聚类算法:DBScan算法
对算法的用例是在Spark平台对学生上网记录处理的一个实例,参考地址见GitHub上的DBScan算法运用实例
一、问题提出
先考虑一个问题,对下左图中的数据集合怎么聚类?对右图的无规则的数据集合又该如何聚类?
二、概念介绍
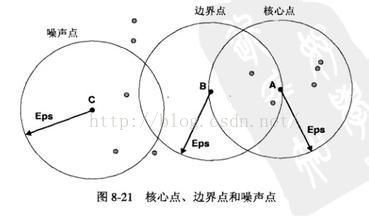
邻域半径(radius):以当前对象为核心确定密度区域范围时引用的长度,二维平面中就指以当前对象为圆心确定圆时引用所用的半径。如下图中的Eps即为领域半径。
密度域值(minPts):以当前对象为核心,以邻域半径为长度,所确定的范围内满足指定要求的最少元素的个数。
核心对象:若一个对象其邻域半径radius内对象元素个数大于等于minPts,则称该对象为核心对象。
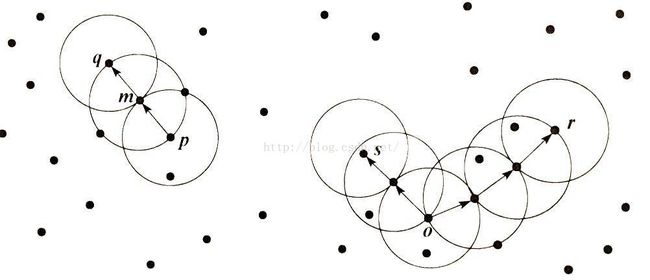
直接密度可达:若一个核心对象P,其邻域半径内若干个点,则这若干个点都有从对象P是直接密度可达的。
密度可达:对象链P(1),P(2),***,P(n),若P(i+1)是从P(i)直接密度可达,则P(n)是从P(1)密度可达(注意:密度可达不是等价关系,因为它不一定是对称的)。
密度相连:存在对象O属于区域D,使得对象S和对象R都从O是密度可达的,则S与R密度相连(注意:密度相连具有等价关系,eg.O1和O2密度相连,O2和O3密度相连,则O1和O3也是密度相连的)。
三、算法介绍
DBScan是具有噪声应用的基于密度的空间聚类算法,可以根据用户指定的参数radius(的邻域半径)和minPts(密度域值),对数据集合进行自动聚类。其最大的特点就是算法本身可以自己决定聚类的数量而不像K-Means算法需要人工指定聚类的数目,可以发现任意形状的类簇,同时可以过滤噪声点和低密度区域。
1、算法的过程描述如下:
输入:初始数据集合、邻域半径(radius)和密度域值(minPts)
建立聚类集合:分别以每个对象为考察对象判断其是否为核心对象,如果是核心对象则建立聚类集合
合并集合:根据密度相连的原则合并聚类集合
输出:输出整理合并达到密度域值要求的集合
2、算法的几个关键点:
(1)如何判断各对象是否为核心对象
判断是否为核心对象时,首先以当前对象为基准,依次计算它与数据集合中其他点的距离,如果距离小于给定的radius(即distance(p,q)
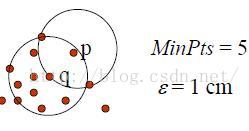
(2)如何度量对象之间的距离
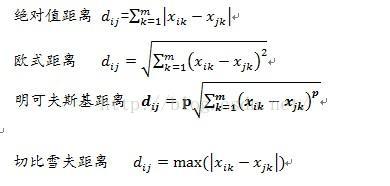
(3)怎么合并聚类集合
通过上面的步骤可以将初始的数据集合处理成各个核心对象的聚类集合,依次遍历上面得以的聚类集合(如图所示),如果聚类集合Cluster中的第i个List集合中的元素在第j个List集合出现过(即两个集合存在密度相连的元素),说明两个集合可以合并成一个大集合。如图过程所示
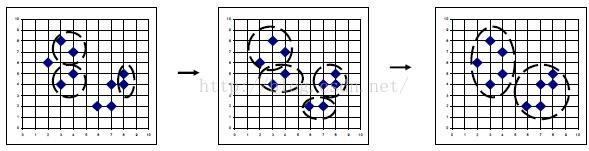
四、算法总结
优点:(1)算法本身可以自己决定聚类数量
(2)可以发现任意形状的类簇
(3)可以过滤低密度的区域,同时可以过滤噪声点
缺点:(1)与用户输入的邻域半径及密度域值密切相关,可能由于用户对数据特点不了解而输入不合适的参数得出不准确的结论
(2)算法过滤噪声点同时也是其缺点,造成了其不适 用于某些领域(比如网络安全领域中恶意攻击的判断)