计网&os复习
基础
文章目录
- 基础
-
- 计算机网络
-
- TCP & UDP
-
- TCP过程
- 流量控制 & 拥塞控制
- TCP首部
- TCP分段 & IP分片
- Http & Https
-
- Http
- Https
- 操作系统
-
- 基础
-
- 中断
- 进程管理
- 存储管理
-
- 存储结构
- 内存分配
- 虚拟内存
计算机网络
TCP & UDP
TCP过程
特性:
- TCP是一种面向连接的,可靠的字节流传输服务
- TCP只能用于点对点的通信,不能用于广播和多播
- TCP使用校验和,确认机制和重传机制来保证可靠传输
- TCP使用滑动窗口机制来进行流量控制,动态改变发送窗口来进行拥塞控制
TCP是100%可靠的传输协议吗?
TCP也不是100%可靠的传输协议,只能保证数据尽最大可能的投递给接收方,投递失败的话,可能会尝试以故障通知的方式通知用户(通过放弃重传并且中断连接这一手段)
三次握手:
- 初始状态:客户端和服务端都处于监听状态(Listen)
- 客户端发送
SYN = 1,seq = x的连接请求报文,客户端进入异步已发送SYN_SENDSYN = 1:请求连接打开seq = x:随机初始序列号
- 服务端收到后,对此报文进行确认,并且发送服务端的连接请求报文
ACK = 1,ack = x + 1,seq = y,SYN = 1,服务端进入异步已接收SYN_RECEACK = 1:对报文确认seq = x + 1:对前面x个序号的报文进行确认SYN = 1:请求连接打开seq = y:随机初始序列号
- 客户端收到后,发回确认
ACK = 1,ack = y + 1,客户端进入连接已建立ESTB - 服务端收到确认后,进入连接已建立
ESTB

SYN攻击
- 定义:
- SYN攻击是指攻击客户端在短时间内伪造大量不存在的IP地址,向服务器不断的发送SYN包,服务端也不断的回复这些SYN包的确认,但是因为这些SYN包的源IP都是不存在的,所以服务端会不断重发确认包,这些伪造的SYN包将长时间的占用未连接队列,导致正常的SYN包无法进入队列而被丢弃,导致目标系统运行缓慢,严重的会导致网络拥塞。
- SYN攻击是一种经典的DDOS攻击
- 如何检测SYN攻击?
- 可以使用
netstat命令查看网络连接状态,如果存在大量半连接的状态并且ip是随机的,这种大概率是SYN攻击 
- 可以使用
- 如何防御SYN攻击?
- 过滤网关,网关层过滤大量非法请求
- 缩短超时(SYN Timeout)时间
TCP keepalive
- TCP KeepAlive 的基本原理是,隔一段时间给连接对端发送一个探测包,如果收到对方回应的 ACK,则认为连接还是存活的,在超过一定重试次数之后还是没有收到对方的回应,则丢弃该 TCP 连接。
- 目的:防止一直维护这个连接,长时间的积累会导致非常多的半打开连接,造成端系统资源的消耗和浪费
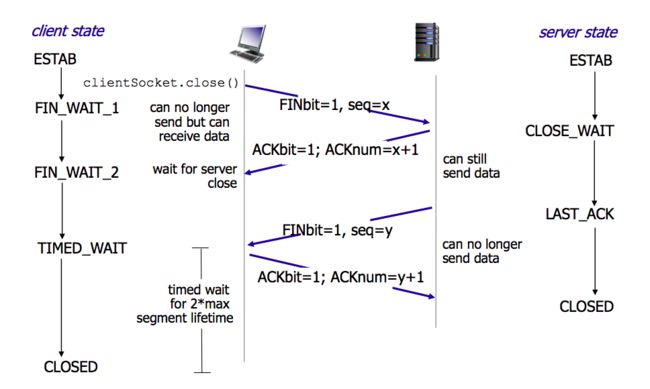
四次挥手:
- 客户端发送
FIN = 1,seq = x的连接关闭请求,发送完后进入FIN_WAIT_1FIN = 1:标识连接关闭请求
- 服务端接收到后发回确认
ack = x + 1,ACK = 1进入CLOSE_WAIT- 客户端接收到确认后进入
FIN_WAIT_2
- 客户端接收到确认后进入
- 服务端处理完后,发出连接关闭请求
FIN = 1,seq = y,进入LAST_ACK - 客户端接收到后发回确认
ACK = 1,ack = y + 1,并进入Time_await状态- 服务端接收到最后一次确认后进入
CLOSE - 客户端也在等待
2msl后进入CLOSE Time_await状态:2个报文段的最大生存周期- 确保上一次连接中的所有报文失效,不会影响到下次连接
- 确保最后一次ACK能正常投递到服务端(能进行重发)
- 服务端接收到最后一次确认后进入
流量控制 & 拥塞控制
什么是流量控制,流量控制的目的?
- 什么是流量控制?
- 流量控制就是防止发送方发送过快导致接收方接收不过来,导致分组丢失
- 流量控制目的:
- 防止接收方接收不过来导致分组丢失,提高TCP的可靠性
如何实现流量控制?
- 由滑动窗口协议(连续ARQ协议实现),滑动窗口协议既保证了分组无差错,有序接收,通过接收者每次ACK报文中首部的窗口字段来控制发送端的发送速率
流量控制死锁问题?
- 如何产生?
- 发送者收到了接收者的窗口大小为0的应答后,发送者不发送数据,等待接收者的下一次应答,如果接收者下一次的窗口大小不为0的应答在传输过程中丢失了,那么发送者接收不到会一直等待下去,接收者也会以为已经发送了而在等待发送者的数据,这样就会造成僵持。
- 如何避免?
- 为了避免流量控制引发的死锁,TCP使用了持续计时器
- 每当发送方收到一个零窗口报文的应答就开启计时器,时间一到就发送一个探测报文主动询问接收者的窗口大小,如果接收者返回0窗口,则重置计时器,继续计时,如果接收者返回不等于的窗口大小,表明之前的应答丢失了,那么则重置发送窗口,开始发送数据
拥塞控制和流量控制的区别?
- 两者处理对象不同:
- 拥塞控制作用的是网络,防止过多的数据注入到网络中避免出现网络负载过大的情况
- 流量控制作用的是接收者,控制发送者的发送速度从而使接收者接收的过来提高TCP的可靠交付
拥塞控制算法:
-
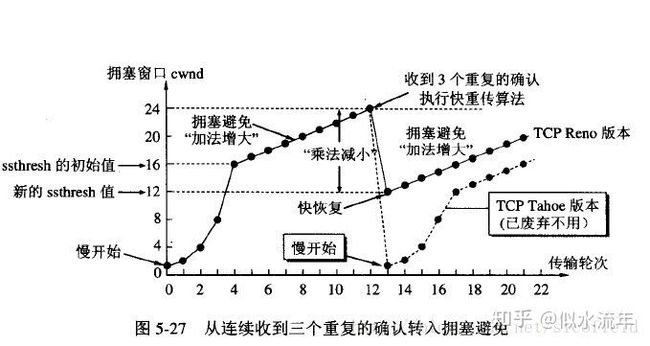
慢开始
- 由小到大的增大拥塞窗口的大小,每经过一个传播轮次(一次往返RTT),拥塞窗口大小翻倍,当拥塞窗口大小 = 门限值时,改用拥塞避免算法
-
拥塞避免
- 拥塞避免算法是让拥塞窗口缓慢增大,每经过一个传播轮次,拥塞窗口大小+1,线性缓慢增长,当出现网络拥塞就把门限值设置为拥塞时发送窗口大小的一半,然后拥塞窗口的大小重置为1,执行慢开始算法
- 这样做的目的就是要迅速减少主机发送到网络中的分组数,使得发生拥塞的路由器有足够时间把队列中积压的分组处理完毕。

- 拥塞避免算法是让拥塞窗口缓慢增大,每经过一个传播轮次,拥塞窗口大小+1,线性缓慢增长,当出现网络拥塞就把门限值设置为拥塞时发送窗口大小的一半,然后拥塞窗口的大小重置为1,执行慢开始算法
-
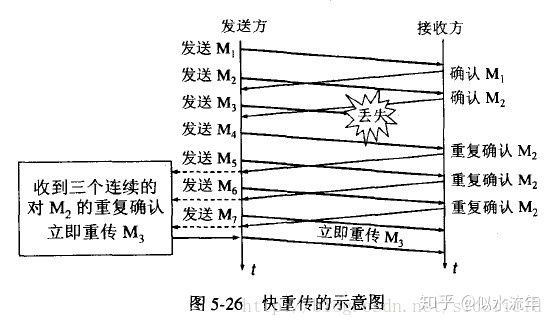
快重传
- 接收方在收到一个失序的报文段后就需要立即发出重复确认,那么发送方在收到接收方连续三个确认后,就必须立即重传接收方尚未收到的报文段,而不必等到超时重传计时器到期
-
快恢复
- 当发送方连续收到三个重复确认时,就执行“乘法减小”算法,把ssthresh门限减半(为了预防网络发生拥塞)。但是接下去并不执行慢开始算法,考虑到如果网络出现拥塞的话就不会收到好几个重复的确认,所以发送方现在认为网络可能没有出现拥塞。所以此时不执行慢开始算法,而是将cwnd设置为ssthresh减半后的值,然后执行拥塞避免算法,使cwnd缓慢增大。慢开始算法只是在TCP连接建立时和网络出现超时时才使用
TCP首部
-
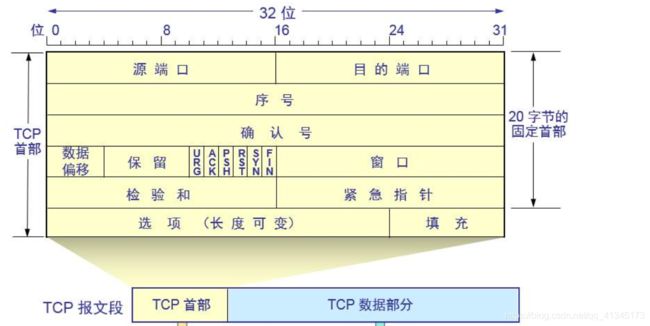
序列号的作用:
- TCP将应用层数据和管理数据的每一字节进行顺序编号,序列号用于指出本报文段携带数据的第一个字节的序列号,(SYN,FIN等算作一个字节数据)
-
确认号的作用:
- 通信双方采用确认号来对收到的数据进行确认,该确认号之前(不包括该确认号)的所有数据均已正确收到,希望下次接收序列号为该确认号的数据。
-
SYN = 1
- 连接打开请求
-
FIN = 1
- 连接关闭请求
-
ACK
- 确认报文
TCP分段 & IP分片
数据报的分段和分片确实发生,分段发生在传输层,分片发生在网络层,但是对于分段来说,这是经常发生在UDP传输层协议上的情况,对于传输层使用TCP协议的通道来说,这种事情很少发生。
MTU,最大传输单元
- 以太网对数据帧的长度有一个限制,在链路层,这个特性称为
MTU,如果IP层有一个数据要传,且数据的长度比链路层的MTU要大,那么IP层就要对数据报进行分片,保证每一片都必须小于MTU- 但是IP分片的过程虽然对上层是透明的,但是有一个弊端,IP分片接收端进行组装的过程中如果发现丢失一片数据,就要对重传整个数据报,因为IP没有确认和超时重传机制。所以:
- 使用UDP很容易造成IP分片
- TCP的话可以避免IP分片,因为TCP数据段一旦超过MSS,就会进行分段,那么分段后交给IP层自然不会超过
MTU
- 但是IP分片的过程虽然对上层是透明的,但是有一个弊端,IP分片接收端进行组装的过程中如果发现丢失一片数据,就要对重传整个数据报,因为IP没有确认和超时重传机制。所以:
MSS,最大分段大小,TCP中的一个概念
- MSS就是TCP数据包每次能够传输的最大数据分段
- 需要减去IP数据包包头的大小20Bytes和TCP数据段的包头20Bytes)所以往往MSS为1460。通讯双方会根据双方提供的MSS值得最小值确定为这次连接的最大MSS值。
- IP分片由网络层完成,也在网络层进行重组;TCP分段是在传输层完成,并在传输层进行重组.
- MUT往往会大于MSS
Http & Https
Http
简介
- HTTP 协议构建于 TCP/IP 协议之上,是一个应用层协议,默认端口号是 80
- HTTP 是无连接无状态的
- 无连接:HTTP是请求-响应模式,对于每一个http请求,都会新建一个连接
- 一开始这么设计是因为之前互联网传输的内容相对简单,现在加载一个图片很多的网页,如果每一章图片的请求都需要建立一个连接,那么开销将会十分大
- 无状态:HTTP每一个请求都是独立的,服务端对事务处理没有记忆能力
- 无连接:HTTP是请求-响应模式,对于每一个http请求,都会新建一个连接
请求方法
get:从服务器获取资源,幂等的,幂等的意味着对同一 URL 的多个请求应该返回同样的结果。post:改变服务器资源put:上传资源delete:删除资源
get请求和post请求的区别?
- get请求从服务器获取资源,是幂等的,post是改变服务器资源,不幂等。
- get请求的参数是明文放在url中,且参数个数有限制,受限于浏览器url栏对其的限制,且参数明文不安全,post请求参数是放于请求体中,无限制,安全
状态码:
- 1xx:
- 100:继续接收请求
- 2xx:
- 200:请求成功
- 3xx:
- 301:永久重定向
- 302:临时重定向
- 4xx:
- 400:客户端请求语法有误
- 403:服务器收到请求但是拒绝服务
- 401:请求未经授权。这个状态代码必须和WWW-Authenticate报头域一起使用
- 404: 请求的资源不存在,例如,输入了错误的URL
- 5xx:
- 500:服务端错误
- 503:服务暂时不可用
解决无连接&无状态
- 解决无连接:
- keepalive:客户端和服务器之间的 HTTP 连接就会被保持,不会断开(超过 Keep-Alive 规定的时间,意外断电等情况除外),当客户端发送另外一个请求时,就使用这条已经建立的连接。
- 解决无状态:
- 无状态如果后续处理需要前面的信息则必须重传,如果需要大量重传,就会导致数据传送量很大带来不必要的开销
- cookie:cookie是存储在本地的小段文本并随每一个请求发送到同一个服务器
- 服务端将sessionId写到请求头
set-cookie字段中,客户端浏览器解析后保存在本地cookie文件。只要是同一服务器的请求都会带上这些cookies,服务器根据传来的cookie(sessionid)找到对应的session
- 服务端将sessionId写到请求头
- session:当程序需要为某个客户端的请求创建一个session时,服务器首先检查这个客户端的请求里是否已包含了一个session标识(称为session id),如果已包含则说明以前已经为此客户端创建过session,服务器就按照session id把这个session检索出来使用(检索不到,会新建一个),如果客户端请求不包含session id,则为此客户端创建一个session并且生成一个与此session相关联的session id,session id的值应该是一个既不会重复,又不容易被找到规律以仿造的字符串,这个session id将被在本次响应中返回给客户端保存。
CSRF & XSS
-
XSS:-
XSS攻击又称CSS,全称Cross Site Script (跨站脚本攻击),其原理是攻击者向有XSS漏洞的网站中输入恶意的 HTML 代码,当用户浏览该网站时,这段 HTML 代码会自动执行,从而达到攻击的目的。 xss攻击可以分成两种类型:一种是非持久型XSS攻击 一种是持久型XSS攻击。 通过正则表达式过滤传入参数的html标签来防范XSS攻击。
-
-
CSRF-
CSRF全称为跨站请求伪造(Cross-site request forgery)你这可以这么理解CSRF攻击:攻击者盗用了你的身份,以你的名义发送恶意请求。CSRF能够做的事情包括:以你名义发送邮件,发消息,盗取你的账号,甚至于购买商品,虚拟货币转账......造成的问题包括:个人隐私泄露以及财产安全。
-
Http基本优化
影响一个http请求的因素主要有两个:带宽和延迟
- 现在网络基础建设已经使得带宽得到极大的提升,我们不再会担心由带宽而影响网速,那么就只剩下延迟了。
- 浏览器阻塞(HOL blocking):浏览器会因为一些原因阻塞请求。浏览器对于同一个域名,同时只能有 4 个连接(这个根据浏览器内核不同可能会有所差异),超过浏览器最大连接数限制,后续请求就会被阻塞。
- DNS 查询(DNS Lookup):浏览器需要知道目标服务器的 IP 才能建立连接。将域名解析为 IP 的这个系统就是 DNS。这个通常可以利用DNS缓存结果来达到减少这个时间的目的。
- 建立连接(Initial connection):HTTP 是基于 TCP 协议的,浏览器最快也要在第三次握手时才能捎带 HTTP 请求报文,达到真正的建立连接,但是这些连接无法复用会导致每次请求都经历三次握手和慢启动。三次握手在高延迟的场景下影响较明显,慢启动则对文件类大请求影响较大。
Http各版本区别:
http1.0 exprires last-modified 连接无法复用
http1.1 etag cache-control 支持长连接(connection) 支持文件断点续传
http2.0 多路复用 首部压缩 server push 传输速度更快了
Https
Https解决了什么问题?
- 因为Http是明文传输的,所以在Http传输过程中,任何人都能从中截获,修改,伪造请求,所以Http是不安全的
- https是http + ssl,利用ssl对数据包进行加密,在通过http协议进行传输

https流程
https = 非对称加密 + 对称加密 + CA证书
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cdXUCK99-1599534168940)(https://camo.githubusercontent.com/149d65173b307d424c78a93987dbfdaeb4f8722c/68747470733a2f2f757365722d676f6c642d63646e2e786974752e696f2f323031392f342f32322f313661343538333963656163626235323f773d3138333426683d3130383026663d706e6726733d313537363832)]
https和http的区别:
- https = http + ssl,端口443,http明文传输,端口80
- HTTPS普遍认为性能消耗要大于HTTP,因为与纯文本通信相比,加密通信会消耗更多的CPU及内存资源
操作系统
基础
中断
中断就是计算机在执行程序的过程中,由于出现了某些特殊的事情,使得CPU暂停对程序的执行,转而去执行处理这一事情的程序,等到处理完毕再回去继续执行原先的程序
- 异常中断:计算机硬件异常
- 软中断:程序中执行了某些中断指令
- 外部中断:外部设备引起的中断
发生中断时,由内核中的中断处理程序进行中断处理
进程管理
什么是进程
- 进程是程序的一次执行过程,等于程序 + 数据
进程的状态转换
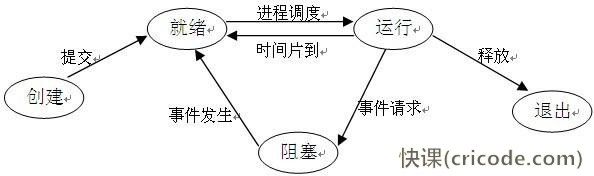
有一种还多了一个挂起,挂起和阻塞的区别在于进程的位置,进程还处于内存但是暂停执行了是阻塞,进程被换出到外存且暂停执行是挂起
进程调度
- 非抢占式
- 先进先出
- 非抢占式优先级调度
- 抢占式
- 抢占式优先级调度
- 最短作业调度
- 最短等待时间调度
- 多级反馈队列
进程同步
锁种类:
- 资源是否是独占(独占锁 - 共享锁)
- 独占锁:只能一个线程获取
- 共享锁:可以同时多个线程获取
- 抢占不到资源怎么办(互斥锁 - 自旋锁)
- 互斥锁:获取不到锁的线程只能阻塞等待
- 自旋锁:获取不到锁的线程循环等待
- 自己能不能重复抢(重入锁 - 不可重入锁)
- 已经获取锁的线程可以再次获取相同的锁(可重入)
- 竞争读的情况比较多,读可不可以不加锁(读写锁)
- 读读不互斥,读写互斥,写写互斥
- 锁升级:即当前获得了读锁,想把当前的锁变成写锁,称为升级,反之称为降级。锁的升降级本身也是为了提升性能,通过改变当前锁的性质,避免重复获取锁。
进程通信
- 共享内存
- 消息队列
- 管道
- socket
死锁
死锁产生的4个必要条件:
-
互斥使用(Mutual exclusion)
指进程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用毕释放。
-
不可抢占(No preemption)
指进程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放。
-
请求和保持(Hold and wait)
指进程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求进程阻塞,但又对自己已获得的其它资源保持不放。
-
循环等待(Circular wait) 指在发生死锁时,必然存在一个进程——资源的环形链,即进程集合{P0,P1,P2,···,Pn}中的P0正在等待一个P1占用的资源;P1正在等待P2占用的资源,……,Pn正在等待已被P0占用的资源。
线程
进程和线程的区别:
- 线程是进程内的一部分,线程是轻量级进程,共享进程内的地址空间,进程间地址空间是相互隔离的
- 线程上下文切换开销小于进程
- 线程是调度的最小单位,进程是资源分配的基本单位
协程
IO多路复用
IO多路复用是指内核一旦发现进程指定的一个或者多个IO条件准备读取,它就通知该进程。
实现:
- select
- poll
- epoll
优势就是开销小,易维护
存储管理
存储结构
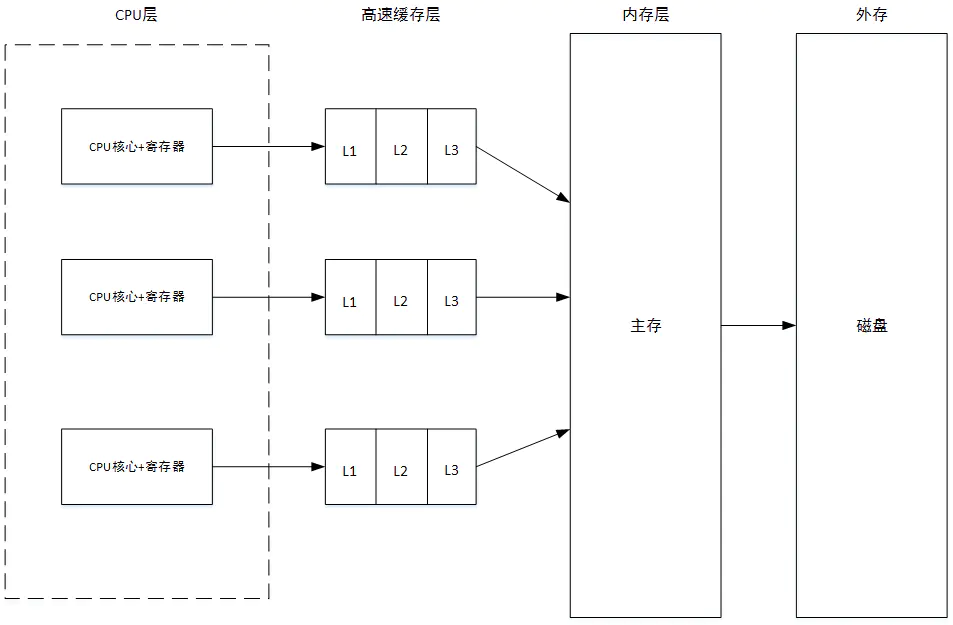
- CPU寄存器,极其昂贵,缓存了频繁使用的资源
- 高速缓存:平衡CPU和内存的读写速度差异,缓存的是最近和将来将要使用的数据
- 主存:进程会被加载到内存中
- 磁盘:一般存放可执行文件,资源文件,配置文件等。IO操作就是指对磁盘进行的读写操作。很多场景下IO操作是系统性能的瓶颈
程序的链接和装入
- 装入:将外存上的程序代码加载到内存的过程就是装入
- 装入过程中存在地址转换的这一过程,将程序上的逻辑地址转为实际物理地址
- 绝对装入:在程序代码编写的过程就确定了存储的物理地址。此时逻辑地址和物理地址保持一致。在现在操作系统中不会采用这种方式
- 可重定位装入:在程序装入内存时转换,物理地址= 相对地址 + 物理地址起始处,装入内存后,地址不可变
- 运行时装入:程序装入内存时不会执行转换,只有在真正执行代码时才会转换
- 装入过程中存在地址转换的这一过程,将程序上的逻辑地址转为实际物理地址
- 链接:
- 程序经过编译后形成多个目标模块,将多个目标模块组合起来的过程就是链接
- 静态链接
- 装入时链接
- 动态链接
- 程序经过编译后形成多个目标模块,将多个目标模块组合起来的过程就是链接
内存分配
- 连续存储空间分配:
- 单一连续存储分配
- 内存分为系统区和工作区,一个进程将会独占工作区
- 固定存储分配
- 内存分区划分为多个相等的分区,一个进程独占一个子分区
- 动态存储空间分配
- 在任务加载进内存时,依据任务所需内存大小实现按需分配。
- 可重定位的分区分配
- 该存储方式,在动态存储空间分配上添加了内存整理功能。若当前内存空间不能满足任务所需内存空间时,其会将已分配的内存空间全部移动,使未分配的内存空间形成一片连续的地址空间。该种方法则要求程序的装入方式是动态装入
- 单一连续存储分配
- 离散存储空间分配:
- 页式存储空间分配
- 段式存储空间分配
虚拟内存
虚拟内存实现了对物理内存的逻辑扩充,不会一次性将完整进程都调入内存,而是只调入进程的一部分到内存,另一部分还在外存,在需要时会调入内存,以页式存储为例
分页置换
- 在内存空间紧张时,会将程序中某些使用或者近期不在使用的页面,从内存置换到磁盘中去。
- LRU
- LFU
- 如果需要的页不在内存,会产生缺页中断,然后通过页面置换算法进行换页
- 如果产生频繁换页,则会产生内存抖动现象,系统效率会降低,需要考虑更换置换算法