浅析Java8中的Stream API (1)
Stream API
Stream API是什么?
Stream API是Java8类库的核心,它能够应用在一组元素上一次执行的操作序列。Stream操作分为中间操作(StatelessOP、StatefulOP)或者最终操作(TerminalOP)两种,最终操作返回一特定类型的计算结果,而中间操作返回Stream本身,这样你我们就可以将多个操作串起来。 使用Stream的时候需要指定一个数据源,它包括List, Set等集合类。
Stream 是对集合(Collection)对象功能的增强,它专注于对集合对象进行各种非常便利、高效的聚合操作(aggregate operation),或者大批量数据操作 (bulk data operation)。Stream API 借助于同样新出现的 Lambda 表达式,极大的提高编程效率和程序可读性。同时它提供串行和并行两种模式进行汇聚操作,并发模式能够充分利用多核处理器的优势,使用 fork/join 并行方式来拆分任务和加速处理过程。通常编写并行代码很难而且容易出错, 但使用 Stream API 无需编写一行多线程的代码,就可以很方便地写出高性能的并发程序。
简单使用:
一个简单的例子:
List test = new ArrayList<>();
test.add("ABC");
test.add("ABC");
test.add("DEF");
test.add("");
List result = test.stream()
.distinct()
.filter("ABC"::equals)
.map(String::toLowerCase)
.collect(Collectors.toList());
System.out.println(result); 得到结果是:

例子中只用到了fileter、map和collect,distinct去除了集合中的重复值,fileter过滤了集合中不等于”ABC”的值,map将每一个值做toLowerCase操作,最终collect操作作为最终操作,返回了最终处理后的结果。
从StatelessOP 、 StatefulOP 和 TerminalOP开始
上面的例子包含了恰好包含了三种操作,具体Stream中的其他操作的类型分类如下:
| Stream操作分类 | 中间操作 |
|---|---|
| 无状态(StatelessOP) | unordered(),filter(),map(),mapToInt(),mapToLong(),mapToDouble(), flatMap(),flatMapToInt(),flatMapToLong(),flatMapToDouble(),peek() |
| 有状态(StatefulOP) | distinct(),sorted(),limit(),skip() |
| 最终操作(TerminalOP) | forEach(),forEachOrdered(),toArray(),reduce(),collect(),max(),min(), count(),anyMatch(),allMatch(),noneMatch(),findFirst(),findAny() |
先从map操作的源码开始:
@Override
@SuppressWarnings("unchecked")
public final Stream map(Functionsuper P_OUT, ? extends R> mapper) {
// 判空
Objects.requireNonNull(mapper);
// 创建了StatelessOP对象并返回
return new StatelessOp(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
// 实现Sink接口中的accept方法,其中accept表示接受具体的输入数据,downstream表示下游接收器。
// 这里的输入数据是mapper.apply()处理后的值,即对原数据进行了map操作
@Override
Sink opWrapSink(int flags, Sink sink) {
// 包装sink的具体操作,不断将传入的sink作为新sink的下游接收器,最终形成sink链
return new Sink.ChainedReference(sink) {
// accept方法在spliterator.forEachRemaining()内被真正执行
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
} 从源码中可以看到,中间操作filter、map等,都会生成新的StatelessOP(或StatefulOP)对象,它们都继承自ReferencePipeline对象,ReferencePipeline继承了AbstractPipeline抽象类,它实质是一个管道(带头结点的双端队列),用于连接上一阶段(操作)管道和下一阶段管道。
StatelessOP的源码:
abstract static class StatelessOp<E_IN, E_OUT>
extends ReferencePipeline<E_IN, E_OUT> {
// upstream 上游管道
// StreamShape 上游管道的流类型(引用 整形 Long Double)
// opFlags 新阶段的标志
StatelessOp(AbstractPipeline upstream,
StreamShape inputShape,
int opFlags) {
// 最终调用AbstractPipeline的构造方法创建新的管道
super(upstream, opFlags);
assert upstream.getOutputShape() == inputShape;
}
@Override
final boolean opIsStateful() {
return false;
}
}AbstractPipeline的两个构造方法如下:
// 头管道节点(head)的构造方法
AbstractPipeline(Spliterator source,
int sourceFlags, boolean parallel) {
this.previousStage = null;
this.sourceSpliterator = source;
// 制定自己为头结点
this.sourceStage = this;
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;
this.depth = 0;
this.parallel = parallel;
}
// 之后连接管道节点的构造方法
AbstractPipeline(AbstractPipeline previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;
previousStage.nextStage = this;
this.previousStage = previousStage;
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
this.sourceStage = previousStage.sourceStage;
if (opIsStateful())
sourceStage.sourceAnyStateful = true;
this.depth = previousStage.depth + 1;
}之前的map的代码,返回一个新的StatelessOP对象时,还重写了AbstractPipeline的opWrapSink方法。
这个方法对几个操作类中的Sink进行组装,返回一个组装后的Sink链。组装结果如下图所示:
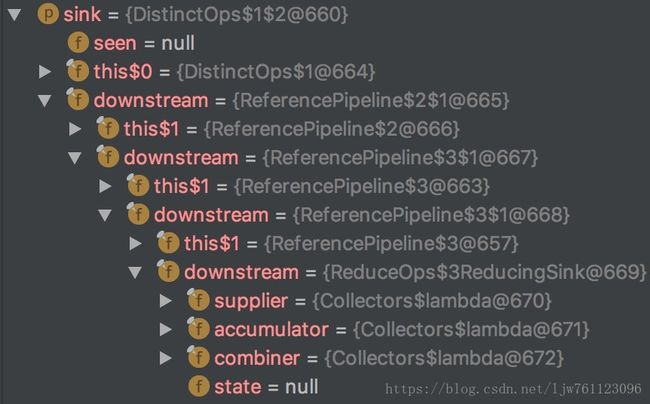
其中downstream代表Stream中的下一操作。Stream通过管道中的Sink(接收器),进行accept操作,并将结果传给下游接收器,并在达到最终操作后返回最终结果。
Sink接口
上面的Sink是一个接口,它继承了Consumer接口,Sink(接收器)用于数据流在各个阶段的管道中传递,并提供流大小管理与控制等额外方法。该接口提供了四个基本方法:
| 方法名 | 用处 |
|---|---|
| accept() | 表示接收器对给定的参数执行此操作 |
| begin(long size) | 重置接收器状态以接收新数据集,其中size表示下游推送数据的确切大小 |
| end() | 表示此接收器已推送所有数据 |
| cancellationRequested() | 表示此接收器不希望再接收任何数据 |
中间阶段(非最终操作)所做的事只是记录和叠加操作,而真正执行操作的是由最终操作触发的。上面的例子中,distinct、filter、map都只是将各自的中间操作不断的组装成一个Sink对象,形成一个Sink链,最终由collect操作触发。所有的最终操作都会调用TerminalOp的evaluateParallel(对应并发操作)或evaluateSequential(对应串行处理)。并调用AbstractPipeline的wrapAndCopyInto方法组装Sink:
// 返回执行操作后的sink
@Override
final > S wrapAndCopyInto(S sink, Spliterator spliterator) {
copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);
// 返回最终结果
return sink;
}
// 具体的组装方法
@Override
@SuppressWarnings("unchecked")
final Sink wrapSink(Sink sink) {
Objects.requireNonNull(sink);
// 具体的组装语句,从管道中不断获取上一操作,并组装成sink链
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
// 返回组装好的sink
return (Sink) sink;
}
// 传入组装好的sink对象
@Override
final void copyInto(Sink wrappedSink, Spliterator spliterator) {
Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
// 具体的Stream操作 例如map、filter等。accept方法真正的执行者
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
}
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
} 其中forEachRemaining()方法根据Spliterator和传入的Sink类型,执行对应的方法,例如ArrayListSpliterator类的forEachRemaining方法:
public void forEachRemaining(Consumersuper E> action) {
int i, hi, mc;
ArrayList lst; Object[] a;
if (action == null)
throw new NullPointerException();
if ((lst = list) != null && (a = lst.elementData) != null) {
if ((hi = fence) < 0) {
mc = lst.modCount;
hi = lst.size;
}
else
mc = expectedModCount;
if ((i = index) >= 0 && (index = hi) <= a.length) {
for (; i < hi; ++i) {
@SuppressWarnings("unchecked") E e = (E) a[i];
// accept()真正的执行处
action.accept(e);
}
if (lst.modCount == mc)
return;
}
}
throw new ConcurrentModificationException();
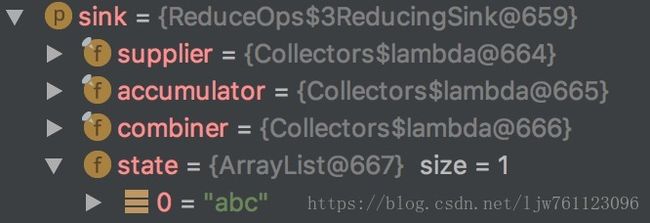
} 例子中最终操作collect中的Sink中的结果就是最终的Stream结果:
以上在并行状态时还会涉及Fork/Join框架,在以后的博客中我可能会进一步分析。