分布式id介绍及应用
ZooKeeper
zookeeper的命名服务,主要是利用zookeepeer节点的树型分层结构和子节点的次序维护能力,为分布式系统中的资源命名与标识能力。
zookeeper的分布式命名服务,典型的应用场景有:
(1)提供分布式JNDI的API目录服务功能。
可以把系统中各种API接口服务的名称、链接地址放在zookeeper的树形分层结果中,提供分布式的API调用能力。著名的分布式框架,就是应用了zookeeper的分布式的JNDI能力。
开源的分布式服务框架Dubbo中使用ZooKeeper来作为其命名服务,维护全局的服务接口API地址列表。在Dubbo实现中,provider服务提供者在启动的时候,向ZK上的指定节点/dubbo/${serviceName}/providers文件夹下写入自己的API地址,这个操作就相当于服务的公开。
consumer服务消费者启动的时候,订阅节点/dubbo/{serviceName}/providers文件夹下的provider服务提供者URL地址,获得所有的访问提供者的API。
(2)制作分布式的ID生成器,为分布式系统中的每一个数据资源,提供的唯一的标识能力。
在单体服务环境下,我们唯一标识一个数据资源,通常利用数据库的主键自增功能。但是在大量服务器集群的场景下,依赖单体服务的数据库主键自增生成唯一ID,没有办法满足高并发和高负载的需求。
(3)分布式节点的命名服务
一个分布式系统会有很多的节点组成,而且,节点的数量是不断动态变化的。根据业务的膨胀需要和迎接流量洪峰,可能会加入大量的动态很多节点。流量洪峰过去,就需要下线大量的节点。或者说,由于机器或者网络的原因,一些节点主动的离开的集群。
如何为大量的动态节点命名呢?一种简单的办法是,可以通过配置文件,手动的进行每一个节点的命名。但是如果节点数据量太大,或者说变动频繁,手动命名是不现实的,这就需要用到分布式节点的命名服务。
疯狂创客圈的分布式IM实战项目,也会使用分布式命名服务,为每一个IM节点动态命名。
算法:分布式id生成算法SnowFlake

符号位说明:
第一位为不能为负的符号位:0
时间戳说明:
41位记录时间戳timeMillis,不是存储当前时间的时间截,而是存储时间截的差值,即当前系统时间 - 默认固定时间的值(开始时间截一般是我们的id生成器开始使用的时间,由我们程序来指定的)
工作机器ID说明:
10位的数据机器位id,可以部署在1024个节点,即datacenterId (5位数据id) + workerId (5位机器id)
datacenterId 与 workerId的最大值十进制值是31(不能为负数)
原因:5位数的最大二进制表示: 0001 1111 —> 十进制:31
序列号说明:
12位自增序列号sequence,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号
Sequence的最大十进制值是4095(不能为负数)
原因:12位数的最大二进制表示:1111 1111 1111 —> 十进制:4095
二进制说明:
按位或,按位与,异或计算例子:

位移说明:

计算所需默认常量:
默认固定时间twepoch: 1288834974657(毫秒)(小于当前时间即可,不能出现负数)
时间戳偏移位数 timestampLeftShift:22(给5位机器id、5位数据id、12位序列号移除位置)
数据id偏移位数 datacenterIdShift:17(给5位数据id、12位序列号移除位置)
机器id偏移位数 workerIdShift:12(给12位序列号移除位置)
开始计算:
一,需要输入的条件(以这4个数据为例):
- 当前时间 timwstamp:1563244877076(毫秒)
- 机器id workerId:6(本机ip)
- 数据id datacentId:20(当前进程Hashmap)
- 序列号sequence:0(自增序列号)
二,计算:
计算公式

步骤:
1.首先计算时间戳;即:timeMillis = timestamp(当前时间) – twepoch(固定时间)
timeMillis : 1563244877076 – 1288834974657 = 274409902419
2.再先分别计算左位移结果
timeMillis << timestampLeftShift
转换: 274409902419 << 22
二进制: 0011111111100100000110101101000101010011 << 22
//位移前
0000 0000 0000 0000 0000 0000 0011 1111 1110 0100 0001 1010 1101 0001 0101 0011
//位移22位后的结果(标记:a)
0000 1111 1111 1001 0000 0110 1011 0100 0101 0100 1100 0000 0000 0000 0000 0000
datacenterId << datacenterIdShift
转换: 20 << 17
二进制:0001 0100 << 17
//位移前
0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0001 0100
//位移17位后的结果(标记:b)
0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0010 1000 0000 0000 0000 0000
workerId << workerIdShift
转换:6 << 12
二进制:0000 0110 << 12
//位移前
0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0110
//位移12位后的结果(标记:c)
0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0110 0000 0000 0000
3.最后计算按位或的结果
计算公式带入值:
274409902419 << 22 |
20 << 17 |
6 << 12 |
0
||
|| 简化
\ || /
a | b | c | 0
||
|| 二进制表示
\ || /
| 41位 | 5 | 5 | 12位
0|000 1111 1111 1001 0000 0110 1011 0100 0101 0100 11|00 000|0 0000| 0000 0000 0000 | //a
0|000 0000 0000 0000 0000 0000 0000 0000 0000 0000 00|10 100|0 0000| 0000 0000 0000 | //b
0|000 0000 0000 0000 0000 0000 0000 0000 0000 0000 00|00 000|0 0110| 0000 0000 0000 | //c
0|000 0000 0000 0000 0000 0000 0000 0000 0000 0000 00|00 000|0 0000| 0000 0000 0000 | //0
0|000 1111 1111 1001 0000 0110 1011 0100 0101 0100 11|10 100|0 0110| 0000 0000 0000 //结果
最终结果:
二进制:0000 1111 1111 1001 0000 0110 1011 0100 0101 0100 1110 1000 0110 0000 0000 0000
十进制:1150958551358267392
SnowFlake算法的优点:
(1)生成ID时不依赖于数据库,完全在内存生成,高性能高可用。
(2)容量大,每秒可生成几百万ID。
(3)ID呈趋势递增,后续插入数据库的索引树的时候,性能较高。
SnowFlake算法的缺点:
(1)依赖于系统时钟的一致性。如果某台机器的系统时钟回拨,有可能造成ID冲突,或者ID乱序。
(2)还有,在启动之前,如果这台机器的系统时间回拨过,那么有可能出现ID重复的危险。
SnowFlake + Zookeeper = id-generator
分布式 ID 生成器的类型
在分布式系统中,ID生成器的使用场景,非常非常多:
(1)大量的数据记录,需要分布式ID
(2)大量的系统消息,需要分布式ID
(3)大量的请求日志,如http请求记录,需要唯一标识,以便进行后续的用户行为分析和调用链路分析,等等等等。
传统的数据库自增主键,或者单体的自增主键,已经不能满足需求。在分布式系统环境中,迫切需要一个全新的唯一ID的系统,这个系统需要满足以下需求:
(1)全局唯一:不能出现重复ID
(2)高可用:ID生成系统是基础系统,被许多关键系统调用,一旦宕机,会造成严重影响。
分布式唯一ID生成分案有很多种:
(1) java的UUID
(2) 利用分布式缓存Redis生成ID
利用Redis的原子操作INCR和INCRBY,生成全局唯一的ID。
(3) Twitter的snowflake算法
(4) ZooKeeper生成ID
利用ZooKeeper 的顺序节点,生成全局唯一的ID。
(5) MongoDb的ObjectId
利用分布式Nosql MongDB,生成全局唯一的ID。
UUID方案
UUID是Universally Unique Identifier的缩写,它是在一定的范围内(从特定的名字空间到全球)唯一的机器生成的标识符。UUID在其他语言中也叫GUID,在java中,生成UUID的代码很简单:
String uuid = UUID.randomUUID().toString()一个UUID是16字节长的数字,一共128位。通常以36字节的字符串表示,比如:3F2504E0-4F89-11D3-9A0C-0305E82C3301。 使用的时候,可以把中间的4个中划线去掉,剩下32位字符串。
UUID经由一定的算法机器生成,为了保证UUID的唯一性,规范定义了包括网卡MAC地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素,以及从这些元素生成UUID的算法。UUID的只能由计算机生成。
UUID的优点:本地生成ID,不需要进行远程调用,时延低,性能高。
UUID的缺点:UUID过长,16字节128位,通常以36长度的字符串表示,很多场景不适用,比如,由于UUID没有排序,无法保证趋势递增,用做数据库索引字段的效率就很低,新增记录存储入库时性能差
从高并发,高可用的角度出发,通过ZooKeeper实现分布式系统唯一ID的方案,是最为合适的解决方案之一。
常见的UID优缺点
数据库自增ID
简单可靠,有序,可读性好,性能也不错。缺点是要锁表,性能会有瓶颈,分库特别是已分库的情况再扩容时会比较麻烦。
UUID
全球唯一,性能好,缺点是太长了,存储空间大,索引性能不好,长度太长使用起来也不方便。另外部分UUID算法生成的不是趋势递增的。
Redis生成
性能好,有序,可读性好。缺点是为了防单点故障,需要引入Redis集群,增加了额外编码和配置的工作量。
Snowflake生成ID
twitter开发的一套全局唯一ID生成算法,要点如下:
41位的时间序列(精确到毫秒,41位的长度可以使用69年)
10位的机器标识(10位的长度最多支持部署1024个节点)
12位的计数顺序号(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号)
最高位是符号位,始终为0。
简单可靠,性能好,趋势有序,不引入第三方系统。缺点是有使用时间限制,8-100年不等,序列不是连续有序。
如何选择
在分布式下,考虑到性能,存储效率和使用方便性,一般不会直接用UUID来做表唯一字段的ID的。另外UUID有可能泄露MAC地址。
如果没有分库的话,用数据库自增ID是不错的选择。
如果有分库可以使用不同步长的自增ID来避免冲突,如果还有继续扩容的可能的话,建议直接使用Redis或Snowflake的方案。
如果对连续性有要求的话,建议使用Redis生成方案,如果对连续性没有要求或者要求干净轻爽的方式的话,建议使用Snowflake方案。
另外连续ID有可能泄露业务信息,根据早晚的ID号,很容易推算出一天的业务量。
Snowflake的改进实现
各开源项目都基于原始算法做了点改进,比如:处理时间回拨问题,调整各段的位数,使用缓存增强并发性能。在虚拟环境下,如k8s下,如何避免多个实例出现相同的worker id等。
比较好的实现有:
百度uid-generator:https://github.com/baidu/uid-generator
美团leaf:https://github.com/zhuzhong/idleaf
我的实现主要是参考了百度的实现。所不同的是,进一步做了简化,百度使用一个数据库表来保存worker id的信息,每次实例启动的时候给一个新号,可以支持几百万次重启。我的实现是去掉了数据库依赖,直接根据机器的IP后24位做worker id。在k8s环境下,网络CIDR默认是-/24,也就是最后24位是不同的,所以用24位IP来做worker id是可以完全避免冲突。相应的,单例每秒的序列号数量有所减少,只有2048个,不过对大部分应用也是够用的。
另外补充解释下,为啥要用这么多位数用于避免worker id重复,实际部署的系统一般也就几百几千台机器/虚拟机,直接为不同的应用指定不同的id不就完了吗?这主要是考虑在Spring Cloud或者k8s这样的环境里,每个应用是有可能同时开好几个实例的,如果worker id是硬编码或者固定配置的,那所有相同应用的实例都会是相同的worker id,肯定会造成UID冲突的。所以就需要有一个渠道能得到唯一的id。那这个渠道在类似k8s这样的虚拟环境下,无非是数据库保存,或者pod ip了。我嫌用数据库又多引进了一个依赖,希望一个尽可能独立干净的实现,所以我使用ip后24位的方式来做worker id。如果将k8s POD网络的CIDR设成-/16的,那就更完美了,用ip的后16位做唯一worker id,同时把时间位和序列位各加4个,那就可以支持单例每秒32768个序列,连续使用128年了。
综合方案(SnowflakeX)
基于snowflake方案,引入时间回拨保护机制,形成趋于完美的方案
应用启动校验流程(新增)
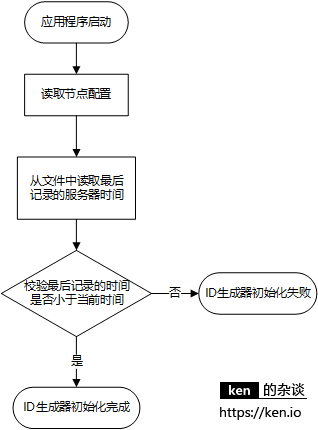
时间打点机制(新增)
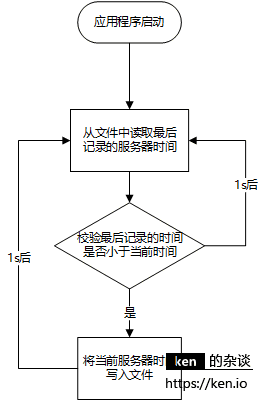
ID生成时时间校验机制(原有)
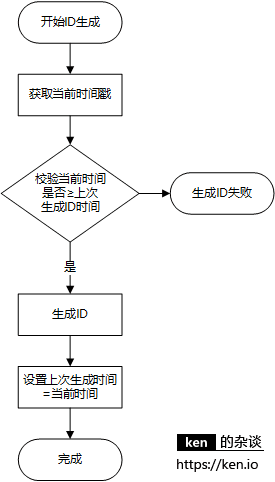
通过这三种保障机制,不管是程序运行时服务器时间发生了回拨,
还是说应用down机的同时,发生了时间回拨等恶劣情况,都可以保证生成的ID不重复
不过,虽然理论上每秒单机可以生成400W+的ID,实际在使用过程中,如果中心化部署,通过API的方式来使用,还要考虑到实际的网络消耗。
测试情况:
测试机1台: Intel 2.30GHz 双核 虚拟机 百兆网卡
测试结果:通过HTTP API每秒可获取100W的ID
方案对比
| 方案 | 唯一性 | 每秒100W+ | 趋于递增 | 高可用 | 可伸缩 |
|---|---|---|---|---|---|
| UUID | 基本满足 | 满足 | 不满足 | 满足 | 满足 |
| 数据库自增列 | 满足 | 不满足 | 满足 | 基本满足 | 不满足 |
| Snowflake | 基本满足 | 满足 | 满足 | 满足 | 满足 |
| SnowflakeX | 满足 | 满足 | 满足 | 满足 | 满足 |
Zookeeper方案
在分布式集群中,可能需要部署的大量的机器节点。在节点少的受,可以人工维护。在量大的场景下,手动维护成本高,考虑到自动部署、运维等等问题,节点的命名,最好由系统自动维护。
节点的命名,主要是为节点进行唯一编号。主要的诉求是,不同节点的编号,是绝对的不能重复。一旦编号重复,就会导致有不同的节点碰撞,导致集群异常。
在Zookeeper中,node可以分为持久节点和临时节点两类。临时节点的生命周期和客户端会话绑定,一旦客户端会话失效,那么这个客户端创建的所有临时节点都会被移除。
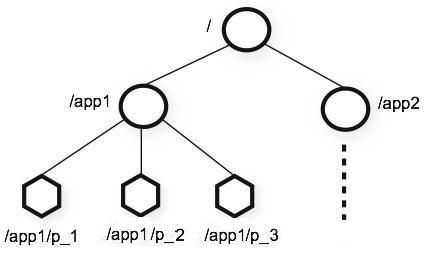
有以下两个方案,可供生成集群节点编号:
(1)使用数据库的自增ID特性,用数据表,存储机器的mac地址或者ip来维护。
(2)使用ZooKeeper持久顺序节点的次序特性。来维护节点的编号。
这里,我们采用第二种,通过ZooKeeper持久顺序节点特性,来配置维护节点的编号NODEID。
集群节点命名服务的基本流程是:
(1)启动节点服务,连接ZooKeeper, 检查命名服务根节点根节点是否存在,如果不存在就创建系统根节点。
(2)在根节点下创建一个临时顺序节点,取回顺序号做节点的NODEID。如何临时节点太多,可以根据需要,删除临时节点。

(1)第一位
占用1bit,其值始终是0,没有实际作用。
(2)时间戳
占用41bit,精确到毫秒,总共可以容纳约69年的时间。
(3)工作机器id
占用10bit,最多可以容纳1024个节点。
(4)序列号
占用12bit,最多可以累加到4095。这个值在同一毫秒同一节点上从0开始不断累加。
总体来说,在工作节点达到1024顶配的场景下,SnowFlake算法在同一毫秒内最多可以生成多少个全局唯一ID呢?这是一个简单的乘法:
同一毫秒的ID数量 = 1024 X 4096 = 4194304
400多万个ID,这个数字在绝大多数并发场景下都是够用的。
snowflake 算法中,第三个部分是工作机器ID,可以结合上一节的命名方法,并通过Zookeeper管理workId,免去手动频繁修改集群节点,去配置机器ID的麻烦。
zookeeper分布式锁的原理
理解了锁的原理后,就会发现,Zookeeper 天生就是一副分布式锁的胚子。
首先,Zookeeper的每一个节点,都是一个天然的顺序发号器。
在每一个节点下面创建子节点时,只要选择的创建类型是有序(EPHEMERAL_SEQUENTIAL 临时有序或者PERSISTENT_SEQUENTIAL 永久有序)类型,那么,新的子节点后面,会加上一个次序编号。这个次序编号,是上一个生成的次序编号加一
比如,创建一个用于发号的节点“/test/lock”,然后以他为父亲节点,可以在这个父节点下面创建相同前缀的子节点,假定相同的前缀为“/test/lock/seq-”,在创建子节点时,同时指明是有序类型。如果是第一个创建的子节点,那么生成的子节点为/test/lock/seq-0000000000,下一个节点则为/test/lock/seq-0000000001,依次类推,等等。
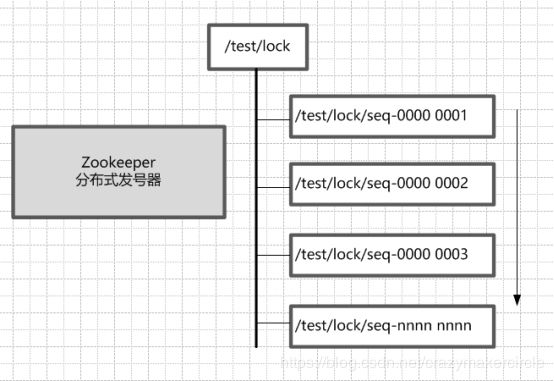
其次,Zookeeper节点的递增性,可以规定节点编号最小的那个获得锁。
一个zookeeper分布式锁,首先需要创建一个父节点,尽量是持久节点(PERSISTENT类型),然后每个要获得锁的线程都会在这个节点下创建个临时顺序节点,由于序号的递增性,可以规定排号最小的那个获得锁。所以,每个线程在尝试占用锁之前,首先判断自己是排号是不是当前最小,如果是,则获取锁。
第三,Zookeeper的节点监听机制,可以保障占有锁的方式有序而且高效。
每个线程抢占锁之前,先抢号创建自己的ZNode。同样,释放锁的时候,就需要删除抢号的Znode。抢号成功后,如果不是排号最小的节点,就处于等待通知的状态。等谁的通知呢?不需要其他人,只需要等前一个Znode 的通知就可以了。当前一个Znode 删除的时候,就是轮到了自己占有锁的时候。第一个通知第二个、第二个通知第三个,击鼓传花似的依次向后。
Zookeeper的节点监听机制,可以说能够非常完美的,实现这种击鼓传花似的信息传递。具体的方法是,每一个等通知的Znode节点,只需要监听linsten或者 watch 监视排号在自己前面那个,而且紧挨在自己前面的那个节点。 只要上一个节点被删除了,就进行再一次判断,看看自己是不是序号最小的那个节点,如果是,则获得锁。
为什么说Zookeeper的节点监听机制,可以说是非常完美呢?
一条龙式的首尾相接,后面监视前面,就不怕中间截断吗?比如,在分布式环境下,由于网络的原因,或者服务器挂了或则其他的原因,如果前面的那个节点没能被程序删除成功,后面的节点不就永远等待么?
其实,Zookeeper的内部机制,能保证后面的节点能够正常的监听到删除和获得锁。在创建取号节点的时候,尽量创建临时znode 节点而不是永久znode 节点,一旦这个 znode 的客户端与Zookeeper集群服务器失去联系,这个临时 znode 也将自动删除。排在它后面的那个节点,也能收到删除事件,从而获得锁。
说Zookeeper的节点监听机制,是非常完美的。还有一个原因。
Zookeeper这种首尾相接,后面监听前面的方式,可以避免羊群效应。所谓羊群效应就是每个节点挂掉,所有节点都去监听,然后做出反映,这样会给服务器带来巨大压力,所以有了临时顺序节点,当一个节点挂掉,只有它后面的那一个节点才做出反映。
Zookeeper分布式锁
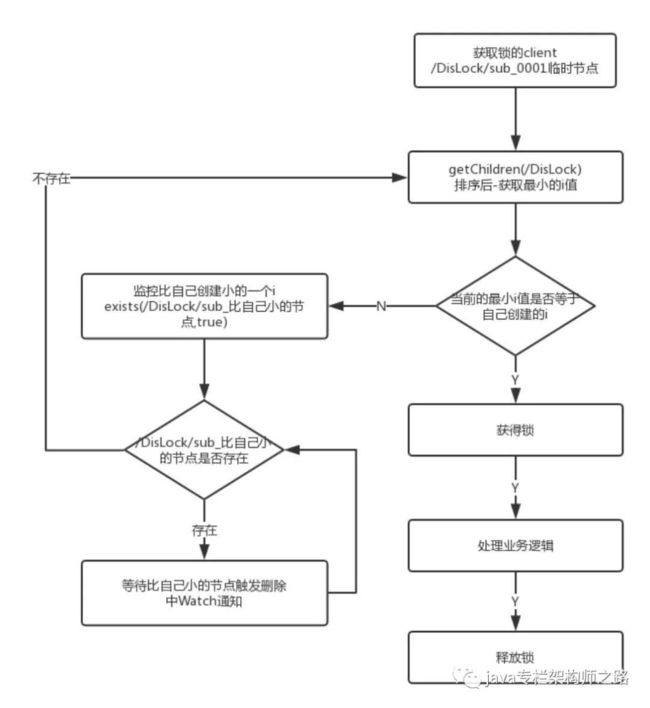
我们将锁抽象成目录,多个线程在此目录下创建瞬时的序列节点,因为Zk会为我们保证节点的序列性,所以可以利用节点的序列进行锁的判断。
首先创建序列节点进行升序排序,然后获取当前目录下最小的节点,判断最小节点是不是当前节点,如果是那么获取锁成功,如果不是那么获取锁失败。
获取锁失败的节点获取当前节点上一个顺序节点,对此节点注册监听,当节点删除的时候通知当前节点。
当unlock的时候删除节点之后会通知下一个节点。
3、ZK VS Redis 锁对比

4、ZK命名服务-ID生成器
zk特性:顺序节点的特性+snowflake方案

41-bit的时间可以表示(1L
到家采用:1+41+5+5+12 方案 即:时间+ center_id +worker_id+随机数
优点:
毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
可以根据自身业务特性分配bit位,非常灵活。
解决时钟问题
因为这种方案依赖时间,如果机器的时钟发生了回拨,那么就会有可能生成重复的ID号,需要解决时钟回退的问题。
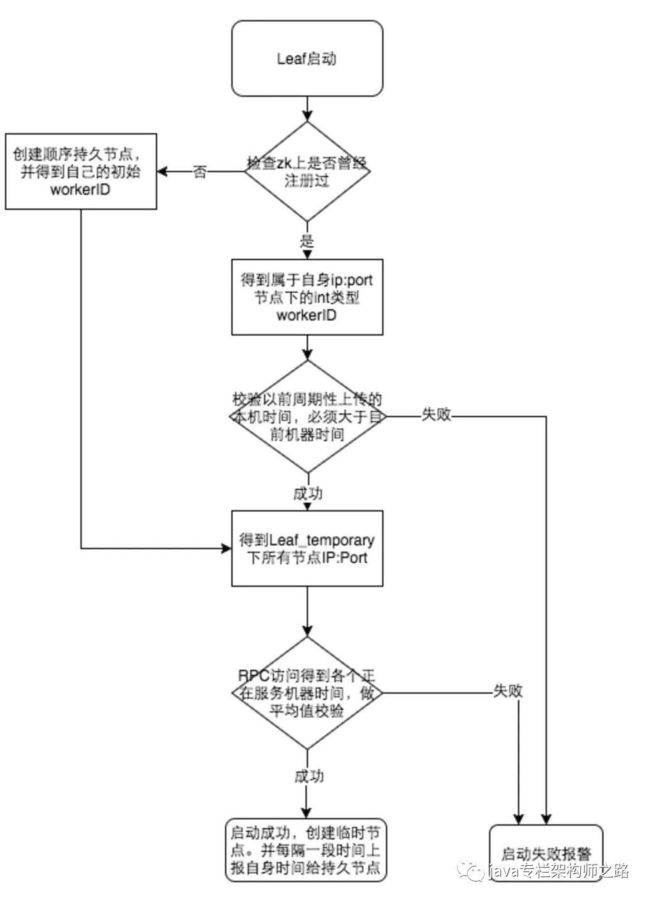
参见上图整个启动流程图,服务启动时首先检查自己是否写过ZooKeeper leaf_forever节点:
若写过,则用自身系统时间与leaf_forever/$节点记录时间做比较,若小于leaf_forever/$时间则认为机器时间发生了大步长回拨,服务启动失败并报警。
若未写过,证明是新服务节点,直接创建持久节点leaf_forever/$并写入自身系统时间,接下来综合对比其余Leaf节点的系统时间来判断自身系统时间是否准确,具体做法是取leaf_temporary下的所有临时节点(所有运行中的Leaf-snowflake节点)的服务IP:Port,然后通过RPC请求得到所有节点的系统时间,计算sum(time)/nodeSize。
若abs( 系统时间-sum(time)/nodeSize )
否则认为本机系统时间发生大步长偏移,启动失败并报警。
每隔一段时间(3s)上报自身系统时间写入leaf_forever/$。
项目介绍
基于Twitter的SnowFlake算法实现的分布式ID发号器。支持手动或通过Zookeeper分配workerId。配置简单,操作简易。生成的id具备全局唯一,粗略有序,可反向解码等特性。
数据结构
毫秒级
| 时间位 | 数据中心 | 工作机器 | 序号位 | |
|---|---|---|---|---|
| 位数 | 41 | 5 | 5 | 12 |
- 时间41位,可以使用2^41/1000/60/60/24/365=69.73, 约可使用69年
- 数据中心5位, 可部署2^5=32个数据中心
- 工作机器5位,同一个数据中心可部署2^5=32个服务
- 序号12位,表示同一机器同一时间(毫秒)内理论上可以产生最多2^12-1=4095个ID序号
秒级
| 时间位 | 数据中心 | 工作机器 | 序号位 | |
|---|---|---|---|---|
| 位数 | 31 | 5 | 5 | 22 |
- 时间31位,可以使用2^31/60/60/24/365=68, 约可使用68年
- 数据中心5位, 可部署2^5=32个数据中心
- 工作机器5位,同一个数据中心可部署2^5=32个服务
- 序号22位,表示同一机器同一时间(秒)内理论上可以产生最多2^22-1=4194303个ID序号
安装
- 在pom.xml文件中增加以下仓库
iwanttomakemoney_admin
https://gitee.com/iwanttomakemoney_admin/maven/raw/master/repository
引入以下依赖
com.lxm
id-generator-interface
2.3
com.lxm
id-generator-core
2.3
配置
基于spring boot的项目
- 在yml或property配置文件中设置所需的参数.(此步骤非必需,若跳过此步骤将生效默认配置)
- 在启动类上增加
@EnableIdGenerator注解即可. 如
@SpringBootApplication
@EnableIdGenerator
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
使用
在需要的地方注入服务即可使用,如:
@Service
class DemoService {
@Autowired
private IdService idService;
public void test() {
// 通过自动装配提供的服务
long id1 = idService.genId();
// 通过单例的形式提供的服务
long id2 = IdUtil.service().genId();
...
}
}API
// 生成id
long idService.genId();
// 批量生成id
long[] batchGenId(int count);
// 解析id
Id decode(long id);
// 手动生成id
long encode(long time, long dataCenterId, long workerId, long seq);
// 解析id中的时间戳
Date transTime(long time);参数
| 属性 | 类型 | 缺省值 | 描述 |
|---|---|---|---|
| id.zookeeper.enable | Boolean | false | 是否启用Zookeeper分配workerId。 默认为false表示使用手动分配workerId;若为true则需预先准备至少一个的Zookeeper服务 |
| id.zookeeper.serverLists | String | null | 连接Zookeeper服务器的列表 包括IP地址和端口号 多个地址用逗号分隔如:host1:2181,host2:2181 |
| id.zookeeper.digest | String | null | 连接Zookeeper的权限令牌 缺省为不需要权限验证 |
| id.zookeeper.namespace | String | "id-generator" | Zookeeper的命名空间 |
| id.zookeeper.baseSleepTime | Integer | 1000 | 等待重试的间隔时间的初始值 单位:毫秒 |
| id.zookeeper.maxSleepTime | Integer | 3000 | 等待重试的间隔时间的最大值 单位:毫秒 |
| id.zookeeper.maxRetries | Integer | 3 | 最大重试次数 |
| id.zookeeper.sessionTimeout | Integer | 60000 | 会话超时时间 单位:毫秒 |
| id.zookeeper.connectionTimeout | Integer | 15000 | 连接超时时间 单位:毫秒 |
| id.type.second=false | Boolean | false | true-秒级别 false-毫秒级别 |
| id.workerId | Integer | 0 | 手动指定工作机器号,当id.zookeeper.enable=false有效 |
| id.datacenterId | Integer | -1 | 手动指定数据中心, 若不指定则将根据mac地址自动分配一个固定的编号 |
参考:
https://www.cnblogs.com/crazymakercircle/p/10225332.html
https://segmentfault.com/a/1190000015356486
https://blog.csdn.net/javaboy/article/details/81978286
https://cloud.tencent.com/developer/news/245438
https://gitee.com/simpleweb/id-generator