionFactoryBuilder().build(reader);
XML 配置文件包含MyBatis 框架的核心设置,包括获取数据库连接的DataSource 实例,和包括决定事务作用域范围和控制的事务管理等。您将能够在后面的章节中找到详细的XML 配置,在这里我们先展示一个简单的例子:
虽然XML 配置文件中还有很多其它的配置细节,但是,上面的示例显示了最重要的部分。注意XML 配置文件的头部,会使用DTD 验证文档来验证该XML 配置文件。body 部分的environment元素,包含了事务管理和连接池配置。Mappers 元素指定了映射配置文件--包含SQL 语句和映射定义的XML 文件。
如何不使用XML 来创建SqlSessionFactory
如果您喜欢直接通过java 代码而不是通过XML 创建配置选项,或者想创建您自己的配置生成器。MyBatis 提供了一个完整的配置类(Configuration class),它提供了与XML 文件相同的配置选项。TransactionFactory transactionFactory = new JdbcTransactionFactory();
Environment environment =new Environment("development", transactionFactory, dataSource);
Configuration configuration = new Configuration(environment);
configuration.addMapper(BlogMapper.class);
SqlSessionFactory sqlSessionFactory =new SqlSessionFactoryBuilder().build(configuration);请注意,这种方式下的配置添加一个映射类(mapper class)。映射类是包含SQL 映射注解的Java 类,从而避免了使用XML。但是,由于注解的一些局限性以及MyBatis 映射的复杂性,XML 仍然是一些高级的映射功能(如嵌套连接映射,Nested Join Mapping)所必须的方式。基于这个原因,如果存在XML 文件,MyBatis 自动寻找并加载这个XML 文件。在这种情况下,BlogMapper.xml 将会被类路径下名称为BlogMapper.class 的类加载。详述请见后面章节。
从SqlSessionFactory 获取SqlSession
现在您已经创建了一个SqlSessionFactory(指上面的sqlMapper),正如它名字暗示那样,您可以通过它来创建一个SqlSession 实例。SqlSession 包含了所有执行数据库SQL 语句的方法。您能够直接地通过SqlSession 实例执行映射SQL 语句。例如:SqlSession session = sqlMapper.openSession();
try {
Blog blog = (Blog) session.selectOne(
"org.mybatis.example.BlogMapper.selectBlog", 101);
} finally {
session.close();
}虽然这种方法很有效,MyBatis 以前版本的用户对此也可能很熟悉,但现在有一个更简便的方式,那就是对给定的映射语句,使用一个正确描述参数与返回值的接口(如
BlogMapper.class),您就能更清晰地执行类型安全的代码,从而避免错误和异常。如:
SqlSession session = sqlSessionFactory.openSession();
try {
BlogMapper mapper = session.getMapper(BlogMapper.class);
Blog blog = mapper.selectBlog(101);
} finally {
session.close();
}现在,让我们一起探索它们究竟是如何执行的。
探索映射SQL 语句
此时,您可能想知道SqlSession 或者映射器类(Mapper class)是怎样执行的。映射SQL语句是一个很大的主题,该主题将可能占据本文档的大部分内容。但是,为了让您看到它是怎样运行的,这里举两个例子。在上面的例子中,映射语句已经在XML 配置文件或注解中定义。让我们首先来看看XML 配置文件,所有MyBatis 提供的功能特性都可以通过基于XML 映射配置文件配置来实现。如果您以前使用过MyBatis,对此就会很熟悉。但许多改进使XML 映射文件变得更简洁清晰。下面是一个基于XML 映射配置的例子,满足上述SqlSession 的调用。
这个简单的例子看起来有不少的开销,但它确实非常地轻巧,只要您喜欢,您可以在一个映射XML 文件中定义许多映射语句。虽然会有一些XML 头部和DOCTYPE 声明,但该文件余下的部分是自解(self explanatory,可理解为不加解释就能明白)的。它定义了映射语句的名称“selectBlog”,在命名空间“org.mybatis.example.BlogMapper”,允许您通过指定完整类名“org.mybatis.example.BlogMapper”来访问上面的例子:
Blog blog = (Blog) session.selectOne(
"org.mybatis.example.BlogMapper.selectBlog", 101);这非常类似java 中通过完整类名来调用方法,而这样做是有原因的。这个名称可以直接映射到一个具在相同命名空间的映射类,这个映射类有一个方法的名称、参数及返回类型都与select映射语句相匹配。正如您前面看到的,这使您很简单地调用映射类里的方法,下面是另外的一个例子:
BlogMapper mapper = session.getMapper(BlogMapper.class);
Blog blog = mapper.selectBlog(101);第二种方法有很多好处。第一,它不依赖于字符串,所以更安全。第二,如果您的IDE 有自动完成功能,您可以利用这功能很快导航到您的映射SQL 语句。第三,您不需要关注返回类型,不需要进行强制转换,因为使用BlogMapper 接口已经限定了返回类型,它会安全地返回。
关于命名空间
正如您看到的那样,命名空间能够进行接口绑定,即使您认为现在不会使用到它,但您应该按照这些准则来做。一旦使用了命名空间并且放入适当的java 包命名空间中将会使您的代码清晰,并提高MyBatis 的长期可用性。
名称解析: 为了减少大量地输入, MyBatis 对所有的配置元素,包括statements、resultmaps、caches 等使用下面的名称解析规则:
• 完整类名:(例如: “com.mypackage.MyMapper.selectAllThings”)可用来直接查找并使用。
• 短名称: (例如: “selectAllThings”)可用来引用明确的实体对象。但是,如果出现有两个或更多(例如“com.foo.selectAllThings 和com.bar.selectAllThings”)实体对象,您将收到一个错误报告(短名称含糊不清),因此,这时就必须使用完整类名。
package org.mybatis.example;
public interface BlogMapper {
@Select("SELECT * FROM blog WHERE id = #{id}")
Blog selectBlog(int id);
}对简单的映射语句,使用注解可以显得非常地清晰。但是java 注解本身的局限难于应付更复杂的语句。如果您准备要做某些复杂的事情,最好使用XML 文件来配置映射语句。
这将由您和您的项目小组来确定哪种方式是适合的,以一致的方式来定义映射语句是非常重要的。也就是说,您不会被限于仅用一种方式。您能够非常容易地从基于注解的映射语句移植到XML 配置文件中,反之亦然。
作用域和生命周期
理解到目前为止所讨论的类的作用域和生命周期是非常重要的。如果使用不当可导致严重的并发性问题。SqlSessionFactoryBuilder
这个类可以在任何时候被实例化、使用和销毁。一旦您创造了SqlSessionFactory 就不需要再保留它了。所以SqlSessionFactoryBuilder 实例的最好的作用域是方法体内(即一个本地方法变量)。您能重用SqlSessionFactoryBuilder 创建多个SqlSessionFactory 实例,但最好不要把时间、资源放在解析XML 文件上,而是要从中解放出来做最重要事情。SqlSessionFactory
一旦创建,SqlSessionFactory 将会存在于您的应用程序整个运行生命周期中。很少或根本没有理由去销毁它或重新创建它。最佳实践是不要在一个应用中多次创建SqlSessionFactory。这样做会被视为“没品味”。所是SqlSessionFactory 最好的作用域范围是一个应用的生命周期范围。这可以由多种方式来实现,最简单的方式是使用Singleton 模式或静态Singleton 模式。但这不是被广泛接受的最佳做法,相反,您可能更愿意使用像Google Guice 或Spring 的依赖注入方式。这些框架允许您创造一个管理器,用于管理SqlSessionFactory 的生命周期。
SqlSession
每个线程都有一个SqlSession 实例,SqlSession 实例是不被共享的,并且不是线程安全的。因此最好的作用域是request 或者method。决不要用一个静态字段或者一个类的实例字段来保存SqlSession 实例引用。也不要用任何一个管理作用域,如Servlet 框架中的HttpSession,来保存SqlSession 的引用。如果您正在用一个WEB 框架,可以把SqlSession 的作用域看作类似于HTTP 的请求范围。也就是说,在收到一个HTTP 请求,您可以打开一个SqlSession,当您把response 返回时,就可以把SqlSession 关闭。关闭会话是非常重要的,您应该要确保会话在一个finally 块中被关闭。SqlSession session = sqlSessionFactory.openSession();
try {
// do work
} finally {
session.close();
}在您的代码里都使用这一模式将保证所有的数据库资源被正确地关闭(假如您没有把您自己的数据库连接传递给MyBatis 管理,这就对MyBatis 表明您希望自己管理连接)。
Mapper 实例
Mappers 是创建来绑定映射语句的接口,该Mapper 实例是从SqlSession 得到的。因此,所有mapper 实例的作用域跟创建它的SqlSession 一样。但是,mapper 实例最好的作用域是method,也就是它们应该在方法内被调用,使用完即被销毁。并且mapper 实例不用显式地被关闭。虽然把mapper 实例保持在一个request 范围(与SqlSession 相似)不会产生太大的问题,但是您可能会发现,在这个层次上管理太多资源可能会失控。保持简单,就是让Mappers 保持在一个方法内。下面的例子演示了这种做法。SqlSession session = sqlSessionFactory.openSession();
try {
BlogMapper mapper = session.getMapper(BlogMapper.class);
// do work
} finally {
session.close();
}Mapper XML 配置
MyBatis 的XML 配置文件包含了设置和影响MyBatis 行为的属性。XML 配置文件的层次结构如下:• configuration
o properties
o settings
o typeAliases
o typeHandlers
o objectFactory
o plugins
o environments
environment
• transactionManager
• dataSource
o mappers
properties 元素
它们都是外部化,可替代的属性。可以配置在一个典型的Java 属性文件中,或者通过properties 元素的子元素进行配置。例如:
在整个配置文件中,这些属性能够被可动态替换(即使用占位符)的属性值引用,例如:
示例中的username 和password 将会被替换为配置在properties 元素中的相应值。driver和url 属性则会被config.properties 文件中的相应值替换。这里提供了大量的配置选项。这些属性也可以传递给sqlSessionFactoryBuilder.build()方法。例如:
SqlSessionFactory factory =sqlSessionFactoryBuilder.build(reader, props);
// ... or ...
SqlSessionFactory factory =sqlSessionFactoryBuilder.build(reader, environment, props);如果一个属性存在于多个地方,MyBatis 将使用下面的顺序加载:
• 首先读入properties 元素主体中指定的属性。• 然后会加载类路径或者properties 元素中指定的url 的资源文件属性。它会覆盖前面已经读入的重复属性。
• 通过方法参数来传递的属性将最后读取(即通过sqlSessionFactoryBuilder.build),同样也会覆盖从properties 元素指定的和resource/url 指定的重复属性。
因此最优先的属性是通过方法参数来传递的属性,然后是通过resource/url 配置的属性,最后是在MyBatis 的Mapper 配置文件中,properties 元素主体中指定的属性。
Settings 元素
Setting 元素下是些非常重要的设置选项,用于设置和改变MyBatis 运行中的行为。下面的表格列出了Setting 元素支持的属性、默认值及其功能。
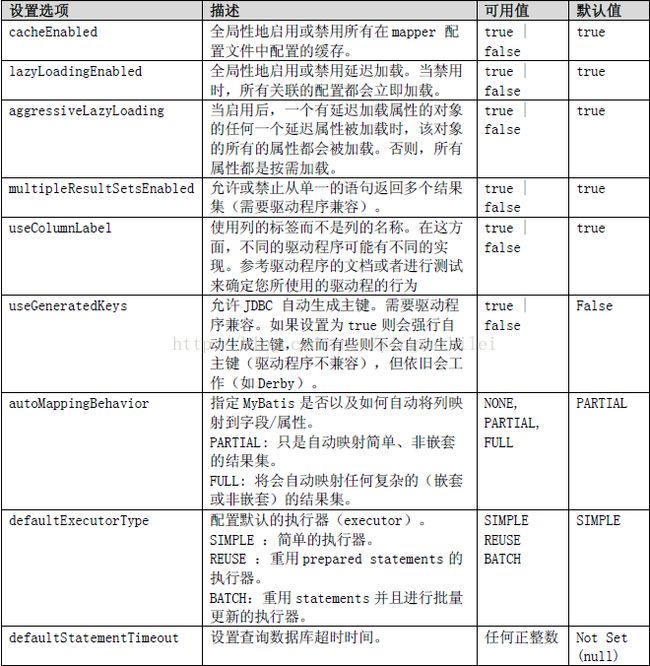
一个Settings 元素完整的配置例子如下:
typeAliases 元素
别名是一个较短的Java 类型的名称。这只是与XML 配置文件相关联,减少输入多余的完整类名。例如:
在这个配置中,您就可以在想要使用"domain.blog.Blog"的地方使用别名“Blog”了。对常用的java 类型,已经内置了一些别名支持。这些别名都是不区分大小写的。注意java
的基本数据类型,它们进行了特别处理,加了“_”前缀。
别名对应的java 类型
_byte byte _long long _short short_int int _integer int_double double _float float_boolean boolean string StringByte Byte Long Longshort Short Int Integerinteger Integer double DoubleFloat Float boolean BooleanDate Date decimal BigDecimal
typeHandlers 元素
每当MyBatis 设置参数到PreparedStatement 或者从ResultSet 结果集中取得值时,就会使用TypeHandler 来处理数据库类型与java 类型之间转换。下表描述了默认的TypeHandlers。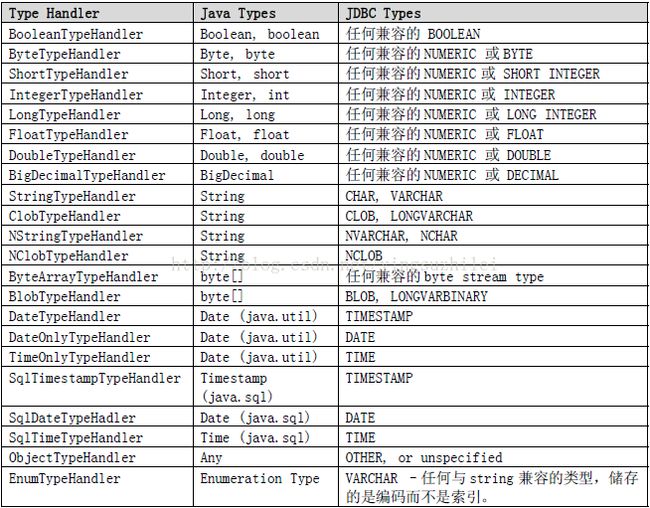
您能够重写类型处理器(type handlers),或者创建您自己的类型处理器去处理没有被支持的或非标准的类型。要做到这一点,只要实现TypeHandler 接口(org.mybatis.type),并且将您的TypeHandler 类映射到java 类型和可选的JDBC 类型即可。例如:
// ExampleTypeHandler.java
public class ExampleTypeHandler implements TypeHandler {
public void setParameter(
PreparedStatement ps, int i, Object parameter, JdbcType jdbcType)
throws SQLException {
ps.setString(i, (String) parameter);
}
public Object getResult(
ResultSet rs, String columnName)
throws SQLException {
return rs.getString(columnName);
}
public Object getResult(
CallableStatement cs, int columnIndex)
throws SQLException {
return cs.getString(columnIndex);
}
}// MapperConfig.xml
使用上面的TypeHandler 将会重写已经存在的用来处理java 的String 属性、VARCHAR 参数和结果集的类型处理器。注意,MyBatis 并不会通过数据库的元数据来确认类型,所以您必须指定它的一个类型处理器,用于将VARCHAR 字段的参数和结果映射到正确的类型上。这是因为MyBatis 在语句的执行之前都不知道它要处理的数据类型是什么。
objectFactory 元素
MyBatis 每次创建一个结果对象实例都会使用ObjectFactory 实例。使用默认的ObjectFactory 与使用默认的构造函数(或含参数的构造函数)来实例化目标类没什么差别。如果您想重写ObjectFactory 来改变其默认行为,那您能通过创造您自己的ObjectFactory 来做到。看下面的例子:
// ExampleObjectFactory.java
public class ExampleObjectFactory extends DefaultObjectFactory {
public Object create(Class type) {
return super.create(type);
}
public Object create(
MyBatis 3 - User Guide
17
Class type,
List constructorArgTypes,
List // MapperConfig.xml
ObjectFactory 接口非常简单,它包含两个create 的方法,一个是默认构造器,还有一个是含参数的构造器。最后的setProperties 方法用来配置ObjectFactory。在初始化您自己的ObjectFactory 实例之后,定义在objectFactory 元素主体中的属性会以参数的形式传递给setProperties 方法。
Plugins 元素
MyBatis 允许您在映射语句执行的某些点拦截方法调用。默认情况下,MyBatis 允许插件(plug-ins)拦截下面的方法:• Executor
(update, query, flushStatements, commit, rollback, getTransaction, close,isClosed)
• ParameterHandler
(getParameterObject, setParameters)
• ResultSetHandler
(handleResultSets, handleOutputParameters)
• StatementHandler
(prepare, parameterize, batch, update, query)
通过寻找完整的方法特征能够发现这些类方法的细节,以及在每个MyBatis 发布版本中的源代码中找到。假如您要做的不仅仅是监视方法的调用情况,您就应该清楚您将重写的方法的行为动作。如果您试图修改或者重写给定的方法,您很可能会改变MyBatis 的核心行为。这些都是比较底层的类和方法,所以要小心使用插件。
// ExamplePlugin.java
@Intercepts({@Signature(
type= Executor.class,
method = "update",
args = {MappedStatement.class,Object.class})})
public class ExamplePlugin implements Interceptor {
public Object intercept(Invocation invocation) throws Throwable {
return invocation.proceed();
}
public Object plugin(Object target) {
return Plugin.wrap(target, this);
}
public void setProperties(Properties properties) {
}
}// MapperConfig.xml
上面定义的插件将会拦截所有对Executor 实例update 方法的调用。Executor 实例是一个负责底层映射语句执行的内部对象。
重写配置类(Configuration Class)
除了能用插件方式修改MyBatis 的核心行为,您也可以完全重写配置类(ConfigurationClass)。简单地扩展它和重写内部的任何方法,然后作为参数传递给sqlSessionFactoryBuilder.build(myConfig)方法。再次提醒,这可能对MyBatis 行为产生严重影响,因此要小心。Environments 元素
MyBatis 能够配置多套运行环境,这有助于将您的SQL 映射到多个数据库上。例如,在您的开发、测试、生产环境中,您可能有不同的配置。或者您可能有多个共享同一schema 的生产用数据库,或者您想将相同的SQL 映射应用到两个数据库等等许多用例。但是请记住:虽然您可以配置多个运行环境,但是每个SqlSessionFactory 实例只能选择一个运行环境。因此,如果您想连接两个数据库,就需要创建两个SqlSessionFactory 实例,一个数据库对应一个SqlSessionFactory 实例。如果是三个数据库,那就创建三个实例,如此类推。这真的非常容易记住:每个数据库对应一个SqlSessionFactory 实例。
要指定哪个运行环境被创建,只需要简单地将运行环境作为可选参数传递给SqlSessionFactoryBuilder,下面是两个接受运行环境的方法:
SqlSessionFactory factory = sqlSessionFactoryBuilder.build(reader,environment);
SqlSessionFactory factory = sqlSessionFactoryBuilder.build(reader,environment,properties);
如果环境参数被忽略,那默认的环境配置将被加载,如下面:
SqlSessionFactory factory = sqlSessionFactoryBuilder.build(reader);
SqlSessionFactory factory =sqlSessionFactoryBuilder.build(reader,properties);
environments 元素定义了运行环境是怎么配置的:
注意这里关键的部分:
• 默认的运行环境ID,引用一个已经定义好的运行环境ID(例如:default=“development”)
• 每个定义的运行环境ID(例如:id=“development”)
• 事务管理器配置(例如: type=“JDBC”)
• 数据源配置(例如:type=“POOLED”)
默认的环境和环境ID 是自解(self explanatory)的,只要您喜欢,就可以随意取一个名字,只要确保默认的运行环境引用一个已定义的运行环境就可以了。
译者注:
……
事务管理器
MyBatis 有两种事务管理类型(即type=”[JDBC|MANAGED]”):• JDBC – 这个配置直接使用JDBC 的提交和回滚功能。它依赖于从数据源获得连接来管理事务的生命周期。
• MANAGED – 这个配置基本上什么都不做。它从不提交或者回滚一个连接的事务。而是让容器(例如:Spring 或者J2EE 应用服务器)来管理事务的生命周期。默认情况下,它会关闭连接,但是一些容器并不会如此,因此,如果您需要通过关闭连接来停止事务,将属性closeConnection 设置为false。例如:
这两个事务管理类型都不需要任何属性。然而它们都是类型别名,换句话说,您可以设置成指向己实现了TransactionFactory 接口的完整类名或者别名。
public interface TransactionFactory {
void setProperties(Properties props);
Transaction newTransaction(Connection conn, boolean autoCommit);
}
实例化后,任何在XML 文件配置的属性都将传递给setProperties()方法。在您的实现中还需要创建一个非常简单的Transaction 接口的实现:
public interface Transaction {
Connection getConnection();
void commit() throws SQLException;
void rollback() throws SQLException;
void close() throws SQLException;
}
……
……
上面例子中,
通过这两个接口,您能够完全自定义MyBatis 如何来处理事务。
dataSource 元素
dataSource 元素使用标准的JDBC 数据源接口来配置JDBC 连接对象源。大部分MyBatis 应用都像上面例子那样配置一个数据源,但这不是必须的。需要认清的是,只有使用了延迟加载才需要数据源。
MyBatis 内置了三种数据源类型(如: type=”????”):
UNPOOLED – 这个类型的数据源实现只是在每次需要的时候简单地打开和关闭连接。虽然有点慢,但是对于不需要立即响应的简单的应用来说,不失为一种好的选择。不同的数据库在性能方面也会有所不同,因此对于一些数据库,不使用连接池时,这个配置就是比较理想的。
UNPOOLED 数据源有四个配置属性:
• driver – 指定JDBC 驱动器。
• url – 连接数据库实例的JDBC URL。
• username –登陆数据库的用户名。
• password - 登陆数据库的密码。
• defaultTransactionIsolationLevel – 指定连接的默认事务隔离级别。
另外,您也可以通过在属性前加前缀“driver”的方式,把属性传递给数据库驱动器,例如:
• driver.encoding=UTF8
这将会通过DriverManager.getConnection(url, driverProperties) 方法,将值是“UTF8”的属性“encoding”传递给数据库驱动器。
POOLED – 这个数据源的实现缓存了JDBC 连接对象,用于避免每次创建新的数据库连接时都初始化和进行认证,加快程序响应。并发WEB 应用通常通过这种做法来获得快速响应。另外,除了上面(UNPOOLED)的属性外,对POOLED 数据源,还有很多属性可以设置。
• poolMaximumActiveConnections – 在任何特定的时间内激活(能够被使用)的连接数量,默认是10。
• poolMaximumIdleConnections –在任何特定的时间内空闲的连接数。
• poolMaximumCheckoutTime – 在连接池被强行返回前,一个连接能够“检出”的总时间。默认是20000ms(20 秒)。
• poolTimeToWait – 这是一上比较底层的设置,如果连接占用了很长时间,能够给连接池一个机会去打印日志,并重新尝试连接。默认是20000ms(20 秒)。
• poolPingQuery –Ping Query 是发送给数据库的Ping 信息,测试数据库连接是否良好和是否准备好了接受请求。默认值是“NO PING QUERY SET”,让大部分数据库都不使用
Ping,返回一个友好的错误信息(译者注:MyBatis 通过向数据执行SQL 语句来确定与数据库连接状况)。
• poolPingEnabled – 这是允许或者禁ping query 的开关。如果允许,您同时也要用一条可用的(并且应该是最高效的)SQL 语句来设置poolPingQuery 属性的值。默认是:
false(即禁止)。
• poolPingConnectionsNotUsedFor – 这个属性配置执行poolPingQuery 的间隔时间。通常设置为与数据库连接的超时时间,来避免不必要的pings 。默认是:0(允许所有连接随时进行ping 测试,当然只有poolPingEnabled 设置为true 才会生效)。JNDI – 这个数据源的配置是为了准备与像Spring 或应用服务器能够在外部或者内部配置数据
源的容器一起使用,然后在JNDI 上下文中引用它。这个数据源只需配置两个属性:
• initial_context – 这个属性被用来从InitialContext 中查找一个上下文。如:initialContext.lookup(initial_context),这个属性是可选的,如果忽略,那么数据源就会直接从InitialContext 中查找。
• data_source – 这个属性是引用一个能够被找到的数据源实例的上下文路径。它会查找根据initial_context 从initialContext 中搜寻返回的上下文。或者在initial_context 没有提供的情况下直接在InitialContext 中进行查找。
译者注:
Context context = (Context) initialContext.lookup(initial_context);//返回一个上下文
//Context context = (Context)initContext.lookup("java:/comp/env");
DataSource ds = (DataSource) context.lookup(data_source); //返回一个数据源
Connection conn = ds.getConnection();
//DataSource ds = (DataSource)context.lookup("jdbc/myoracle");
跟数据源的其它属性配置一样,可以通过在属性名前加“env.”的方式直接传递给InitialContext。例如:
• env.encoding=UTF8
这将会把属性“encoding”及它的值“UTF8”在InitialContext 实例化的时候传递给它的构造器。
Mappers 元素
现在,MyBatis 的行为属性都已经在上面的配置元素中配置好了,接下来开始定义映射SQL语句。但首先,我们需要告诉MyBatis 在哪里能够找到我们定义的映射SQL 语句。在这方面,JAVA 自动发现没有提供好的方法,因此最好的方法是告诉MyBatis 在哪里能够找到这些映射文件。您可以使用类资源路径或者URL(包括file:/// URLs),例如:// Using classpath relative resources
// Using url fully qualified paths
这些配置告诉MyBatis 在哪里找到SQL 映射文件。而其它的更详细的信息配置在每一个SQL映射文件里。这些将在下一章节里讨论。
SQL 映射XML 文件
MyBatis 真正强大之处就在这些映射语句,也就是它的魔力所在。对于它的强大功能,SQL 映射文件的配置却非常简单。如果您比较SQL 映射文件配置与JDBC 代码,您很快可以发现,使用SQL 映射文件配置可以节省95%的代码量。MyBatis 被创建来专注于SQL,但又给您自己的实现极大的空间。如果initial_context 没有配置,那么数据源就会直接从InitialContext 进行查找,如:
DataSource ds = (DataSource) initialContext.lookup(data_source);
SQL 映射XML 文件只有一些基本的元素需要配置,并且要按照下面的顺序来定义(in theorder that they should be defined):• cache –在特定的命名空间配置缓存。
• cache-ref – 引用另外一个命名空间配置的缓存.
• resultMap – 最复杂也是最强大的元素,用来描述如何从数据库结果集里加载对象。
• parameterMap – 不推荐使用! 在旧的版本里使用的映射配置,这个元素在将来可能会被删除,因此不再进行描述。
• sql – 能够被其它语句重用的SQL 块。
• insert –INSERT 映射语句
• update –UPDATE 映射语句
• delete –DELEETE 映射语句
• select –SELECT 映射语句
接下来的章节将会对每一个元素进行描述。
Select 元素
Select 是MyBatis 中最常用的元素之一。除非您把数据取回来,否则把数据放在数据库是没什么意义的,因此大部分的应用查询数据远多于修改数据。对每一次插入、修改、删除数据都可能伴有大量的查询。这是MyBatis 基本设计原则之一,也就是为什么把这么多的焦点和努力放在查询和结果集映射上。对简单的查询,select 元素的配置是相当简单的,如:这条语句叫做selectPerson,以int 型(或者Integer 型)作为参数,并返回一个以数据库列名作为键值的HashMap。
注意这个参数的表示方法:#{id}
它告诉MyBatis 生成PreparedStatement 参数。对于JDBC,像这个参数会被标识为“?”,然后传递给PreparedStatement,像这样:
// Similar JDBC code, NOT MyBatis…
String selectPerson = “SELECT * FROM PERSON WHERE ID=?”;
PreparedStatement ps = conn.prepareStatement(selectPerson);
ps.setInt(1,id);
当然,如果单独使用JDBC 去提取这个结果集并把结果集映射到对象上的话,则需要更多的代码,而这些,MyBatis 都已经为您做到了。关于参数和结果集映射,还有许多要学的,以后有专门的章节来讨论。
select 语句有很多的属性允许您详细配置每一条语句。
parameterType=”int”
parameterMap=”deprecated”
resultType=”hashmap”
resultMap=”personResultMap”
flushCache=”false”
useCache=”true”
timeout=”10000”
fetchSize=”256”
statementType=”PREPARED”
resultSetType=”FORWARD_ONLY”
>
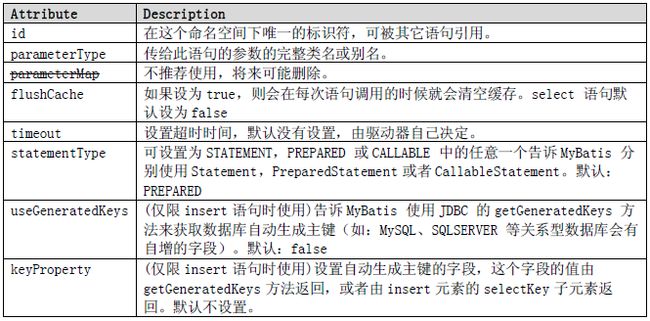
Insert、update、delete 元素
数据修改语句insert、update 和delete 的配置使用都非常相似:
下面是一些insert、update 和delete 语句例子。
insert into Author (id,username,password,email,bio)
values (#{id},#{username},#{password},#{email},#{bio})
update Author set
username = #{username},
password = #{password},
email = #{email},
bio = #{bio}
where id = #{id}
delete from Author where id = #{id}
正如您看到,insert 元素有更多一些的扩展属性及子元素,允许您使用多种方式自动生成主键。
首先,如果您使用的数据库支持自动生成主键(如:MySQL 和SQL Server),那么您就可以简单地将useGeneratedKeys 设置为”true”,然后使用keyProperty 设置您希望自动生成主键的字段就可以了。例如,如果上面提到的Author 表使用一个字段自动生成主键,那么配置语句就可以修改为:
insert into Author (username,password,email,bio)
values (#{username},#{password},#{email},#{bio})
MyBatis 还有另外一种方式为不支持自动生成主键的数据库及JDBC 驱动来生成键值。下面展示一个能够随机生成ID 的例子(也许您不会这么做,这仅仅是演示MyBatis 的功
能):
select CAST(RANDOM()*1000000 as INTEGER) a from SYSIBM.SYSDUMMY1
insert into Author
(id, username, password, email,bio, favourite_section)
values
(#{id}, #{username}, #{password}, #{email}, #{bio},
#{favouriteSection,jdbcType=VARCHAR}
)
在上面的例子中,selectKey 语句首先会执行,Author 表的ID 首先会被设值,然后才会调用insert 语句。这相当于在您的数据库中自动生成键值,不需要编写复杂的java 代码。
selectKey 元素描述如下:

Sql 元素
这个元素用来定义能够被其它语句引用的可重用SQL 语句块。例如:这个SQL 语句块能够被其它语句引用,如:
参数(Parameters)
在前面的语句中,我们可以看到一些例子中简单的参数(用于代入SQL 语句中的可替换变量,如#{id})。参数是MyBatis 中非常强大的配置属性,基本上,90%的情况都会用到,如:上面的例子演示了一个非常简单的命名参数映射,parameterType 被设置为“int”。参数可以设置为任何类型。像基本数据类型或者像Integer 和String 这样的简单的数据对象,(因为没有相关属性)将使用全部参数值。而如果传递的是复杂对象(一般是指JavaBean),那情况就有
所不同。例如:
insert into users (id, username, password)
values (#{id}, #{username}, #{password})
如果参数对象User 被传递给SQL 语句,那么将会搜寻PreparedStatement 里的id,username和password 属性,并被User 对象里相应的属性值替换。这种传递参数到语句的方式非常优雅和简单。但参数映射还在很多特性。首先,像MyBatis 其它部分一样,参数可以指定许多的数据类型。
#{property,javaType=int,jdbcType=NUMERIC}
像MyBatis 的其它部分一样,这个javaType 是由参数对象决定,除了HashMap 以外。然后这个javaType 应该确保指定正确的TypeHandler 被使用。
Note:如果传递了一个空值,那这个JDBC Type 对于所有JDBC 允许为空的列来说是必须的。您可以研读一下关于PreparedStatement.setNull()的JavaDocs 文档。
对于需要自定义类型处理,您也可以指定一个特殊的TypeHandler 类或者别名,如:
#{age,javaType=int,jdbcType=NUMERIC,typeHandler=MyTypeHandler}
当然,这看起来更加复杂了,不过,这种情况比较少见。对于数据类型,可以使用numericScale 来指定小数位的长度。
#{height,javaType=double,jdbcType=NUMERIC,numericScale=2}
最后,mode属性允许您指定IN、OUT 或INOUT 参数。如果参数是OUT 或INOUT,参数对象属的实际值将会改变,正如您希望调用一个输出参数。如果mode=OUT (或者INOUT),并且jdbcType=CURSOR (如Oracle 的REFCURSOR),您必须指定一个resultMap映射结果集给这个参数类型。注意这里的javaType 类型是可选的,如果为空值而jdbcType =CURSOR 的话,则会自动地设给ResultSet。
#{department,
mode=OUT,
jdbcType=CURSOR,
javaType=ResultSet,
resultMap=departmentResultMap}
MyBatis 也支持像structs 这样高级的数据类型,但当您把mode 设置为out 的时候,您必须把类型名告诉执行语句。例如:
#{middleInitial,
mode=OUT,
jdbcType=STRUCT,
jdbcTypeName=MY_TYPE,
resultMap=departmentResultMap}
尽管有这些强大的选项,但是大多数情况下您只需指定属性名,MyBatis 将会识别其它部分的设置。最多就是给可以为null 值的列指定jdbcType:
#{firstName}
#{middleInitial,jdbcType=VARCHAR}
#{lastName}
字符串替换
默认的情况下,使用#{}语法会促使MyBatis 生成PreparedStatement并且安全地设置PreparedStatement 参数(=?)值。尽量这是安全、快捷并且是经常使用的,但有时候您可能想直接未更改的字符串代入到SQL 语句中。比如说,对于ORDER BY,您可以这样使用ORDER BY ${columnName}这样MyBatis 就不会修改这个字符串了。
警告: 这种不加修改地接收用户输入并应用到语句的方式,是非常不安全的。这使用户能够进行SQL注入,破坏代码。所以,要么这些字段不允许用户输入,要么用户每次输入后都进行检测和规避。
resultMap 元素
resultMap元素是MyBatis中最重要最强大的元素。与使用JDBC从结果集获取数据相比,它可以省掉90%的代码,也可以允许您做一些JDBC不支持的事。事实上,要写一个类似于连结映射(join mapping)这样复杂的交互代码,可能需要上千行的代码。设计ResultMaps 的目的,就是只使用简单的配置语句而不需要详细地处理结果集映射,对更复杂的语句除了使用一些必须的语句描述以外,就不需要其它的处理了。您可能已经看到过这样简单映射语句,它并没有使用resultMap,例如:高级结果映射
MyBatis的创建基于这样一个思想:数据库并不是您想怎样就怎样的。虽然我们希望所有的数据库遵守第三范式或BCNF(修正的第三范式),但它们不是。如果有一个数据库能够完美映射到所有应用数据模型,也将是非常棒的,但也没有。结果集映射就是MyBatis为解决这些问题而提供的解决方案。例如,我们如何映射下面这条语句?您可能想要把它映射到一个智能的对象模型,包括由一个作者写的一个博客,有许多文章(Post,帖子),每个文章由0个或者多个评论和标签。下面是一个复杂ResultMap 的完整例子(假定作者、博客、文章、评论和标签都是别名)。仔细看看这个例子,但是不用太担心,我们会一步步地来分析,一眼看上去可能让人沮丧,但是实际上非常简单的
这个resultMap 的元素的子元素比较多,讨论起来比较宽泛。下面我们从概念上概览一下这个resultMap的元素。
resultMap
• constructor – 实例化的时候通过构造器将结果集注入到类中o idArg – ID 参数; 将结果集标记为ID,以方便全局调用
o arg – 注入构造器的结果集
• id –结果集ID,将结果集标记为ID,以方便全局调用
• result – 注入一个字段或者javabean 属性的结果
• association – 复杂类型联合; 许多查询结果合成这个类型
o 嵌套结果映射– associations 能引用自身, 或者从其它地方引用
• collection – 复杂类型集合
o 嵌套结果映射– collections 能引用自身, 或者从其它地方引用
• discriminator –使用一个结果值以决定使用哪个resultMap
o case – 基于不同值的结果映射
嵌套结果映射–case 也能引用它自身, 所以也能包含这些同样的元素。它也可以从外部引用resultMap
最佳实践: 逐步地生成resultMap,单元测试对此非常有帮助。如果您尝试一下子就生成像上面这样巨大的resultMap,可能会出错,并且工作起来非常吃力。从简单地开
始,再一步步地扩展,并且进行单元测试。使用框架开发有一个缺点,它们有时像是一个黑盒子。为了确保达到您所预想的行为,最好的方式就是进行单元测试。这对提交bugs也非常有用。
下一节,我们一步步地查看这些细节。
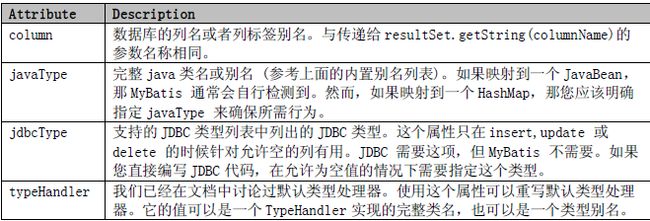
id, result 元素
这是最基本的结果集映射。id 和result 将列映射到属性或简单的数据类型字段(String,int, double, Date 等)。这两者唯一不同的是,在比较对象实例时id 作为结果集的标识属性。这有助于提高总体性能,特别是应用缓存和嵌套结果映射的时候。
id、result 属性如下:


支持如下的JDBC 类型:

Constructor 元素
当属性与DTO,或者与您自己的域模型一起工作的时候,许多场合要用到不变类。通常,包含引用,或者查找的数据很少或者数据不会改变的的表,适合映射到不变类中。构造器注入允许您在类实例化后给类设值,这不需要通过public方法。MyBatis 同样也支持private 属性和JavaBeans 的私有属性达到这一点,但是一些用户可能更喜欢使用构造器注入。构造器元素可以做到这点。考虑下面的构造器:
public class User {
//…
public User(int id, String username) {
//…
}
//…
}
为了将结果注入构造器,MyBatis 需要使用它的参数类型来标记构造器。Java 没有办法通过参数名称来反射获得。因此当创建constructor 元素,确保参数是按顺序的并且指定了正确的类型。
其它的属性与规则与id、result 元素的一样。
Association 元素
Association 元素处理“has-one”(一对一)这种类型关系。比如在我们的例子中,一个Blog 有一个Author。联合映射与其它的结果集映射工作方式差不多,指定property、column、javaType(通常MyBatis 会自动识别)、jdbcType(如果需要)、typeHandler。不同的地方是您需要告诉MyBatis 如何加载一个联合查询。MyBatis 使用两种方式来加载:
• Nested Select: 通过执行另一个返回预期复杂类型的映射SQL 语句(即引用外部定义好的SQL 语句块)。
• Nested Results: 通过嵌套结果映射(nested result mappings)来处理联接结果集(joined results)的重复子集。
首先,让我们检查一下元素属性。正如您看到的,它不同于普通只有select 和resultMap 属性的结果映射。

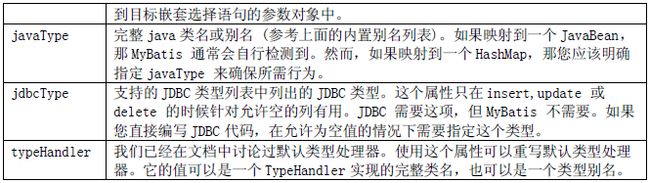
联合嵌套选择(Nested Select for Association)

例如:
我们使用两个select 语句:一个用来加载Blog,另一个用来加载Author。Blog 的resultMap 描述了使用“selectAuthor”语句来加载author 的属性。
如果列名和属性名称相匹配的话,所有匹配的属性都会自动加载。
译者注:
上面的例子,首先执行
blog_id;
title;
Author author
{
id;
username;
password;
email;
bio;
}
}
建议不要使用Batatis 的自动赋值,这样不能够清晰地知道要映射哪些属性,并且有时候还不能保证正确地映射数据库检索结果。
虽然这个方法简单,但是对于大数据集或列表查询,就不尽如人意了。这个问题被称为“N+1选择问题”(N+1 Selects Problem)。概括地说,N+1选择问题是这样产生的:
• 您执行单条SQL 语句去获取一个列表的记录( “+1”)。• 对列表中的每一条记录,再执行一个联合select 语句来加载每条记录更加详细的信息(“N”)。
译者注:
如:执行一条SQL 语句获得了10 条记录,这10 条记录的每一条再执行一条SQL 语句去加载更详细的信息,这就执行了10+1 次查询。
这个问题会导致成千上万的SQL 语句的执行,因此并非总是可取的。
上面的例子,MyBatis 可以使用延迟加载这些查询,因此这些查询立马可节省开销。然而,如果您加载一个列表后立即迭代访问嵌套的数据,这将会调用所有的延迟加载,因此性能会变得非常糟糕。
鉴于此,这有另外一种方式。
联合嵌套结果集(Nested Results for Association)
resultMap : 一个可以映射联合嵌套结果集到一个适合的对象视图上的ResultMap 。这是一个替代的方式去调用另一个select 语句。它允许您去联合多个表到一个结果集
里。这样的结果集可能包括冗余的、重复的需要分解和正确映射到一个嵌套对象视图的数据组。简言之,MyBatis 让您把结果映射‘链接’到一起,用来处理嵌套结果。举个例子会更好理解,例子在表格下方。
您已经在上面看到了一个非常复杂的嵌套联合的例子,接下的演示的例子会更简单一些。我们把Blog 和Author 表联接起来查询,而不是执行分开的查询语句:
注意到这个连接(join),要确保所有的别名都是唯一且无歧义的。这使映射容易多了,现在我们来映射结果集:
在上面的例子中,您会看到Blog 的作者(“author”)联合一个“authorResult”结果映射来加载Author 实例。
重点提示: id 元素在嵌套结果映射中扮演了非常重要的角色,您应该总是指定一个或多个属性来唯一标识这个结果集。事实上,如果您没有那样做,MyBatis 也会工作,但是会导致严重性能开销。选择尽量少的属性来唯一标识结果,而使用主键是最明显的选择(即使是复合主键)。
上面的例子使用一个扩展的resultMap 元素来联合映射。这可使Author结果映射可重复使用。然后,如果您不需要重用它,您可以直接嵌套这个联合结果映射。下面例子就是使用这样的方式:
在上面的例子中您已经看到如果处理“一对一”(“ has one”)类型的联合查询。但是对于“一对多”(“has many”)的情况如果处理呢?这个问题在下一节讨论。
Collection 元素
collection 元素的作用差不多和association 元素的作用一样。事实上,它们非常相似,以至于再对相似点进行描述会显得冗余,因此我们只关注它们的不同点。
继续我们上面的例子,一个Blog 只有一个Author。但一个Blog 有许多帖子(文章)。在Blog 类中,会像下面这样定义相应属性:
private List
映射一个嵌套结果集到一个列表,我们使用collection 元素。就像association 元素那样,我们使用嵌套查询,或者从连接中嵌套结果集。
集合嵌套选择(Nested Select for Collection)
首先我们使用嵌套选择来加载Blog 的文章。
一看上去这有许多东西需要注意,但大部分看起与我们在association元素中学过的相似。首先,您会注意到我们使用了collection元素,然后会注意到一个新的属性“ofType”。这个元素是用来区别JavaBean属性(或者字段)类型和集合所包括的类型。因此您会读到下面这段代码。
理解为: “一个名为posts,类型为Post 的ArrayList 集合( A collection of posts in an ArrayList of type Post)” 。
javaType 属性不是必须的,通常MyBatis 会自动识别,所以您通常可以简略地写成:
集合的嵌套结果集(Nested Results for Collection)
这时候,您可能已经猜出嵌套结果集是怎样工作的了,因为它与association 非常相似,只
不过多了一个属性“ofType”。
让我们看下这个SQL:
同样,我们把Blog 和Post 两张表连接在一起,并且也保证列标签名在映射的时候是唯一且无歧义的。现在将Blog 和Post 的集合映射在一起是多么简单:
再次强调一下,id 元素是非常重要的。如果您忘了或者不知道id 元素的作用,请先读一下上面association 一节。
如果希望结果映射有更好的可重用性,您可以使用下面的方式:
Note: 在您的映射中没有深度、宽度、联合和集合数目的限制。但应该谨记,在进行映射的时候也要考虑性能的因素。应用程序的单元测试和性能测试帮助您发现最好的方式可能要花很长时间。但幸运的是,MyBatis 允许您以后可以修改您的想法,这时只需要修改少量代码就行了。关于高级联合和集合映射是一个比较深入的课题,文档只能帮您了解到这里,多做一些实践,一切将很快变得容易理解。
Discriminator 元素
有时候一条数据库查询可能会返回包括各种不同的数据类型的结果集。Discriminator(识别器)元素被设计来处理这种情况,以及其它像类继承层次情况。识别器非常好理解,它就像java里的switch 语句。Discriminator定义要指定column和javaType属性。列是MyBatis 将要取出进行比较的值,javaType 用来确定适当的测试是否正确运行(即使是String 在大部分情况下也可以工作),例:
在这个例子中,MyBatis 将会从结果集中取出每条记录,然后比较它的vehicle type 的值。如果匹配任何discriminator 中的case,它将使用由case 指定的resultMap。这是排它性的,换句话说,其它的case 的resultMap 将会被忽略(除非使用我们下面说到的extended)。如果没有匹配到任何case,MyBatis 只是简单的使用定义在discriminator 块外面的resultMap。所以,如果carResult 像下面这样定义:
那么,只有doorCount属性会被加载。这样做是为了与识别器cases群组完全独立开来,哪怕它与上一层的resultMap 一点关系都没有。在刚才的例子里我们当然知道cars和vehicles的关系,a Car is-a Vehicle。因此,我们也要把其它属性加载进来。我们要稍稍改动一下resultMap:
现在,vehicleResult 和carResult 的所有属性都会被加载。可能有人会认为这样扩展映射定义有一点单调了,所以还有一种可选的更加简单明了的映射风格语法。例如:
记住:对于这么多的结果映射,如果您不指定任何的结果集,那么MyBatis 会自动地将列名与属性相匹配。所以上面所举的例子比实际中需要的要详细。尽管如此,大部分数据库有点复杂,并且它并不是所有情况都是完全可以适用的。
Cache 元素
MyBatis 包含一个强大的、可配置、可定制的查询缓存机制。MyBatis 3 的缓存实现有了许多改进,使它更强大更容易配置。默认的情况,缓存是没有开启的,除了会话缓存以外,会话缓存可以提高性能,且能解决循环依赖。开启二级缓存,您只需要在SQL映射文件中加入简单的一行:这句简单的语句作用如下:
• 所有映射文件里的select 语句的结果都会被缓存。
• 所有映射文件里的insert、update 和delete 语句执行都会清空缓存。
• 缓存使用最近最少使用算法(LRU)来回收。
• 缓存不会被设定的时间所清空。
• 每个缓存可以存储1024 个列表或对象的引用(不管查询方法返回的是什么)。
• 缓存将作为“读/写”缓存,意味着检索的对象不是共享的且可以被调用者安全地修改,而不会被其它调用者或者线程干扰。
所有这些特性都可以通过cache 元素进行修改。例如:
flushInterval="60000"
size="512"
readOnly="true"/>
这种高级的配置创建一个每60秒刷新一次的FIFO 缓存,存储512个结果对象或列表的引用,并且返回的对象是只读的。因此在不用的线程里的调用者修改它们可能会引用冲突。
可用的回收算法如下:
• LRU – 最近最少使用:移出最近最长时间内都没有被使用的对象。
• FIFO –先进先出:移除最先进入缓存的对象。
• SOFT – 软引用: 基于垃圾回收机制和软引用规则来移除对象(空间内存不足时才进行回
收)。
• WEAK – 弱引用: 基于垃圾回收机制和弱引用规则(垃圾回收器扫描到时即进行回
收)。
默认使用LRU。
flushInterval :设置任何正整数,代表一个以毫秒为单位的合理时间。默认是没有设置,因此没有刷新间隔时间被使用,在语句每次调用时才进行刷新。
Size:属性可以设置为一个正整数,您需要留意您要缓存对象的大小和环境中可用的内存空间。默认是1024。
readOnly:属性可以被设置为true 或false。只读缓存将对所有调用者返回同一个实例。因此这些对象都不能被修改,这可以极大的提高性能。可写的缓存将通过序列化来返回一个缓存对象的拷贝。这会比较慢,但是比较安全。所以默认值是false。
使用自定义缓存
除了上面已经定义好的缓存方式,您能够通过您自己的缓存实现来完全重写缓存行为,或者通过创建第三方缓存解决方案的适配器。
这个例子演示了如果自定义缓存实现。由type 指定的类必须实现org.mybatis.cache.Cache接口。这个接口是MyBatis 框架比较复杂的接口之一,先给个示例:
public interface Cache {
String getId();
int getSize();
void putObject(Object key, Object value);
Object getObject(Object key);
boolean hasKey(Object key);
Object removeObject(Object key);
void clear();
ReadWriteLock getReadWriteLock();
}
要配置您的缓存,简单地添加一个公共的JavaBeans 属性到您的缓存实现中,然后通过cache元素设置属性进行传递,下面示例,将在您的缓存实现上调用一个setCacheFile(String file)方法。
您可以使用所有简单的JavaBeans 属性,MyBatis 会自动进行转换。
需要牢记的是一个缓存配置和缓存实例都绑定到一个SQL Map 文件命名空间。因此,所有的这个相同命名空间的语句也都和这个缓存绑定。语句可以修改如何与这个缓存相匹配,或者使用两个简单的属性来完全排除它们自己。默认情况下,语句像下面这样来配置:
cache-ref 元素
回想上一节,我们仅仅只是讨论在某一个命名空间里使用或者刷新缓存。但有可能您想要在不同的命名空间里共享同一个缓存配置或者实例。在这种情况下,您就可以使用cache-ref 元素来引用另外一个缓存。动态SQL(Dynamic SQL)
MyBatis 最强大的特性之一就是它的动态语句功能。如果您以前有使用JDBC或者类似框架的经历,您就会明白把SQL语句条件连接在一起是多么的痛苦,要确保不能忘记空格或者不要在columns列后面省略一个逗号等。动态语句能够完全解决掉这些痛苦。尽管与动态SQL一起工作不是在开一个party,但是MyBatis确实能通过在任何映射SQL语句中使用强大的动态SQL来改进这些状况。动态SQL元素对于任何使用过JSTL或者类似于XML之类的文本处理器的人来说,都是非常熟悉的。在上一版本中,需要了解和学习非常多的元素,但在MyBatis 3 中有了许多的改进,现在只剩下差不多二分之一的元素。MyBatis使用了基于强大的OGNL表达式来消除了大部分元素。• if
• choose (when, otherwise)
• trim (where, set)
• foreach
if 元素
动态SQL 最常做的事就是有条件地包括where 子句。例如:这条语句提供一个带功能性的可选的文字。如果您没有传入标题,那么将返回所有激活的Blog。如果您传入了一个标题,那它就会查找与这个标题匹配的Blog(在这种情况下,您的参数值可能需要包括任何masking或者通配符)。
如果我们想要可选地根据标题或者作者查询怎么办?首先,我把语句的名称稍稍改一下,使得看起来更直观。然后简单地加上另外一个条件。
choose, when, otherwise 元素
有时候我们不想应用所有的条件,而是想从多个选项中选择一个。与java 中的switch 语句相似,MyBatis 提供了一个choose 元素。让我们继续使用上面的例子,但这次我们只搜索有提供查询标题的,或者只搜索有提供查询作者的数据。如果两者都没有提供,那只返回加精的Blog (可能是管理员有选择性的查询,而不是返回大量无意义的随机的Blog)。trim, where, set 元素
考虑一下我们上面提到的‘if ’的例子中,如果现在我们把‘ACTIVE=1’也做为条件,会发生什么情况。如果我们一个条件都不设置,会发生什么呢?语句最终可能会变成这个样子:
SELECT * FROM BLOG
WHERE
这将会执行失败。如果只有第二个条件满足呢?语句最终会变成这样:
SELECT * FROM BLOG
WHERE
AND title like ‘someTitle’
这同样会执行失败。这个问题仅用条件很难简单地解决,如果您已经这么写了,那您可能以后永远都不想犯这样的错了。
MyBatis有个简单的方案能解决这里面90%的问题。如果where没有出现的时候,您可以自定一个。修改一下,就能完全解决:
where 元素知道插入“where”如果它包含的标签中有内容返回的话。此外,如果返回的内容以“AND” 或者“OR”开头,它会把“AND” 或者“OR”去掉。
如果where 元素的行为并没有完全按您想象的那样,您还可以使用trim 元素来自定义。例如,下面的trim 与where 元素实现相同功能:
…
overrides属性使用了管道分隔的文本列表来覆写,而且它的空白也不能忽略的。这样的结果是移出了指定在overrides 属性里字符,而在开头插入prefix属性中指定的字符。
译者注,下面的两种配置方法效果是一样的:
Foreach 元素
另一个动态SQL 经常使用到的功能是集合迭代,通常用在IN 条件句。例如:下面的使用SET 元素也类似。
译者注:
对上面这个映射SQL 语句的java 调用代码示例如下:
List
postList.add(2);
postList.add(3);
postList.add(4);
List
"selectPostIn", postList);
//将会查询出ID 是2、3、4 的文章。
foreach 元素非常强大,允许您指定一个集合,申明能够用在元素体内的项和索引变量。也允许您指定开始和结束的字符,也可以加入一个分隔符到迭代器之间。这个元素的聪明之处在于它不会意外地追加额外的分隔符。
注意: 您可以把一个List 实例或者一个数组作为一个参数对象传递给MyBatis。如果您这么做,MyBatis 会自动将它包装成一个Map,并以名字作为key。List 实例会以
“list”作为key,array 实例会以“ array” 作为key。关于XML 配置文件及XML 映射文件就讨论到这了,下一章节我们将详细讨论Java API。
Java API
现在您知道如何配置MyBatis 和生成映射,您已经收获良多。MyBatis 的Java API 让您的努力获得回报。正如您将看到的,相比JDBC,MyBatis 极大地简化了您的代码,并使您的代码保持清晰、容易理解和维护。MyBatis3 推出了一系列重大的改进来使SQL 映射更好地工作。目录结构
在我们深入Java API 之前,理解目录结构的最佳实践是非常重要的。MyBatis 非常灵活,您可以对您的文件做任何事,但是做为一个框架,总有一个首选的方式。让我们来看一下典型的应用目录结构:

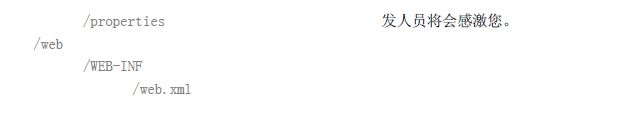
这章节的例子都是假定您按照上面的目录结构来存放文件。
SqlSessions
SqlSession 是与MyBatis 一起工作的基本java 接口。通过这个接口,您可以执行命令、获得映射和管理事务。我们很快就会讨论SqlSession,但首先我们要了解如果获得一个SqlSession实例。SqlSessions 是由SqlSessionFactory 实例创建的。SqlSessionFactory 包含从不同的方式创建SqlSessions 实例的方法。而SqlSessionFactory 又是SqlSessionFactoryBuilder 从XML 文件,注解或者手动编写java 配置代码中创建的。SqlSessionFactoryBuilder
SqlSessionFactoryBuilder 有五个build() 方法, 每个方法允许您从不同来源中创建SqlSessionSqlSessionFactory build(Reader reader)
SqlSessionFactory build(Reader reader, String environment)
SqlSessionFactory build(Reader reader, Properties properties)
SqlSessionFactory build(Reader reader, String env, Properties props)
SqlSessionFactory build(Configuration config)
前四个方法较为常用,它们使用一个引用XML 文件的Reader 实例,或者更具体地说是上面讨论的SqlMapConfig.xml 文件。可选参数是environment 和properties。Environment 决定加载的环境(包括数据源和事务管理)。例如:
…
…
…
…
如果您调用一个传递environment 参数的build 方法,MyBatis 将使用所传递的环境的配置。当然,如果您指定一个不可用的环境,您将收到一个错误。如果您调用的build 方法没有传递environment 参数,将使用默认的环境(像上面的例子中由default=“development”指定)。
如果您调用一个传递properties 实例的方法,MyBatis 将会加载传递进来的属性,并使这些属性在配置文件中生效。这些属性能够应用于配置文件中使用${propName}语法的地方。回想一下,属性可以从SqlMapConfig.xml 文件中被引用,也可以直接指定它。因此很重要的是要理解它们的优先顺序。在文档前面已经提到过,这里再次引用以供参考:
如果属性存在于多个地方,MyBatis 按照下面的顺序来加载:
• 首先读入properties 元素主体中指定的属性。
• 然后会加载类路径或者properties 元素中指定的url 的资源文件属性。它会覆盖前面已经读入的重复属性。
• 通过方法参数来传递的属性将最后读取(即通过sqlSessionFactoryBuilder.build),同样也会覆盖从properties 元素指定的和resource/url 指定的重复属性。
因此优先级最高的属性是通过方法参数来传递的属性,然后是通过resource/url 配置的属性,最后是在MyBatis 的映射配置文件中,properties 元素主体中指定的属性。
总得来说,前面四个方法大致相同,通过重载的方式允许您可选地指定environment 和/或者properties。这里是一个从SqlMapConfig.xml 文件中创建SqlSessionFactory 的例子:
String resource = "org/mybatis/builder/MapperConfig.xml";
Reader reader = Resources.getResourceAsReader(resource);
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
SqlSessionFactory factory = builder.build(reader);
注意,我们使用了Resources工具类,Resources工具类放在org.mybatis.io包中。Resources类,正如它的名字暗示,帮助我们从类路径、文件系统或者WEB URL加载资源。浏览一下这个类的源代码,或者使用您的IDE 查看,就会显露一系列有用的方法,简单列表如下:
URL getResourceURL(String resource)
URL getResourceURL(ClassLoader loader, String resource)
InputStream getResourceAsStream(String resource)
InputStream getResourceAsStream(ClassLoader loader, String resource)
Properties getResourceAsProperties(String resource)
Properties getResourceAsProperties(ClassLoader loader, String resource)
Reader getResourceAsReader(String resource)
Reader getResourceAsReader(ClassLoader loader, String resource)
File getResourceAsFile(String resource)
File getResourceAsFile(ClassLoader loader, String resource)
InputStream getUrlAsStream(String urlString)
Reader getUrlAsReader(String urlString)
Properties getUrlAsProperties(String urlString)
Class classForName(String className)
最后一个build 方法传递一个Configuration 的实例。Configuration 类包含您需要了解的关于SqlSessionFactory 实例的所有事情。Configuration 类对于内省的配置很有用,包括发现和操作SQL 映射。Configuration 类有您已经学过的所有配置开关,像java API 那样提供方法暴露出来。下面是一个例子,演示如何操作Configuration 实例,如何把这个实例传递给build()方法来创建SqlSessionFactory。
DataSource dataSource = BaseDataTest.createBlogDataSource();
TransactionFactory transactionFactory = new JdbcTransactionFactory();
Environment environment =
new Environment("development", transactionFactory, dataSource);
Configuration configuration = new Configuration(environment);
configuration.setLazyLoadingEnabled(true);
configuration.setEnhancementEnabled(true);
configuration.getTypeAliasRegistry().registerAlias(Blog.class);
configuration.getTypeAliasRegistry().registerAlias(Post.class);
configuration.getTypeAliasRegistry().registerAlias(Author.class);
configuration.addMapper(BoundBlogMapper.class);
configuration.addMapper(BoundAuthorMapper.class);
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
SqlSessionFactory factory = builder.build(configuration);
现在您拥有了一个SqlSessionFactory,您就能用它来创建SqlSession 实例了。
SqlSessionFactory
SqlSessionFactory 有六个方法用来创建SqlSession 实例。在一般情况下,选择其中一个方法要考虑下面几个方面:• 事务(Transaction): 您是否想为会话使用事务作用域,或者自动提交(通常是指数据库或者JDBC 驱动没有事务的情况下)
• 连接(Connection): 您想从配置数据源获得一个连接,还是想自己提供一个?
• 执行(Execution): 您想让MyBatis 重复使用用PreparedStatements 还是希望批量更新(包括插入和删除)?
重载的openSession()方法集,允许您选择任何一种有意义的组合。
SqlSession openSession()
SqlSession openSession(boolean autoCommit)
SqlSession openSession(Connection connection)
SqlSession openSession(TransactionIsolationLevel level)
SqlSession openSession(ExecutorType execType,TransactionIsolationLevel level)
SqlSession openSession(ExecutorType execType)
SqlSession openSession(ExecutorType execType, boolean autoCommit)
SqlSession openSession(ExecutorType execType, Connection connection)
Configuration getConfiguration();
默认的openSession()方法不需要参数,创建的SqlSession 有以下特征:
• 将会启用一个事务作用域(即不会自动提交)
• 一个连接对象将从正在生效的运行环境所配置的数据源实例中获得
• 事务隔离级别是由驱动或数据源使用的默认级别
• PreparedStatements 不会被重用,也不会进行批量更新
大部分方法自身都是很容易理解的。要启用自动提交,传入“true”值给可选参数autoCommit。要使用自己的连接,可以传入一个连接实例给参数connection。注意,没有提供重
载的方法同时传入Connection 和autoCommit 参数,因为MyBatis 将会使用所提供的连接对象正在使用的设置。MyBatis 使用java 枚举包装器作为事务隔离级别TransactionIsolationLevel,并有5 个JDBC 支持的级别:NONE、READ_UNCOMMITTED、READ_COMMITTED、REPEATABLE_READ、SERIALIZABLE,如果不设置,它们按默认方式工作。还有一个前面没有遇到过的新参数ExecutorType,这个枚举定义了三个值:
ExecutorType.SIMPLE
这个类型不做特殊的事情,它只为每个执行语句创建一个PreparedStatement。
ExecutorType.REUSE
这个类型的执行器(Executor)重用PreparedStatements。
ExecutorType.BATCH
这个执行器(Executor)将会批量执行更新语句,如果SELECT 在更新语句中被执行,要
根据需要进行区分,确保动作易于理解。
译者注:
1. 使用ExecutorType.SIMPLE
session = factory.openSession(ExecutorType.SIMPLE);
对于XML 映射配置文件中定义的所有SQL 语句在执行时都由Connection 创建一个PreparedStatement 对象来执行。即使在执行同一条SQL 语句,也要创建一个新的
PreparedStatement 对象。如:
执行N 次session.selectOne("selectBlog", #{id}),就要创建N 个PreparedStatement对象,了解一下数据库引擎工作原理,就知道这样会带来不小的开销。
2. 使用ExecutorType.REUSE
session = factory.openSession(ExecutorType.REUSE);
对于XML 映射配置文件中定义的所有SQL 语句在执行时都由Connection 创建一个PreparedStatement 对象来执行。但MyBatis 会把每条SQL 语句的PreparedStatement 对象缓存起来,等到下次再执行相同的SQL 语句,则使用缓存的PreparedStatement 对象。如,执行N 次session.selectOne("selectBlog", #{id}),只是创建一个PreparedStatement 对象。
3. 使用ExecutorType.BATCH
执行批量更新,把要进行批量更新的SQL 语句作为整体进行打包、编译、优化等,可减少网络流量等。
注意:SqlSessionFactory 中还有一个方法我们没有提到,那就是getConfiguration()。这个方法返回一个能够在运行期通过反射的方式得到的Configuration 实例。
注意: 如果您已经使用过以前的MyBatis 版本,您可能会回想起会话、事务和批量处理都是分开的。现在不再是这个样子,这三者都完美地包括在一个sesson 作用域里。您不需要分开处理事务和批量处理就能获得它们的全部好处。
SqlSession
正如前面提到的,SqlSession 实例是MyBatis 里最强大的类。SqlSession 实例里您会找到所有的执行语句、提交或者回滚事务、获得mapper 实例的方法。在SqlSession 类里有超过20 个方法,现在让我们把它们拆分成容易理解的分组。
语句执行方法组(Statement Execution Methods)
这些方法用来执行定义在SQL 映射XML 文件中的select , insert,update 和delete 语句。它们都很好理解,执行时使用语句的ID 和并传入参数对象(基本类型,javaBean,POJO 或者Map)。
Object selectOne(String statement, Object parameter)
List selectList(String statement, Object parameter)
int insert(String statement, Object parameter)
int update(String statement, Object parameter)
int delete(String statement, Object parameter)
selectOne 方法和selectList 方法的不同之处是selectOne 必须返回一个对象,如果返回一个以上的对象或者返回0 个对象,将会抛出异常。如果不能预知会返回多少对象,最好使用selectList 方法。如果您只是检测一下是否存在一个对象,可以使用SQL 语法中的COUNT 返回一个计数(0 或者1)。因为不是所有语句都需要传入参数的,因此这些方法可以重载为不需要参数的版本。
Object selectOne(String statement)
List selectList(String statement)
int insert(String statement)
int update(String statement)
int delete(String statement)
最后,它们还有三个select 方法的高级版本,允许您限定返回行记录的范围或者提供自定义的结果处理逻辑。这三个方法一般用来处理大量的数据集
List selectList
(String statement, Object parameter, RowBounds rowBounds)
void select
(String statement, Object parameter, ResultHandler handler)
void select
(String statement, Object parameter, RowBounds rowBounds,
ResultHandler handler)
RowBounds 参数促使MyBatis 跳过指定数量的记录,或者返回指定数量的结果集。RowBounds类有一个构造函数,设定偏移量或者指定条数,如果没进行设置,那就没有限制了。
int offset = 100;
int limit = 25;
RowBounds rowBounds = new RowBounds(offset, limit);
不同的驱动程序在这方面可以达到的效率是不同的。为了得到最好性能,使用SCROLL_SENSITIVE 或者SCROLL_INSENSITIVE 参数设置来返回结果集(换名话说,不要使用
FORWARD_ONLY)。
(译者注)默认情况下获得的结果集是不能更新的,且只有一个向前移动的光标。下面ResultHandler 参数允许您按照自己喜欢的方式对每条记录进行操作。您能把每条记录加入一个list、Map 或者Set,或者只是进行数量统计。您能让ResultHandler 做许多事情,它同样被MyBatis 用来生成结果集列表(result set lists)。
这个接口非常简单:
package org.mybatis.executor.result;
public interface ResultHandler {
void handleResult(ResultContext context);
}
ResultContext 参数允许您访问结果对象本身,创建一定数量的结果对象,或者使用返回值是Boolean 的stop()方法来停止加载更多的结果集。
事务控制方法组(Transaction Control Methods)
有四个控制事务作用域的方法,当然,如果您使用了自动提交或者正在使用的是外部事务管理器,那这四个方法就没什么作用。然而,如果您使用由Connection 实例管理的JDBC 的事务管理器,那这四个方法就非常管用:
void commit()
void commit(boolean force)
void rollback()
void rollback(boolean force)
默认地MyBatis 不会自动提交,除非它检测到数据库被insert,update 或者delete 改变。如果在哪里作了修改而没有使用这些方法,那么,您需要传入true 到commit 和rollback 方法,以保证它会提交。注意:您依然不能把一个会话或者一个使用外部事务的管理器强制设成自动提交模式。大部分时间,您不需要调用rollback()方法,因为如果您不调用commit 方法的话,MyBatis 会为您进行回滚。然而,如果您需要在一个有多个提交或者多个回滚可能的会话中获得更好(更细粒度)的控制,那么可以使用rollback 选项来实现。
清除会话层缓存(Clearing the Session Level Cache)
是一个可更新可滚动的结果集:Statement stmt = con.createStatement(
ResultSet.TYPE_SCROLL_INSENSITIVE,
ResultSet.CONCUR_UPDATABLE);
ResultSet rs = stmt.executeQuery("SELECT a, b FROM TABLE2");
void clearCache()
SqlSession 实例有一个本地缓存,这个缓存在每次提交,回滚和关闭时进行清除。如果不想在每次提交或者回滚时都清空缓存,可以明确地调用clearCache()方法来关闭。
确保SqlSession 已经关闭(Ensuring that SqlSession is Closed)void close()
最重要的事情是要确保关闭已经打开的会话,而最好的方式来保证是用下面的模式:SqlSession session = sqlSessionFactory.openSession();
try {
// following 3 lines pseudocod for “doing some work”
session.insert(…);
session.update(…);
session.delete(…);
session.commit();
} finally {
session.close();
}
注意: 就像SqlSessionFactory,您能够使用SqlSession 的getConfiguration()方法来获得Configuration 的实例。
Configuration getConfiguration()
使用Mappers
虽然前面提到的insert, update, delete 和select 方法很强大,但同时,它们也有点冗长,且不是类型安全的,IDE 或者单元测试也帮助发现不了其中的错误。我们在文章最开始就看到过使用Mappers 的例子,我们可以回顾一下。因此,一个最常用的方式是使用Mapper 接口来执行映射语句。一个Mapper 接口定义的方法要与SqlSession 执行的方法相匹配,即Mapper 接口方法名与映射SQL 文件中的映射语句ID 相同。下面例子演示了这种用法。
public interface AuthorMapper {
// (Author) selectOne(“selectAuthor”,5);
Author selectAuthor(int id);
// (List
List
// insert(“insertAuthor”, author)
void insertAuthor(Author author);
// updateAuthor(“updateAuhor”, author)
void updateAuthor(Author author);
// delete(“deleteAuthor”,5)
void deleteAuthor(int id);
}
总体来说,每个Mapper接口方法签名,都要与一个SqlSession 的方法相对应,方法名也要与映射语句的ID相对应。另外,返回的类型要与期望的结果类型一致。支持返回所有类型,包括:基本数据类型,
Maps,POJOs 和JavaBeans。
Mapper 接口不需要实现任何接口或者继承任何类,只要方法签名能够唯一地与映射语句相对应就可以了。
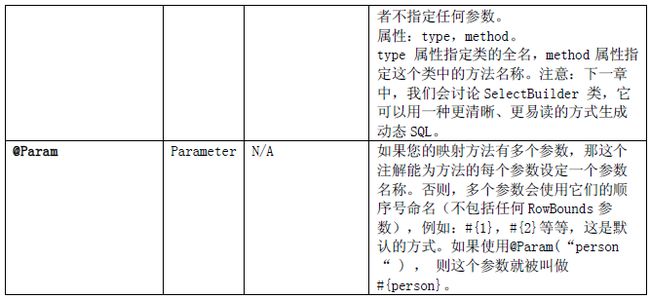
Mapper 接口可以继承其它接口。当您使用XML 绑定Mapper 接口时,要确保在同一命名空间里有您使用的语句。唯一的限制是不能同时有相同的方法签名在两个不同层次的接口。您能够传递多个参数给mapper 方法,如果这么做,要它们默认的参数列表位置来命名,例如这样:#{1}, #{2}等,如果您想改变参数的名字(多参数情况下),那您可以使用@Param(“paramName”) 注解的方式来传入参数。您同样也可以传递一个RowBounds 实例到方法,用来限定查询结果范围。
Mapper 注解
从很早的时候,MyBatis 就使用XML 驱动的框架,基于XML 配置,映射语句都定义在XML 中。在MyBatis3 中,还有新的可选方案。MyBatis3 建立于广泛且强大的java 配置API 之上。java 配置API 是基于XML 的MyBatis 配置的基础,同时也是基于注解的配置基础。注解提供了一个简单的方式来执行简单映射语句而不引入大量的开销。注意: 很不幸,java 注解在表现力与灵活性上是有限的。尽管花了很多时间来研究,设计与试验,但是强大的MyBatis 映射不能够建立在注解之上。C#属性则不会有这种限制。虽然如此,基于注解的配置并非没有好处的。
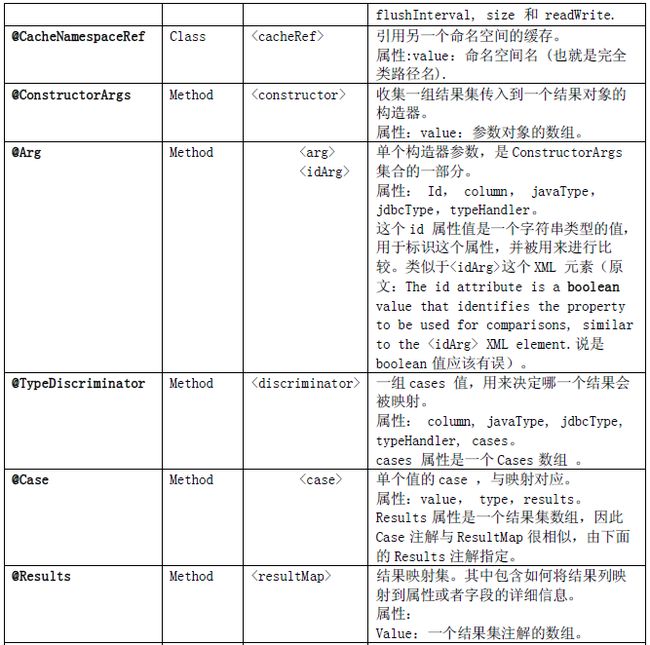
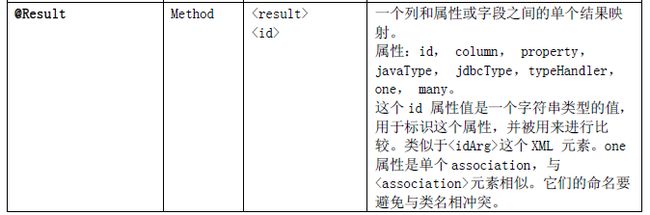
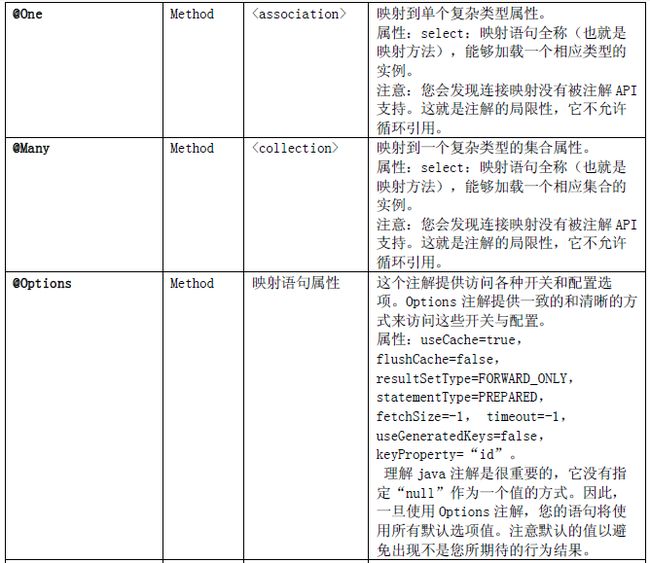
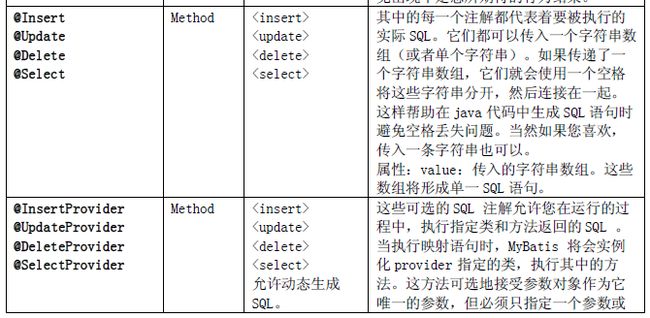
注解配置属性如下表:

SelectBuilder
Java 开发人员最讨厌的事情就是不得不在java 代码中嵌入SQL 语句。通常这样做的原因是SQL 必须动态生成,要不然,您可以把SQL 定义在外部文件或者存储过程中。正如您所看到的,MyBatis 在它的XML 映射功能中对动态SQL 的生成有一个很强大的解决方案。然而,有时候还是不得不在java 代码中生成SQL 语句字符串,这种情况下,MyBatis 还有一个功能可以帮助到您,用于减少加号、引号、换行、格式问题和在嵌套条件中处理额外的逗号与AND 连词……事实上,在java 中动态生成SQL 代码可以说是一场真正的噩梦。MyBatis3 引入一个稍微有点不同的概念来处理这个问题。我们可以生成一个类的实例,然后调用这个实例的方法来一步生成一条SQL 语句,最终的SQL 看起来更像是java 代码而不像SQL 代码。我们正在尝试不同的东西,最终结果接近一种领域特定语言(DSL),这也是java 目前形态要达到的目标。SelectBuilder 的秘密
SelectBuilder 类并没有什么神奇的地方,如果您不了解它如何工作,它对我们也没任何好处。SelectBuilder 使用一组静态导入方法和一个ThreadLocal 变量来启用一个能够很容易地组合条件并会注意所有SQL 格式的语法。例如:public String selectBlogsSql() {
BEGIN(); // Clears ThreadLocal variable
SELECT("*");
FROM("BLOG");
return SQL();
}
这只是一个您可能只选择静态生成SQL 的简单例子,下面是一个更复杂的例子:
private String selectPersonSql() {
BEGIN(); // Clears ThreadLocal variable
SELECT("P.ID, P.USERNAME, P.PASSWORD, P.FULL_NAME");
SELECT("P.LAST_NAME, P.CREATED_ON, P.UPDATED_ON");
FROM("PERSON P");
FROM("ACCOUNT A");
INNER_JOIN("DEPARTMENT D on D.ID = P.DEPARTMENT_ID");
INNER_JOIN("COMPANY C on D.COMPANY_ID = C.ID");
WHERE("P.ID = A.ID");
WHERE("P.FIRST_NAME like ?");
OR();
WHERE("P.LAST_NAME like ?");
GROUP_BY("P.ID");
HAVING("P.LAST_NAME like ?");
OR();
HAVING("P.FIRST_NAME like ?");
ORDER_BY("P.ID");
ORDER_BY("P.FULL_NAME");
return SQL();
}
如果使用字符串连接,上面的SQL 语句就会像下面这样来生成:
"SELECT P.ID, P.USERNAME, P.PASSWORD, P.FULL_NAME, "
"P.LAST_NAME,P.CREATED_ON, P.UPDATED_ON " +
"FROM PERSON P, ACCOUNT A " +
"INNER JOIN DEPARTMENT D on D.ID = P.DEPARTMENT_ID " +
"INNER JOIN COMPANY C on D.COMPANY_ID = C.ID " +
"WHERE (P.ID = A.ID AND P.FIRST_NAME like ?) " +
"OR (P.LAST_NAME like ?) " +
"GROUP BY P.ID " +
"HAVING (P.LAST_NAME like ?) " +
"OR (P.FIRST_NAME like ?) " +
"ORDER BY P.ID, P.FULL_NAME";
如果您喜欢上面这种语法,那您仍然可以使用它,但是它很容易出错,要注意在每行结束的地方都加一个空格。即使您喜欢上面的语法,下面的例子毫无争辩地比在java 代码中连接字符串更简单:
private String selectPersonLike(Person p){
BEGIN(); // Clears ThreadLocal variable
SELECT("P.ID, P.USERNAME, P.PASSWORD, P.FIRST_NAME, P.LAST_NAME");
FROM("PERSON P");
if (p.id != null) {
WHERE("P.ID like #{id}");
}
if (p.firstName != null) {
WHERE("P.FIRST_NAME like #{firstName}");
MyBatis 3 - User Guide
66
}
if (p.lastName != null) {
WHERE("P.LAST_NAME like #{lastName}");
}
ORDER_BY("P.LAST_NAME");
return SQL();
}
上面的例子有什么特别之处呢?如果您仔细观察的话,您会发现您不需要再担心是否会遇外地加入了重复的“AND”关键字,或者考虑要使用“WHERE”还是“AND”或者两者都使用。上面的例子生成一个查询所有PERSON记录的语句,查出与ID匹配的、或者与firstName匹配的、或者与lastName匹配的记录,或者是与上述三种任何组合条件相匹配的记录。SelectBuilder 会知道哪里需要添加“WHERE”,哪里需要使用“AND”,以及会注意字符串的连接。最重要的是,它几乎不管您调用这些方法的顺序(只有一个例外就是使用OR()方法)。
您可能已经关注到这两个方法:BEGIN() and SQL()。概括地说,每一个SelectBuilder 方法都要以BEGIN()开头,以SQL()结束,这也是生成SQL 的范围。在BEGIN()和SQL()之间,您可以提取SelectBuilder 的方法来一步一步分解您的逻辑。BEGIN()方法清除了ThreadLocal 变量以保证不会有先前残留的内容,SQL()方法装配自从调用BEGIN()后所有SelectBuilder 方法生成的SQL 语句。注意:BEGIN()方法有一个同义词方法RESET(),它们做相同的事,在某些情况下使用RESET()可读性会更强。
要像上面那样使用SelectBuilder 的方法,您简单地只要使用静态导入就可以了,如:
import static org.mybatis.jdbc.SelectBuilder.*;
一旦被导入,您就能够使用SelectBuilder 类的所有方法。SelectBuilder 类的方法如下:
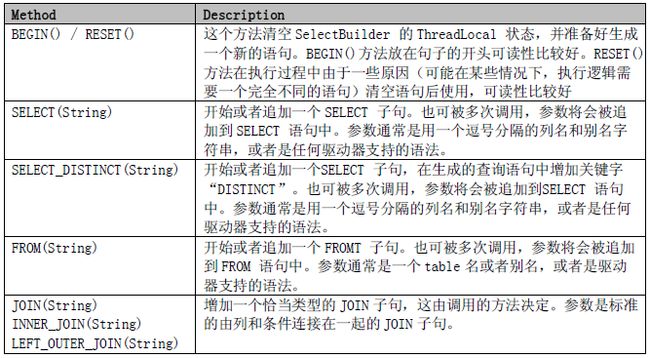
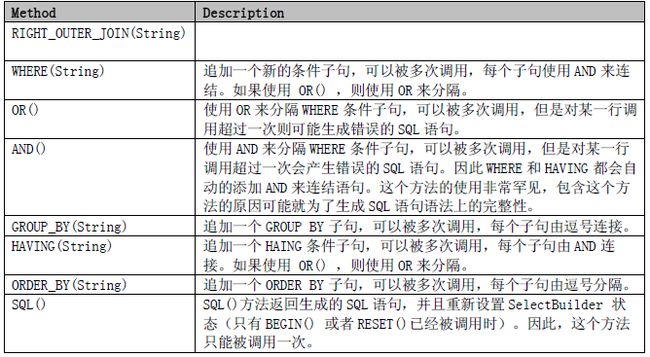
SqlBuilder
与SelectBuilder类似,MyBatis 也包含了一个通用的SqlBuilder类,它包含了SelectBuilder的所有方法,同时也有一些针对inserts, updates, 和deletes 的方法。这个类在DeleteProvider 、nsertProvider和UpdateProvider (以及SelectProvider )里生成SQL 语句时非常有用。
要像上面的例子那样使用SqlBuilder,同样只要使用静态导入就可了,例如:
import static org.mybatis.jdbc.SqlBuilder.*;
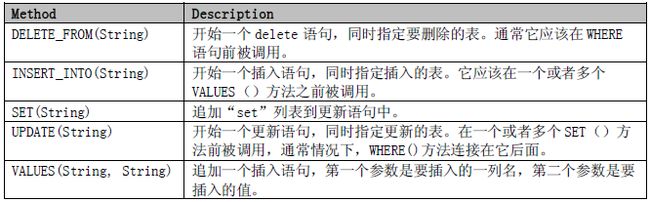
SqlBuilder 包含了SelectBuilder 的所有方法, 同时还有一些额外的方法:
下面是些例子:
public String deletePersonSql() {
BEGIN(); // Clears ThreadLocal variable
DELETE_FROM("PERSON");
WHERE("ID = ${id}");
return SQL();
}
public String insertPersonSql() {
BEGIN(); // Clears ThreadLocal variable
INSERT_INTO("PERSON");
VALUES("ID, FIRST_NAME", "${id}, ${firstName}");
VALUES("LAST_NAME", "${lastName}");
return SQL();
}
public String updatePersonSql() {
BEGIN(); // Clears ThreadLocal variable
UPDATE("PERSON");
SET("FIRST_NAME = ${firstName}");
WHERE("ID = ${id}");
return SQL();
}
结束语
MyBatis 是一款方便、简单又不失灵活的持久层框架。至此,官方英文版用户指南也结束了,感谢GOOGLE,因为在翻译本文档时,GOOGLE 翻译帮了大忙。但是,用户指南对MyBatis 的介绍还远远不够。接下来要靠我们继续去学习、使用和挖掘了,这样才能真正地了解或掌握MyBatis。
以后的附录章节是译者学习和使用MyBatis 的一些笔记记录,供大家参考,与大家共勉。