爬取笔趣阁小说网站上的所有小说(一)
爬取笔趣阁小说网站上的所有小说(一)
网址为:https://www.biqukan.cc/topallvisit/1.html
反反爬虫
爬虫首先要做的就是看看目标网址有没有反爬虫手段,一般网站都是有的,但是想这种网站的话,一般不会太厉害,所以只要价格请求头就好了。
user_agent = r'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'
head = {
'User-Agnet': user_agent, }
分析网址
打开网址的调试模式,第一章方法:按F12打开调试模式,然后点击调试窗口左上角的鼠标按钮,选择一个元素(小说)就可以看到对用的内容了;第二周方法,也可以在一个小说上点击右键,选择检查(Chrome浏览器)或审查(Firefox浏览器),就可以得到以下内容:
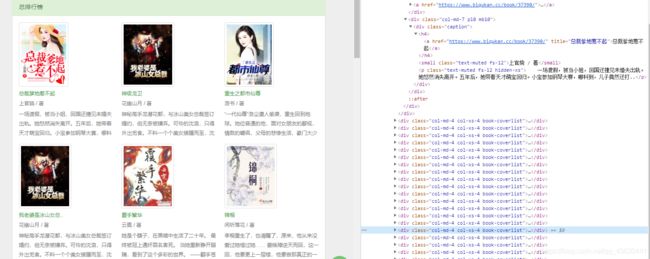
通过观察我们可以发现,对应打开的小说的源代码,上下对比可以考到每个小说的所有内容都在一个div里面,所以我们只需获得这些div就可以得到网址了;
# 获得网页源码
html = requests.get(url=first_url,headers=head)
# 把我们使用的编码改成和网站相同的编码
html.encoding = html.apparent_encoding
# 使用BeautifulSoup清理源码,意思就是改变成我们人类看着方便的方式展示
soup = BS(html.text, "html.parser")
#所有包含小说网址的div
book_name_lists=soup.findAll(class_='caption')
findAll方法是可以通过个元素的名册可以找到所有的元素,并返回一个列表。
获取小说网址
因为我们现在只需要一个小说的网址,所以只要一下内容就可以提取到了。不需要包含图片的div。
<div class="caption">
<h4><a href="https://www.biqukan.cc/book/37390/" title="总裁爹地惹不起">总裁爹地惹不起a>
h4>
<small class="text-muted fs-12">上官娆 / 著small>
<p class="text-muted fs-12 hidden-xs"> 一场渡假,被当小姐,回国还撞见未婚夫出轨。她怒然消失离开。五年后,她带着天才萌宝回归。小宝参加钢琴大赛,哪料到,儿子竟然还打..p>
div>
写入文件
book_name_lists已经包含了当前页面所有小说的地址,现在只需要循环提取并写入we年就达到了我们得目的,看代码:
# 开始写入文件
with open('第'+str(i) + '页.txt', 'a+', encoding='utf-8') as f:
# 文档的头部信息
# 遍历每本书
for book in book_name_lists:
# 书名
print(book.a['title'])
# 书链接
print(book.a['href'])
f.write(book.a['href']+'\n')
记得在最后加‘\n’换行符,不然第二个网址会写在第一个网址后面,造成混乱。
这里我们选择每一页写入一个网址,一也包含030个小说。
源码
import requests
from bs4 import BeautifulSoup as BS
import time
# 请求头
user_agent = r'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'
head = {'User-Agnet': user_agent, }
# 以10页为例
for i in range(1,11):
# 地址
first_url='https://www.biqukan.cc/topallvisit/'+str(i)+'.html'
# 获得网页源码
html = requests.get(url=first_url,headers=head)
# 把我们使用的编码改成和网站相同的编码
html.encoding = html.apparent_encoding
# 使用BeautifulSoup清理源码,意思就是改变成我们人类看着方便的方式展示
soup = BS(html.text, "html.parser")
book_name_lists=soup.findAll(class_='caption')
# 开始写入文件
with open('第'+str(i) + '页.txt', 'a+', encoding='utf-8') as f:
# 文档的头部信息
# 遍历每本书
for book in book_name_lists:
# 书名
print(book.a['title'])
# 书链接
print(book.a['href'])
f.write(book.a['href']+'\n')
#当前页面已经写入成功
print("第" + str(i) + "页结束**********")
# 睡眠一秒
time.sleep(1)
爬取笔趣阁小说网站上的所有小说(一)
下载等功能在此链接