MapReduce第三天:MapTask、ReduceTask机制、OutputFormat数据输出、Join应用、MapReduce Join、计数器应用、数据清洗ETL、MapReduce开发总结
接上篇第3章的3.3.10MapReduce第二天:Hadoop序列化及Writable接口、InputFormat数据输入、自定义InputFormat、FileInputFormat切片
MapReduce代码要多写多练
本文目录
3.4MapTask工作机制
3.5 ReduceTask工作机制
3.6OutputFormat数据输出
3.6.1OutputFormat接口实现类
3.6.2自定义OutputFormat
3.6.3自定义OutputFormat案例实操
3.7 Join多种应用
3.7.1 Reduce Join
3.7.2Reduce Join案例实操
3.7.3 Map Join
3.7.4Map Join案例实操
3.8计数器应用
3.9数据清洗(ETL)
3.9.1数据清洗案例实操-简单解析版
3.9.2数据清洗案例实操-复杂解析版
3.10MapReduce开发总结
3.4 MapTask工作机制
MapTask工作机制如图4-12所示。
这张图要在脑海里能画出来

图4-12 MapTask工作机制
(1)Read阶段:MapTask通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value。
(2)Map阶段:该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value。
(3)Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中。
(4)Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
溢写阶段详情:
步骤1:利用快速排序算法对缓存区内的数据进行排序,排序方式是,先按照分区编号Partition进行排序,然后按照key进行排序。这样,经过排序后,数据以分区为单位聚集在一起,且同一分区内所有数据按照key有序。
步骤2:按照分区编号由小到大依次将每个分区中的数据写入任务工作目录下的临时文件output/spillN.out(N表示当前溢写次数)中。如果用户设置了Combiner,则写入文件之前,对每个分区中的数据进行一次聚集操作。
步骤3:将分区数据的元信息写到内存索引数据结构SpillRecord中,其中每个分区的元信息包括在临时文件中的偏移量、压缩前数据大小和压缩后数据大小。如果当前内存索引大小超过1MB,则将内存索引写到文件output/spillN.out.index中。
(5)Combine阶段:当所有数据处理完成后,MapTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
当所有数据处理完后,MapTask会将所有临时文件合并成一个大文件,并保存到文件output/file.out中,同时生成相应的索引文件output/file.out.index。
在进行文件合并过程中,MapTask以分区为单位进行合并。对于某个分区,它将采用多轮递归合并的方式。每轮合并io.sort.factor(默认10)个文件,并将产生的文件重新加入待合并列表中,对文件排序后,重复以上过程,直到最终得到一个大文件。
让每个MapTask最终只生成一个数据文件,可避免同时打开大量文件和同时读取大量小文件产生的随机读取带来的开销。
3.5 ReduceTask工作机制
1.ReduceTask工作机制
ReduceTask工作机制,如图4-19所示。

图4-19 ReduceTask工作机制
(1)Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
(2)Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
(3)Sort阶段:按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
(4)Reduce阶段:reduce()函数将计算结果写到HDFS上。
2.设置ReduceTask并行度(个数)
ReduceTask的并行度同样影响整个Job的执行并发度和执行效率,但与MapTask的并发数由切片数决定不同,ReduceTask数量的决定是可以直接手动设置:
// 默认值是1,手动设置为4
job.setNumReduceTasks(4);
3.实验:测试ReduceTask多少合适
(1)实验环境:1个Master节点,16个Slave节点:CPU:8GHZ,内存: 2G
(2)实验结论:
表4-3 改变ReduceTask (数据量为1GB)
| MapTask =16 |
|---|
| ReduceTask 1 5 10 15 16 20 25 30 45 60 |
| 总时间 892 146 110 92 88 100 128 101 145 104 |
4.注意事项
(1)ReduceTask=0,表示没有Reduce阶段,输出文件个数和Map个数一致。
(2)ReduceTask默认值就是1,所以输出文件个数为一个。
(3)如果数据分布不均匀,就有可能在Reduce阶段产生数据倾斜。
(4)ReduceTask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个ReduceTask。
(5)具体多少个ReduceTask,需要根据集群性能而定。
(6)如果分区数不是1,但是ReduceTask为1,是否执行分区过程。答案是:不执行分区过程。因为在MapTask的源码中,执行分区的前提是先判断ReducelNum个数是否大于1。不大于1肯定不执行。
3.6 OutputFormat数据输出
3.6.1 OutputFormat接口实现类
OutputFormat是Map Reduce出的基类,所有实现MapReduce输出都实现了OutputFormat接口。下面介绍几种常见的OutputFormat实现类。
1.文本输出TextOutputFormat默认的输出格式是TextOutputFormat,它把每条记录写为文本行。它的键和值可以是任意类型,因为TextOutputFormat周用toString0方法把它们转换为字符串。
2.SequenceFileOutputFormat将SequenceFileOutputFormat出作为后续MapReduce任务的输入,这便是一种好的输出格式,因为它的格式紧凑,很容易被压缩。
3.自定义OutputFormat根据用户需求,自定义实现输出。
3.6.2 自定义OutputFormat
1.使用场景
为了实现控制最终文件的输出路径和输出格式,可以自定义OutputFormat。
例如:要在一个MapReduce程序中根据数据的不同输出两类结果到不同目录,这类灵活的输出需求可以通过自定义OutputFormat来实现。
2.自定义OutputFormat步骤
(1)自定义一个类继承FileOutputFormat。
(2)改写RecordWriter,具体改写输出数据的方法wite0。
3.6.3 自定义OutputFormat案例实操
1.需求
过滤输入的log日志,包含atguigu的网站输出到e:/atguigu.log,不包含atguigu的网站输出到e:/other.log。
(1)输入数据
http://www.baidu.com
http://www.google.com
http://cn.bing.com
http://www.atguigu.com
http://www.sohu.com
http://www.sina.com
http://www.sin2a.com
http://www.sin2desa.com
http://www.sindsafa.com
(2)期望输出数据
atguigu.log
http://www.atguigu.com
other.log
http://cn.bing.com
http://www.baidu.com
http://www.google.com
http://www.sin2a.com
http://www.sin2desa.com
http://www.sina.com
http://www.sindsafa.com
http://www.sohu.com
2.需求分析
1、需求:过虑输入的log日志,包含gigu的网站输出到e:/atguigulog,不包含atguigu的网站输出到e:/other.log
2、输入数据
http://wwww.baidu.com
http://www.google.com
http://cn.bing.com
http://www.atguigu.com
http://www.sohu.com
http://www.sina.com
http://www.sin2a.com
http://www.sin2desa.com
http://www.sindsafa.com
3、输出数据
atguigu.log
http://www.atguigu.com
other.log
http://cn.bing.com
http://www.baidu.com
http://www.google.com
http://www.sin2a.com
http://www.sin2desa.com
http://www.sina.com
http://www.sindsafa.com
http://www.sohu.com
4、自定义一个OutputFormat类
(1)创建一个类FilterRecordWriter继承RecordWriter
(a)创两个文件的输出流:atgiguOt、otherOut
(b)如果输入数据包含gigu,输出到atgigOw流如果不包含atgig1,输出到otherOut流
5、驱动类Driver
//要好自定义的输出格式组件设置到job中
job.setO utputF ormatClass(FilterOutputF ormat.das);
3.案例实操
(1)编写FilterMapper类
package com.atguigu.mapreduce.outputformat;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class FilterMapper extends Mapper{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 写出
context.write(value, NullWritable.get());
}
}
(2)编写FilterReducer类
package com.atguigu.mapreduce.outputformat;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FilterReducer extends Reducer {
Text k = new Text();
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = key.toString();
// 2 拼接
line = line + "\r\n";
// 3 设置key
k.set(line);
// 4 输出
context.write(k, NullWritable.get());
}
}
(3)自定义一个OutputFormat类
package com.atguigu.mapreduce.outputformat;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FilterOutputFormat extends FileOutputFormat{
@Override
public RecordWriter getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException {
// 创建一个RecordWriter
return new FilterRecordWriter(job);
}
}
(4)编写RecordWriter类
package com.atguigu.mapreduce.outputformat;
import java.io.IOException;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
public class FilterRecordWriter extends RecordWriter {
FSDataOutputStream atguiguOut = null;
FSDataOutputStream otherOut = null;
public FilterRecordWriter(TaskAttemptContext job) {
// 1 获取文件系统
FileSystem fs;
try {
fs = FileSystem.get(job.getConfiguration());
// 2 创建输出文件路径
Path atguiguPath = new Path("e:/atguigu.log");
Path otherPath = new Path("e:/other.log");
// 3 创建输出流
atguiguOut = fs.create(atguiguPath);
otherOut = fs.create(otherPath);
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void write(Text key, NullWritable value) throws IOException, InterruptedException {
// 判断是否包含“atguigu”输出到不同文件
if (key.toString().contains("atguigu")) {
atguiguOut.write(key.toString().getBytes());
} else {
otherOut.write(key.toString().getBytes());
}
}
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
// 关闭资源
IOUtils.closeStream(atguiguOut);
IOUtils.closeStream(otherOut); }
}
(5)编写FilterDriver类
package com.atguigu.mapreduce.outputformat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FilterDriver {
public static void main(String[] args) throws Exception {
// 输入输出路径需要根据自己电脑上实际的输入输出路径设置
args = new String[] { “e:/input/inputoutputformat”, “e:/output2” };
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(FilterDriver.class);
job.setMapperClass(FilterMapper.class);
job.setReducerClass(FilterReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 要将自定义的输出格式组件设置到job中
job.setOutputFormatClass(FilterOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 虽然我们自定义了outputformat,但是因为我们的outputformat继承自fileoutputformat
// 而fileoutputformat要输出一个_SUCCESS文件,所以,在这还得指定一个输出目录
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
3.7 Join多种应用
3.7.1 Reduce Join
Map端的主要工作:为来自不同表或文件的key/value对,打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。
Reduce端的主要工作:在Reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在Map阶段已经打标志志分开,最后进行合并就ok了。
3.7.2 Reduce Join案例实操
1.需求
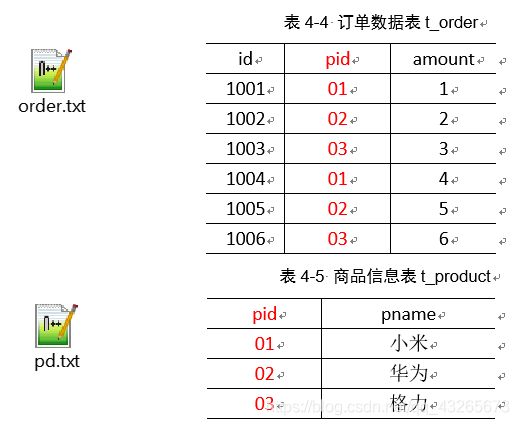
将商品信息表中数据根据商品pid合并到订单数据表中。
id pname amount
1001 小米 1
1004 小米 4
1002 华为 2
1005 华为 5
1003 格力 3
1006 格力 6
2.需求分析
通过将关联条件作为Map输出的key,将两表满足Join条件的数据并携带数据所来源的文件信息,发往同一个ReduceTask,在Reduce中进行数据的串联,如图4-20所示。
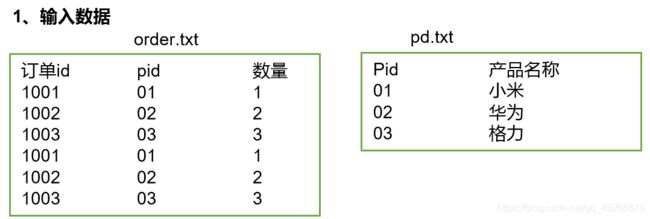
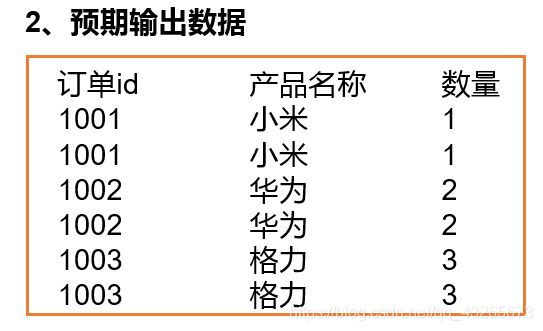


图4-20 Reduce端表合并
3.代码实现
1)创建商品和订合并后的Bean类
package com.atguigu.mapreduce.table;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class TableBean implements Writable {
private String order_id; // 订单id
private String p_id; // 产品id
private int amount; // 产品数量
private String pname; // 产品名称
private String flag; // 表的标记
public TableBean() {
super();
}
public TableBean(String order_id, String p_id, int amount, String pname, String flag) {
super();
this.order_id = order_id;
this.p_id = p_id;
this.amount = amount;
this.pname = pname;
this.flag = flag;
}
public String getFlag() {
return flag;
}
public void setFlag(String flag) {
this.flag = flag;
}
public String getOrder_id() {
return order_id;
}
public void setOrder_id(String order_id) {
this.order_id = order_id;
}
public String getP_id() {
return p_id;
}
public void setP_id(String p_id) {
this.p_id = p_id;
}
public int getAmount() {
return amount;
}
public void setAmount(int amount) {
this.amount = amount;
}
public String getPname() {
return pname;
}
public void setPname(String pname) {
this.pname = pname;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(order_id);
out.writeUTF(p_id);
out.writeInt(amount);
out.writeUTF(pname);
out.writeUTF(flag);
}
@Override
public void readFields(DataInput in) throws IOException {
this.order_id = in.readUTF();
this.p_id = in.readUTF();
this.amount = in.readInt();
this.pname = in.readUTF();
this.flag = in.readUTF();
}
@Override
public String toString() {
return order_id + "\t" + pname + "\t" + amount + "\t" ;
}
}
2)编写TableMapper类
package com.atguigu.mapreduce.table;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
public class TableMapper extends Mapper{
String name;
TableBean bean = new TableBean();
Text k = new Text();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
// 1 获取输入文件切片
FileSplit split = (FileSplit) context.getInputSplit();
// 2 获取输入文件名称
name = split.getPath().getName();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取输入数据
String line = value.toString();
// 2 不同文件分别处理
if (name.startsWith("order")) {// 订单表处理
// 2.1 切割
String[] fields = line.split("\t");
// 2.2 封装bean对象
bean.setOrder_id(fields[0]);
bean.setP_id(fields[1]);
bean.setAmount(Integer.parseInt(fields[2]));
bean.setPname("");
bean.setFlag("order");
k.set(fields[1]);
}else {// 产品表处理
// 2.3 切割
String[] fields = line.split("\t");
// 2.4 封装bean对象
bean.setP_id(fields[0]);
bean.setPname(fields[1]);
bean.setFlag("pd");
bean.setAmount(0);
bean.setOrder_id("");
k.set(fields[0]);
}
// 3 写出
context.write(k, bean);
}
}
3)编写TableReducer类
package com.atguigu.mapreduce.table;
import java.io.IOException;
import java.util.ArrayList;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class TableReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
// 1准备存储订单的集合
ArrayList orderBeans = new ArrayList<>();
// 2 准备bean对象
TableBean pdBean = new TableBean();
for (TableBean bean : values) {
if ("order".equals(bean.getFlag())) {// 订单表
// 拷贝传递过来的每条订单数据到集合中
TableBean orderBean = new TableBean();
try {
BeanUtils.copyProperties(orderBean, bean);
} catch (Exception e) {
e.printStackTrace();
}
orderBeans.add(orderBean);
} else {// 产品表
try {
// 拷贝传递过来的产品表到内存中
BeanUtils.copyProperties(pdBean, bean);
} catch (Exception e) {
e.printStackTrace();
}
}
}
// 3 表的拼接
for(TableBean bean:orderBeans){
bean.setPname (pdBean.getPname());
// 4 数据写出去
context.write(bean, NullWritable.get());
}
}
}
4)编写TableDriver类
package com.atguigu.mapreduce.table;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TableDriver {
public static void main(String[] args) throws Exception {
// 0 根据自己电脑路径重新配置
args = new String[]{"e:/input/inputtable","e:/output1"};
// 1 获取配置信息,或者job对象实例
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 指定本程序的jar包所在的本地路径
job.setJarByClass(TableDriver.class);
// 3 指定本业务job要使用的Mapper/Reducer业务类
job.setMapperClass(TableMapper.class);
job.setReducerClass(TableReducer.class);
// 4 指定Mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(TableBean.class);
// 5 指定最终输出的数据的kv类型
job.setOutputKeyClass(TableBean.class);
job.setOutputValueClass(NullWritable.class);
// 6 指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
4.测试
运行程序查看结果
1001 小米 1
1001 小米 1
1002 华为 2
1002 华为 2
1003 格力 3
1003 格力 3
5.总结
缺点:这种方式中,合并的操作是在Reduce阶段完成,Reduce端的处理压力太大,Map节点的运算负载则很低,资源利用率不高,且在Reduce阶段极易产生数据倾斜。
解决方案:Map端实现数据合并
3.7.3 Map Join
1.使用场景
Map Join适用于一张表十分小、一张表很大的场景。
2.优点
思考:在Reduce端处理过多的表,非常容易产生数据倾斜。怎么办?
在Map端缓存多张表,提前处理业务逻辑,这样增加Map端业务,减少Reduce端数据的压力,尽可能的减少数据倾斜。
3.具体办法:采用DistributedCache
(1)在Mapper的setup阶段,将文件读取到缓存集合中。
(2)在驱动函数中加载缓存。
// 缓存普通文件到Task运行节点。
job.addCacheFile(new URI("file://e:/cache/pd.txt"));
3.7.4 Map Join案例实操
1.需求
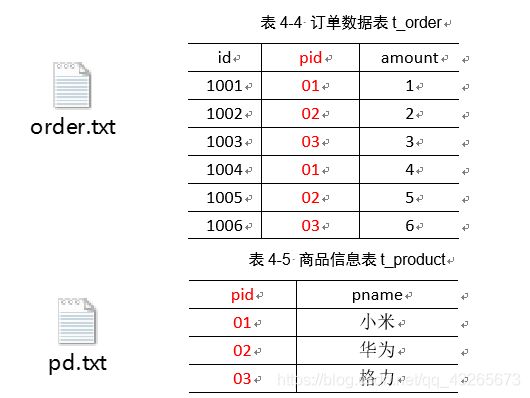
将商品信息表中数据根据商品pid合并到订单数据表中。
表4-6 最终数据形式
id pname amount
1001 小米 1
1004 小米 4
1002 华为 2
1005 华为 5
1003 格力 3
1006 格力 6
2.需求分析
MapJoin适用于关联表中有小表的情形。
1)DistributedCacheDriver 缓存文件
//1加载缓存数据
job.addCacheFile(new URI("file://e:/cacdhe/pd.txt"));
//2Map端join的逻辑不需要Reduce阶段,设置ReduceTak数量为0
job.setNunRecduce Tasks(0);
2)读取缓存的文件数据
setup0方法中 map方法中
//1获取缓存的文件 //1获取一行
//2循环读取缓存文件一行 //2截取
//3切割 //3获取订单id
//4缓存数据到集合 //4获取商品名称
//5关流 //5拼接
//6写出
图4-21 Map端表合并
3.实现代码
(1)先在驱动模块中添加缓存文件
package test;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class DistributedCacheDriver {
public static void main(String[] args) throws Exception {
// 0 根据自己电脑路径重新配置
args = new String[]{"e:/input/inputtable2", "e:/output1"};
// 1 获取job信息
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 设置加载jar包路径
job.setJarByClass(DistributedCacheDriver.class);
// 3 关联map
job.setMapperClass(DistributedCacheMapper.class);
// 4 设置最终输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 5 设置输入输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 6 加载缓存数据
job.addCacheFile(new URI("file:///e:/input/inputcache/pd.txt"));
// 7 Map端Join的逻辑不需要Reduce阶段,设置reduceTask数量为0
job.setNumReduceTasks(0);
// 8 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
(2)读取缓存的文件数据
package test;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class DistributedCacheMapper extends Mapper{
Map pdMap = new HashMap<>();
@Override
protected void setup(Mapper.Context context) throws IOException, InterruptedException {
// 1 获取缓存的文件
URI[] cacheFiles = context.getCacheFiles();
String path = cacheFiles[0].getPath().toString();
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(path), "UTF-8"));
String line;
while(StringUtils.isNotEmpty(line = reader.readLine())){
// 2 切割
String[] fields = line.split("\t");
// 3 缓存数据到集合
pdMap.put(fields[0], fields[1]);
}
// 4 关流
reader.close();
}
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 截取
String[] fields = line.split("\t");
// 3 获取产品id
String pId = fields[1];
// 4 获取商品名称
String pdName = pdMap.get(pId);
// 5 拼接
k.set(line + "\t"+ pdName);
// 6 写出
context.write(k, NullWritable.get());
}
}
3.8 计数器应用
Hadoop为每个作业维护若干内置计数器,以描述多项指标。例如,某些计数晶记录已处理的字节数和记录数,使用户可监控已处理的输入数据量和已产生的输出数据量。
1.计数器API
(1)采用枚举的方式统计计数
enum MyCounter(MALFORORMED NORMAL)
//对年定义的自定义计数器加1
context.getCounter(MyCounter.MALFORORMED).increment(1);
(2)采用计数器组、计数器名称的方式统计
context.getCounter("counterGroup","counter").increment(1);
组名和计数器名称随便起,但最好有意义。
(3)计数结果在程序运行后的控利台上查看。
2.计数器案例实操 详见下面的数据清洗案例。
3.9 数据清洗(ETL)
在运行核心业务MapReduce程序之前,往往要先对数据进行清洗,清理掉不符合用户要求的数据。清理的过程往往只需要运行Mapper程序,不需要运行Reduce程序。
3.9.1 数据清洗案例实操-简单解析版
1.需求
去除日志中字段长度小于等于11的日志。
(1)输入数据
web.log(部分)
194.237.142.21 - - [18/Sep/2013:06:49:18 +0000] "GET /wp-content/uploads/2013/07/rstudio-git3.png HTTP/1.1" 304 0 "-" "Mozilla/4.0 (compatible;)"
183.49.46.228 - - [18/Sep/2013:06:49:23 +0000] "-" 400 0 "-" "-"
163.177.71.12 - - [18/Sep/2013:06:49:33 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
163.177.71.12 - - [18/Sep/2013:06:49:36 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
101.226.68.137 - - [18/Sep/2013:06:49:42 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
101.226.68.137 - - [18/Sep/2013:06:49:45 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
60.208.6.156 - - [18/Sep/2013:06:49:48 +0000] "GET /wp-content/uploads/2013/07/rcassandra.png HTTP/1.0" 200 185524 "http://cos.name/category/software/packages/" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36"
222.68.172.190 - - [18/Sep/2013:06:49:57 +0000] "GET /images/my.jpg HTTP/1.1" 200 19939 "http://www.angularjs.cn/A00n" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36"
222.68.172.190 - - [18/Sep/2013:06:50:08 +0000] "-" 400 0 "-" "-"
183.195.232.138 - - [18/Sep/2013:06:50:16 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
183.195.232.138 - - [18/Sep/2013:06:50:16 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
66.249.66.84 - - [18/Sep/2013:06:50:28 +0000] "GET /page/6/ HTTP/1.1" 200 27777 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
221.130.41.168 - - [18/Sep/2013:06:50:37 +0000] "GET /feed/ HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36"
157.55.35.40 - - [18/Sep/2013:06:51:13 +0000] "GET /robots.txt HTTP/1.1" 200 150 "-" "Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)"
50.116.27.194 - - [18/Sep/2013:06:51:35 +0000] "POST /wp-cron.php?doing_wp_cron=1379487095.2510800361633300781250 HTTP/1.0" 200 0 "-" "WordPress/3.6; http://blog.fens.me"
58.215.204.118 - - [18/Sep/2013:06:51:35 +0000] "GET /nodejs-socketio-chat/ HTTP/1.1" 200 10818 "http://www.google.com/url?sa=t&rct=j&q=nodejs%20%E5%BC%82%E6%AD%A5%E5%B9%BF%E6%92%AD&source=web&cd=1&cad=rja&ved=0CCgQFjAA&url=%68%74%74%70%3a%2f%2f%62%6c%6f%67%2e%66%65%6e%73%2e%6d%65%2f%6e%6f%64%65%6a%73%2d%73%6f%63%6b%65%74%69%6f%2d%63%68%61%74%2f&ei=rko5UrylAefOiAe7_IGQBw&usg=AFQjCNG6YWoZsJ_bSj8kTnMHcH51hYQkAA&bvm=bv.52288139,d.aGc" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
58.215.204.118 - - [18/Sep/2013:06:51:36 +0000] "GET /wp-includes/js/jquery/jquery-migrate.min.js?ver=1.2.1 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
58.215.204.118 - - [18/Sep/2013:06:51:35 +0000] "GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
(2)期望输出数据
每行字段长度都大于11。
2.需求分析
需要在Map阶段对输入的数据根据规则进行过滤清洗。
3.实现代码
(1)编写LogMapper类
package com.atguigu.mapreduce.weblog;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class LogMapper extends Mapper{
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取1行数据
String line = value.toString();
// 2 解析日志
boolean result = parseLog(line,context);
// 3 日志不合法退出
if (!result) {
return;
}
// 4 设置key
k.set(line);
// 5 写出数据
context.write(k, NullWritable.get());
}
// 2 解析日志
private boolean parseLog(String line, Context context) {
// 1 截取
String[] fields = line.split(" ");
// 2 日志长度大于11的为合法
if (fields.length > 11) {
// 系统计数器
context.getCounter("map", "true").increment(1);
return true;
}else {
context.getCounter("map", "false").increment(1);
return false;
}
}
}
(2)编写LogDriver类
package com.atguigu.mapreduce.weblog;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class LogDriver {
public static void main(String[] args) throws Exception {
// 输入输出路径需要根据自己电脑上实际的输入输出路径设置
args = new String[] { "e:/input/inputlog", "e:/output1" };
// 1 获取job信息
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 加载jar包
job.setJarByClass(LogDriver.class);
// 3 关联map
job.setMapperClass(LogMapper.class);
// 4 设置最终输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 设置reducetask个数为0
job.setNumReduceTasks(0);
// 5 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 6 提交
job.waitForCompletion(true);
}
}
3.9.2 数据清洗案例实操-复杂解析版
1.需求
对Web访问日志中的各字段识别切分,去除日志中不合法的记录。根据清洗规则,输出过滤后的数据。
(1)输入数据
数据同上web.log
(2)期望输出数据
都是合法的数据
2.实现代码
(1)定义一个bean,用来记录日志数据中的各数据字段
package com.atguigu.mapreduce.log;
public class LogBean {
private String remote_addr;// 记录客户端的ip地址
private String remote_user;// 记录客户端用户名称,忽略属性"-"
private String time_local;// 记录访问时间与时区
private String request;// 记录请求的url与http协议
private String status;// 记录请求状态;成功是200
private String body_bytes_sent;// 记录发送给客户端文件主体内容大小
private String http_referer;// 用来记录从那个页面链接访问过来的
private String http_user_agent;// 记录客户浏览器的相关信息
private boolean valid = true;// 判断数据是否合法
public String getRemote_addr() {
return remote_addr;
}
public void setRemote_addr(String remote_addr) {
this.remote_addr = remote_addr;
}
public String getRemote_user() {
return remote_user;
}
public void setRemote_user(String remote_user) {
this.remote_user = remote_user;
}
public String getTime_local() {
return time_local;
}
public void setTime_local(String time_local) {
this.time_local = time_local;
}
public String getRequest() {
return request;
}
public void setRequest(String request) {
this.request = request;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public String getBody_bytes_sent() {
return body_bytes_sent;
}
public void setBody_bytes_sent(String body_bytes_sent) {
this.body_bytes_sent = body_bytes_sent;
}
public String getHttp_referer() {
return http_referer;
}
public void setHttp_referer(String http_referer) {
this.http_referer = http_referer;
}
public String getHttp_user_agent() {
return http_user_agent;
}
public void setHttp_user_agent(String http_user_agent) {
this.http_user_agent = http_user_agent;
}
public boolean isValid() {
return valid;
}
public void setValid(boolean valid) {
this.valid = valid;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(this.valid);
sb.append("\001").append(this.remote_addr);
sb.append("\001").append(this.remote_user);
sb.append("\001").append(this.time_local);
sb.append("\001").append(this.request);
sb.append("\001").append(this.status);
sb.append("\001").append(this.body_bytes_sent);
sb.append("\001").append(this.http_referer);
sb.append("\001").append(this.http_user_agent);
return sb.toString();
}
}
(2)编写LogMapper类
package com.atguigu.mapreduce.log;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class LogMapper extends Mapper{
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取1行
String line = value.toString();
// 2 解析日志是否合法
LogBean bean = parseLog(line);
if (!bean.isValid()) {
return;
}
k.set(bean.toString());
// 3 输出
context.write(k, NullWritable.get());
}
// 解析日志
private LogBean parseLog(String line) {
LogBean logBean = new LogBean();
// 1 截取
String[] fields = line.split(" ");
if (fields.length > 11) {
// 2封装数据
logBean.setRemote_addr(fields[0]);
logBean.setRemote_user(fields[1]);
logBean.setTime_local(fields[3].substring(1));
logBean.setRequest(fields[6]);
logBean.setStatus(fields[8]);
logBean.setBody_bytes_sent(fields[9]);
logBean.setHttp_referer(fields[10]);
if (fields.length > 12) {
logBean.setHttp_user_agent(fields[11] + " "+ fields[12]);
}else {
logBean.setHttp_user_agent(fields[11]);
}
// 大于400,HTTP错误
if (Integer.parseInt(logBean.getStatus()) >= 400) {
logBean.setValid(false);
}
}else {
logBean.setValid(false);
}
return logBean;
}
}
(3)编写LogDriver类
package com.atguigu.mapreduce.log;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class LogDriver {
public static void main(String[] args) throws Exception {
// 1 获取job信息
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 加载jar包
job.setJarByClass(LogDriver.class);
// 3 关联map
job.setMapperClass(LogMapper.class);
// 4 设置最终输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 5 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 6 提交
job.waitForCompletion(true);
}
}
3.10 MapReduce开发总结
在编写MapReduce程序时,需要考虑如下几个方面:
1.输入数据接口:InputFormat
(1)默认使用的实现类是:TextmputFormat
(2)TextmputFormat的功能逻辑是:一次读一行文本,然后将该行的起始偏移量作为key,行内容作为value返回。
(3)KeyValue TextInputFormat每一行均为一条记录,被分隔符分割为key,value。默认分隔符是tab(t)。
(4)NlinelInputFormat按照指定的行数N来划分切片。
(5)Combine TextlnputFormat可以把多个小文件合并成一个切片处理,提高处理效率。
(6)用户还可以自定义ImputFormat。
2.逻辑处理接口:
Mapper用户根据业务需求实现其中三个方法:map() setup() deanup()
3.Partitioner分区
(1)有默认实现HashPartitioner,逻辑是根据key的哈希值和numReduces来返回一个分区号;
keyhashCode0&Integer.MAXVALE%
numReduces
(2)如果业务上有特别的需求,可以自定义分区。
4.Comparable排序
(1)当我们用自定义的对象作为key来输出时,就必须要实现whitableComparable接口,重写其中的compareTo0方法。
(2)部分排序:对最终输出的每一个文件进行内部排序。
(3)全排序:对所有数据进行排序,通常只有一个Reduce。
(4)二次排序:排序的条件有两个。
5.Combiner合并
Combiner合并可以提高程序执行效率,减少I0传输。但是使用时必须不能影响原有的业务处理结果。
6.Reduce端分组
Groupingcomparator在Reduce端对key进行分组。
应用于:在接收的key为bean对象时,想让一个或几个字段相同(全部字段比较不相同)的key进入到同一个reduce方法时,可以采用分组排序。
7.逻辑处理接口
Reducer用户根据业务需求实现其中三个方法:reduce0seupO cdeanup0
8.输出数据接口:OutputFormat
(1)默认实现类是TextOtputFormat,功能逻辑是:将每一个KV对,向目标文本文件输出一行。
(2)将SecquenceFileOutputFormat输出作为后续MapReduce任务的输入,这便是一种好的输出格式,因为它的格式紧凑,很容易被压缩。
(3)用户还可以自定义OutputFomat。
MapReduce代码要多训练
MapReduce代码要多训练
MapReduce代码要多训练