DBSCAN聚集算法改进,可用于车辆GPS经纬度聚集计算
1、DBSCAN简介
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。
该算法利用基于密度的聚类的概念,即要求聚类空间中的一定区域内所包含对象(点或其他空间对象)的数目不小于某一给定阈值。
DBSCAN算法的优点:
1. 聚类速度快且能够有效处理噪声点和发现任意形状的空间聚类。
2. 与K-means方法相比,DBSCAN不需要事先知道要形成的簇类的数量。
3. 与K-means方法相比,DBSCAN可以发现任意形状的簇类。
4. 同时,DBSCAN能够识别出噪声点。
5. DBSCAN对于数据库中样本的顺序不敏感,即Pattern的输入顺序对结果的影响不大。但是,对于处于簇类之间边界样本,可能会根据哪个簇类优先被探测到而其归属有所摆动。
DBSCAN算法的弱点:
由于它直接对整个数据库进行操作且进行聚类时使用了一个全局性的表征密度的参数,因此也具有两个比较明显
1. 当数据量增大时,要求较大的内存支持I/O消耗也很大;
2. 当空间聚类的密度不均匀、聚类间距差相差很大时,聚类质量较差。
3. DBScan不能很好反映高尺寸数据。
4. DBScan不能很好反映数据集以变化的密度。
2、算法步骤
DBScan需要二个参数: 扫描半径 (eps)和最小包含点数(minPts)。 任选一个未被访问(unvisited)的点开始,找出与其距离在eps之内(包括eps)的所有附近点。
如果 附近点的数量 ≥ minPts,则当前点与其附近点形成一个簇,并且出发点被标记为已访问(visited)。 然后递归,以相同的方法处理该簇内所有未被标记为已访问(visited)的点,从而对簇进行扩展。
如果 附近点的数量 < minPts,则该点暂时被标记作为噪声点。
如果簇充分地被扩展,即簇内的所有点被标记为已访问,然后用同样的算法去处理未被访问的点。
DBScan需要二个参数: 扫描半径 (eps)和最小包含点数(minPts)。 任选一个未被访问(unvisited)的点开始,找出与其距离在eps之内(包括eps)的所有附近点。
如果 附近点的数量 ≥ minPts,则当前点与其附近点形成一个簇,并且出发点被标记为已访问(visited)。 然后递归,以相同的方法处理该簇内所有未被标记为已访问(visited)的点,从而对簇进行扩展。
如果 附近点的数量 < minPts,则该点暂时被标记作为噪声点。
如果簇充分地被扩展,即簇内的所有点被标记为已访问,然后用同样的算法去处理未被访问的点。
3、代码
在网上找到DBSCAN聚集算法源代码,运行了一下发现结果有些偏差,于是着手修复和改进,并可用于车辆GPS经纬度进行聚集,不多说直接贴代码了:
DataPoint.h文件
#ifndef DataPoint_H
#define DataPoint_H
#pragma once
#include
#include
using namespace std;
const int DIME_NUM=2; //数据维度为2,全局常量
//数据点类型
class DataPoint
{
private:
unsigned long dpID; //数据点ID
double dimension[DIME_NUM]; //维度数据
long clusterId; //所属聚类ID
bool isKey; //是否核心对象
bool visited; //是否已访问
vector arrivalPoints; //领域数据点id列表
public:
CString strDeviceID;//设备ID
int nVehicleID;//车辆ID
public:
DataPoint(); //默认构造函数
DataPoint(unsigned long dpID,double* dimension , bool isKey); //构造函数
unsigned long GetDpId(); //GetDpId方法
void SetDpId(unsigned long dpID); //SetDpId方法
double* GetDimension(); //GetDimension方法
void SetDimension(double* dimension); //SetDimension方法
void SetDimension(double* dimension, const CString deviceID); //SetDimension方法
void SetDimension(double* dimension, const int vehicleID); //SetDimension方法
bool IsKey(); //GetIsKey方法
void SetKey(bool isKey); //SetKey方法
bool isVisited(); //GetIsVisited方法
void SetVisited(bool visited); //SetIsVisited方法
long GetClusterId(); //GetClusterId方法
void SetClusterId(long classId); //SetClusterId方法
vector& GetArrivalPoints(); //GetArrivalPoints方法
};
#endif DataPoint.cpp文件
#include "stdafx.h"
#include "DataPoint.h"
//默认构造函数
DataPoint::DataPoint()
{
}
//构造函数
DataPoint::DataPoint(unsigned long dpID,double* dimension , bool isKey):isKey(isKey),dpID(dpID)
{
//传递每维的维度数据
for(int i=0; idimension[i]=dimension[i];
}
}
//设置维度数据
void DataPoint::SetDimension(double* dimension)
{
for(int i=0; idimension[i]=dimension[i];
}
}
//设置维度数据
void DataPoint::SetDimension(double* dimension, const CString deviceID)
{
SetDimension(dimension);
this->strDeviceID = deviceID;
}
//设置维度数据
void DataPoint::SetDimension(double* dimension, const int vehicleID)
{
SetDimension(dimension);
this->nVehicleID = vehicleID;
}
//获取维度数据
double* DataPoint::GetDimension()
{
return this->dimension;
}
//获取是否为核心对象
bool DataPoint::IsKey()
{
return this->isKey;
}
//设置核心对象标志
void DataPoint::SetKey(bool isKey)
{
this->isKey = isKey;
}
//获取DpId方法
unsigned long DataPoint::GetDpId()
{
return this->dpID;
}
//设置DpId方法
void DataPoint::SetDpId(unsigned long dpID)
{
this->dpID = dpID;
}
//GetIsVisited方法
bool DataPoint::isVisited()
{
return this->visited;
}
//SetIsVisited方法
void DataPoint::SetVisited( bool visited )
{
this->visited = visited;
}
//GetClusterId方法
long DataPoint::GetClusterId()
{
return this->clusterId;
}
//GetClusterId方法
void DataPoint::SetClusterId( long clusterId )
{
this->clusterId = clusterId;
}
//GetArrivalPoints方法
vector& DataPoint::GetArrivalPoints()
{
return arrivalPoints;
} ClusterAnalysis.h文件
#ifndef ClusterAnalysis_H
#define ClusterAnalysis_H
#include
#include
#include "DataPoint.h"
using namespace std;
//聚类分析类型
class ClusterAnalysis
{
private:
vector dadaSets; //数据集合
unsigned int dimNum; //维度
double radius; //半径
unsigned int dataNum; //数据数量
unsigned int minPTs; //邻域最小数据个数
unsigned long m_MaxclusterId; //最大簇ID;
void SetArrivalPoints(DataPoint& dp); //设置数据点的领域点列表
void KeyPointCluster( unsigned long i, unsigned long clusterId ); //对数据点领域内的点执行聚类操作
public:
ClusterAnalysis(){} //默认构造函数
bool Init(double radius, int minPTs); //初始化操作
bool Init(char* fileName, double radius, int minPTs); //从文件初始化
bool AddData(DataPoint &DP) ; //加载数据
bool DoDBSCANRecursive(); //DBSCAN递归算法
bool WriteToFile(char* fileName); //将聚类结果写入文件
double GetDistance(DataPoint dp1, DataPoint dp2, bool isGPS = true); //距离函数
unsigned long GetMaxClusterId(); //获取最大簇ID
DataPoint GetDataPoint(unsigned long clusterId, vector &DpSets);//根据点簇ID,获取对应数据,并返回其中一个核心对象
};
#endif
#include "stdafx.h"
#include "ClusterAnalysis.h"
#include
#include
#include
const double PI = 3.1415926535897932384626433;
const double R = 6.378137*1e6;
/*
函数:聚类初始化操作
说明:将半径,领域最小数据个数信息写入聚类算法类
参数:
double radius; //半径
int minPTs; //领域最小数据个数
返回值: true; */
bool ClusterAnalysis::Init(double radius, int minPTs)
{
this->radius = radius; //设置半径
this->minPTs = minPTs; //设置领域最小数据个数
this->dimNum = DIME_NUM; //设置数据维度
dataNum = 0;
return true; //返回
}
/*
函数:聚类初始化操作
说明:将数据文件名,半径,领域最小数据个数信息写入聚类算法类,读取文件,把数据信息读入写进算法类数据集合中
参数:
char* fileName; //文件名
double radius; //半径
int minPTs; //领域最小数据个数
返回值: true; */
bool ClusterAnalysis::Init(char* fileName, double radius, int minPTs)
{
this->radius = radius; //设置半径
this->minPTs = minPTs; //设置领域最小数据个数
this->dimNum = DIME_NUM; //设置数据维度
ifstream ifs(fileName); //打开文件
if (! ifs.is_open()) //若文件已经被打开,报错误信息
{
cout << "Error opening file"; //输出错误信息
exit (-1); //程序退出
}
unsigned long i=0; //数据个数统计
while (! ifs.eof() ) //从文件中读取POI信息,将POI信息写入POI列表中
{
DataPoint tempDP; //临时数据点对象
double tempDimData[DIME_NUM]; //临时数据点维度信息
for(int j=0; j>tempDimData[j];
}
tempDP.SetDimension(tempDimData); //将维度信息存入数据点对象内
//char date[20]="";
//char time[20]="";
double type; //无用信息
//ifs >> date;
//ifs >> time; //无用信息读入
tempDP.SetDpId(i); //将数据点对象ID设置为i
tempDP.SetVisited(false); //数据点对象isVisited设置为false
tempDP.SetClusterId(-1); //设置默认簇ID为-1
dadaSets.push_back(tempDP); //将对象压入数据集合容器
i++; //计数+1
cout< &DpSets; //要输出的数据
返回值: 核心对象 */
DataPoint ClusterAnalysis::GetDataPoint(unsigned long clusterId, vector &DpSets)
{
DataPoint KeyDP;
for(unsigned long i=0; i= minPTs) //若dp领域内数据点数据量> minPTs执行.包括该点
{
dp.SetKey(true); //将dp核心对象标志位设为true
return; //返回
}
dp.SetKey(false); //若非核心对象,则将dp核心对象标志位设为false
}
/*
函数:执行聚类操作
说明:执行聚类操作
参数:
返回值: true; */
bool ClusterAnalysis::DoDBSCANRecursive()
{
for(unsigned long i=0; i= dataNum) //防止访问出错
return;
DataPoint& srcDp = dadaSets[dpID]; //获取数据点对象
if(!srcDp.IsKey()) return;
vector& arrvalPoints = srcDp.GetArrivalPoints(); //获取对象领域内点ID列表
for(unsigned long i=0; i //直接输入输出数据
ClusterAnalysis cs;
cs.Init(2.5, 3, false);//点之间距离设定为2.5,最小聚集数量为3,false为不使用GPS计算距离
DataPoint point;
double tempPoint[19][2] ={2,2,3,1,3,4,5,3,3,14,8,3,8,6,9,8,10,4,10,7,10,10,10,14,11,13,12,8,12,15,14,7,14,9,14,15,15,8};
for(int i =0 ;i <19; i++)
{
point.SetDimension(tempPoint[i]);
cs.AddData(point);
}
cs.DoDBSCANRecursive();//执行聚类计算
std::vector dp;
DataPoint dp2;//返回其中一个点(最后一个点)
unsigned long nClusterCount = cs.GetMaxClusterId();//获取聚簇ID最大值(数量)
for(int i = 0; i < nClusterCount; i++)
{
dp2 = cs.GetDataPoint(i, dp);//获取聚集簇
for(auto itr = dp.begin(); itr != dp.end(); itr++)
{
TRACE("聚集簇ID:%d,坐标:%f,%f\r\n", itr->GetClusterId() , itr->GetDimension()[0], itr->GetDimension()[1]);
}
dp.clear();
}
cs.GetDataPoint(-1, dp);//获取噪声簇
for(auto itr = dp.begin(); itr != dp.end(); itr++)
{
TRACE("噪声点ID:%d,坐标:%f,%f\r\n", itr->GetClusterId() , itr->GetDimension()[0], itr->GetDimension()[1]);
}
//使用文件输入输出数据
ClusterAnalysis csFile;
csFile.Init("d:\\In.txt", 2.5, 3, false);//点之间距离设定为2.5,最小聚集数量为3,false为不使用GPS计算距离
csFile.DoDBSCANRecursive();//执行聚类计算
csFile.WriteToFile("d:\\Out.txt");//输出到文件 结果:
聚集簇ID:0,坐标:2.000000,2.000000
聚集簇ID:0,坐标:3.000000,1.000000
聚集簇ID:0,坐标:3.000000,4.000000
聚集簇ID:0,坐标:5.000000,3.000000
聚集簇ID:1,坐标:8.000000,6.000000
聚集簇ID:1,坐标:9.000000,8.000000
聚集簇ID:1,坐标:10.000000,7.000000
聚集簇ID:1,坐标:10.000000,10.000000
聚集簇ID:1,坐标:12.000000,8.000000
聚集簇ID:1,坐标:14.000000,7.000000
聚集簇ID:1,坐标:14.000000,9.000000
聚集簇ID:1,坐标:15.000000,8.000000
聚集簇ID:2,坐标:10.000000,14.000000
聚集簇ID:2,坐标:11.000000,13.000000
聚集簇ID:2,坐标:12.000000,15.000000
聚集簇ID:2,坐标:14.000000,15.000000
噪声点ID:-1,坐标:3.000000,14.000000
噪声点ID:-1,坐标:8.000000,3.000000
噪声点ID:-1,坐标:10.000000,4.000000输入输出文件:
In.txt文件
2
2
3
1
3
4
5
3
3
14
8
3
8
6
9
8
10
4
10
7
10
10
10
14
11
13
12
8
12
15
14
7
14
9
14
15
15
8输出结果Out.txt
2 2 0
3 1 0
3 4 0
5 3 0
3 14 -1
8 3 -1
8 6 1
9 8 1
10 4 -1
10 7 1
10 10 1
10 14 2
11 13 2
12 8 1
12 15 2
14 7 1
14 9 1
14 15 2
15 8 1
附图:
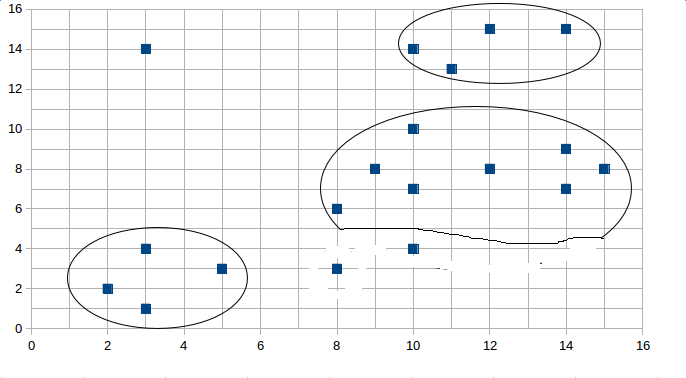
如果用于GPS车辆的聚集,可能会形成如下图形:

本文章提及的代码和数据DEMO下载地址:
http://download.csdn.net/download/winnyrain/10241173