RHCSA&RHCE(RHCE7)学习知识点-- Linux 磁盘与文件系统管理
磁盘组成与分区
磁盘的组成主要有:
- 圆形的磁盘盘片(主要记录数据的部分);
- 机械手臂,与在机械手臂上的磁盘读取头(可擦写磁盘盘片上的数据);
- 主轴马达,可以转动磁盘盘片,让机械手臂的读取头在磁盘盘片上读写数据。
磁盘盘片上的物理组成则为:
- 扇区(Sector)为最小的物理储存单位,且依据磁盘设计的不同,目前主要有512bytes与4K两种格式;
- 将扇区组成一个圆,那就是磁柱(Cylinder);
- 早期的分区主要以磁柱为最小分区单位,现在的分区通常使用扇区为最小分区单位(每个扇区都有其号码,就好像座位一样);
- 磁盘分区表主要有两种格式,一种是限制较多的MBR分区表,一种是较新且限制较少的 GPT 分区表。
- MBR 分区表中,第一个扇区最重要,里面有:(1)主要引导区(Master boot record, MBR)及分区表(partition table), 其中 MBR 占有 446 bytes,而 partition table 则占有 64 bytes。
- GPT 分区表除了分区数量扩充较多之外,支持的磁盘容量也可以超过 2TB。
实体磁盘的文件名都已经被模拟成 /dev/sd[a-p] 的格式,第一颗磁盘文件名为 /dev/sda。 而分区的文件名若以第一颗磁盘为例,则为 /dev/sda[1-128] 。除了实体磁盘之外,虚拟机的磁盘通常为 /dev/vd[a-p] 的格式。若有使用到软件磁盘阵列的话,那还有 /dev/md[0-128] 的磁盘文件名。使用的是 LVM 时,文件名则为 /dev/VGNAME/LVNAME 等格式。
文件系统特性
需要将分区进行格式化,以成为操作系统能够利用的『文件系统格式(filesystem)』,通常我们可以称呼一个可被挂载的数据为一个文件系统而不是一个分区。
文件系统通常会将权限与属性放置到 inode 中,至于实际数据则放置到 data block 区块中。另外,还有一个超级区块 (superblock) 会记录整个文件系统的整体信息,包括 inode 与 block 的总量、使用量、剩余量等。每个 inode 与 block 都有编号,至于这三个数据的意义可以简略说明如下:
- superblock:记录此 filesystem 的整体信息,包括inode/block的总量、使用量、剩余量,以及文件系统的格式与相关信息等;
- inode:记录文件的属性,一个文件占用一个inode,同时记录此文件的数据所在的 block号码;
- block:实际记录文件的内容,若文件太大时,会占用多个 block 。


索引式文件系统(indexed allocation) 资料存取示意图

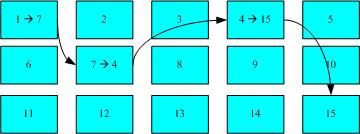
FAT文件系统资料存取示意图
需要碎片整理的原因就是文件写入的 block 太过于离散了,此时文件读取的性能将会变的很差所致。可以透过碎片整理将同一个文件所属的 blocks 汇整在一起,这样数据的读取会比较容易
Linux 的 EXT2 文件系统(inode)
文件系统一开始就将 inode 与 block 规划好了,除非重新格式化(或者利用 resize2fs 等指令变更文件系统大小),否则 inode 与 block 固定后就不再变动。Ext2 文件系统在格式化的时候基本上是区分为多个区块群组 (block group) 的,每个区块群组都有独立的 inode/block/superblock 系统。
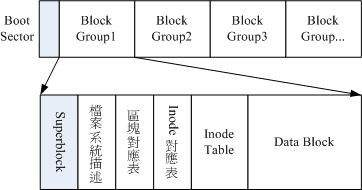

ext2文件系统示意图
文件系统最前面有一个启动扇区(boot sector),这个启动扇区可以安装开机管理程序,我们就能够将不同的开机管理程序安装到个别的文件系统最前端,而不用覆盖整颗磁盘唯一的MBR,这样也才能够制作出多重引导的环境,每一个区块群组(block group)的六个主要内容说明:
- data block (资料区块)
data block 是用来放置文件内容数据地方,在 Ext2 文件系统中所支持的 block 大小有 1K, 2K 及 4K 三种。在格式化时 block 的大小就固定了,且每个 block 都有编号,以方便 inode 的记录。由于 block 大小的差异,会导致该文件系统能够支持的最大磁盘容量与最大单一文件容量并不相同。block 大小而产生的 Ext2 文件系统限制如下:
| Block 大小 |
1KB |
2KB |
4KB |
| 最大单一文件限制 |
16GB |
256GB |
2TB |
| 最大文件系统总容量 |
2TB |
8TB |
16TB |
Ext2 文件系统的 block基本限制如下:
- 原则上,block 的大小与数量在格式化完就不能够再改变了(除非重新格式化);
- 每个 block 内最多只能够放置一个文件的数据;
- 如果文件大于 block 的大小,则一个文件会占用多个 block 数量;
- 若文件小于 block ,则该 block 的剩余容量就不能够再被使用了(磁盘空间会浪费)。
- inode table (inode 表格)
基本上,inode 记录的文件数据至少有下面这些:
- 该文件的存取模式(read/write/excute);
- 该文件的拥有者与群组(owner/group);
- 该文件的容量;
- 该文件建立或状态改变的时间(ctime);
- 最近一次的读取时间(atime);
- 最近修改的时间(mtime);
- 定义文件特性的标识(flag),如 SetUID...;
- 该文件真正内容的指向 (pointer);
inode 的数量与大小也是在格式化时就已经固定了,除此之外 inode 还有些什么特色呢?
- 每个 inode 大小均固定为 128 bytes (新的 ext4 与 xfs 可设定到 256 bytes);
- 每个文件都仅会占用一个inode 而已;
- 因此文件系统能够建立的文件数量与inode 的数量有关;
- 系统读取文件时需要先找到inode,并分析inode 所记录的权限与用户是否符合,若符合才能够开始实际读取block的内容。
将 inode 记录 block 号码的区域定义为12个直接,一个间接, 一个双间接与一个三间接记录区。


inode 结构示意图
以较小的 1K block 来说明,可以指定的情况如下:
- 12 个直接指向: 12*1K=12K
由于是直接指向,所以总共可记录 12 笔记录,因此总额大小为如上所示; - 间接: 256*1K=256K
每笔 block 号码的记录会花去 4bytes,因此 1K 的大小能够记录 256 笔记录,因此一个间接可以记录的文件大小如上; - 双间接: 256*256*1K=2562K
第一层 block 会指定 256 个第二层,每个第二层可以指定 256 个号码,因此总额大小如上; - 三间接: 256*256*256*1K=2563K
第一层 block 会指定 256 个第二层,每个第二层可以指定 256 个第三层,每个第三层可以指定 256 个号码,因此总额大小如上; - 总额:将直接、间接、双间接、三间接加总,得到 12 + 256 + 256*256 + 256*256*256 (K) = 16GB
Ext4 文件系统的 inode 容量已经可以扩大到 256bytes了,更大的 inode 容量,可以纪录更多的文件系统信息,包括新的 ACL 以及 SELinux 类型等
- Superblock (超级区块)
Superblock 是记录整个 filesystem 相关信息的地方, 没有 Superblock ,就没有这个 filesystem 了。他记录的信息主要有:
- block 与 inode 的总量;
- 未使用与已使用的 inode / block 数量;
- block 与 inode 的大小 (block 为 1, 2, 4K,inode 为 128bytes 或 256bytes);
- filesystem 的挂载时间、最近一次写入数据的时间、最近一次检验磁盘 (fsck) 的时间等文件系统的相关信息;
- 一个 valid bit 数值,若此文件系统已被挂载,则 valid bit 为 0 ,若未被挂载,则 valid bit 为 1 。
一般来说,superblock 的大小为 1024bytes。此外,每个 block group 都可能含有 superblock, 除了第一个 block group 内会含有 superblock 之外,后续的block group不一定含有 superblock,而若含有superblock则该superblock主要是做为第一个block group内 superblock 的备份
- Filesystem Description (文件系统描述说明)
这个区段可以描述每个 block group 的开始与结束的 block 号码,以及说明每个区段 (superblock, bitmap, inodemap, data block) 分别介于哪一个 block 号码之间。
- block bitmap (区块对照表)
从 block bitmap 当中可以知道哪些 block 是空的,因此我们的系统就能够很快速的找到可使用的空间来处置文件,如果你删除某些文件时,那么那些文件原本占用的 block 号码就得要释放出来, 此时在 block bitmap 当中相对应到该 block 号码的标志就得要修改成为『未使用中』,这就是 bitmap 的功能。
- inode bitmap (inode 对照表)
这个其实与 block bitmap 是类似的功能,只是 block bitmap 记录的是使用与未使用的block号码,至于inode bitmap则是记录使用与未使用的inode号码
- dumpe2fs:查询Ext家族superblock信息的指令
每个区段与 superblock 的信息都可以使用 dumpe2fs 这个指令来查询的
# dumpe2fs [-bh] 设备文件名
选项与参数:
-b :列出保留为坏轨的部分
-h :仅列出 superblock 的数据,不会列出其他的区段内容
[root@study ~]# dumpe2fs /dev/vda5
dumpe2fs 1.42.9 (28-Dec-2013)
Filesystem volume name:
Last mounted on:
Filesystem UUID: e20d65d9-20d4-472f-9f91-cdcfb30219d6
Filesystem magic number: 0xEF53 #上方UUID为 Linux 对设备的定义码
Filesystem revision #: 1 (dynamic) # 下方的 features 为文件系统的特征数据
Filesystem features: has_journal ext_attr resize_inode dir_index filetype extent 64bit flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl # 默认在挂载时会主动加上的挂载参数
Filesystem state: clean #这块文件系统的状态,clean是没问题
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 65536 # inode 的总数
Block count: 262144 # block 的总数
Reserved block count: 13107 # 保留的 block 总数
Free blocks: 249189 # 还有多少的 block 可用数量
Free inodes: 65525 # 还有多少的 inode 可用数量
First block: 0
Block size: 4096 # 单个 block 的容量大小
Fragment size: 4096
Group descriptor size: 64
....(中间省略)....
Inode size: 256 # inode 的容量大小!已经是 256
....(中间省略)....
Journal inode: 8
Default directory hash: half_md4
Directory Hash Seed: 3c2568b4-1a7e-44cf-95a2-c8867fb19fbc
Journal backup: inode blocks
Journal features: (none)
Journal size: 32M # Journal 日志式数据的可供纪录总容量
Journal length: 8192
Journal sequence: 0x00000001
Journal start: 0
Group 0: (Blocks 0-32767) # 第一块 block group 位置
Checksum 0x13be, unused inodes 8181
Primary superblock at 0, Group descriptors at 1-1 # 主要 superblock 的所在
Reserved GDT blocks at 2-128
Block bitmap at 129 (+129), Inode bitmap at 145 (+145)
Inode table at 161-672 (+161) # inode table 的所在
28521 free blocks, 8181 free inodes, 2 directories, 8181 unused inodes
Free blocks: 142-144, 153-160, 4258-32767 # 下面两行说明剩余的容量有多少
Free inodes: 12-8192
Group 1: (Blocks 32768-65535) [INODE_UNINIT] # 后续为更多其他的 block group
....(下面省略)....
至于 block group 的内容我们单纯看 Group0 信息好了。从上表中我们可以发现:
- Group0 所占用的 block 号码由 0 到 32767 号,superblock 则在第 0 号的 block 区块内!
- 文件系统描述说明在第 1 号 block 中;
- block bitmap 与 inode bitmap 则在 129 及 145 的 block 号码上。
- 至于 inode table 分布于 161-672 的 block 号码中!
- 由于 (1)一个 inode 占用 256 bytes ,(2)总共有 672 - 161 + 1(161本身) = 512 个 block 花在 inode table 上, (3)每个 block 的大小为 4096 bytes(4K)。由这些数据可以算出 inode 的数量共有 512 * 4096 / 256 = 8192 个 inode
- 这个 Group0 目前可用的 block 有28521个,可用的inode 有 8181个;
- 剩余的 inode 号码为 12 号到 8192 号
与目录树的关系
- 目录
当我们在 Linux 下的文件系统建立一个目录时,文件系统会分配一个inode 与至少一块 block 给该目录。其中,inode 记录该目录的相关权限与属性,并可记录分配到的那块block号码;而block则是记录在这个目录下的文件名与该文件名占用的inode号码数据。也就是说目录所占用的block内容记录如下的信息:


如果想要实际观察 root 家目录内的文件所占用的 inode 号码时,可以使用 ls -i 这个选项来处理:
- 文件:
当我们在Linux下的ext2建立一个一般文件时,ext2会分配一个inode与相对于该文件大小的block数量。
- 目录树读取:
因为文件名是记录在目录的 block 当中, 因此当我们要读取某个文件时,就务必会经过目录的 inode 与 block ,然后才能够找到那个待读取文件的 inode 号码,最终才会读到正确的文件的 block 内的数据。
由于目录树是由根目录开始读起,因此系统透过挂载的信息可以找到挂载点的 inode 号码,此时就能够得到根目录的 inode 内容,并依据该 inode 读取根目录的 block 内的文件名数据,再一层一层的往下读到正确的文件名。
- filesystem 大小与磁盘读取性能:
由于磁盘上面的数据总是来来去去的,所以,整个文件系统上面的文件通常无法连续写在一起(block号码不会连续的意思),而是将数据填入没有被使用的 block 当中。如果文件写入的 block 真的分的很散, 此时就会有所谓的文件数据离散的问题发生了。会发生读取效率低落的问题,因为磁头要在整个文件系统中来来去去的频繁读取。当一个文件分别记录在这个文件系统的最前面与最后面的 block 号码中, 此时会造成磁盘的机械手臂移动幅度过大,也会造成数据读取性能的低落。而且磁头在搜寻整个filesystem时,也会花费比较多的时间
EXT2/EXT3/EXT4 文件的存取与日志式文件系统的功能
要新增一个文件,此时文件系统的行为是:
- 先确定用户对于欲新增文件的目录是否具有 w 与 x 的权限;
- 根据 inode bitmap 找到没有使用的inode号码,并将新文件的权限/属性写入;
- 根据 block bitmap 找到没有使用中的block号码,并将实际的数据写入 block 中,且更新 inode 的 block 指向数据;
- 将刚刚写入的 inode 与 block 数据同步更新 inode bitmap 与 block bitmap,并更新 superblock 的内容。
一般来说,我们将 inode table 与 data block 称为数据存放区域,其他 superblock、 block bitmap 与 inode bitmap 等区段就被称为 metadata
- 数据的不一致 (Inconsistent) 状态
文件在写入文件系统时,因为未知原因导致系统中断(例如突然的停电、系统核心发生错误等等),所以写入的数据仅有inode table 及 data block,最后一个同步更新metadata的步骤并没有做完,此时就会发生 metadata 的内容与实际数据存放区产生不一致 (Inconsistent) 的情况
系统在重新启动的时候,就会通过 Superblock 当中记录的 valid bit (是否有挂载) 与 filesystem state (clean与否)等状态来判断是否强制进行数据一致性的检查!若有需要检查时则以e2fsck来进行的
这样的检查是很费时的,因为要针对 metadata 区域与实际数据存放区来进行比对,这样的检查会造成主机恢复时间的拉长,就造成后来所谓日志式文件系统的兴起了。
- 日志式文件系统 (Journaling filesystem)
在filesystem 当中划出一个区块专门记录写入或修订文件时的步骤,就可以简化一致性检查的步骤:
- 预备:当系统要写入一个文件时,会先在日志记录区块中纪录某个文件准备要写入的信息;
- 实际写入:开始写入文件的权限与数据;开始更新metadata的数据;
- 结束:完成数据与 metadata 的更新后,在日志记录区块当中完成该文件的纪录。
万一数据的纪录过程当中发生了问题,系统只要去检查日志记录区块,就可以知道哪个文件发生了问题,针对该问题来做一致性的检查即可,而不必针对整块 filesystem去检查,这样就可以达到快速修复filesystem 的能力
ext3/ext4 是 ext2 的升级版本,可达到这样的功能并且可向下兼容 ext2 版本
Linux 文件系统的运作
为了解决这个效率的问题,Linux是透过一个称为异步处理 (asynchronously) 的方式。
当系统加载一个文件到内存后,如果该文件没有被更动过,则在内存区段的文件数据会被设定为干净(clean)的。但如果内存中的文件数据被更改过了(例如你用 nano去编辑过这个文件),此时该内存中的数据会被设定为脏的 (Dirty)。此时所有的动作都还在内存中执行,并没有写入到磁盘中,系统会不定时的将内存中设定为『Dirty』的数据写回磁盘,以保持磁盘与内存数据的一致性。
Linux系统上面文件系统与内存有非常大的关系:
- 系统会将常用的文件数据放置到主存储器的缓冲区,以加速文件系统的读/写;
- 因此 Linux 的物理内存最后都会被用光!这是正常的情况!可加速系统性能;
- 你可以手动使用sync来强迫内存中设定为Dirty的文件回写到磁盘中;
- 若正常关机,关机指令会主动调用sync来将内存的数据回写入磁盘内;
- 但若不正常关机(如跳电、当机或其他不明原因),由于数据尚未回写到磁盘内,因此重新启动后可能会花很多时间在进行磁盘检验,甚至可能导致文件系统的损毁(非磁盘损毁)。
挂载点的意义 (mount point)
每个filesystem都有独立的inode/block/superblock等信息,这个文件系统要能够链接到目录树才能被我们使用。将文件系统与目录树结合的动作我们称为『挂载』。挂载点一定是目录,该目录为进入该文件系统的入口。并不是有任何文件系统都能使用,必须要『挂载』到目录树的某个目录后,才能够使用该文件系统的。
其他 Linux 支持的文件系统与 VFS
常见的支持文件系统有:
- 传统文件系统:ext2/minix/MS-DOS/FAT(用 vfat 模块)/iso9660 (光盘)等等;
- 日志式文件系统:ext3/ext4/ReiserFS/Windows' NTFS/IBM's JFS/SGI's XFS/ZFS
- 网络文件系统:NFS/SMBFS
察看Linux 支持的文件系统有哪些:
| #ls -l /lib/modules/$(uname -r)/kernel/fs |
系统目前已加载到内存中支持的文件系统:
| #cat /proc/filesystems |
- Linux VFS (Virtual Filesystem Switch)
Linux系统是透过一个名为Virtual Filesystem Switch的核心功能去读取 filesystem 的。Linux认识的 filesystem 其实都是 VFS 在进行管理,使用者并不需要知道每个partition上头的 filesystem 是什么,VFS 会主动的帮我们做好读取的动作。

VFS 文件系统的示意图
XFS 文件系统简介
- EXT 家族当前较伤脑筋的地方:支持度最广,但格式化超慢
Ext文件系统家族采用的是预先规划出所有的inode/block/meta data等数据,未来系统可以直接取用,不需要再进行动态配置的作法。
- XFS 文件系统的配置
xfs是一个日志式文件系统,几乎所有Ext4文件系统有的功能,xfs都可以具备
xfs文件系统在资料的分布上,主要规划为三个部份,一个数据区(data section)、一个文件系统活动登录区(log section)以及一个实时运作区(realtime section):
- 数据区(data section)
数据区包括 inode/data block/superblock等数据。这个数据区与 ext 家族的 block group 类似,也是分为多个储存区群组(allocation groups)来分别放置文件系统所需要的数据。每个储存区群组都包含了(1)整个文件系统的 superblock、(2)剩余空间的管理机制、(3)inode的分配与追踪。此外,inode与 block 都是系统需要用到时,这才动态配置产生,所以格式化动作超级快
另外,与ext家族不同的是,xfs的block与inode有多种不同的容量可供设定,block 容量可由512bytes~ 64K调配,不过,Linux的环境下,由于内存控制的关系 (页面文件pagesize的容量之故),因此最高可以使用的block 大小为 4K 而已,至于inode容量可由 256bytes 到 2M 这么大
- 文件系统活动登录区(log section)
主要被用来纪录文件系统的变化,其实有点像是日志区,文件的变化会在这里纪录下来,直到该变化完整的写入到数据区后,该笔纪录才会被终结。如果文件系统因为某些缘故 (例如最常见的停电) 而损毁时,系统会拿这个登录区块来进行检验,看看系统挂掉之前,文件系统正在运作些啥动作,以快速的修复文件系统。
可以指定外部的磁盘来作为 xfs 文件系统的日志区块
- 实时运作区(realtime section)
当有文件要被建立时,xfs会在这个区段里面找一个到数个的 extent 区块,将文件放置在这个区块内,等到分配完毕后,再写入到 data section 的 inode 与 block 去。这个extent区块的大小得要在格式化的时候就先指定,最小值是 4K 最大可到 1G。一般非磁盘阵列的磁盘默认为 64K 容量,而具有类似磁盘阵列的 stripe 情况下,则建议 extent 设定为与 stripe 一样大较佳。这个 extent 最好不要乱动,因为可能会影响到物理磁盘的性能。
- XFS 文件系统的描述数据观察
可以使用 xfs_info 去观察:
# xfs_info 挂载点|设备文件名
文件系统的简单操作
磁盘与目录的容量
- df:列出文件系统的整体磁盘使用量;
- du:评估文件系统的磁盘使用量(常用在推估目录所占容量)
实体链接与符号链接: ln
- Hard Link (实体链接, 硬式连结或实际连结)
hard link只是在某个目录下新增一笔文件名链接到某inode号码的关连记录
hard link是有限制的:
- 不能跨 Filesystem;
- 不能 link 目录。
- Symbolic Link (符号链接,亦即是快捷方式)
Symbolic link是建立一个独立的文件,而这个文件会让数据的读取指向他 link 的那个文件的文件名,会占用inode与block
# ln [-sf] 来源文件 目标文件
选项与参数:
-s :如果不加任何参数就进行连结,那就是hard link,至于 -s 就是symbolic link
-f :如果目标文件存在时,就主动的将目标文件直接移除后再建立
- 关于目录的 link 数量:
建立一个新的目录时,『新的目录的link数为 2 ,而上层目录的link数则会增加1』
磁盘的分区、格式化、检验与挂载
- 对磁盘进行分区,以建立可用的 partition ;
- 对该 partition 进行格式化 (format),以建立系统可用的 filesystem;
- 若想要仔细一点,则可对刚刚建立好的 filesystem 进行检验;
- 在 Linux 系统上,需要建立挂载点 (亦即是目录),并将他挂载上来;
观察磁盘分区状态
- lsblk 列出系统上的所有磁盘列表
# lsblk [-dfimpt] [device]
选项与参数:
-d :仅列出磁盘本身,并不会列出该磁盘的分区数据
-f :同时列出该磁盘内的文件系统名称
-i :使用 ASCII 的线段输出,不要使用复杂的编码 (在某些环境下很有用)
-m :同时输出该设备在 /dev 下面的权限数据 (rwx 的数据)
-p :列出该设备的完整文件名!而不是仅列出最后的名字而已。
-t :列出该磁盘设备的详细数据,包括磁盘队列机制、预读写的数据量大小等
- blkid 列出设备的 UUID 等参数
UUID 是全局单一标识符 (universally unique identifier),Linux 会将系统内所有的设备都给予一个独一无二的标识符,这个标识符就可以拿来作为挂载或者是使用这个设备/文件系统之用
- parted 列出磁盘的分区表类型与分区信息
# parted device_name print
磁盘分区: gdisk/fdisk
MBR分区表使用fdisk,GPT分区表使用gdisk
磁盘格式化(创建文件系统)
- XFS 文件系统 mkfs.xfs
- EXT4 文件系统 mkfs.ext4
# mkfs.ext4 [-b size] [-L label] 设备名称
选项与参数:
-b :设定 block 的大小,有 1K, 2K, 4K 的容量,
-L :后面接这个设备的标头名称。
文件系统检验
- xfs_repair 处理 XFS 文件系统
# xfs_repair [-fnd] 设备名称
选项与参数:
-f :后面的设备其实是个档案而不是实体设备
-n :单纯检查并不修改文件系统的任何数据 (检查而已)
-d :通常用在单人维护模式下面,针对根目录 (/) 进行检查与修复的动作!很危险!不要随便使用
- fsck.ext4 处理 EXT4 文件系统
# fsck.ext4 [-pf] [-b superblock] 设备名称
选项与参数:
-p :当文件系统在修复时,若有需要回复 y 的动作时,自动回复 y 来继续进行修复动作。
-f :强制检查!一般来说,如果 fsck 没有发现任何 unclean 的旗标,不会主动进入细部检查的,如果您想要强制 fsck 进入细部检查,就得加上 -f 旗标啰!
-D :针对文件系统下的目录进行优化配置。
-b :后面接 superblock 的位置!一般来说这个选项用不到。但是如果你的 superblock 因故损毁时,透过这个参数即可利用文件系统内备份的 superblock 来尝试救援。一般来说,superblock 备份在:1K block 放在 8193, 2K block 放在 16384, 4K block 放在 32768
文件系统挂载与卸载
# mount [-t 文件系统] 设备文件名 挂载点
系统会自动的分析最恰当的文件系统来尝试挂载你需要的设备,Linux 可以透过分析 superblock 搭配 Linux 自己的驱动程序去测试挂载
- /etc/filesystems:系统指定的测试挂载文件系统类型的优先级;
- /proc/filesystems:Linux系统已经加载的文件系统类型。
- umount (将设备文件卸载)
# umount [-fn] 设备文件名或挂载点
选项与参数:
-f :强制卸除!可用在类似网络文件系统 (NFS) 无法读取到的情况下;
-l :立刻卸除文件系统,比 -f 还强!
-n :不更新 /etc/mtab 情况下卸除
磁盘/文件系统参数修改
- mknod
# mknod 设备文件名 [bcp] [Major] [Minor]
选项与参数:
设备种类:
b :设定设备名称成为一个周边储存设备档案,例如磁盘等;
c :设定设备名称成为一个周边输入设备档案,例如鼠标/键盘等;
p :设定设备名称成为一个 FIFO 档案;
Major :主要设备代码;
Minor :次要设备代码;
- xfs_admin 修改 XFS 文件系统的 UUID 与 Label name
# xfs_admin [-lu] [-L label] [-U uuid] 设备文件名
选项与参数:
-l :列出这个设备的 label name
-u :列出这个设备的 UUID
-L :设定这个设备的 Label name
-U :设定这个设备的 UUID
- tune2fs 修改 ext4 的 label name 与 UUID
# tune2fs [-l] [-L Label] [-U uuid] 设备文件名
选项与参数:
-l :将 superblock 内的数据读出来
-L :修改 LABEL name
-U :修改 UUID
开机挂载 /etc/fstab 及 /etc/mtab
/etc/fstab的内容
| [设备/UUID等] [挂载点] [文件系统] [文件系统参数] [dump] [fsck] |
- 第一栏:磁盘设备文件名/UUID/LABEL name:
这个字段可以填写的数据主要有三个项目:
- 文件系统或磁盘的设备文件名,如 /dev/vda2 等
- 文件系统的 UUID 名称,如 UUID=xxx
- 文件系统的 LABEL 名称,例如 LABEL=xxx
- 第二栏:挂载点 (mount point):
- 第三栏:磁盘分区的文件系统:
- 第四栏:文件系统参数:
| 参数 |
内容意义 |
| async/sync |
设定磁盘是否以异步方式运作!默认为 async(性能较佳) |
| auto/noauto |
当下达 mount -a 时,此文件系统是否会被主动测试挂载。默认为 auto。 |
| rw/ro |
让该分区以可擦写或者是只读的型态挂载上来,如果你想要分享的数据是不给用户随意变更的, 这里也能够设定为只读。则不论在此文件系统的档案是否设定 w 权限,都无法写入喔! |
| exec/noexec |
限制在此文件系统内是否可以进行『执行』的工作?如果是纯粹用来储存数据的目录, 那么可以设定为 noexec 会比较安全。不过,这个参数也不能随便使用,因为你不知道该目录下是否默认会有执行档。 |
| user/nouser |
是否允许用户使用 mount 指令来挂载呢?一般而言,我们当然不希望一般身份的 user 能使用 mount 啰,因为太不安全了,因此这里应该要设定为 nouser 啰! |
| suid/nosuid |
该文件系统是否允许 SUID 的存在?如果不是执行文件放置目录,也可以设定为 nosuid 来取消这个功能! |
| defaults |
同时具有 rw, suid, dev, exec, auto, nouser, async 等参数。 基本上,默认情况使用 defaults 设定即可! |
- 第五栏:能否被 dump 备份指令作用:
dump 是一个用来做为备份的指令,不过现在有太多的备份方案了,所以这个项目可以直接输入0
- 第六栏:是否以 fsck 检验扇区:
参考文档:
《鸟哥的Linux私房菜基础篇第三版》