SQL如何进行优化
SQL优化
前言
对于初级程序开发工程师而言,SQL是很多人的弱项,为此我给大家来做一下总结,希望能够帮到你们。
课程说明
1、对MySQL SQL优化方案做讲解,学习如何排查慢查询;
SQL优化
分页查询优化
一页一页的往下面翻这种查询方式,可以对分页做如下优化
SELECT `id`,`name` FROM tb_user LIMIT 10000,10; -- 可能存在性能问题
-- 如何 优化?
-- 解决方案,携带上一页的最后一个id
SELECT `id`,`name` FROM tb_user WHERE id > #{last_id} LIMIT 10;
建立索引、使用索引
索引应建立在那些将用于JOIN ON条件、WHERE条件判断、ORDERBY排序的字段上
没有命中索引的SQL不允许执行!
在Java代码中进行条件判断,不允许没有命中索引的SQL执行;
字段能小则小
普通索引不要建立在大字段上
索引建立在离散度大的字段上
批量插入
不要大量使用 insert into,可以使用insert into table (字段) values (),(),();
先导入数据再建立索引
数据迁移的时候
某些情况下避免使用子查询
id in (select id from **) — 10 W
索引字段查询避免使用函数
create_time 就算它是索引, where date_format(create_time,’%Y-%m-%d’) = ‘2019-04-05’ 这个语句也无法命中索引
优化:where create_time >= ‘2019-04-05 00:00:00’ and create_time <= ‘2019-04-05 23:59:59’ 则可以命中索引
禁止排序
如果分组之后没有相关的需求根据那个聚合字段进行排序,则可以加上 order by null 禁止默认排序,提升效率;
group by ** order by null;
建立全文索引替换like模糊匹配
根据词 来 定位 某条数据
表结构
id name introduction(varchar 1024)
1 张三 北京 昌平区 Java 程序员 …
建立全文索引的sql: ALTER TABLE 表名 ADD FULLTEXT INDEX 自定义一个全文索引名称(字段名);
// 备注 也可以在两个列上建立全文索引 —— 够在title和content两个列上创建全文索引
ALTER TABLE article ADD FULLTEXT INDEX fulltext_article(title,content);
我们mysql5.7 InnoDB 它是支持全文索引
我们存储文档时,把需要搜索的关键字 以 空格 或者,或者| 隔开 存储到我们的mysql text / varchar 这种大字段中,对其可以建立全文索引。
避免 使用 like 模糊查询 影响效率。
全文检索的sql
SELECT * FROM tbk_item_coupon WHERE MATCH(title) AGAINST(‘夏季’ IN BOOLEAN MODE);
但是多数情况下,一般会将 mysql数据 同步到 全文搜索服务器 比如 ES 中,提供全文检索功能(分词更加灵活,减轻mysql压力)。
相同类型字段进行比较
比如我们数据库表结果中,某个字段是 varchar 类型
我们 sql 传入的 匹配条件是 Long 类型,那么就算这个varchar 是建立了索引,索引也可能会失效

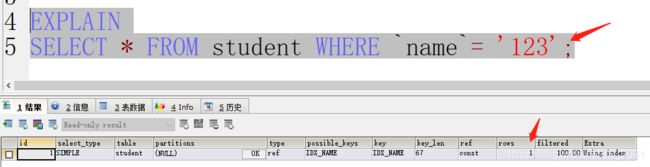
EXPLAIN
SELECT * FROM student WHERE `name`= 123;

减少锁的独占表的范围
针对某些业务,我们可以在客户端使用 乐观锁的机制,来保证线程安全,可以避免使用 数据库 悲观锁:select *** for update;
乐观锁 : 基于版本 基于 重试。update *** set *** where id = 条件 and version = 我们期待的值;
如何排查慢查询
当我们发现 mysql 从库 数据同步 延迟较高, mysql 服务机器 cpu、内存 使用率 飙升,或者是说一个很简单的sql都没法执行,或者说 远程 客户端都连接不上 mysql服务时,那么 就需要考虑,当前mysql是不是 正在 执行一个慢查询。
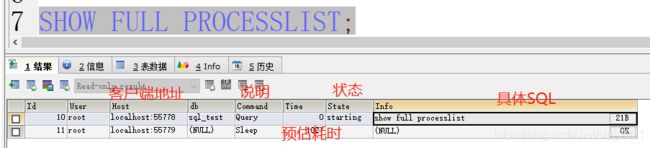
show [full] processlist
查看数据库各SQL执行进程情况
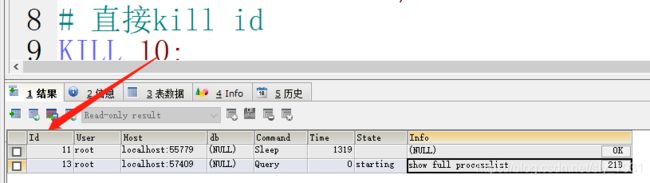
如何强硬终止某个慢查询呢?
EXPLAIN查看执行计划
我如何知道,我写的SQL会不会是慢查询?难道要跑到线上去执行一下,把线上数据库查崩才能判断我的SQL是慢查询吗?
可以使用执行计划;
mysql在执行每个sql语句前,会先进行分析,统计这个sql大概需要如何去查询,以及扫描的行数,命中的索引,及数据扫描的方式…
通过EXplain 执行 分析报告 查看 当前SQL 是否为 慢查询

要求,sql执行一定要命中索引,扫描的行数 rows 越小越好。

ALL:`即全表扫描,意味着mysql需要从头到尾去查找所需要的行。通常情况下这需要增加索引来进行优化了
Extra列
![]()
![]()