CHI协议层
CHI协议层综述------待写
一、传输通道和域段
1.1 传输通道
协议节点之间的通讯是基于通道channels进行的,表1为RN和SN节点的通道名字和功能:
表1
| Channel | RN channel designation | SN channel designation |
|---|---|---|
| REQ | TXREQ. Outbound Request | RXREQ. Inbound Request |
| WDAT | TXDAT. Outbound Data。used for write data,atomic data,snoop data,forward data | RXDAT. Inbound Data。used for write data,atomic data |
| SRSP | TXRSP. Outbound Response。used for snoop response and completion acknowledge | — |
| CRSP | RXRSP. Inbound Response。used for response from completer | TXRSP. Outbound Response。used for responses from the completer |
| RDAT | RXDAT. Inbound Data。used for read data,atomic data | TXDAT. Outbound Data。used for read data,atomic data |
| SNP | RXSNP. Inbound Snoop Request | — |
1.2 域段
transaction是有许多不同的packets组成,而且transaction结构随着packets中的域段不同也可能不同。只有request channel和snoop channel中的某些域段可能会影响transaction structure,Response packet和Data pacet不会影响transaction structure,域段上携带有packet的信息。具体每个通道包含的域段的含义可以查下CHI issueC 表2-2至2-5手册,不仔细列出了,只是阐述总结性的知识点。
1.2.1 ID域段
Target Identifier(TgtID),Source Identifier(ScrID):用于packet在ICN上的路由;
Transaction Identifier(TxnID),Data Buffer Identifier(DBID),Return Transaction Identifier(ReturnTxnID),Forward Transaction Identifier(FwdTxnID)用于关联同一个transaction的所有packets;
Data Identifier(DataID),Critical Chunk Identifier(CCID):用于同一个transaction内表示特定的data packets;
Logical Process Identifier(LPID),Stash Logical Processor Identifier(StashLPID):用于同一个Requester内表示特定的处理器单元;
Stash Node Identifier(StashNID):该域段用于标识Stash的目的节点;
Return Node Identifier(ReturnNID),Forward Node Identifier(FwdNID):这些域表示了返回数据响应应该送到的节点;
Home Node Identifier:该域标识了CompAck响应应该送到的节点;
在每个packer中使用到的域段也一样,如下:
- Request packet:TgtID,SrcID,TxnID,LPID,StashNID,StashLPID,ReturnNID,ReturnTxnID;
- Response packet:TgtID,SrcID,TxnID,DBID;
- Data packet:TgtID,SrcID,TxnID,HomeNID,DBID;
- Snoop packet:SrcID,TxnID,FwdNID,FwdTxnID,StashLPID;
在看transaction Identifier field flow时,记得遵循以下规定,就很easy了:
- 所有的带有相同颜色的域段的值是一样的;
- 用箭头表明后续packets是由哪个产生的;
- 包含*的表示第一次产生,由当前agent产生该域的原始值;
- 带圆括号()的表示该域是固定值,典型如Requester发送packets的SrcID,packets到达Completer的TgtID;
- 被划掉的域段表示该域段无效;
- 可以被ICN remapped的TgtID要标识上字母R;
- 任何和当前传输不相关的域段在CHI协议域段流程图上省略了;
具体的Read transactions、Write transactions、Dataless transactions和DVMOp transaction等transactions的域段传输流程图可以看下issueC的图2-24至2-33,里面有详细的各个域段转换说明;
这里补充下LPID这个域段的一些知识:
CHI协议在Request transaction里定义了一个LPID,如果在一个Requester内部包含多个logical processes,该域段用于标识唯一Logical process。在以下transactions中,LPID必须设置为正确的值:
- For any Non-snoopable Non-cacheable or Device acess:ReadNoSnp、WriteNoSnp;
- For Exclusive accesses,that can be one of the following transaction types:ReadClean、ReadShared、ReadNotSharedDirty、CleanUnique、ReadNoSnp、WriteNoSnp;
除了以上的操作,其他transaction的LPID域也可以用于标识发送transaction的original logical processor,但是该功能在CHI中是可选的。
1.2.2 其他关键域段
Packet包含了其他的定义Transactions行为的属性信息,这些属性通过Packet域段传递到总线上,总线解析这些信息并采取相对应的操作。这些信息有:address、Secure bit、memory attributes、likely shared、snoop attributes、Do not transition to SD、data formatting。
1.2.2.1 Address
CHI协议支持
- Physical Address(PA) of 44 to 52 bits, in one bit increments
- Virtual Address(VA) of 49 to 53 bits
对于REQ和SNP packet的地址域为: - REQ channel:Addr[(MPA-1):0]
- SNP channel:Addr[(MPA-1):3]
MPA是PA的最大值;对于REQ packet的地址位宽为44bit-52bit,SNP packet的地址位宽为41bit-49bit,地址信息在不同的message类型中有不同的用途,如下: - 对于Read、PrefetchTgt、Datelss、Write、Atomic transactions,REQ的addr域就是要访问memory的地址信息;
- 对于Snoop request,除了SnpDVMOp,Addr[(43-51):6]用于snoop cacheline;Addr[5:4]标识transaction访问的critical chunk,CHI协议建议被snoop的cache data以wrap形式且最先critical chunk的形式返回;Addr[3]不用;
- 对于DVMOp操作,Addr信息是用于携带DVM操作的相关信息;
- PCrdRetrun transaction的地址域必须为0;
1.2.2.2 Secure bit
Request transaction可以定义Secure bit来指定该操作安全和非安全;对于Snoopable transactions,secure field可以认为是附加的地址bit,因此相当于定义了两份地址空间:安全地址空间和非安全地址空间,硬件一致性没法管理安全和非安全地址空间的一致性,因此使用时要正确处理好。Secure field可以在以下操作中使用:
- 所有Read、Dataless、Write、Atomic transaction
- PrefetchTgt transaction
- 在DVMOp和PCrdRetrun中不用,且必须为0
1.2.2.3 Memory Attributes
Memory Attributes(MemAttr)是由Early Write Acknowledge(EWA),Device,Cacheable和Allocate组成的。
1、EWA
EWA用于指示写完成信号从哪个节点返回。如果EWA置位,写完成信号可以来自中间节点(如:HN),也可以来自endpoint(最终节点),来自中间节点的完成信号必须提供同样的Comp响应来保证;如果EWA不置位,写完成响应必须来自最终节点;
注意:如果不实现EWA功能的话,那么写完成响应必须来自endpoint。
EWA是否置位根据transaction分类如下:
- ReadNoSnpSep、ReadNoSnp、WriteNoSnp、CMO、Atomic transaction可以采用任意值;
- 除了ReadNoSnpSep、ReadNoSnp、CMO、WriteNoSnp之外的所有Read、Dataless和Write transaction必须将EWA置位;
- 在DVMOp或PCrdRetrun transaction中不使用,tie为0;
- 在PrefetchTgt中不使用,为任意值;
2、Device
Device属性指示访问的memory属性是Device还是Normal。
Device memory type:
Device memory type空间必须用于地址相关性的memory空间,当然用于地址不相关性的空间也允许。
访问Device type memory空间的transaction有如下要求:
- Read transaction不能读到比要求更多的数据;
- PrefetchTgt不能访问Device memory空间;
- 读数据必须来自endpoint,不能来自同地址write操作的中间节点;
- 不能将多笔访问不同地址的请求组合成一笔,也不能将访问同一个地址的多个不同请求组合成一笔;
- 写操作不能merged;
- 访问Device memory的写操作的完成信号是来自中间节点的话,需要即使使写数据对endpoint节点可见。
访问Device memory的transaction必须使用以下类型: - 必须使用ReadNoSnp操作去读Device memory空间;
- 必须使用WriteNoSnp或WriteNoSnpPtl去访问Device memory空间;
- CMO和Atomic操作允许访问Device空间;
- PrefetchTgt不允许访问Device memory空间,该bit不用且可以为任意值;
Normal memory type:
Normal memory type空间用于地址不相关的memory空间,不能用于地址相关的memory空间。
访问Normal memory空间在prefetching或forwarding上没有和Device type memory空间同样的约束: - EWA的读数据可以来自同地址write操作的中间节点;
- 写操作可以merged;
任何Read、Dataless、Write、PrefetchTgt、Atomictransaction类型都可以去访问Normal memory空间。具体使用的transaction type要完成的memory操作和Snoopable属性。
3、Cacheable
Cacheable属性用于指示一笔transaction是否必须执行cache查找:
- 当Cacheable置位时,transaction必须执行cache查找;
- 当Cacheable没置位时,transaction必须访问最终节点;
Cacheable attribute的值有如下要求: - 对于任何的Device memory transaction,必须不置位;
- 除了ReadNoSnpSep和ReadNoSnp,任何Read transaction必须置位;
- 除了CMO操作,任何Dataless操作必须置位;
- 除了WriteNoSnp和WriteNoSnpPtl,任何write transaction都必须置位;
- 在ReadNoSnpSep、ReadNoSnp、WriteNoSnpFull、WriteNoSnpPtl访问Normal memory空间时,可以为任何值;
- 在CMO和Atomic transactions中可以为任意值;
- 在DVMOp和PCrdRetrun transaction中必须为0;
- 在PrefetchTgt中不会用,可以为任意值;
注意:如果一笔transaction的Cacheable可以设置为任意值,通常情况下是有page table attributes决定的。
4、Allocate
Allocate attribute是一种cache缓存分配指示,它指示一笔transaction是否推荐分配cache缓存,具体如下:
- 如果Allocate置位,出于性能考虑,建议该笔transaction的数据应该被分配到cache中,但也可以不分配;
- 如果Allocate不置位,出于性能考虑,建议该笔transaction的数据不应该被分配到cache中,但其实也可以分配的;
Allocate attribute值有如下要求: - 可以在任意Cacheable置位的transaction中置位;
- WriteEvictFull操作必须置位;如果WriteEvictFull的Allocate没有置位,RN可以将其转换为Evict操作;
- 对于Device memory transaction必须不能置位;
- 对于Normal Non-cacheable memory transaction中不能置位;
- 在DVMOp、PCrdRetrun和Evict操作中不使用,必须设置为0;
- 在PrefetchTgt中不使用,可以设置为任意值;
5、Propagation of Attr
MemAttr属性在一笔transaction从HN发往SN时必须要保留,有一种情况除外:当知道downstream memory是Normal类型,那Device域值要设置为0来知识Normal类型;
SnpAttr attribute bit值在HN到SN中不需要保留,且必须设置为0;
由于HN的Prefetch预取或者SystemCache的eviction操作下产生的ReadNoSnp和WriteNoSnp transaction,相关属性设置如下:
- MemAttr中的EWA、Cacheable、Allocate必须全部设置为1;
- Device属性必须设置为0指示是Normal type;
- SnpAttr属性必须设置为0指示是Non-snoopable;
1.2.2.4 Transaction attribute combinations
表1列出了合法的MemAttr、SnpAttr和Order域组合,并且等价于相应的ARM memory type。
表1 Legal combinations of MemAttr, SnpAttr, and Order field values

对于表1所示的每种Memory type的具体规格下面将进行阐述:
1、Device nRnE
Device nRnE memory type有如下行为:
- 写响应必须从最终节点获得;
- 读数据必须从最终节点获得;
- 读数据不能得到比预期要求的更多;
- 读操作不能被预取;
- 写操作不能被merged;
- 写操作不能写大于原始transaction的地址范围;
- 来自同源的所有读和写transaction去往同一个endpoint必须要保序;
2、Device nRE
Device nRE memory type的行为和Device nRnE memory一致,除了:
- 写响应可以从中间节点获得;
3、Device RE
Deivce RE memory type的行为和Device nRE memory一致,除了:
- 来自同一个源的读和写transactions发往同一个endpoint不需要保序;
- 来自同一个源的读和写transactions发往有交叠地址的需要保序;
4、Normal Non-cacheable Non-bufferable
Normal Non-cacheable Non-bufferable memory type的行为如下:
- 写响应必须来自最终节点;
- 读数据必须来自最终节点;
- 写操作可以被merged;
- 同一个源的读和写transactions发往有交叠地址的需要保序;
5、Normal Non-cacheable Bufferable
Normal Non-cacheable Bufferable memory type的行为如下:
- 写响应可以从中间节点返回;
- 写transaction必须对最终节点及时可见,但没有机制能够决定何时写transaction可以被最终节点可见;
- 读数据可以从几个地方获取:a. 最终节点;b. 正在发往最终节点的写传输,如果数据时从写传输中获得,那么它必须来自最近的写传输,而且数据不能被后期读缓存起来;
- 写操作可以被merged;
- 同一个源的读和写transactions发往有交叠地址的需要保序;
6、Write-back No-allocate
Write-back No-allocate memory type的行为如下:
- 写响应可以从中间节点返回;
- 写传输不要求对最终节点可见;
- 读数据可以从中间cahce获得;
- 读操作可以prefetch预取;
- 写可以被merged;
- 读和写transaction需要查找cache;
- 同一个源的读和写transactions发往有交叠地址的需要保序;
- No-allocated attribute只是一种cache分配暗示,为了性能考虑,建议不缓存到cache中,但是也可以被allocate到cache中;
7、Write-back Allocate
Write-back Allocatememory type的行为和Write-back No-allocate memory一样,除了该种memory为了性能考虑,是建议缓存数据,但其实也可以不缓存;
1.2.2.5 Likely Shared
LikelyShared是一种cache分配指示。在置位时指示requested data可能在其它RN节点中也共享着,只是为了性能考虑的一种指示作用;
LikeShared的置位规则如下:
- 这几种操作可以置位:ReadClean、ReadNotSharedDirty、ReadShared、StashOnceUnique、StashOnceShared、WriteUniquePtl、WriteUniqueFull、WriteUniquePtlStash、WriteUniqueFullStash、WriteBackFull、WriteCleanFull、WriteEvictFull;
- 其它的Read和Write操作中不能置位;
- 其它的Dataless和Atomic操作中不能置位;
- 在DVMOp和PCrdRetrun transaction中没有用,tie 0;
- 在PrefetchTgt transaction中没有用,可以为任意值;
1.2.2.6 Snoop Attribute
Snoop Attribute(SnpAttr)指示一笔transaction是否需要snoop,有Non-snoopable和Snoopable两种,不同命令类型的snoop属性如表2所示。
表2 Snoop attributes for the different transaction types
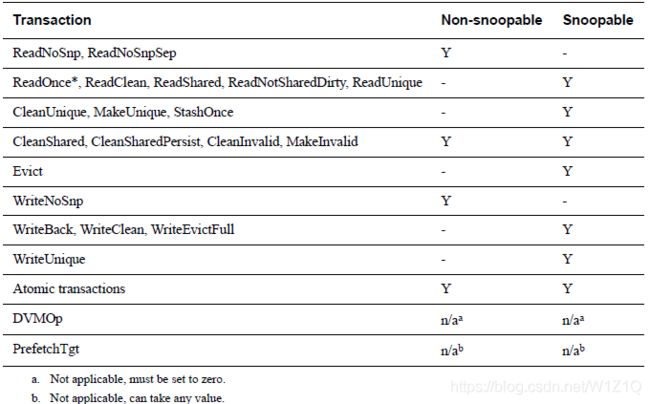
不管原始Request发送HN的SnpAttr域为何值,从HN发送SN的CMO、ReadNoSnpSep和ReadNoSnp的SnpAttr域值必须设置为0。
注意:对于可以取多个SnpAttr值的transaction,SnpAttr通常是由page table(页表) attribute决定的。
1.2.2.7 Do not transition to SD
Do not transition to SD是non-invalidating snoop的一种指示符,它指定被snoop的RN在snoop之后不能将cache状态变为SD态;
在以下几种Snoop requests中可以根据场景使用:SnpCleanFwd、SnpClean、SnpNotSharedDirtyFwd、SnpNotSharedDirty、SnpSharedFwd、SnpShared;
在以下几种Snoop requests中该域段必须设置为1:SnpUniqueFwd、SnpUnique、SnpCleanShared、SnpCleanInvalid、SnpMakeInvalid;
在以下几种Snoop requests中可以为任意值,且被snoop的RN要忽略这些值:SnpOnceFwd、SnpOnce;
除了以上这些snoop requests,其它snoop requests没有用到;
Do not transition to SD是通过SNP packet的DoNotDataPull域段体现出来的,如果被snoop的RN已经是SD态,DoNotGoToSD=1,那么它必须放弃SD态;
1.2.2.8 Mismatched Memory attributes
CHI协议允许两个不同agents在同一个时间点,采用不匹配的MemAttr或SnpAttr memory attribute访问相同的地址空间,这种情况可以认为是software protocol error,会导致一致性失效和数据值的损坏。CHI协议要求在software protocol error发生时不存在死锁情况,且transaction仍可以进行。
使用mismatched memory attributes会导致RN-F正在进行ReadNoSnp或WriteNoSnp操作时,收到同地址的Snoop transaction,在这种情况下,Snoop transaction和RN-F已经发送的transaction之间的顺序是不确定的;
对于访问一个4KB memory region的software protocol error不能导致其它4KB memory region的数据损坏;对于位于Normal memroy区域的,使用恰当的software CMO操作可以使memory区间返回到一个确定的状态。
1.2.2.9 Data formatting
Read、Write、Atomic transactions和Snoop responses with data都有data payload。对于不同组合的address、transaction size、memory type,本节讲述数据对齐规则和访问的data bytes。
1、Data size
Size域段结合其它域段可以决定多少访问多少bytes,表3为不同Size域段对应的Byte数,Snoop transactions不包含Size域段,所有的snoop data传输都是64 Bytes。
表3 Size field value encoding
| Size[2:0] | Bytes |
|---|---|
| 0b000 | 1 |
| 0b001 | 2 |
| 0b010 | 4 |
| 0b011 | 8 |
| 0b100 | 16 |
| 0b101 | 32 |
| 0b110 | 64 |
| 0b111 | Reserved |
2、Bytes access in memory
MemAttr[1]域决定memory type是Device或Normal,对于不同memory type,访问得到的byte数不一样,具体如下:
2-a、Normal Memory
Normal memory type的transactions访问的byte数量取决于Size域,数据时从Aligned_Address(nearest Size boundary)到下一个Size boundary。计算方式为:
Start_Address = Addr field value;
Number_Bytes = 2^Size field value;
INT(x) = Rounded down integer value of x;(即x向下取整)
Aligned_Address = (INT(Start_Address/Number_Bytes)) x Number_Bytes;
The Bytes accessed are from (Aligned_Address) to (Aligned_Address+Number_Bytes) -1;
Device
2-b Device
Device memory type的transaction访问的byte数量是从transaction address到next Size boundary,即the bytes accessed are from (Start_Address) to (Aligned_Address + Number_Bytes) - 1;
对于Device区间的写操作,Byte enables必须只对访问的bytes置位;
3、Byte Enables
Byte Enables也简称为BE,与Write transactions和Snoop response with Data一起传输;
对于Write transactions,BE置位意味着相应data byte有效,且数据必须更新到memory或cache,BE不置位意味着相应data byte无效,且数据不能更新到memory或cache。
在Write Data和Snoop response Data中,BE无效必须设置相应byte value为0;
如果RN在发request和data之间,有snoop请求过来,将Dirty data snoop 走了,那么CopyBackWrData_I packet将会作为Data Response发送给HN,告知HN说Copyback request的Copyback取消了,RN必须将CopyBackWrData_I packet的所有BE值置为0。如果WriteUniquePtl、WriteUniquePtlStash、WriteNoSnpPtl被取消掉,RN也必须将WriteDataCancel的所有BE值设置为0;
除了write data是CopyBackWrData_I packet,以下Write transactions在数据传输时必须将全部BE设置为1:
- WriteNoSnpFull
- CopyBack:WriteBackFull、WriteCleanFull、WriteEvictFull
- WriteUniqueFull、WriteUniqueFullStash
对于以下Write transactions允许BE以任意组合,包括全部有效或全部无效: - WriteBackPtl
- WriteUniquePtl、WriteUniquePtlStash
对于WriteNoSnpPtl transaction,有以下约束: - 如果访问的是Normal memory,BE可以任意组合,包括全部有效或全部无效;
- 如果访问的是Device memory,有效的BE必须在高于或等于transaction中指定的address。在address之上的任意BE组合都允许,包括全部有效或全部无效;
对于所有的Write transaction,如果BE不在Addr和Size指定的data窗口内,则必须为0;
对于Atomic transaction,如果BE不在以下Addr和Size指定的data窗口内,则必须为0: - 如果Addr与Size对齐,Data window等于[Addr:(Addr+Size-1)];
- 如果Addr不与Size对齐,Data window等于[(Addr-Size/2):(Addr+Size/2 -1)];
- 对于Atomic transaction,在Data window内的所有的data的BE都必须有效;
对于Snoop Responses with data使用SnpRespData opcode时,所有的BE都必须有效;
对于Snoop Responses with data使用SnpRespDataPtl opcode时,任意组合的BE都可以,包括全部有效或全部无效;
4、Data packetization
对于带data的每个transaction,data bytes可以使用多个packets传输,packets的个数取决于:
- Number of bytes
- Data bus width
每个packet的byte数取决于:
- Data bus width
CHI协议支持以下的data bus width:
- 128-bit
- 256-bit
- 512-bit
DataID和CCID用于标识一个transaction内的packet,如如果一个transaction的byte数为16通常用一个packet就可以传输完,DataID域的值必须等于Addr[5:4],因为DataID域代表一个packet里最低地址byte的Addr[5:4]。表3为DataID在不同data bus widths下的值。
表3 DataID and the bytes within a packet for different data widths
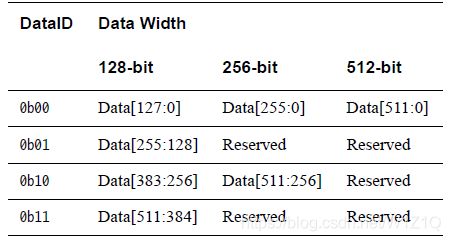
在一个data packet内,所有byte都位于他们原始byte位置,即使只有少量data bytes需要在data bus上传输。
对于访问Device空间的transaction中data packets的数目与transaction中的address无关,需要的data packets数目只取决于Size域和data bus width。
CCID域用于标识一个transaction request中最关键的data butes,CCID域必须等于原始请求的Addr[5:4]值,一个包含多个data packets的transaction中,所有的data packets的CCID值必须全部一样;CCID的作用是:如果多个data packet在ICN内被reorder了,那么可以用DataID和CCID相匹配,如果相等就是第一个关键packet。至于用几bit去匹配取决于data bus width:如果是128bit的data bus,CCID和DataID必须全部匹配;如果是256bit的data bus,那只需要匹配CCID和DataID的最高位;
5、Critical chunk first wrap order
Data的发送者允许但不要求发送一个transaction里的每个独立Data packet以critical chunk first wrap order。接口属性CCF_Wrap_Order定义了Sender的能力以及Receiver接收的保证:
- CCF_Wrap_Order at the Sender:True,Sender表示其有能力以critical chunk first wrap order发送data packets;False,Sender表示其没有能力以critical chunk first wrap order发送data packets;
- CCF_Wrap_Order at the ICN:True,ICN保证其有能力按接收顺序保持一个transaction内Data packets的顺序;False,ICN不保证其有能力按接收顺序保持一个transaction内Data packets的顺序;
- CCF_Wrap_Order at the Receiver that is not an ICN:True,Receiver要求data packets以critical chunk first wrap order被接收,即要送来的数据就是critical chunk first wrap order;False,Receiver不要求data packets以critical chunk first wrap order被接收;
注意:在设计时,CCF_Wrap_Order参数可以帮助一个组件判断是否需要以critical chunk first wrap order形式发送Data。例如:如果组件知道自己连接到out-of-order总线,那么它可以通过不支持以critical chunk first wrap order形式发送Data来简化它的data packet path。如果ICN支持CCF_Wrap_Order属性,那么RN以critical chunk first wrap order发送data packets,receiver(SN)就可以以critical chunk first来接收数据,这样可以优化latency。
Wrap order按如下定义:
Start_Address = Addr;
Number_Bytes = 2^Size;
INT(x) = Rounded down integer value of x;
Aligned_Address = (INT(Start_Address/Number_Bytes)) x Number_Bytes;
Lower_Wrap_Boundary = Aligned_Address;
Upper_Wrap_Boundary = Aligned_Address + Number_Bytes -1;
为了保持wrap order,order顺序如下:
a. 第一笔data packet必须对应于Start_Address所指定的data bytes;
b. 接下一笔必须对应于地址递增方向的data bytes,直到Upper_Wrap_Boundary;
c. 接下一笔必须对应于Lower_Wrap_Boundary;
d. 接下一笔必须对应于地址递增方向的data bytes,直到Start_Address;
对于Data transfer examples可以参见CHI-issueC 122页,这里不仔细说明。
1.2.2.10 Request Retry
为了防止request transactions将REQ通道堵住,CHI协议提供了一种request retry机制,当Completer无法接收request transaction时,可以发RetryAck响应。除了PrefetchTgt和PCrdRetrun,其它命令都可以被Retry。
除了PrefetchTgt,Requester要求保留住所有已发送的request,直到收到request对应的完成响应或者retryack指示后续再发送,为了达到该要求,除了PrefetchTgt,transaction在第一次发送时AllowRetry需要置位,即允许retry。
Completer通常在没有资源和没有足够存储空间来存放当前的request transaction时,会对Requests进行retry,如果earlier transactions完成并释放资源了,就可以发送PCrdGrant响应允许二次发送命令。当Completer对request进行retry,它需要记录该笔request的来源(通过SrcID),也需要决定和记录Protocol Credit的类型,因为后续PCrdGrand的P-Credit type要和RetryAck中的一致。当Completer有资源后,它必须发送通过PCrdGrant响应发送P-Credit给Requester,通知Request被retry的transaction可以再发送;
由于ICN可能reorder PCrdGrant和RetryAck,会导致Request先收到PCrdGrant后收到RetryAck的情况,在这种场景下,Requester必须记录已经接收到的P-Credit,包括credit类型,这样子收到RetryAck响应时就可以正确的选择P-Credit,不过这种场景很少见。
当Requester接收到一个P-Credit,重发request时不能将AllowRetry域置位,因此该request已经保证可以被接收了。在transaction被重新发送的时,所有的域段都必须相同,除了以下几个:
- TgtID
- Qos
- TxnID
- 对于HN发往SN的ReadNoSnpSep和ReadNoSnp命令的ReturnTxnID
- RSVDC
- AllowRetry必须不置位
- PCrdType必须设置为Retry response中的值;
- TraceTag
P-Credit和transactions之间没有固定的关系,如果Requester收到多笔RetryAck响应,但只得到一个P-Credit,那么Requester可以自由选择一个最适合的被retry的transaction来消耗这个P-Credit。Retry机制支持16种不同的P-Credit type,因此Completer可以用不同的P-Credit type来服务不同的资源。比如:Completer可能使用一种P-Credit type标识Read transactions的资源,用另一种P-Credit type标识Write transactions的资源。用不同的P-Credit type来控制被retried request的发送,使得Completer有效的管理它的资源。因为,Requester只有收到的PCrdGrant中的PCrdType和RetryAck中的PCrdType一致才能重新发送被retry的命令。
为了正确的分发P-Credit,Completer必须有能力记录所有被Retry的命令。如果Completer使用多种P-Credit type给RetryAck响应,那么每种P-Credit type都必须被记录;Requester必须要限制发送的outstanding transactions的数目不要达到256,这样Completer可以永远不需要去跟踪超过256的RetryAck命令。
一笔outstanding的transaction从该笔命令发送的当前时钟周期开始,直到以下两种情况:
- 该笔transaction完全结束,通过以下几种响应决定:ReadReceipt,CompData,DBIDResp,Comp,CompDBIDResp;
- 接收到RetryAck和PCrdGrant,并且如下选择一种:a. 被Retry的命令重新发送并收到所有的响应;b. 使用PCrdRetrun message将P-Credit返回回去,即取消重新发送;
Requester在以下情况可以选择reuse TxnID: - 一笔request被收到RetryAck响应的TxnID;
- 对于non-retry request,收到该笔request的所有响应;
每一笔transaction request包含一个Qos值,可以用于影响Completer在有资源时分配P-Credit。
1、Credit Return
Requester可能收到比需要更多的P-Credits,CHI协议没有定义这种场景会发生,但有两种典型的场景是: - 在第一次发送到收到PCrdGrant之间就把transaction取消掉了;
- 一笔transaction要求随着Qos值的增加多次传输,但是只有一笔完成响应需要;
Requester通过PCrdRetrun返回P-Credit,告知Completer PCrdType分配的资源已经不需要了,任何不需要的P-Credit都需要及时释放掉,不能保留它们以备后续使用,这样可能会造成资源浪费并且给分析系统性能带来困难;
2、Transaction Retry mechanism
本小结阐述request transaction中用于Retry相关的域段,PrefetchTgt不支持retry。
AllowRetry:
AllowRetry指示一笔transaction能否被Retry。如果transaction是第一次发送,那么AllowRetry必须置位;AllowRetry在以下情况下必须不置位:
- transaction使用pre-allocated P-Credit;
- transaction是PrefetchTgt;
PCrdType:
PCrdType指示request请求中的credit type类型,具体取值按如下原则:
- 对于Request transaction:如果AllowRetry置位,那么PCrdType域值设置为0b000;如果AllowRetry不置位,那么PCrdType域值必须等于RetryAck响应中的PCrdType的值;
- PCrdRetrun transaction必须设置credit type等于Completer返回的credit type;
- 对于Completer只有一个简单的credit分类,或没有credit分类,CHI协议建议将PCrdType域值设置为0b000;
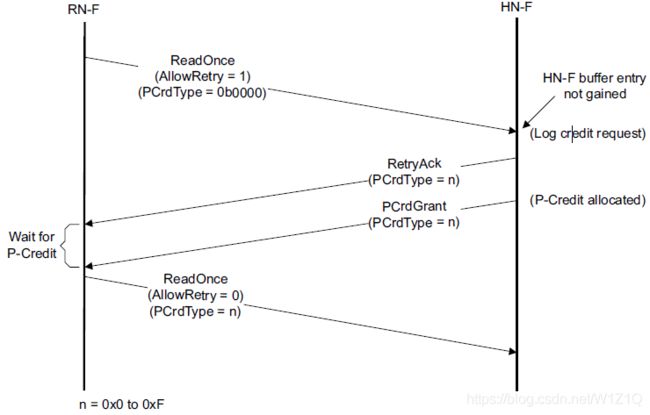
Completer在实现时必须考虑放饿死机制,确保所有的transactions不管它们的Qos值或需要credit type类型,即时需要很长时间,最终都可以进行执行下去。这个可以通过给每个已经收到RetryAck的transaction都确保分配credit来保证。
下图展示了transaction retry flow的示意图:
二、各请求命令传输结构(Transaction Structure)
根据transactions的不同可以分类为:Read、Dataless、Write、Atomic、Other、Snoop。这些类型在《CHI基本概念介绍》中有讲解,本节将按如下方式阐述Transaction structure:
- Request transactions without a Retry,对于完整的Request transaction流程,Snoop transaction可能也需要,但是对于Requester来说不可见,因此本节将两者分开描述;
- Request transactions with a Retry,除了PCrdReturn和PrefetchTgt命令,其余命令都支持Retry操作,为了便于讨论,Retry流程也将单独讨论;
- Snoop transactions;
2.1 Read Transactions
2.1.1 Snoop Reads excluding ReadOnce*
除了ReadOnce*操作,snoopable读操作有:
- ReadClean
- ReadNotSharedDirty
- ReadShared
- ReadUnique
snoopable读操作通常是RN-F发出的,用于获取其它RN或SN的数据,该数据会被cache所缓存。
根据数据来源的不同可以分为以下三类:
2.1.1.1 Read transaction structure with DMT
DMT用于当数据可以直接从SN发送给原始Requester,传输结构如图1所示。对于Request/Response必须遵循的原则如下:
-
Completer必须收到读请求后,才能发送相应的CompData;
-
Requester必须收到至少一个CompData packet后,才能发送CompAck,在issueC之前,是必须全部收到数据包后,才能发送;
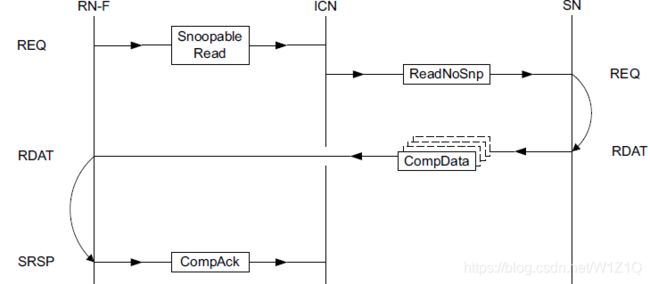
图1 Snoopable Read DMT structure
DMT限制: -
必须所有带TxnID的Response都返回后,Requester才能重复利用该TxnID;
-
HN只有满足以下条件才能发送DMT请求给SN-F:1. Snoop请求不需要发送;2. 如果snoop请求已经发送了,所有的snoop响应都已经回来,且没有Dirty数据;3. 如果snoop响应包含有Partial Dirty数据,Partial Dirty数据必须写到SN-F,且收到completion响应后,HN才能发送DMT请求;4. 如果是Forwarding类型的snoop请求,只有没有forward传输给Requester,HN才允许发送DMT请求;
注意:HN可以同时使能DMT和DCT,但是必须等DCT响应回来后,才能发送DMT请求给SN-F。
2.1.1.2 Read transaction structure with DCT
DCT用于被snoop的RN-F可以直接返回数据给原始Requester,传输结构如图2所示。对于Request/Response必须遵循如下原则:
- Completer必须收到snoop请求后,才能发送CompData;
- Requester必须收到至少一个CompData packet后,才能发送CompAck,在issueC之前,是必须收到全部数据包后,才能发送;
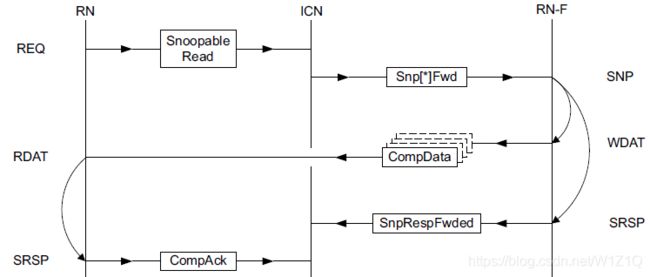
图2 Snoopable Read DCT structure
2.1.1.3 Read transaction structure without Direct Data Transfer
除了DMT和DCT,读传输中,Requester所得到的数据可以由HN提供,传输结构如图3所示。同样的,Requester必须收到至少一个CompData packet后,才能发送CompAck。

图3 Snoopable Read structure without Direct Data Transfer
2.1.2 ReadNosnp,ReadOnce*
为什么将ReadNoSnp和ReadOnce放在一起说呢?我猜是因为它们两者都有可选的保序需求和可选的CompAck;如果ReadNoSnp和ReadOnce要求具有保序功能,那么HN必须确保当前保序transaction对于后续的保序transactions是可见的;如果ReadNoSnp和ReadOnce将ExpCompAck置位,即使用CompAck,那么这它们将支持DMT和分离的Comp与Data响应;
ReadNoSnp传输不会去snoop其它master,只是简单的执行读传输流程,它所获得的数据可以直接来自SN,也可以来自ICN;
ReadOnce传输需要去snoop其它master,但是Requester不会缓存该数据,同样它所获得的数据可以直接来自SN,也可以来自ICN;
2.1.2.1 ReadNoSnp and ReadOnce* structure with DMT
ReadNoSnp和ReadOnce使用DMT传输如图4所示,如果Requester置起order域,那么HN必须通过CRSP通道返回ReadReceipt,表示保序已经在HN上建立;如果HN往SN发送ReadNoSnp操作时置起order域,那么SN也需要返回ReadReceipt表示该笔transaction已经接收,不会被Retry了。

图4 ReadNoSnp and ReadOnce DMT structure
使用DMT的ReadNoSnp和ReadOnce命令在HN上的生命周期可以通过SN发送的ReadReceipt来缩短,即HN收到ReadReceipt后,就可以提前释放这些命令的资源,不需要等到后续的CompAck。具体ReadNoSnp/ReadOnce与DMT、ReadReceipt、CompAck、order域段之间的关系在下面有专题论述。
2.1.2.2 ReadOnce* structure with DCT
ReadNoSnp不需要snoop transaction,所以就没有DCT说法了。对于ReadOnce的DCT传输如图5所示,DCT传输需要被snoop的RN返回response表示当前DCT是否成功进行。

图5 ReadOnce DCT structure
2.1.2.3 ReadNoSnp and ReadOnce* structure without Direct Data transfer
ReaNoSnp和ReadOnce*没有数据传输如图6所示。Request/Response必须遵循如下原则:
- ReadReceipt必须在相应的请求接收后才能发送,返回ReadReceipt和CompData之间的顺序无要求;
- CompData必须在响应的请求接收后才能发送;
- CompAck必须在requester接收至少一个CompData packet之后才能发送,Requester发送CompAck可以不需要等待ReadReceipt,Completer发送ReadReceipt不能等待CompAck;
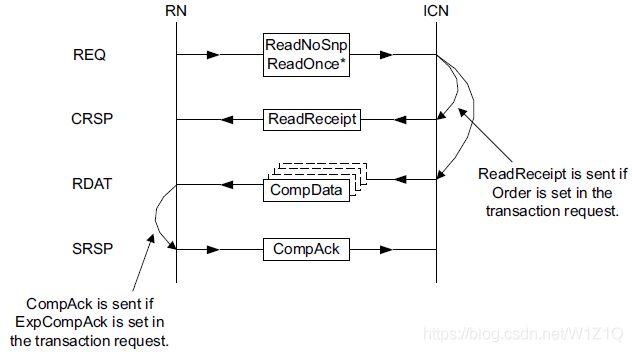
图6 ReadNoSnp and ReadOnce* structure without Direct Data Transfer
下表2列出DMT和DCT与order域、CompAck不同组合后对ReadNoSnp和ReadOnce的影响。
表2 Permitted DMT and DCT for ReadNoSnp and ReadOnce from an RN
| Order[1:0] | ExpCompAck | DMT | DCT | Notes |
|---|---|---|---|---|
| 00 | 0 | Y | Y | 不需要通知HN该transaction是否结束;对于DMT,HN必须获得ReadReceipt响应,确保SN不会Retry该transaction |
| 1 | Y | Y | 不需要通知HN该transaction是否结束;对于DMT,HN可以通过SN的ReadReceipt或RN的CompAck知道该transaction是否被retry | |
| 01 | – | – | – | Not permitted |
| 10/11 | 0 | N | Y | 对于DCT,HN通过SnpRespFwded或SnpRespDataFwded响应来决定该transaction的结束 |
| 1 | Y | Y | 对于DMT,HN使用CompAck来决定该transaction结束;对于DCT,HN使用SnpRespFwd或SnpRespDataFwd响应来决定改transaction结束 |
2.1.2.4 Read with separate Non-data and Data-only responses
从issueC开始,对于所有的读类型transaction,CHI支持分离的来自HN的non-data response和来自HN或SN的Data-only response;该特性在以下transactions不支持:
- Atomic transactions
- Exclusive transactions
- Ordered ReadNoSnp and ReadOnce* transactions without CompAck
分离的Non-data和Data-only响应有以下两种方式:
- comp来自HN,Data来自SN,如图7所示:

图7 Comp from Home and Data from Slave - comp和data都来自HN,如图8所示:
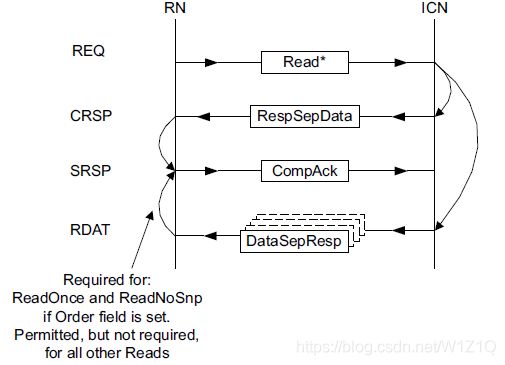
图8 Comp and Data from Home
注:对于非保序的带CompAck的ReadOnce*和ReadNoSnp命令,requester发送CompAck不需要等待DataSepResp。
在分离comp和data响应中,Request和Response需要遵循如下原则:
- DataSepResp和RespSepData必须在completer接收到相应的请求后才能发送,RespSepData只能由HN发送,DataSepResp可以由SN或HN发送;
- 在ReadNoSnp和ReadOnce*中,对于无保序的请求,CompAck可以不等待data返回就发送,对于有保序的请求,CompAck必须等待data返回后才发送;
- Completer不能等待收到CompAck后才发送Data Packets;
- ReadNoSnoSep必须在HN收到所有的Snoop响应后,由HN发往SN;SN在收到ReadNoSnpSep后,必须返回Readreceipt,表明该笔transaction不会被retry;
- SN不能呢发送分离的comp响应给HN,对于保序的ReadOnce*和ReadNoSnp请求,HN通过收到CompAck可以知道该transaction已经结束;
- 对于保序的ReadOnce和ReadNoSnp命令,如果采用分离的Comp和Data响应,HN不能发送ReadReceipt响应给requester,因为HN发送的RespSepData响应已经蕴含了ReadReceipt;
在所有可以使用分离回data和comp响应的地方,也都可以使用CompData响应;
对于ReadNoSnp和ReadOnce操作,不同的order值、ExpCompAck值,可以使用分离Non-data与Data-only响应和CompData响应的具体细则可以参考issueC文档中表2-7,这里不细述。
2.2 Dataless Transactions
对于Dataless操作,主要用于以下功能:
- 获取对cache的写权限(CleanUnique/MakeUnique);
- cache维护(CMO:CleanShared/CleanSharedPersist/CleanInvalid/Makeinvalid);
- 更新snoop fliter的状态(Evict);
- 将数据移到更接近的地方,方便可预见的将来使用(StashOnceUnique/StashOnceShared);
对于Dataless传输的流程如下图所示9,从RN视角:
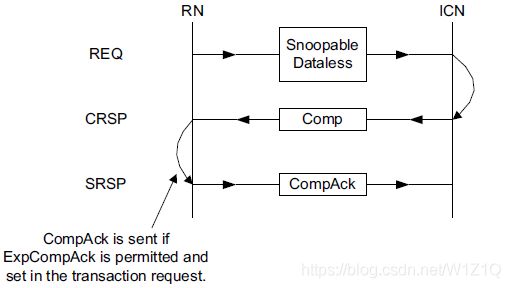
图9 Snoopable Dataless transaction structure
对Request/Response的约束如下: - Completer必须在收到响应的请求后,才能发送Comp;
- Requester必须在收到响应的Comp后,才能发送CompAck;
- 不是所有的Dataless操作都需要CompAck响应,只有CleanUnique/MakeUnique才需要置起ExpCompAck,其余Dataless命令不需要置起ExpCompAck。**
这个问题得想想???**
2.3 Write Transactions
2.3.1 WriteNoSnp*
当对某个地址进行写操作,且不需要监听其它master是否有该地址的数据时,可以用WriteNoSnp命令;
对于WriteNoSnp命令,completer可以返回CompDBID,也可以将Comp和DBID分开返回;Comp表示该transaction可以被其它Requester观察到,DBID表示该Completer有足够data buffer接收写数据;传输结构如图10所示。
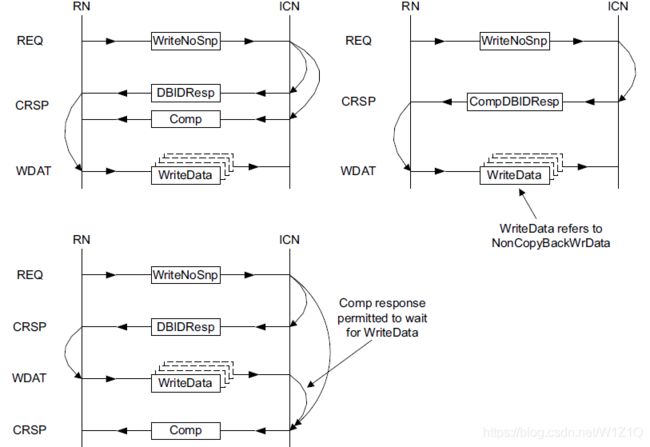
图10 WriteNoSnp* transaction structure options
对于Request/Response需要遵循的原则如下:
- 分离的DBID和Comp,或者CompDBID都必须在Completer收到相应的请求后,才能由Completer发送;
- Reuqester只有在收到CompDBID或DBIDResp后,才能发送写数据;
- 如果Comp和DBID分开发送,Requester等到DBIDResp后,就需要发送写数据,不能等到Comp之后才发送;DBIDResp和Comp对于Requester的接收和Completer的发送都是in any order;
- Completer允许在收到WriteData后才发送Comp响应;
2.3.2 WriteUnique*
当对某个地址进行写操作,且需要监听其它master时,可以使用WriteUnique命令;WriteUnique操作的传输结果如图11所示,从RN视角。WriteUnique命令也可以使用分离的Comp和DBID响应,或CompDBID响应,作用和WriteNoSnp一样;如果ExpCompAck域段置位,那么WriteUnique需要发送CompAck来结束命令,从issueC开始,有一个取巧方式是CompAck和Data可以组合为NCBWrDataCompAck一块发送,省的发两次。

图11 WriteUnique transaction structure options
对于Request/Response的约束和2.3.1节基本一样,不同点有两个:1. WriteUnique操作中,Completer不能等待WriteData后再发送Comp,我才猜想如果这样做会有死锁风险,比如说Data是以NCBWrDataCompAck的形式返回的话,Requester会等待Completer发送Comp,而Completer会等待Requester发送Data,造成互相等待死锁;2. Requester必须在收到Comp或CompDBIDResp后才能发送CompAck;
2.3.3 CopyBack(WriteBack*/WriteCleanFull/WriteEvitFull)
除了WriteEvictFull命令,CopyBack操作通常用于更新主存或下游cache,WriteEvictFull单单用于更新下游cache,该命令产生的效果不会超过它的snoop domain;CopyBack操作流程如图12所示。CopyBack命令有两个注意点:1. Comp和DBID必须一块返回,即为CompDBIDResp;2. Requester收到CompDBIDResp后,表明Completer可以接收该命令的,而且在该命令结束前,不会接收到同地址的snoop命令。
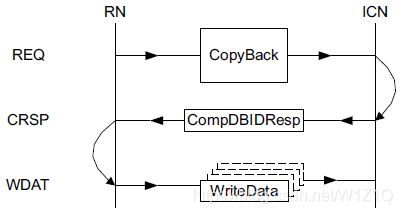
图12 CopyBack transaction structure
2.4 Atomic Transactions
Atomic操作可以分为两类:
- 一类是返回只有completion响应,有:AtomicStore;
- 一类是返回有completion和Data响应,有:AtomicLoad/AtomicSwap/AtomicCompare;
Atomic传输结果如图13所示:
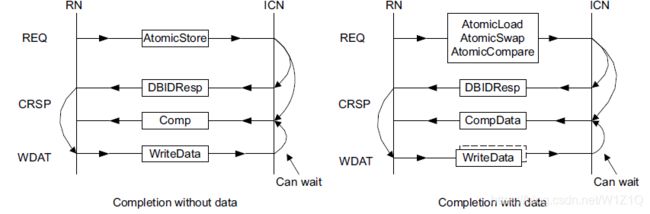
图13 Atomic transaction structure - 对于AtomicStore操作,允许Completer分开返回DBID和Comp响应,或组合的CompDBID;对于AtomicLoad/AtomicSwap/AtomicCompare操作,Completer只能返回DBIDResp,Comp是通过CompData返回的;
- 在分离的Comp和DBIDResp中,Completer不能等待收到Data后才发送DBIDResp,但是允许等到Data之后再发送Comp,如果这样做的话,就可以使用Comp来传递原子操作结果或数据接收是否有错误;
- 在CompDBID中,Completer不能等待收到Data之后才发送CompDBID响应;Requester在收到DBIDResp活CompDBIDResp之后,就可以发送Data,不能等CompData或Comp响应;
- Completer在返回read data时可以采用两种方式:1. 在收到命令之后的任何节点返回Read data;2. 直到收到所有的write data之后再返回read data;
Atomic操作的self-snoop:
在Atomic操作中,CHI协议允许Requester对自己进行self-snooping,如果SnoopMe域段置位,则允许self-snooping。通常RN在发送Atomic操作之前无法失效掉自己的cacheline的话,则需要self-snooping:1. 失效掉自己的cache line拷贝,2. 如果cache line时Dirty,则获取一份拷贝;
HN收到SnoopMe置位的Atomic操作时,如果Requester里该cache line有数据,则必须发送snoop请求,反之可以不需要;如果SnoopMe为0,则不能发送snoop给Requester;HN发送给Requester的snoop命令可以是SnpUnique或SnpCleanInvalid;
注意:如果Atomic命令的SnoopMe置位,则RN可以发送同时并行发送同地址的CopyBack命令和Atomic操作,不需要等待同地址的其中某个操作完成后再发送下一个。
2.5 Other Transactions
2.5.1 DVM transaction
DVM是Distributed Virtual Memory的缩写,DVM传输流程如图14所示;Request/Response需要遵循如下原则:
- Completer必须收到相应的请求命令后才能发送DBIDResp;
- Requester必须收到DBIDResp之后才能发送WriteData;
- Completer必须收到Data后才能发送Comp响应;

图14 DVM transaction structure
2.5.2 Prefetch transaction
PrefetchTgt是由RN直接发到SN,SN收到该命令可以采用两种做法:1. 去主存取数据,并将数据缓存起来,等待接下来同地址的读请求;2. 直接将命令丢弃掉,不做任何处理。传输流程如图15所示:
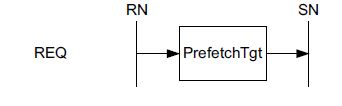
图15 PrefetchTgt transaction structure
对于Request/Response需要遵循如下原则:
- Requester在发送完PrefetchTgt命令后,马上释放资源;
- SN不会讲PrefetTgt命令retry;
- SN可以将PrefetchTgt命令扔掉,不采取任何进一步措施;
2.6 Transaction Retry sequence
除了PCrdReturn和PrefetchTgt命令,其它request命令都可以被retry。Request命令第一次发送时是不带Protocol Credit(P-Credit),如果该命令不能被Completer接收,Completer必须发送RetryAck响应表明暂时无法接收该命令,等到有合适的Credit后再发。当Completer可以接收的话,再发送PCrdGrant响应给Requester。此时CHI协议允许被retry的命令是否要重发,因此有两种情况需要讨论。下面分别阐述:
2.6.1 Retry sequence
如果需要重发的话,则必须携带PCrdGrant的Credit,确保命令肯定能被接收,传输结构如图16所示。
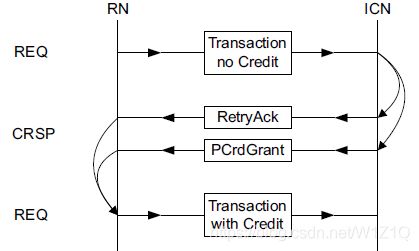
图16 Transaction Retry sequence
对于retry的transaction有以下约束:
- Completer必须收到相应的请求命令后才能发送RetryAck;
- Completer必须收到相应的请求命令后才能发送PCrdGrant;
- Completer发送和Requester接收的RetryAck和PCrdGrant之间的顺序没有要求;
- Requester必须收到RetryAck和PCrdGrant之后,才能重新发送带Credit的transaction;
2.6.2 Not retrying a transaction
如果Requester在收到RetryAck和PCrdGrant后,并不想重新发送transaction,可以使用PCrdReturn命令将P-Credit返回给Completer,这样相当于发了一笔空操作,传输结构如图17所示。
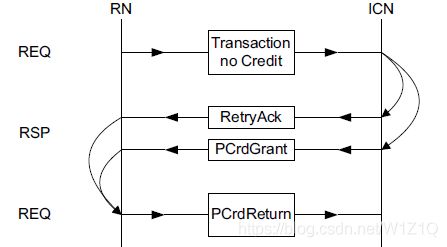
图17 Cancelled transaction sequence
2.7 Snoop Transactions
Snoop操作是由HN发给RN的transaction:
- 如果是RN-F需要接收所有的Snoop transaction;
- 如果是RN-D要只接收SnpDVMOp transaction;
- RN-F和RN-D在收到snoop request(除了DVMOp Sync)时,必须要及时返回snoop响应,不能和其它oustanding requests有任何的完成依赖关系。
snoop transaction的传输结构有以下几种: - Snoop with response to Home
- Snoop with Data to Home
- Snoop with Data return to Requester and response to Home
- Snoop with Data return to Requester and Data to Home
- Snoop DVM operation and response to Misc Node
snoop transaction也可以用于stash数据在Snoopee处,Stash类型的snoop transaction有以下几种: - Stashing snoop with Data from Home
- Stashing snoop with Data using DMT
下面将对各个Snoop transaction进行阐述。
2.7.1 Snoop with response without Data to Home
该传输结构如图18所示,RN必须在收到相应的Snoop请求后才能发送SnpResp响应。
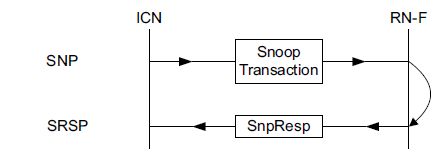
图18 Snoop transaction structure with response to Home
2.7.2 Snoop with response with Data to Home
该传输流程如图19所示,只有如下几种snoop请求才能有data响应:
- SnpOnceFwd,SnpOnce
- SnpCleanFwd,SnpClean
- SnpNotSharedDirty,SnpNotSharedDirty
- SnpSharedFwd,SnpShared
- SnpUniqueFwd,SnpUnique
- SnpCleanShared
- SnpCleanInvalid
RN可以通过SnpRespData和SnpRespDataPtl响应返回数据,同样的SnpRespData*只有在RN收到相应的snoop请求后才能发送;
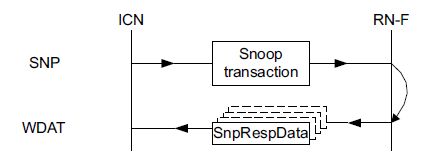
图19 Snoop transaction structure with data to Home
2.7.3 Snoop with Data forwarded to Requester without or with Data to Home
该传输流程如图20和21所示,forward data的snoop请求有如下几种:
- SnpOnceFwd
- SnpCleanFwd
- SnpNotSharedDirtyFwd
- SnpSharedFwd
- SnpUniqueFwd
被Snoop的RN如果要forward数据给Requester,通过CompData opcode,走WDAT通道,因为forward是DCT传输,被snoop RN需要通知HN是否DCT成功,如果被snoop RN单单只回响应,则通过SRSP通道和SnpRespFwded opcode告知HN,如果被snoop RN要把数据和响应都要回,则通过WDAT通道和SnpRespDataFwded opcode告知HN。

图20 Snoop with data forwarded to Requester
with response to Home
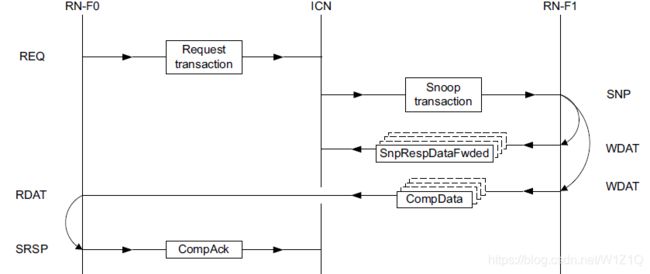
图21 Snoop with Data forwarded to Requester with Data to Home
对于forward snoop请求的request/response需要遵循如下规则: - 被snoop RN只有在收到相应的snoop请求后,才能发送SnpRespFwded或SnpRespDataFwded响应,CompData同理;
- 被snoop的RN发SnpRespDataFwded或SnpRespFwded和CompData可以为任何顺序;
- Requester只有收到Data的第一笔数据后,才能发送CompAck;
2.7.4 Snoop DVMOp
SnpDVMOp传输结构如图22所示,ICN需要发送两个opcode为SnpDVMOp的snoop request,被snoop的RN需要接收到两个snoop请求后,才能发送SnpResp响应;
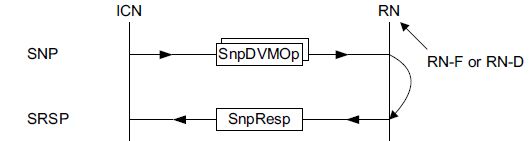
图22 SnpDVMOp transaction structure
2.7.5 Stash snoops
Stash snoops传输的结构情况较多,图23和24分别给出了两种情况:
图23是带Data Pull的响应,因此HN需要发送Data给被snoop RN;
Data Pull指的是SnpResp响应中蕴涵读操作,即相当于既回了snoop响应,也发了一笔读操作;

图23 Stash type snoop with Data Pull,Data response from Snoopee,and Data from Home
图24也是带Data Pull的响应,但是被snoop RN回的响应不带数据,且HN采用DMT传输给被snoop RN提供数据;
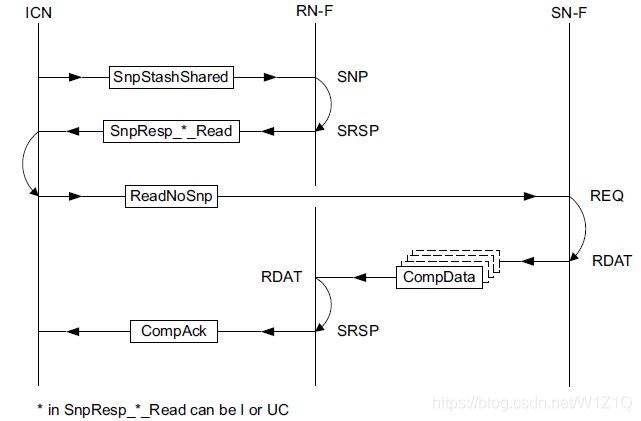
图24 Stash type snoop with Data Pull,no Data response from Snoopee,and DMT
三、传输响应类型
除了PrefetchTgt,每一笔request transaction都会产生一个或多个响应,有一些响应可能还带有数据,对于响应类型可以按如:
3.1 Completion response
除了PCrdRetrun和PrefetchTgt,其它request transaction都需要(completion response)完成响应。完成响应通常是由Completer发送的,是传输的最后一笔message,用于结束一笔request transaction。然而,对于Requester可能仍然需要发送CompAck响应来结束该笔transaction。完成响应保证request transaction已经到达PoS或PoC点,它们会对系统中其它requester发送的同地址requests进行保序。
3.1.1 Read and Atomic transaction completion
Read transactions完成信号要么来自CompData,要不分离响应RespSepData和DataSepResp。AtomicLoad、AtomicSwap、AtomicCompare的完成信号来自CompData。
CompData和DataSepResp完成信号的Resp域包含了如下信息:
- Cache state:the final permitted state of the cache line at the Requester for all reads except ReadNoSnp and ReadOnce*.
- Pass Dirty:Indicates if the responsibility for updating memory is passed to the Requester. The assertion of the PassDirty bit is shown by _PD in the response name.
当使用分离的Comp和Data响应时,RespSepData响应中也有包含带有cache state和pass dirty的Resp域,RespSepData的Resp域要么不用设置为0,要么必须要和DataSepResp的Resp域一样;
如果完成响应含有error indication,那么cache state可以为任意值。
3.1.2 Dataless transaction completion
Dataless transaction完成响应是来自Comp,在Comp响应的Resp域包含了如下信息:
- Cache state:The final state the cache line is permitted to be in at the Requester,except for CMO transaction. For CMO transactions,the cache state field value is ignored and the cache state remains unchanged.
- Pass Dirty:Dateless transactions do not pass responsibility for a Dirty cache line.
如果完成响应含有error indication,那么cache state可以为任意值。
3.1.3 Write and Atomic transaction completion
Write and AtomicStore完成响应是来自Comp或CompDBID。对于write transaction没有传递cache state和pass dirty信息,在Comp和CompDBIDResp响应中的Resp域必须全部设置为0,所有的cache state和Pass dirty信息使用WriteData传递的。允许的Write transaction有:
- Comp:用于分离的Comp和DBIDResp返回响应;
- CompDBIDResp:用于组合完成响应,Non-CopyBack writes和AtomicStore可以分开Comp和DBIDResp响应返回,也可以组合CompDBIDResp响应返回。对于CopyBack writes只能组合CompDBIDResp响应返回。
3.1.4 Miscellaneous transaction completion
对于DVM transaction的完成响应Comp的Resp域必须设置为0。
3.2 WriteData response
WriteData response是Write request和DVMOp transactions的一部分。Requester在收到DBIDResp响应后就可以将WriteData发往Completer。WriteData response是通过WDAT通道传输的,有以下几种opcodes:
- CopyBackWrData:1. 用于CopyBack transactions;2. 传输一致性数据从RN的cache到ICN;3. 包含WriteData响应发送之前的cache line状态信息。
- NonCopyBackWrData:1. 用于WriteUnique和WriteNoSnp transactions;2. 用于DVMOp transaction;3. 响应中的cache state必须是I态。
- NCBWrDataCompAck:1. 用于WriteUnique transactions;2. 组合NonCopyBackWrData和CompAck;3. 响应中的cache state必须是I态。
WriteData响应中的Resp域包含如下信息:
- Cache state:指示在WriteData响应发送之前的cache line状态信息。这个状态信息不同于Requester最开始发送request时的cacheline状态信息,因为在发送request和发送WriteData之间可能会收到同地址的snoop请求,snoop请求可能会将cache line状态改变;
- Pass Dirty:指示Requester是否将pass dirty传递给其它人,Pass Dirty bit置位的话在响应名字上会带有_PD;
在write transaction完成后,Requester的cache line状态信息不是由WriteData响应中cache state信息决定的,而是由transaction opcode决定transaction完成后cache line是否有效或无效:
- WriteBack或WriteEvictFull transaction必须是I态;
- WriteCleanFull transaction可以保持clean态;
如果WriteData的RespErr域指示有data error,WriteData响应的cache line状态可以为任意值。
Requester在发送WriteUniquePtl、WriteUniquePtlStash、WriteNoSnpPtl之后,Requester可以选择取消transaction的进行,data响应WriteDataCancel用于通知HN该笔写已经被取消了。
WriteDataCancel响应规则如下:
- 只能用于WriteUniquePtl、WriteUniquePtlStash和WriteNoSnpPtl transaction;
- 不能用于Device memory type的WriteNoSnp transaction;
- 所有原先打算传送的data packets必须发送;
- WriteNoSnpPtl transaction不管是发送取消还是非取消的数据,都必须等到DBIDResp,不能等Comp;
- WriteUniquePtl和WriteUniquePtlStash transactions不管是发送取消还是非取消的数据,都必须等到DBIDResp,不能等Comp;
- 对external interfaces可见的WriteDataCancel message必须将BE和Data域的值设置为0。External interfaces包括:1. External RN to ICN;2. ICN to an external SN。
3.3 Snoop response
Snoop transaction包括snoop response,snoop response可以带或不带data。snoop response的Resp域包含如下信息:
- Cache state:the final state of the cache line at the snooped node after sending the Snoop response.
- Pass Dirty:Indicates that theresponsibility for updating memory is passed to the Requester or ICN. Pass Dirty must only be asserted for a Snoop response with data. The assertion of the Pass Dirty bit is shown by _PD in the response name.
snoop response也包含FwdState域的信息,该域用于DCT传输,用于指示DCT传送给Requester的CompData中的cache state和pass dirty信息,即等于CompData的Resp域的值;
即时RespErr域指示有个错误,Snoop response with data上cache line state也必须是合法的值,但如果是snoop response without data就可以为任意值。
3.4 Miscellaneous response
本节描述一些没法归类到Completion、WriteData、Snoop response的responses,本节的所有responses的Resp和RespErr域没有任何意义且必须设置为0。包含这些response:
- CompAck:1. Requester收到完成响应之后就可以发送;2. 用于Read、Dataless、WriteUnique transactions;
- RetryAck:1. 用于Completer在缺乏资源来接收request时,发送给Requester;2. 除了PCrdReturn和PrefetchTgt,其余request都可以被Retry;
- PCrdGrant:传递P-Credit,Requester收到后可以发送被Retry的命令;
- ReadReceipt:1. HN对要求Order的命令返回的保序保证;2. SN发送ReadReceipt表示它已经接收read request,不会发送RetryAck响应;3.只用于ReadNoSnp、ReadNoSnpSep、ReadOnce* request transactions;
- DBIDResp:用于Write和Atomic transaction,告知Request在Completer有足够的资源来接收WriteData响应;
四、Cache state transitions
本节描述cache状态悄悄转换和各个request transaction的cache状态切换和完成响应(completion responses)。
4.1 Silence cache state transitions
由于内部事件,cache可以悄悄转换而不通知系统中的其它masters;表4为合法的silent cache state transaction。在一些情况下,RN可能但不是必须发送一笔transaction表明cache state转换已经发生。如果RN发送了这样的一笔transaction,并且cache state转换对ICN可见,那么这种情况就不能归为silent transition。
对于表4中描述的RN-F local sharing是RN-F将Unique态改写成Shared态,这种场景在一个RN-F内有多个interna agents,cache line在它们之间变成shared时会发生。
对于silent cache state transaction:
- Cache eviction和Local sharing transitions在任何point都可以发生,由具体实现决定;
- Store和Cache Invalidate transitions只能是有意为之,在core执行特定的程序指令时发生;
表4 Legal silent cache state transitions,Notes那一栏表示如何在interface上将silent cache transitions转换为non-silent or visible转换。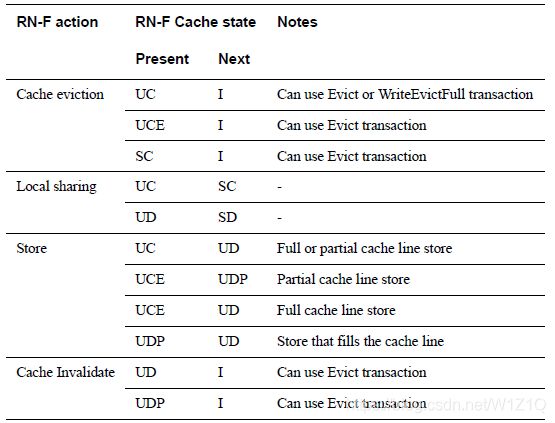
注意:
1、cache state不能从UC变为UCE;
2、一系列silent transitions也可能发生,比如说从UC经过Local Sharing变成UD,但又经过cache Invalidate变成I态等一串silent操作。
4.2 Read request transactions
表5为在Requester上的读请求的cache state transitions和completion response。
不管原始request是什么,SN发往Requester的Data response的cache state通常是UC。对于ReadNoSnp、ReadOnce*的CompData Response,Requester必须忽略cache state,因为这些操作的cache state隐含为I态。
在non-DMT data transfer,SN发往HN的CompData的cache state可以是I或UC态,但是期望SN可简化设计为总是使用UC,HN使用合适的cache state值CompData给Requester。


注意:
1、表5中的Other Permitted initial cahce state是在transaction传输过程中允许的cache state;
2、表5中的任何transaction,如果cache line可以silently transition到any Expected或Other Permitted state,那也可以正常发送这些transaction,但这些silent transitions必须在transaction发送之前就应该发生;
3、如果cache state为UD或SD,来自memory的data必须扔掉;如果是UDP,那必须merge;如果是SC或UC,来自memory的data必须和cached data一样。
4.3 Dataless request transactions
表6为在Requester的Dataless request所对应的cache state transitions和completion responses。
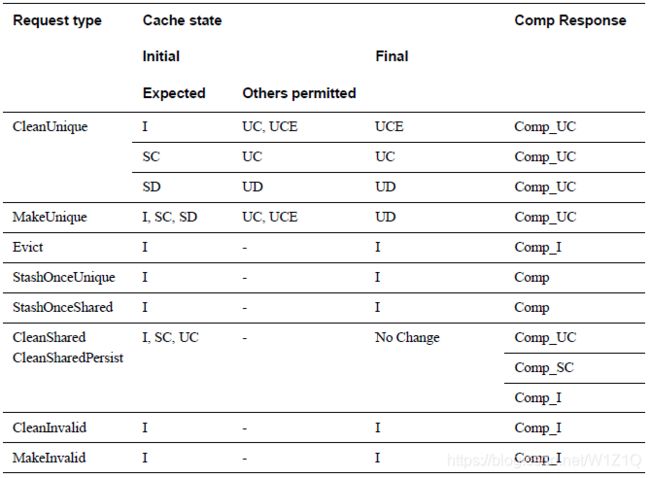
注意:
1、在CleanInvalid、MakeInvalid、Evict transaction之前,允许cache state是UC、UCE或SC。但是在transaction要发送时,cache state必须转换到I态,因此这三个命令的initial state只能是I态;
2、表6中的Other Permitted initial cahce state是在transaction传输过程中允许的cache state;
2、表6中的任何transaction,如果cache line可以silently transition到any Expected或Other Permitted state,那也可以正常发送这些transaction,但这些silent transitions必须在transaction发送之前就应该发生;
4.4 Write request transactions
表7为在Requester处Write和WriteBack request transactios所对应的的cache state transitions、Write data response和组合或分离的Completion和DBID响应。

注意:在WriteClean transaction完成后,Unique state的cache line可能会马上转变到Dirty state。
4.5 Atomic transactions
表8为在Requester处的Atomic操作所对应的cache state transitions和Completion response。
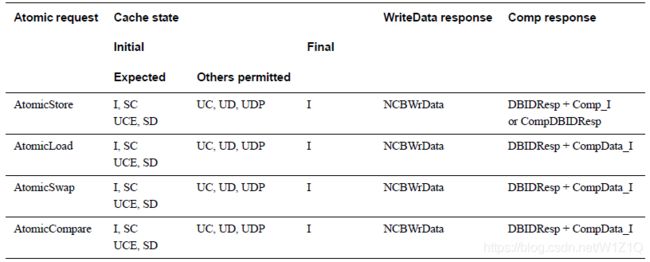
4.6 Other request transactions
DVMOp和PrefetchTgt requests没有任何的cache state transitions。
4.7 Snoop request transactions
对于Non-forward snoop request,响应只能是SnpResp或SnpRespData,在由多个可选的final cache state情况,response取决于具体实现;
RN处于UC态时,不需要返回snoop data response。除了SnpOnce,接收snoop response的Completer不能区分以下情况:
- RN在UC态没有返回带data的snoop response;
- 在收到snoop request之前,RN silent transition到SC或I态,因此snoop response不带data;
表10 Cache state,RetToSrc value,and valid completion responses
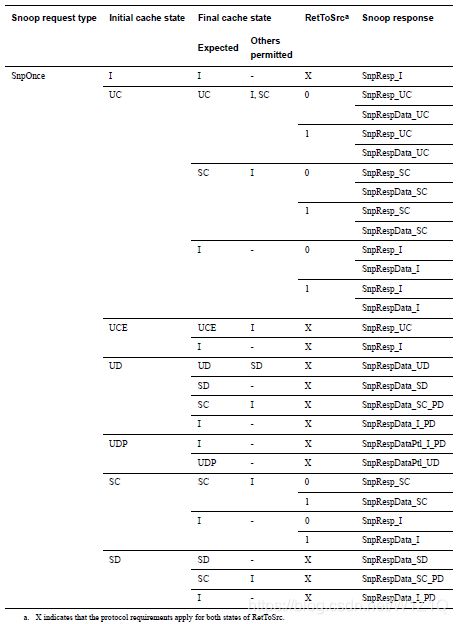
表11 Cache state transitions,RetToSrc value,and valid completion responses

表12 Cache state transaction,RetToSrc value,and valid completion responses
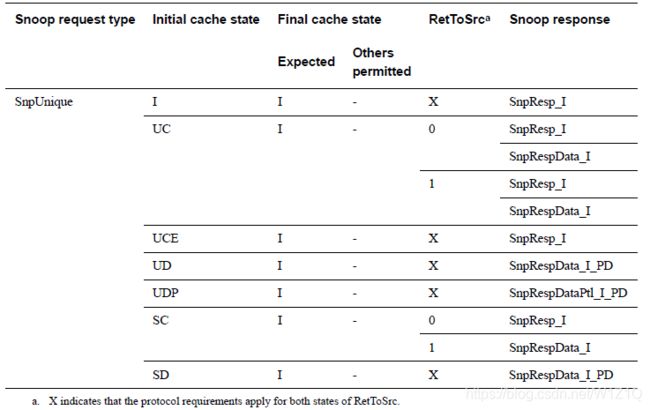
表13 Cache state transitions,RetToSrc value,and valid completion responses
4.8 Stash type snoops
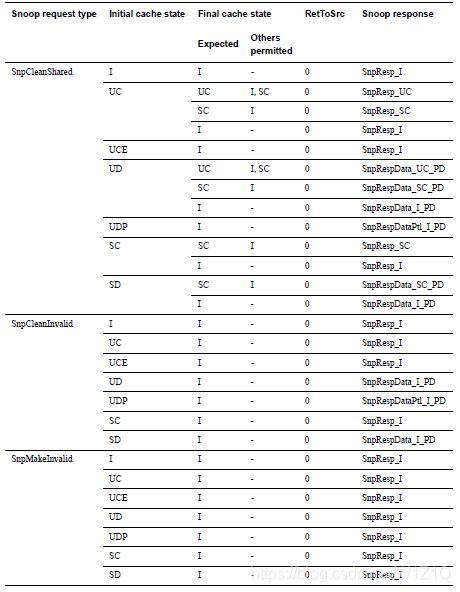
1、SnpUniqueStash and SnpMakeInvalidStash
SnpUniqueStash和SnpMakeInvalidStash的responses分别和SnpUnique和SnpMakeInvalid的responses一样。对于SnpUniqueStash和SnpMakeInvalidStash的RetToSrc必须设置为0;如果DoNotDataPull没有置位的话,snoop responses可以包含Data Pull。
表14 Snoop response to SnpUniqueStash and SnpMakeInvalidStash
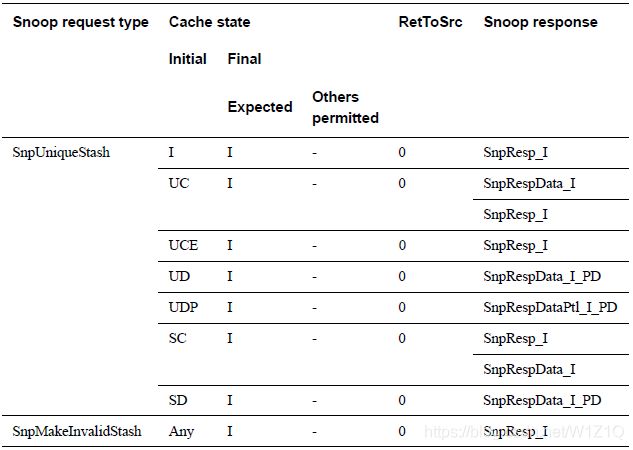
2、SnpStashUnique and SnpStashShared
Snoopee对于SnpStashUnique and SnpStashShared命令不会改变cache state。Snoopee允许不查找cache就返回response,在这种情况下snoop response必须是SnpResp_I。当然,Snoopee允许返回精确的cache state response;在response的cache state是精确的,且DoNotDataPull没有置位的情况下,snoop response可以包含Data Pull;在包含Data Pull的Snoop response中,必须确保initial state不会和相应的读的initial state有冲突。
表15 Snoop responses to SnpStashUnique
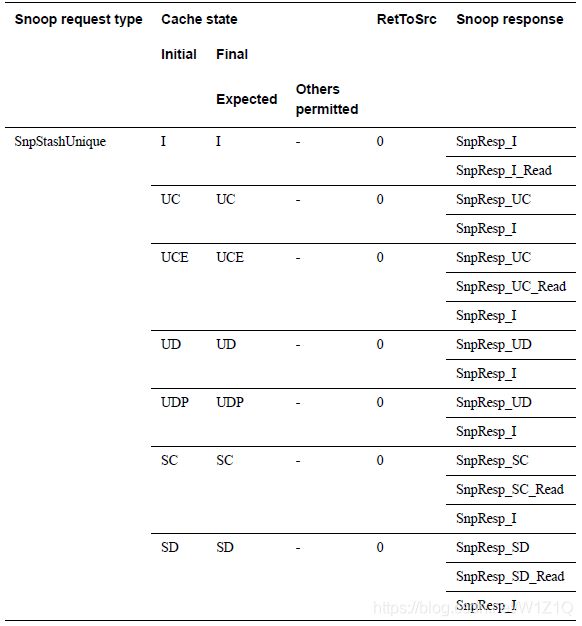
表16 Snoop response to SnpStashShared

4.9 Forwarding type snoops
Forwarding(Fwd) type snoop用于HN的DCT传输,对于所有在Snoopee的Fwd type snoops有如下规则:
- 如果是以下几种cache state,那必须forward data给requester:UD、UC、SD、SC;
- 不允许转化为相应的Non-Fwd typesnoop;
- 对于Non-invalidation type snoop,Unique state不能forward data;
- Snoopee收到DoNotGoTOSD置位的snoop请求,不能将cache state转为SD,即时一致性条件允许;
- 在一定条件下,包括Snoop type、the state of the cache line at the Snoopee,and the RetToSrc value in the Snoop request,Snoopee可以forward data给Request,也顺带发送一份数据给HN;
- HN在以下情况不能发送forwarding type snoop:1. Atomic transactions;2. Passing Exclusive read transactions;
以下分别阐述每种特定的Fwd typ snoop:
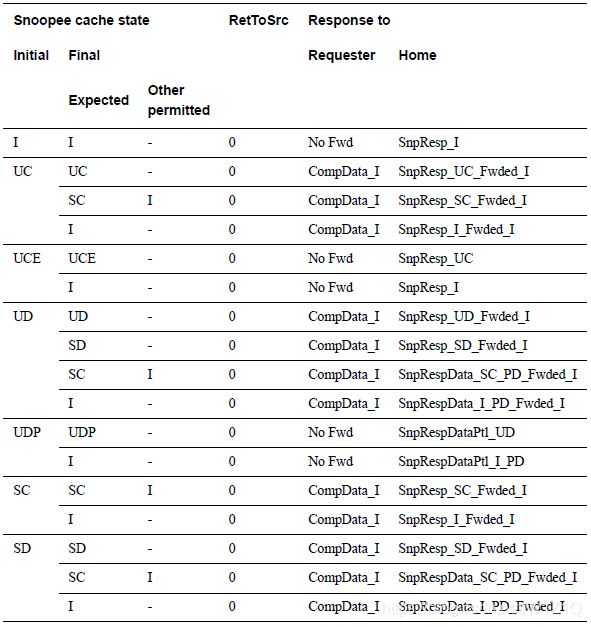
1、SnpOnceFwd
除了以上common rules,Snoopee在收到SnpOnceFwd时,需要遵循如下规则:
- Snoopee必须forward I态的cacheline,另外Snoopee不能Passdirty给Requester;
- 当Dirty state变为Clean或Invalid,Snoopee必须返回数据给HN;
- snoop的RetToSrc必须设置为0;
- Snoopee可以忽略DoNotGoTOSD的值;
表17 Snoop response to SnpOnceFwd
2、SnpCleanFwd
除了以上common rules,Snoopee在收到SnpCleanFwd时,需要遵循如下规则: - Snoopee必须forward SC态的cacheline;
- Snoopee必须将cache state转为SC、SD或I state;
表18 Snoop response to SnpCleanFwd
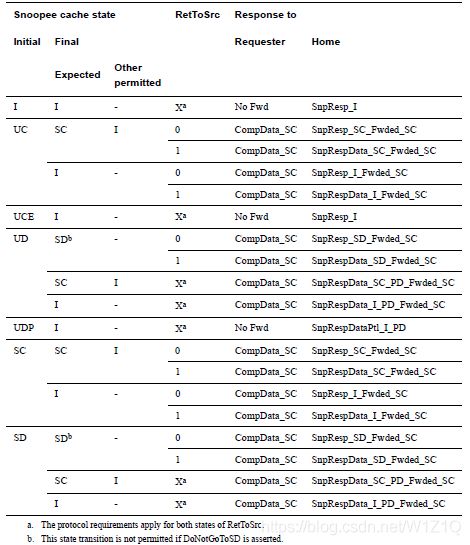
3、SnpNotSharedDirtyFwd
除了以上common rules,Snoopee在收到SnpNotSharedDirtyFwd时,需要遵循如下规则: - Snoopee必须forward SC态的cacheline;
- Snoopee必须将cache state转为SC、SD或I state;
表19 Snoop response to SnpNotSharedDirtyFwd
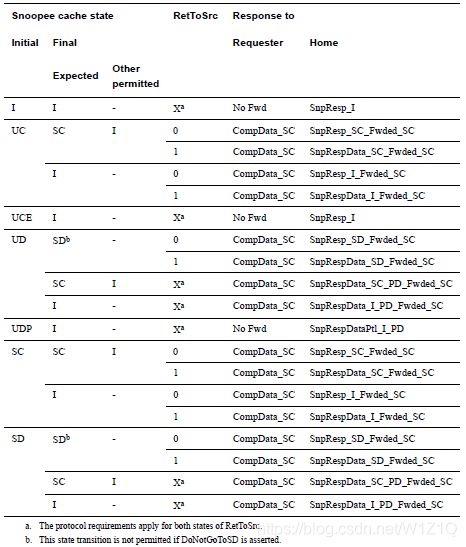
4、SnpSharedFwd
除了以上common rules,Snoopee在收到SnpSharedFwd时,需要遵循如下规则: - Snoopee必须forward SC态或SD态的cacheline;
- Snoopee必须将cache state转为SC、SD或I state;
表19 Snoop response to SnpSharedFwd
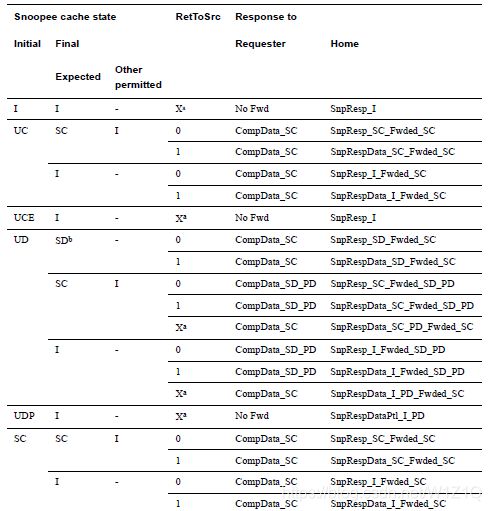
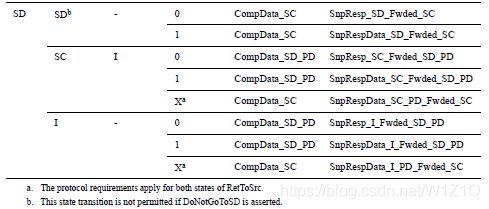
5、SnpUniqueFwd
如果cache被缓存在唯一一个RN-F中,才能允许使用SnpUniqueFwd snoop;如果HN决定invalidating snoop需要被送到唯一cache上,HN可以发送SnpUniqueFwd给处于Shared态的RN-F;
除了以上common rules,Snoopee在收到SnpUniqueFwd时,需要遵循如下规则: - Snoopee必须forward Unique态的cacheline;
- Requester上Dirty state的cacheline必须Pass dirty给Requester,而不是Home;
- Snoopee必须将cache state转为 I state;
- Snoopee不能返回数据给HN;
- snoop中的RetToSrc必须为0;
表20 Snoop response to SnpUniqueFwd


4.10 Shared clean state return
Snoop request中的RetToSrc域段用于指示Snoopee是否需要返回一份cacheline数据给HN,具体细则如下:
1、如果RetToSrc域值为1:
- 对于Forwarding snoop:如果cacheline是Dirty或Clean,Snoopee必须返回一份cacheline数据;
- 对于Non-forwarding snoops SnpOnce、SnpClean、SnpNotSharedDirty、SnpShared、SnpUnique:1. 对于SC态,必须返回一份数据给HN;2. 对于UD、UDP和SD态,必须发返回一份数据给HN;3. 对于UC态,可选是否返回一份数据给HN;
2、如果RetToSrc域值为0:
- 对于Forwarding snoop:1. 除了Snoopee的更新memory责任被pass给HN,或者Snoopee拥有UDP的cacheline且不愿意放弃这种状态,其余情况都不能返回数据给HN;
- 对于Non-fowarding snoops SnpOnce、SnpClean、SnpNotSharedDirty、SnpShared、SnpUnique:1. 对于SC态,不能返回数据给HN;对于UD、UDP和SD态,必须返回数据给HN;3. 对于UC态,可选是否返回一份数据给HN;
在以下snoop requests,RetToSrc域值必须设置为0,因为这些snoops在clean态下不会返回数据:SnpStashUnique、SnpStashShared、SnpUniqueStash、SnpCleanShared、SnpCleanInvalid、SnpMakeInvalid、SnpMakeInvalidStash;
在婴喜爱几种Forwarding snoops中,RetToSrc域值必须设置为0:SnpOnceFwd、SnpUniqueFwd;
HN发送的Snoop requests中只能给一个RN设置RetToSrc为非0。