RHCSA&RHCE(RHCE7)学习知识点-- Linux认识与学习BASH
硬件、核心与 Shell
我们要通过『 Shell 』输入指令与 Kernel沟通,让 Kernel可以控制硬件来工作。
操作系统是一组软件,控制整个硬件与管理系统的活动监测。用户可以透过应用程序来指挥核心,让核心完成我们所需要的硬件任务。应用程序其实是在最外层,就如同鸡蛋的外壳一样,因此也就被称为壳程序(shell)。壳程序的功能只是提供用户操作系统的一个接口,因此这个壳程序需要调用其他软件来完成任务。
系统的合法 shell 与 /etc/shells 功能
/etc/shells文件包含了我们可以使用的shells
- /bin/sh (已经被 /bin/bash 所取代)
- /bin/bash (就是 Linux 默认的 shell)
- /bin/tcsh (整合 C Shell ,提供更多的功能)
- /bin/csh (已经被 /bin/tcsh 所取代)
Bash shell 的功能
/bin/bash 是 Linux 默认的shell,bash 是 GNU 计划中重要的工具软件之一,目前也是 Linux distributions 的标准shell。bash主要兼容于sh,并且依据一些使用者需求而加强的shell版本。bash 主要的优点有下面几个:
- 命令历史 (history):
他能记忆使用过的指令在你的家目录内的 .bash_history,~/.bash_history记录的是前一次登入以前所执行过的指令,而这一次登入所执行的指令都被暂存在内存中,当你成功的注销系统后,该指令记忆才会记录到.bash_history
- 命令与档案补全功能: ([tab] 按键的好处)
[Tab] 接在一串指令的第一个字的后面,则为命令补全;
[Tab] 接在一串指令的第二个字以后时,则为『档案补齐』!
若安装 bash-completion 软件,则在某些指令后面使用 [tab] 按键时,可以进行『选项/参数的补齐』功能
- 命令别名设定功能: (alias)
- 工作控制、前台后台控制:(job control, foreground, background)
- 程序化脚本: (shell scripts)
- 通配符: (Wildcard)
查询指令是否为 Bash shell 的内建命令:type
为了方便 shell 的操作,其实 bash 已经『内建』了很多指令,利用 type 这个指令知道某个指令是来自于外部指令或是内建在bash当中
$ type [-tpa] name
选项与参数:
:不加任何选项与参数时,type 会显示出 name 是外部指令还是 bash 内建指令
-t :当加入 -t 参数时,type 会将 name 以下面这些字眼显示出他的意义:
file :表示为外部指令;
alias :表示该指令为命令别名所设定的名称;
builtin :表示该指令为 bash 内建的指令功能;
-p :如果后面接的 name 为外部指令时,才会显示完整文件名;
-a :会由 PATH 变量定义的路径中,将所有含 name 的指令都列出来,包含 alias
指令的下达与快速编辑按钮
如果指令串太长,利用『 \[Enter] 』来将 [Enter] 这个按键『转义』,让 [Enter] 按键不再具有『开始执行』的功能,让指令可以继续在下一行输入。[Enter] 按键是紧接着反斜杠 (\) 的,两者中间没有其他字符。因为 \ 仅转义『紧接着的下一个字符』
| 组合键 |
功能与示范 |
| [ctrl]+u/[ctrl]+k |
分别是从光标处向前删除指令串 ([ctrl]+u) 及向后删除指令串 ([ctrl]+k)。 |
| [ctrl]+a/[ctrl]+e |
分别是让光标移动到整个指令串的最前面 ([ctrl]+a) 或最后面 ([ctrl]+e)。 |
Shell 的变量功能
变量就是让某一个特定字符串代表不固定的内容。用一个简单的 "字眼" 来取代另一个比较复杂或者是容易变动的数据
- 影响 bash 环境操作的变量
某些特定变量会影响到 bash 的环境,由于系统需要一些变量来提供数据的存取 (或者是一些环境的设定参数值),所以就有一些所谓的『环境变量』需要来读入系统中,例如 PATH、HOME、MAIL、SHELL 等等,为了区别与自定义变量的不同,环境变量通常以大写字符来表示
- 脚本程序设计 (shell script) 的好帮手
变量就是以一组文字或符号等,来取代一些设定或者是一串保留的数据
变量的取用与设定:echo, 变量设定规则, unset
使用 echo指令可以取用变量,变量被取用时,前面必须加上$或者是以 ${变量}
- 变量的取用: echo
$ echo $variable
$ echo ${PATH} #也可以使用这种格式
『设定』或者是『修改』 某个变量的内容,用『等号(=)』连接变量与他的内容
$ myname=VBird
bash 在你没有设定的变量中强迫去 echo 时,它会显示出空的值。
- 变量的设定规则
- 变量与变量内容以一个等号『=』来连结,如下所示:
『myname=VBird』 - 等号两边不能直接接空格符,如下所示为错误:
『myname = VBird』或『myname=VBird Tsai』 - 变量名称只能是英文字母与数字,但是开头字符不能是数字,如下为错误:
『2myname=VBird』 - 变量内容若有空格符可使用双引号『"』或单引号『'』将变量内容结合起来,但
- 双引号内的特殊字符如 $ 等,可以保有原本的特性,如下所示:
『var="lang is $LANG"』则『echo $var』可得『lang is zh_TW.UTF-8』 - 单引号内的特殊字符则仅为一般字符 (纯文本),如下所示:
『var='lang is $LANG'』则『echo $var』可得『lang is $LANG』
- 双引号内的特殊字符如 $ 等,可以保有原本的特性,如下所示:
- 可用转义字符『 \ 』将特殊符号(如 [Enter], $, \, 空格符, '等)变成一般字符,如:
『myname=VBird\ Tsai』 - 在一串指令的执行中,还需要其他额外的指令所提供的信息时,可以使用反单引号『`指令`』或『$(指令)』。特别注意,那个 ` 是键盘上方的数字键 1 左边那个按键,而不是单引号! 例如想要取得核心版本的设定:
『version=$(uname -r)』再『echo $version』可得『3.10.0-229.el7.x86_64』 - 若该变量为扩增变量内容时,则可用 "$变量名称" 或 ${变量} 累加内容,如下所示:
『PATH="$PATH":/home/bin』或『PATH=${PATH}:/home/bin』 - 若该变量需要在其他子程序执行,则需要以 export 来使变量变成环境变量:
『export PATH』 - 通常大写字符为系统默认变量,自行设定变量可以使用小写字符,方便判断;
- 取消变量的方法为使用 unset :『unset 变量名称』例如取消 myname 的设定:
『unset myname』
环境变量的功能
环境变量有很多功能:包括家目录的变换、提示字符的显示、执行文件搜寻的路径等等
- 用 env 观察环境变量与常见环境变量说明
env 是 environment (环境) 的简写,可以列出来所有的环境变量。
- 用 set 观察所有变量 (含环境变量与自定义变量)
set 除了环境变量之外, 还会将其他在 bash 内的变量通通显示出来,常用的变量:
- PS1:(提示字符的设定)
这个是我们的『命令提示字符』
- \d :可显示出『星期 月 日』的日期格式,如:"Mon Feb 2"
- \H :完整的主机名。
- \h :仅取主机名在第一个小数点之前的名字
- \t :显示时间,为 24 小时格式的『HH:MM:SS』
- \T :显示时间,为 12 小时格式的『HH:MM:SS』
- \A :显示时间,为 24 小时格式的『HH:MM』
- \@ :显示时间,为 12 小时格式的『am/pm』样式
- \u :目前使用者的账号名称;
- \v :BASH 的版本信息
- \w :完整的工作目录名称,由根目录写起的目录名称。但家目录会以 ~ 取代;
- \W :利用 basename 函数取得工作目录名称,所以仅会列出最后一个目录名。
- \# :下达的第几个指令。
- \$ :提示字符,如果是 root 时,提示字符为 # ,否则就是 $
- $:(关于本 shell 的 PID)
- ?:(关于上个执行指令的返回值)
- OSTYPE, HOSTTYPE, MACHTYPE:(主机硬件与核心的等级)
- export: 自定义变量转成环境变量
$ export 变量名称
export没有接变量时,将会把所有的『环境变量』列出来
影响显示结果的语言变量 (locale)
locale查询Linux到底支持了多少的语言,这些语言档案都放置在: /usr/lib/locale/ 这个目录中。
$ locale -a
$ locale <==后面不加任何选项与参数即可!
LANG=en_US <==主语言的环境
LC_CTYPE="en_US" <==字符(文字)辨识的编码
LC_NUMERIC="en_US" <==数字系统的显示信息
LC_TIME="en_US" <==时间系统的显示数据
LC_COLLATE="en_US" <==字符串的比较与排序等
LC_MONETARY="en_US" <==币值格式的显示等
LC_MESSAGES="en_US" <==信息显示的内容,如菜单、错误信息等
LC_ALL= <==整体语言的环境
....(后面省略)....
整体系统默认的语言定义在/etc/locale.conf
变量的有效范围
被 export 后的变量,我们可以称他为『环境变量』,环境变量可以被子程序所引用,但是其他的自定义变量内容就不会存在于子程序中。
环境变量=全局变量
自定义变量=局部变量
- 当启动一个 shell,操作系统会分配一记忆区块给 shell 使用,此内存内之变量可让子程序取用
- 若在父程序利用 export 功能,可以让自定义变量的内容写到上述的记忆区块当中(环境变量);
- 当加载另一个 shell 时 (亦即启动子程序,而离开原本的父程序了),子 shell 可以将父 shell 的环境变量所在的记忆区块导入自己的环境变量区块当中。
变量键盘读取、数组与宣告: read, array, declare
- read
要读取来自键盘输入的变量,就是用 read 这个指令
$ read [-pt] variable
选项与参数:
-p :后面可以接提示字符!
-t :后面可以接等待的『秒数!』这个比较有趣~不会一直等待
- declare / typeset
declare 或 typeset 是一样的功能,就是在『宣告变量的类型』。如果使用 declare 后面并没有接任何参数,那么 bash 就会主动的将所有的变量名称与内容列出来
$ declare [-aixr] variable
选项与参数:
-a :将后面名为 variable 的变量定义成为数组 (array) 类型
-i :将后面名为 variable 的变量定义成为整数数字 (integer) 类型
-x :用法与 export 一样,就是将后面的 variable 变成环境变量;
-r :将变量设定成为 readonly 类型,该变量不可被更改内容,也不能 unset
由于在默认的情况下面, bash 对于变量有几个基本的定义:
- 变量类型默认为『字符串』,所以若不指定变量类型,则 1+2 为一个『字符串』而不是『计算式』。
- bash 环境中的数值运算,默认最多仅能到达整数形态,所以 1/3 结果是 0;
- 数组 (array) 变量类型
var[index]=content
那个 index 就是一些数字啦,重点是用中刮号 ([ ]) 来设定的。目前我们 bash 提供的是一维数组。
与文件系统及程序的限制关系: ulimit
ulimit可以『限制用户的某些系统资源』的,包括可以开启的档案数量, 可以使用的 CPU 时间,可以使用的内存总量等等。
$ ulimit [-SHacdfltu] [配额]
选项与参数:
-H :hard limit ,严格的设定,必定不能超过这个设定的数值;
-S :soft limit ,警告的设定,可以超过这个设定值,但是若超过则有警告信息。在设定上,通常 soft 会比 hard 小,举例来说,soft 可设定为 80 而 hard 设定为 100,那么你可以使用到 90 (因为没有超过 100),但介于 80~100 之间时,系统会有警告信息通知你!
-a :后面不接任何选项与参数,可列出所有的限制额度;
-c :当某些程序发生错误时,系统可能会将该程序在内存中的信息写成档案(除错用),这种档案就被称为核心档案(core file)。此为限制每个核心档案的最大容量。
-f :此 shell 可以建立的最大档案容量(一般可能设定为 2GB)单位为 Kbytes
-d :程序可使用的最大断裂内存(segment)容量;
-l :可用于锁定 (lock) 的内存量
-t :可使用的最大 CPU 时间 (单位为秒)
-u :单一用户可以使用的最大程序(process)数量。
变量内容的删除、取代与替换 (Optional)
- 变量内容的删除与取代
| 变量设定方式 |
说明 |
| ${变量#关键词} |
若变量内容从头开始的数据符合『关键词』,则将符合的最短数据删除 |
| ${变量%关键词} |
若变量内容从尾向前的数据符合『关键词』,则将符合的最短数据删除 |
| ${变量/旧字符串/新字符串} |
若变量内容符合『旧字符串』则『第一个旧字符串会被新字符串取代』 |
- 变量的测试与内容替换
| 变量设定方式 |
str 没有设定 |
str 为空字符串 |
str 已设定非为空字符串 |
| var=${str-expr} |
var=expr |
var= |
var=$str |
| var=${str:-expr} |
var=expr |
var=expr |
var=$str |
| var=${str+expr} |
var= |
var=expr |
var=expr |
| var=${str:+expr} |
var= |
var= |
var=expr |
| var=${str=expr} |
str=expr |
str 不变 |
str 不变 |
| var=${str:=expr} |
str=expr |
str=expr |
str 不变 |
| var=${str?expr} |
expr 输出至 stderr |
var= |
var=$str |
| var=${str:?expr} |
expr 输出至 stderr |
expr 输出至 stderr |
var=$str |
命令别名设定: alias, unalias
在 alias 后面加上你的 {『别名』='指令 选项...' }
命令别名的设定还可以取代既有的指令
使用 alias不带任何参数查看有哪些的命令别名
要取消命令别名的话,那么就使用 unalias
历史命令:history
使用 history查询我们曾经执行过的指令
$ history [n]
$ history [-c]
$ history [-raw] histfiles
选项与参数:
n :数字,意思是『要列出最近的 n 笔命令行表』的意思!
-c :将目前的 shell 中的所有 history 内容全部消除
-a :将目前新增的 history 指令新增入 histfiles 中,若没有加 histfiles ,
则默认写入 ~/.bash_history
-r :将 histfiles 的内容读到目前这个 shell 的 history 记忆中;
-w :将目前的 history 记忆内容写入 histfiles 中
在正常的情况下,历史命令的读取与记录是这样的:
- 当我们以 bash 登入 Linux 主机之后,系统会主动的由家目录的 ~/.bash_history 读取以前曾经下过的指令,那么 ~/.bash_history 会记录几笔数据呢?这就与你 bash 的 HISTFILESIZE 这个变量设定值有关
- 假设我这次登入主机后,共下达过 100 次指令,『等我注销时, 系统就会将 101~1100 这总共 1000 笔历史命令更新到 ~/.bash_history 当中。』 也就是说,历史命令在我注销时,会将最近的 HISTFILESIZE 笔记录到我的纪录文件当中
- 当然,也可以用 history -w 强制立刻写入的!那为何用『更新』两个字呢? 因为 ~/.bash_history 记录的笔数永远都是 HISTFILESIZE 那么多,旧的信息会被主动的拿掉,仅保留最新的
可以利用相关的功能来帮我们执行命令:
| $ !number $ !command $ !! 选项与参数: number :执行第几笔指令的意思; command :由最近的指令向前搜寻『指令串开头为 command』的那个指令,并执行; !! :就是执行上一个指令(相当于按↑按键后,按 Enter)
最后注销的那个 bash 才会是最后写入的数据,其他 bash 的指令操作就不会被记录下来了 (其实有被记录,只是被后来的最后一个 bash 所覆盖更新了) |
- 无法记录时间
历史命令还有一个问题,那就是无法记录指令下达的时间。由于这 1000 笔历史命令是依序记录的, 但是并没有记录时间,所以在查询方面会有一些不方便。
Bash Shell 的操作环境:
路径与指令搜寻顺序
指令运行的顺序:
- 以相对/绝对路径执行指令,例如『 /bin/ls 』或『 ./ls 』;
- 由 alias 找到该指令来执行;
- 由 bash 内建的 (builtin) 指令来执行;
- 透过 $PATH 这个变量的顺序搜寻到的第一个指令来执行。
bash 的进站与欢迎信息: /etc/issue, /etc/motd
进站画面与欢迎信息在 /etc/issue 里面
$ cat /etc/issue
\S
Kernel \r on an \m
|
issue 内的各代码意义 |
| \d 本地端时间的日期; |
telnet 连接到主机时,主机的登入画面就会显示 /etc/issue.net
要让使用者登入后取得一些信息,可以将信息加入/etc/motd 里面
bash 的环境配置文件
系统有一些环境配置文件,让 bash 在启动时直接读取这些配置文件,以规划好 bash 的操作环境,而这些配置文件又可以分为全体系统的配置文件以及用户个人偏好配置文件。我们前面谈到的命令别名、自定义的变量,在你注销 bash 后就会失效,要保留你的设定,就得要将这些设定写入配置文件才行。
- login 与 non-login shell
login shell 与 non-login shell 重点在于有没有登入 (login)
- login shell:取得 bash 时需要完整的登入流程的,就称为 login shell。
- non-login shell:取得 bash 接口的方法不需要重复登入的举动。
这两个取得 bash 的情况中,读取的配置文件数据并不一样所致。login shell 其实只会读取这两个配置文件:
- /etc/profile:这是系统整体的设定,你最好不要修改这个档案;
- ~/.bash_profile 或 ~/.bash_login 或 ~/.profile:属于使用者个人设定,你要改自己的数据,就写入这里
- /etc/profile (login shell 才会读)
这个配置文件可以利用使用者的标识符 (UID) 来决定很多重要的变量数据, 这也是每个使用者登入取得 bash 时一定会读取的配置文件。如果你想要帮所有使用者设定整体环境,那就是改这里
- PATH:会依据 UID 决定 PATH 变量要不要含有 sbin 的系统指令目录;
- MAIL:依据账号设定好使用者的 mailbox 到 /var/spool/mail/账号名;
- USER:根据用户的账号设定此一变量内容;
- HOSTNAME:依据主机的 hostname 指令决定此一变量内容;
- HISTSIZE:历史命令记录笔数。CentOS 7.x 设定为 1000 ;
- umask:包括 root 默认为 022 而一般用户为 002
/etc/profile还会去调用外部的设定数据:
- /etc/profile.d/*.sh
只要在 /etc/profile.d/ 这个目录内且扩展名为 .sh ,另外,使用者能够具有 r 的权限,那么该档案就会被/etc/profile调用进来。在 CentOS 7.x 中,这个目录下面的档案规范了 bash 操作接口的颜色、语言、ll 与 ls 指令的命令别名、vi 的命令别名、which 的命令别名等等。如果你需要帮所有使用者设定一些共享的命令别名时,可以在这个目录下面自行建立扩展名为 .sh 的档案,并将所需要的数据写入即可
- /etc/locale.conf
这个档案是由 /etc/profile.d/lang.sh 调用进来的,这也是我们决定 bash 默认使用何种语言的重要配置文件,档案里最重要的就是 LANG/LC_ALL 这些个变量的设定
- /usr/share/bash-completion/completions/*
这个目录下面的内容是由/etc/profile.d/bash_completion.sh这个档案载入的,处理指令的选项/参数补齐功能
bash 的 login shell 情况下所读取的整体环境配置文件其实只有 /etc/profile,但是 /etc/profile 还会调用其他的配置文件,让我们的 bash 操作接口变的非常的友善
- ~/.bash_profile (login shell 才会读)
bash 在读完了整体环境设定的 /etc/profile 并调用其他配置文件后,接下来则是会读取使用者的个人配置文件。 在 login shell 的 bash 环境中,所读取的个人偏好配置文件其实主要有三个,依序分别是:
- ~/.bash_profile
- ~/.bash_login
- ~/.profile
其实 bash 的 login shell 设定只会读取上面三个档案的其中一个, 而读取的顺序则是依照上面的顺序。如果 ~/.bash_profile 存在,那么其他两个档案不论有无存在,都不会被读取。如果 ~/.bash_profile 不存在才会去读取 ~/.bash_login,而前两者都不存在才会读取 ~/.profile 的意思。
bash 配置文件的读入方式是透过一个指令『 source 』来读取的, ~/.bash_profile 其实会再调用 ~/.bashrc 的设定内容。整个 login shell 的读取流程:
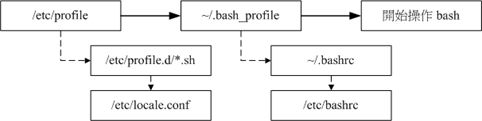
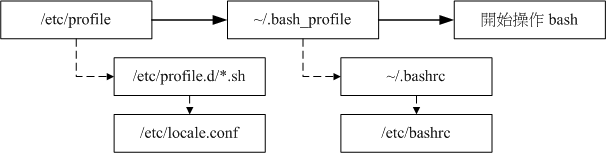
login shell 的配置文件读取流程
- source:读入环境配置文件的指令
由于 /etc/profile 与 ~/.bash_profile 都是在取得 login shell 的时候才会读取的配置文件,所以,如果你将自己的偏好设定写入上述的档案后,通常都是得注销再登入后,该设定才会生效。利用 source 这个指令直接读取配置文件而不注销登入
$ source 配置文件文件名
利用 source 或小数点 (.) 都可以将配置文件的内容读进来目前的 shell 环境中
- ~/.bashrc (non-login shell会读)
当你取得non-login shell时,该 bash 配置文件仅会读取~/.bashrc
CentOS 7.x的~/.bashrc 还会主动的调用/etc/bashrc这个档案,/etc/bashrc 帮我们的 bash 定义出下面的数据:
- 依据不同的 UID 规范出 umask 的值;
- 依据不同的 UID 规范出提示字符 (就是 PS1 变量);
- 调用/etc/profile.d/*.sh的设定
这个 /etc/bashrc 是 CentOS 特有的 (其实是 Red Hat 系统特有的),其他不同的 distributions 可能会放置在不同的文件名
- 其他相关配置文件
还有一些配置文件可能会影响到你的 bash 操作:
- /etc/man_db.conf
这个档案规定了执行man 的时候,该去哪里查看数据的路径设定
- ~/.bash_history
我们的历史命令就记录在这里,能够记录几笔数据,则与 HISTFILESIZE 这个变量有关
- ~/.bash_logout
这个档案则记录了『当我注销 bash 后,系统再帮我做完什么动作后才离开』
终端机的环境设定: stty, set
利用 stty (setting tty 终端机的意思) 可以帮助查看和设定终端机的输入按键代表意义
$ stty [-a]
选项与参数:
-a :将目前所有的 stty 参数列出来
如果出现 ^ 表示 [Ctrl] 那个按键的意思。几个重要的代表意义是:
- intr : 送出一个 interrupt (中断) 的讯号给目前正在 run 的程序
- quit : 送出一个 quit 的讯号给目前正在 run 的程序;
- erase : 向后删除字符,
- kill : 删除在目前命令行上的所有文字;
- eof : End of file 的意思,代表『结束输入』。
- start : 在某个程序停止后,重新启动他的 output
- stop : 停止目前屏幕的输出;
- susp : 送出一个 terminal stop 的讯号给正在 run 的程序。
$ stty erase ^h
删除字符就得要使用 [ctrl]+h,想要恢复利用 [backspace]删除字符 ,就执行 stty erase ^?
bash 还有自己的一些终端机设定值利用set 来设定和显示
$ set [-uvCHhmBx]
选项与参数:
-u :默认不启用。若启用后,当使用未设定变量时,会显示错误信息;
-v :默认不启用。若启用后,在信息被输出前,会先显示信息的原始内容;
-x :默认不启用。若启用后,在指令被执行前,会显示指令内容(前面有 ++ 符号)
-h :默认启用。与历史命令有关;
-H :默认启用。与历史命令有关;
-m :默认启用。与工作管理有关;
-B :默认启用。与刮号 [] 的作用有关;
-C :默认不启用。若使用 > 等,则若档案存在时,该档案不会被覆盖
bash 默认的组合键:
| 组合按键 |
执行结果 |
| Ctrl + C |
终止目前的命令 |
| Ctrl + D |
输入结束 (EOF),例如邮件结束的时候; |
| Ctrl + M |
就是 Enter 啦! |
| Ctrl + S |
暂停屏幕的输出 |
| Ctrl + Q |
恢复屏幕的输出 |
| Ctrl + U |
在提示字符下,将整列命令删除 |
| Ctrl + Z |
『暂停』目前的命令 |
通配符与特殊符号
| 符号 |
意义 |
| * |
代表『 0 个到无穷多个』任意字符 |
| ? |
代表『一定有一个』任意字符 |
| [ ] |
同样代表『一定有一个在括号内』的字符(非任意字符)。例如 [abcd] 代表『一定有一个字符,可能是 a, b, c, d 这四个任何一个』 |
| [ - ] |
若有减号在中括号内时,代表『在编码顺序内的所有字符』。例如 [0-9] 代表 0 到 9 之间的所有数字,因为数字的语言编码是连续的! |
| [^ ] |
若中括号内的第一个字符为指数符号 (^) ,那表示『反向选择』,例如 [^abc] 代表 一定有一个字符,只要是非 a, b, c 的其他字符就接受的意思。 |
bash 环境中的特殊符号:
| 符号 |
内容 |
| # |
批注符号:这个最常被使用在 script 当中,视为说明!在后的数据均不执行 |
| \ |
转义符号:将『特殊字符或通配符』还原成一般字符 |
| | |
管道 (pipe):分隔两个管道命令的界定(后两节介绍); |
| ; |
连续指令下达分隔符:连续性命令的界定 (注意!与管道命令并不相同) |
| ~ |
用户的家目录 |
| $ |
取用变量前导符:亦即是变量之前需要加的变量取代值 |
| & |
工作控制 (job control):将指令变成后台下工作 |
| ! |
逻辑运算意义上的『非』 not 的意思! |
| / |
目录符号:路径分隔的符号 |
| >, >> |
数据流重定向:输出导向,分别是『取代』与『累加』 |
| <, << |
数据流重定向:输入导向 (这两个留待下节介绍) |
| ' ' |
单引号,不具有变量置换的功能 ($ 变为纯文本) |
| " " |
具有变量置换的功能! ($ 可保留相关功能) |
| ` ` |
两个『 ` 』中间为可以先执行的指令,亦可使用 $( ) |
| ( ) |
在中间为子 shell 的起始与结束 |
| { } |
在中间为命令区块的组合! |
数据流重定向
数据流重定向就是将某个指令执行后应该要出现在屏幕上的数据,给他传输到其他的地方
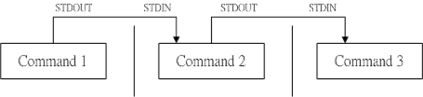
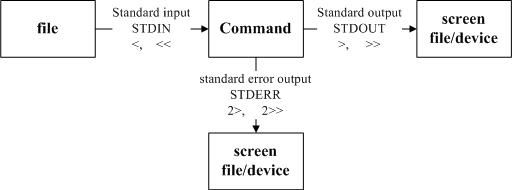
指令执行过程的数据传输情况
standard output 与 standard error output 分别代表『标准输出 (STDOUT)』与『标准错误输出 (STDERR)』,
- standard output 与 standard error output
标准输出指的是『指令执行所返回的正确的信息』,而标准错误输出可理解为『 指令执行失败后,所返回的错误信息』。
数据流重定向可以将 standard output (简称 stdout) 与 standard error output (简称 stderr) 分别传送到其他的档案或设备去,而分别传送所用的特殊字符则如下所示:
- 标准输入 (stdin) :代码为 0 ,使用 < 或 << ;
- 标准输出 (stdout):代码为 1 ,使用 > 或 >> ;
- 标准错误输出(stderr):代码为 2 ,使用 2> 或 2>> ;
若以 > 输出到一个已存在的档案中,那个档案就会被覆盖掉,利用两个大于的符号 (>>)将数据累加而不要将旧的数据删除
- 1> :以覆盖的方法将『正确的数据』输出到指定的档案或设备上;
- 1>>:以累加的方法将『正确的数据』输出到指定的档案或设备上;
- 2> :以覆盖的方法将『错误的数据』输出到指定的档案或设备上;
- 2>>:以累加的方法将『错误的数据』输出到指定的档案或设备上;
注意:『 1>> 』以及『 2>> 』中间是没有空格的
- /dev/null 垃圾桶黑洞设备与特殊写法
这个 /dev/null 可以吃掉任何导向这个设备的信息,写入同一个档案的特殊语法使用 2>&1 也可以使用 &>
- standard input : < 与 <<
< 将原本需要由键盘输入的数据,改由档案内容来取代
<< 这个连续两个小于的符号代表的是『结束的输入字符』的意思
为何要使用命令输出重定向:
- 屏幕输出的信息很重要,而且我们需要将他存下来的时候;
- 后台执行中的程序,不希望他干扰屏幕正常的输出结果时;
- 一些系统的例行命令 (例如写在 /etc/crontab 中的档案) 的执行结果,希望他可以存下来时;
- 一些执行命令的可能已知错误信息时,想以『 2> /dev/null 』将他丢掉时;
- 错误信息与正确信息需要分别输出时。
命令执行的判断依据: ; , &&, ||
- cmd ; cmd (不考虑指令相关性的连续指令下达)
可以一次执行多个指令
- $? (指令返回值) 与 && 或 ||
两个指令之间有相依性,而这个相依性主要判断的地方就在于前一个指令执行的结果是否正确。
| 指令下达情况 |
说明 |
| cmd1 && cmd2 |
1. 若 cmd1 执行完毕且正确执行($?=0),则开始执行 cmd2。 |
| cmd1 || cmd2 |
1. 若 cmd1 执行完毕且正确执行($?=0),则 cmd2 不执行。 |
一般来说,假设判断式有三个,也就是:
command1 && command2 || command3
顺序通常不会变,一般来说, command2 与 command3 会放置肯定可以执行成功的指令
管道命令 (pipe)
管道命令使用的是『 | 』这个界定符号,这个管道命令『 | 』仅能处理经由前面一个指令传来的正确信息,也就是 standard output 的信息,对于 stdandard error 并没有直接处理的能力。
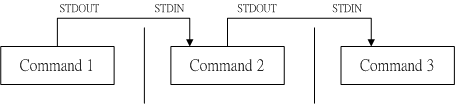
管道命令的处理示意图
在每个管道后面接的第一个数据必定是『指令』,而且这个指令必须要能够接受 standard input 的数据才行,这样的指令才可以是为『管道命令』,例如 less, more, head, tail 等都是可以接受 standard input 的管道命令。至于例如 ls, cp, mv 等就不是管道命令了,因为 ls, cp, mv 并不会接受来自 stdin 的数据。 也就是说,管道命令主要有两个比较需要注意的地方:
- 管道命令仅会处理 standard output,对于 standard error output 会予以忽略
- 管道命令必须要能够接受来自前一个指令的数据成为 standard input 继续处理才行。
撷取命令: cut, grep
撷取命令将一段数据经过分析后,取出我们所想要的,或者是经由分析关键词,取得我们所想要的那一行。不过,一般来说,撷取信息通常是针对『一行一行』来分析的,并不是整篇信息分析的
- cut
这个指令可以将一段信息的某一段给他『切』出来,处理的信息是以『行』为单位,cut 主要的用途在于将『同一行里面的数据进行分解!』最常使用在分析一些数据或文字数据的时候
$ cut -d'分隔字符' -f fields <==用于有特定分隔字符
$ cut -c 字符区间 <==用于排列整齐的信息
选项与参数:
-d :后面接分隔字符。与 -f 一起使用;
-f :依据 -d 的分隔字符将一段信息分割成为数段,用 -f 取出第几段的意思;
-c :以字符 (characters) 的单位取出固定字符区间;
- grep
grep是分析一行信息,取出我们所需要的信息
$ grep [-acinv] [--color=auto] '搜寻字符串' filename
选项与参数:
-a :将 binary 档案以 text 档案的方式搜寻数据
-c :计算找到 '搜寻字符串' 的次数
-i :忽略大小写的不同,所以大小写视为相同
-n :顺便输出行号
-v :反向选择,亦即显示出没有 '搜寻字符串' 内容的那一行!
--color=auto :可以将找到的关键词部分加上颜色的显示
排序命令: sort, wc, uniq
- sort
可以依据不同的数据型态来排序,数字与文字的排序就不一样。排序的字符与语言的编码有关,默认『以第一个』数据来排序,默认是以『文字』型态来排序
$ sort [-fbMnrtuk] [file or stdin]
选项与参数:
-f :忽略大小写的差异,例如 A 与 a 视为编码相同;
-b :忽略最前面的空格符部分;
-M :以月份的名字来排序,例如 JAN, DEC 等等的排序方法;
-n :使用『纯数字』进行排序(默认是以文字型态来排序的);
-r :反向排序;
-u :就是 uniq ,相同的数据中,仅出现一行代表;
-t :分隔符,默认是用 [tab] 键来分隔;
-k :以那个区间 (field) 来进行排序的意思
- uniq
将重复的资料仅列出一个显示
$ uniq [-ic]
选项与参数:
-i :忽略大小写字符的不同;
-c :进行计数
- wc
查看档案里面有多少字,多少行,多少字符
$ wc [-lwm]
选项与参数:
-l :仅列出行;
-w :仅列出多少字(英文单字);
-m :多少字符
双向重定向: tee
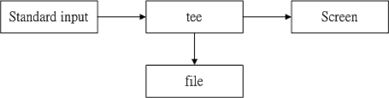

tee 的工作流程示意图
tee 会同时将数据流分送到档案去与屏幕 (screen);而输出到屏幕的,其实就是 stdout ,那就可以让下个指令继续处理
tee 可以让 standard output 转存一份到档案内并将同样的数据继续送到屏幕去处理
tee [-a] file
选项与参数:
-a :以累加 (append) 的方式,将数据加入 file 当中
字符转换命令: tr, col, join, paste, expand
- tr
tr 可以用来删除一段信息当中的文字,或者是进行文字信息的替换!
| $ tr [-ds] SET1 ... 选项与参数: -d :删除信息当中的 SET1 这个字符串; -s :取代掉重复的字符! |
- col
可以用来简单的处理将 [tab] 按键取代成为空格键
$ col [-xb]
选项与参数:
-x :将 tab 键转换成对等的空格键
- join
主要是在处理『两个档案当中,有 "相同数据" 的那一行,才将他加在一起』
$ join [-ti12] file1 file2
选项与参数:
-t :join 默认以空格符分隔数据,并且比对『第一个字段』的数据,
如果两个档案相同,则将两笔数据联成一行,且第一个字段放在第一个!
-i :忽略大小写的差异;
-1 :这个是数字的 1 ,代表『第一个档案要用那个字段来分析』的意思;
-2 :代表『第二个档案要用那个字段来分析』的意思
- paste
直接『将两行贴在一起,且中间以 [tab] 键隔开』
$ paste [-d] file1 file2
选项与参数:
-d :后面可以接分隔字符。默认是以 [tab] 来分隔的!
- :如果 file 部分写成 - ,表示来自 standard input 的资料的意思
- expand
将 [tab] 按键转成空格键
$ expand [-t] file
选项与参数:
-t :后面可以接数字。一般来说,一个 tab 按键可以用 8 个空格键取代。
我们也可以自行定义一个 [tab] 按键代表多少个字符
分割命令: split
将一个大档案,依据档案大小或行数来分割,可以将大档案分割成为小档案
$ split [-bl] file PREFIX
选项与参数:
-b :后面可接欲分割成的档案大小,可加单位,例如 b, k, m 等;
-l :以行数来进行分割。
PREFIX :代表前导符的意思,可作为分割档案的前导文字
参数代换: xargs
产生某个指令的参数, xargs 可以读入 stdin 的数据,并且以空格符或断行字符作为分辨,将 stdin 的资料分隔成为 arguments
$ xargs [-0epn] command
选项与参数:
-0 :如果输入的 stdin 含有特殊字符,例如 `, \, 空格键等等字符时,这个 -0 参数可以将他还原成一般字符。
-e :这个是 EOF (end of file) 的意思。后面可以接一个字符串,当 xargs 分析到这个字符串时,就会停止继续工作!
-p :在执行每个指令的 argument 时,都会询问使用者的意思;
-n :后面接次数,每次 command 指令执行时,要使用几个参数的意思。
当 xargs 后面没有接任何的指令时,默认是以 echo 来进行输出
关于减号 - 的用途
在管道命令当中,常常会使用到前一个指令的 stdout 作为这次的 stdin , 某些指令需要用到文件名 (例如 tar) 来进行处理时,该 stdin 与 stdout 可以利用减号 "-" 来替代
参考文档:
《鸟哥的Linux私房菜基础篇第三版》