zabbix监控第一篇---基础使用
zabbix监控系统第一篇---安装和简单使用
在本文中主要讲一下目前比较流行的zabbix监控系统的安装和使用,实验以最新的zabbix版本为准。
1. 监控系统简介:
业界常用的监控系统主要包括Nagios、cacti、zabbix。这三个监控各有自己的优点和缺点,主要总结如下:
Nagios是一款开源的免费网络监视工具,能有效监控Windows、Linux和Unix的主机状态,交换机路由器等网络设备,打印机等。在系统或服务状态异常时发出邮件或短信报警第一时间通知网站运维人员,在状态恢复后发出正常的邮件或短信通知。Nagios可运行在Linux/Unix平台之上,同时提供一个可选的基于浏览器的WEB界面以方便系统管理人员查看网络状态,各种系统问题,以及日志等等
Cacti 是一个用 rrdtool 来画图的网络监控系统, 通常一说到网络管理, 大家首先想到的经常是 mrtg, 但是 mrtg 画的图比较简单而且且难看, rrdtool 虽然画图本领一流, 画出来的图也漂亮, 但是毕竟是一个画图工具, 不像 mrtg 那样本身还集成了数据收集功能. Cacti 则是集成了各种数据收集功能,然后用 rrdtool 画出监控图形. 其本身界面比起同类系统要漂亮不少。Cacti 和 Nagios 是不同功用的系统, Nagios 适合监视大量服务器计算环境,重点并不在于图形化的监控, 其集成了很多功能,例如报警,都是 cacti 没有或者很弱的. Cacti 主要用途还是用来收集历史数据和画图, 所以界面比 Nagios 漂亮很多. 现在网上还有一种将cacti安装集成到一个操作系统里面,名字叫做cactiEZ,通过虚拟化安装操作cactiEZ系统之后,cactiEZ省去了复杂烦琐的Cacti配置过程,安装之后即可使用,全部中文化,界面更友好.
zabbix是一个高度集成的监控解决方案,可以实现企业级的开源分布式监控,通过C/S模式采集监控数据,再通过B/S模式实现Web管理. Zabbix监控服务器可以通过SNMP技术或Agent采集数据,数据可以写入MySQL、Oracle等数据库中,服务器使用LAMP实现web前端的管理;被监控的主机需要安装Agent,支持SNMP协议.
总结一下就是cacti画图比较好看,但是告警不怎么好,比较适合网络监控;nagios画图一般,但是插件比较多,特别是告警这块比较灵活。而zabbix就是集成了cacti和nagios两个的优点,画图和告警都不错,并且支持分布式的监控部署,可以安装zabbix-proxy,实现多个数据中心监控等。比较适合大型企业的运维监控;由于目前主流的还是zabbix监控系统,cacti和nagios都比较老了没多少企业在用,所以本文全部是针对zabbix来讲解运维监控系统的;
2. zabix监控系统安装:
zabbix安装需要使用到mysql数据库,需要先安装mysql数据。然后zabbix的安装我是参考官网上面最新的说明,直接使用yum安装的;
yum -y install mariadb mariadb-server
systemctl start mariadb
systemctl enable mariadb
mysql_secure_installation
CentOS7操作系统需要安装的mariadb数据库,安装之后需要配置密码
vi /etc/my.cnf
在[mysqld]标签下添加
init_connect='SET collation_connection = utf8_unicode_ci'
init_connect='SET NAMES utf8'
character-set-server=utf8
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
# 修改文件/etc/my.cnf.d/client.cnf
vi /etc/my.cnf.d/client.cnf
# 在[client]中添加如下内容
default-character-set=utf8
# 修改文件/etc/my.cnf.d/mysql-clients.cnf
vi /etc/my.cnf.d/mysql-clients.cnf
# 在[mysql]中下面增加
default-character-set=utf8
# 全部配置完成,重启mariadb
systemctl restart mariadb
# 之后进入MariaDB查看字符集
mysql -u root -p
MariaDB [(none)]> show variables like "%character%";show variables like "%collation%";安装完成mariadb数据库之后还需要配置字符集;
# 安装zabbix的yum源
rpm -Uvh https://repo.zabbix.com/zabbix/4.2/rhel/7/x86_64/zabbix-release-4.2-2.el7.noarch.rpm
yum clean all
# 安装zabbix-server zabbix-web zabbix-agent
yum -y install zabbix-server-mysql zabbix-web-mysql zabbix-agent
# 创建初始化的zabbix数据库,并赋权限
mysql> create database zabbix character set utf8 collate utf8_bin;
mysql> grant all privileges on zabbix.* to zabbix@localhost identified by 'password';
mysql> quit;
# 导入初始化数据
zcat /usr/share/doc/zabbix-server-mysql*/create.sql.gz | mysql -uzabbix -p zabbix
# 修改zabbix-server.conf的配置,配置数据库账户信息
DBPassword=password
# 修改php时区
vim /etc/httpd/conf.d/zabbix.conf
php_value date.timezone Asia/Shanghai
# 启动zabbix-server
systemctl restart zabbix-server zabbix-agent httpd
systemctl enable zabbix-server zabbix-agent httpd
# 通过管理页面初始化zabbix
http://server_ip_or_name/zabbix安装zabbix-server,并通过管理页面第一次登陆初始化zabbix-server,初始化过程在会检查php版本等配置,符合条件的话就可以进入下一步初始化zabbix
3. 实现第一台linux主机的基础资源监控:
登陆到zabbix监控系统看到默认已经监控了zabbix-server这台机器,现在我们再增加一台机器的监控,首先是在另外一台linux服务器上面安装zabbix-agent。

cd /etc/pki/rpm-gpg/
wget https://mirrors.aliyun.com/zabbix/RPM-GPG-KEY-ZABBIX-A14FE591
rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-ZABBIX-A14FE591
yum -y install zabbix-agent
# 修改zabbix-agent的配置文件
PidFile=/var/run/zabbix/zabbix_agentd.pid
LogFile=/var/log/zabbix/zabbix_agentd.log
LogFileSize=0
Server=10.83.32.129
ServerActive=10.83.32.129
Hostname=rainbondnode01
Include=/etc/zabbix/zabbix_agentd.d/*.conf
UnsafeUserParameters=1
# 重新启动zabbix-agent的服务
systemctl start zabbix-agent首先创建一个主机群组

创建完成群组之后,再创建主机
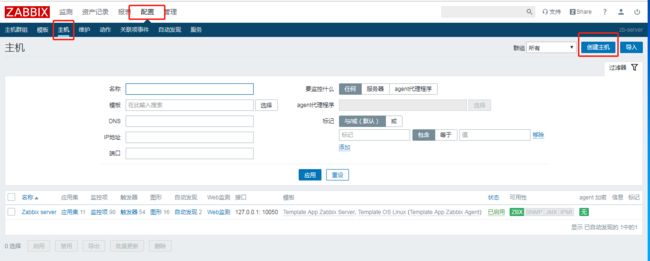

创建主机,分别配置主机的名称,agent的IP地址等,然后还要链接模板

什么是模板了?模板其实就是别人已经配置好的,包括Item、Triiger、Graphs、application、Discovery等。这些又是什么东西了,且容我慢慢道来;
-
Item: 主机监控的对象,比如主机的cpu利用率,这里cpu的利用率就可以成为一个item。比如我监控的一个服务也可以成为一个item,我们可以这样理解,我们说监控的东西就可以简单的被成为一个item;
-
Triiger: triiger被称为触发器,可以理解为促成警报的一个阀值,比如,当/目录的剩余空间只剩下百分之十时触发邮件或者短信告警,我们可以把这个条件做为一个triger。
- Graphs: 图表,我们监控一个设备时,有时候希望以更加直观的图表的形式显示出来的时候往往可以通过graphs来设置,比如我们监控的一个item对象是etho 网卡出口的流量和一个iteme etho网卡进口的流量, 并且我们想把eth0网卡进出流量以曲线图的形式显示出来的话往往就需要在graphs里面来设置
-
application: 应用,其实就是Item的组合;就是把相同类型的一组Item归类到一个应用里面,比如我们把CPU类的监控都放在一个叫做process的application里面;包括cpu使用率、cpu负载等;
- discovery: 自动发现,比如监控磁盘分区、网卡流量等,因为每个linux主机的磁盘分区可能不一样,网卡数量也会不一样。所以通过自动发现规则会实现根据监控的主机的特征,自动识别所有的操作系统分区和网卡实现监控;

如果客户端机器开启了防火墙,可能这里会显示红色的,需要增加10050端口的策略。zabbix服务器的端口是10051,zabbix客户端的端口是10050
iptables -I INPUT -p tcp --dport 10050 -j ACCEPT /sbin/iptables-save
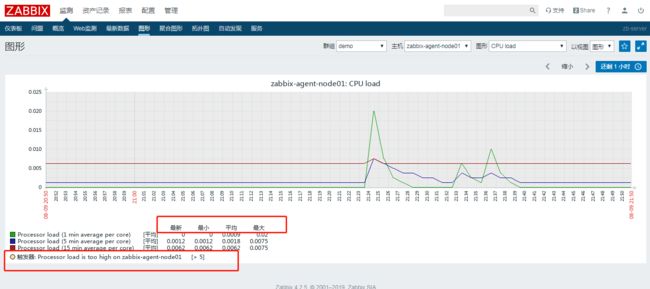
通过监测-图形-选择主机组-选择主机-选择图形-选择时间区间,可以查看图形。比如我可以查看刚才安装的主机的cpu负载情况;[root@rainbondmanager fonts]# pwd /usr/share/zabbix/assets/fonts [root@rainbondmanager fonts]# ll total 0 lrwxrwxrwx. 1 root root 33 Aug 3 01:56 graphfont.ttf -> /etc/alternatives/zabbix-web-font [root@rainbondmanager fonts]# [root@rainbondmanager fonts]# cd /etc/alternatives/ [root@rainbondmanager alternatives]# ll total 0 lrwxrwxrwx. 1 root root 15 Jul 8 14:43 ld -> /usr/bin/ld.bfd lrwxrwxrwx. 1 root root 34 Jul 8 14:43 libnssckbi.so.x86_64 -> /usr/lib64/pkcs11/p11-kit-trust.so lrwxrwxrwx. 1 root root 25 Aug 3 01:58 mysqlbug -> /usr/lib64/mysql/mysqlbug lrwxrwxrwx. 1 root root 29 Aug 3 01:56 zabbix-server -> /usr/sbin/zabbix_server_mysql lrwxrwxrwx. 1 root root 38 Aug 3 01:56 zabbix-web-font -> /usr/share/fonts/dejavu/DejaVuSans.ttf [root@rainbondmanager alternatives]# cd /usr/share/fonts/dejavu/ [root@rainbondmanager dejavu]# ll total 5288 -rw-r--r--. 1 root root 611212 Feb 27 2011 DejaVuSans-BoldOblique.ttf -rw-r--r--. 1 root root 672300 Feb 27 2011 DejaVuSans-Bold.ttf -rw-r--r--. 1 root root 580168 Feb 27 2011 DejaVuSansCondensed-BoldOblique.ttf -rw-r--r--. 1 root root 631992 Feb 27 2011 DejaVuSansCondensed-Bold.ttf -rw-r--r--. 1 root root 576004 Feb 27 2011 DejaVuSansCondensed-Oblique.ttf -rw-r--r--. 1 root root 643852 Feb 27 2011 DejaVuSansCondensed.ttf -rw-r--r--. 1 root root 345204 Feb 27 2011 DejaVuSans-ExtraLight.ttf -rw-r--r--. 1 root root 611556 Feb 27 2011 DejaVuSans-Oblique.ttf -rw-r--r--. 1 root root 720012 Feb 27 2011 DejaVuSans.ttf [root@rainbondmanager dejavu]# mv DejaVuSans.ttf DejaVuSans.ttf.bak mv msyh.ttf DejaVuSans.ttf刚才看到的图形,发现字符是乱码的?怎么解决了?很简单,将windows系统c:\windows\fonts\msyh.ttf 微软雅黑字体拷贝到linux的/usr/share/fonts/dejavu目录,将默认的字体文件先备份,然后将微软雅黑字体替换成默认的DejaVuSans.ttf

4. 自定义监控的实现:
前面讲到的都是使用zabbix系统现有的模板来实现监控,现有的模板一般都是通用的监控,比如常见的监控CPU使用率、CPU负载、内存使用率、磁盘分区使用率、网络流量等,常用的触发器也就是CPU使用率超过80%告警、内存使用率超过80%告警等等。当然这些模板也可以根据公司自己的情况来自定义告警阀值。那么有些监控没有模板怎么办?比如我们公司有一些需求是模板肯定没有的,我举例如下:
- 针对进程的监控;
- 服务器挂载的NAS共享存储监控;
- 应用使用的mq队列,比较重要的队列,一旦有消息堵塞需要马上告警的监控;
首先我们看看针对进程的监控是怎么实现的? 我先安装一个nginx的应用, 然后实现如果nginx应用出现问题的时候,会邮件告警;
yum install nginx -y
iptables -I INPUT -p tcp --dport 80 -j ACCEPT
# 查看nginx进程是否存在,存在的话,结果输出是1
ps aux |grep nginx|grep -v grep|grep master|wc -l
# 增加一个自定义的监控配置文件,路径是在zabbix_agentd.d目录下面
vim /etc/zabbix/zabbix_agentd.d/monitor_process.conf
UserParameter=monitor_process[*], /bin/ps aux |grep -v grep|grep -w "$1"|grep master|wc -l在zabbix客户端配置了自定义的配置文件之后,还需要在web管理端增加自定义的Item监控项
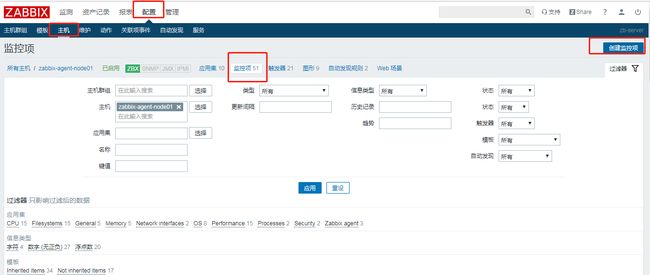
选择配置-主机-监控项-增加监控项
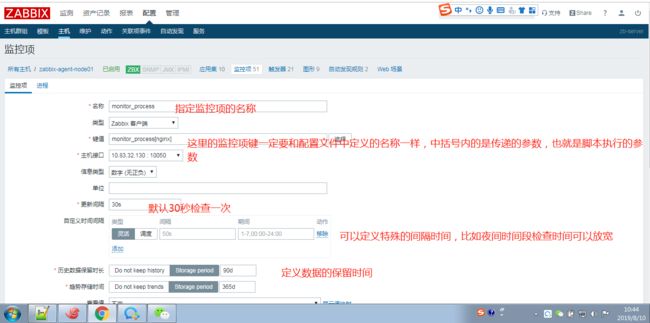
增加监控nginx进程的监控项
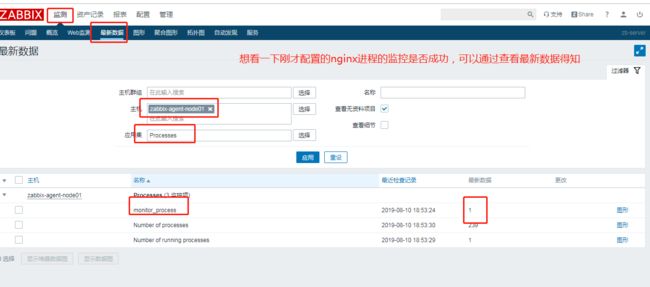
通过最新的数据可以发现刚才的进程监控已经有数据了,那么下一步我们就开始配置触发器,实现nginx进程停止之后告警

增加一个触发器
定义触发器的名称,还有选择监控项和表达式,有很多zabbix已经内置的表达式,我们选择其中的一个最新的值,如果是0就触发告警。当然这里还可以把多个条件做与非运算,比如AND OR NOT等运算;

选择告警的items和表达式,下面我们尝试把nginx进程给停止掉,看看有什么反应
root@rainbondnode01 zabbix_agentd.d]# systemctl stop nginx
[root@rainbondnode01 zabbix_agentd.d]# systemctl status nginx
● nginx.service - The nginx HTTP and reverse proxy server
Loaded: loaded (/usr/lib/systemd/system/nginx.service; disabled; vendor preset: disabled)
Active: inactive (dead)
Jul 25 21:36:46 rainbondnode01 nginx[26474]: nginx: configuration file /etc/nginx/nginx.conf test is successful
Jul 25 21:36:46 rainbondnode01 systemd[1]: Started The nginx HTTP and reverse proxy server.
Jul 29 18:07:21 rainbondnode01 systemd[1]: Stopping The nginx HTTP and reverse proxy server...
Jul 29 18:07:21 rainbondnode01 systemd[1]: Stopped The nginx HTTP and reverse proxy server.
Aug 09 14:49:02 rainbondnode01 systemd[1]: Starting The nginx HTTP and reverse proxy server...
Aug 09 14:49:02 rainbondnode01 nginx[16430]: nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
Aug 09 14:49:02 rainbondnode01 nginx[16430]: nginx: configuration file /etc/nginx/nginx.conf test is successful
Aug 09 14:49:02 rainbondnode01 systemd[1]: Started The nginx HTTP and reverse proxy server.
Aug 10 11:08:29 rainbondnode01 systemd[1]: Stopping The nginx HTTP and reverse proxy server...
Aug 10 11:08:29 rainbondnode01 systemd[1]: Stopped The nginx HTTP and reverse proxy server.
[root@rainbondnode01 zabbix_agentd.d]# 
大家看到,nginx停止掉之后,这里的告警已经出来了。只不过这样做还是不行,不能让运维人员天天盯着zabbix看吧,得通过邮件、短信、微信、钉钉等方式通知到运维人员才行,这样我们第一时间发现问题;本实验通过邮件来实现通知,也是最简单的。短信一般需要短信猫等设备,或者用移动139邮箱也可以实现;微信、钉钉等一般都有第三方API接口,调用他们的接口也可以实现告警;
# zabbix web管理页面显示的时区不对一般就几个地方需要确认
/etc/php.ini
/etc/httpd/conf.d/zabbix.conf
# 这两个配置文件里面的timezone配置
# 还有本地时区的配置,zabbix server和zabbix agent都需要配置时间同步,这样的话,web页面显示的时间就对了5. 用户定义、邮件告警、动作配置等:
1. 配置邮件发送脚本:
我们现在开始配置邮件告警。首先需要配置zabbix的配置文件/etc/zabbix/zabbix_server.conf,指定脚本的路径,默认的配置如下:
AlertScriptsPath=/usr/lib/zabbix/alertscripts那我就在这个目录下面写一个发送邮件的python脚本,然后通过web管理控制台调用这个脚本发送邮件;
cd /use/lib/zabbix/alertscripts
vim send_mail.py
#!/bin/env python
# -*- coding: utf-8 -*-
import smtplib
from email.mime.text import MIMEText
import smtplib
import sys
email_host = 'smtp.exmail.qq.com' #邮箱地址
email_user = '[email protected]' # 发送者账号
email_pwd = '123456' # 发送者的密码
maillist = sys.argv[1]
text = sys.argv[3]
msg = MIMEText('%s'%(text), 'plain', 'utf-8') # 邮件内容
msg['From'] = email_user # 发送者账号
msg['To'] = sys.argv[1] # 接收者账号列表
msg['Subject'] = sys.argv[2] # 邮件主题
smtp = smtplib.SMTP_SSL(email_host,port=465) # 连接邮箱,传入邮箱地址,和端口号,smtp的端口号是25
smtp.login(email_user, email_pwd) # 发送者的邮箱账号,密码
smtp.sendmail(email_user, maillist, msg.as_string())
# 参数分别是发送者,接收者,第三个是把上面的发送邮件的内容变成字符串
smtp.quit() # 发送完毕后退出smtp
print ('email send success.')
# 手动执行以下脚本,然后测试邮件是否可以正常发送
[root@rainbondmanager alertscripts]# python send_mail.py [email protected] testmail hellogaoyang
email send success.
# 登录邮箱,查看是否有测试的邮件接受到,如果有的话,表示脚本成功了2. 配置告警媒介类型:

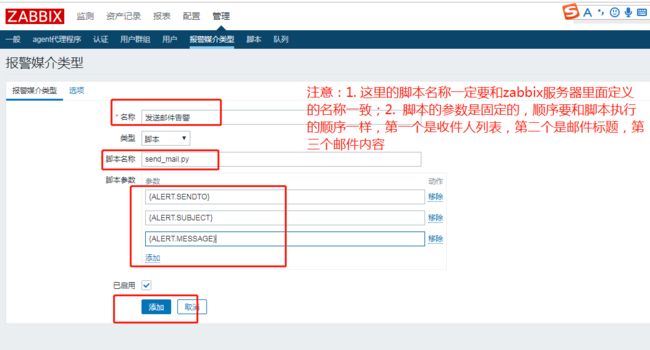
增加告警媒介类型,将刚才在zabbix server上面写的python脚本配置上去
3. 增加用户群组和用户:
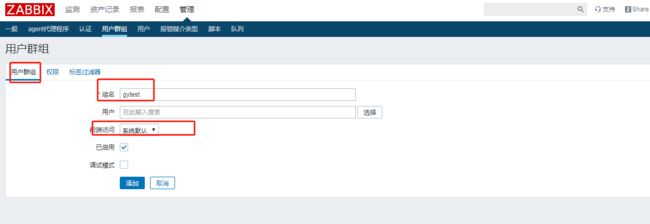

首先创建一个用户组,赋予管理主机组的权限,然后再创建用户;

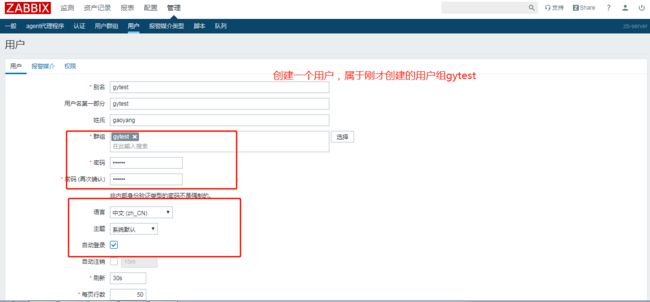

创建了一个用户,配置用户属于用户组,配置用户的报警媒介,包括用户的邮件地址,如果有短信发送,还需要配置用户的手机号等;
4. 配置一个触发器的动作:


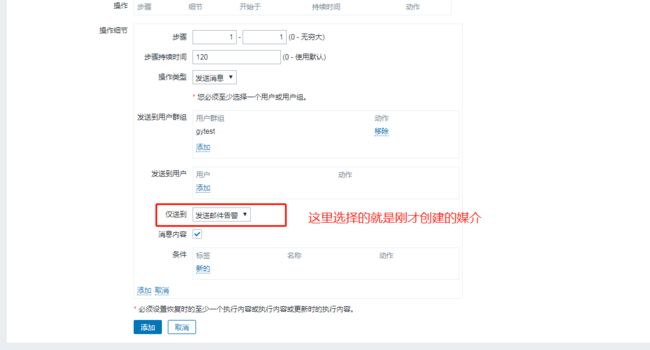

配置一个触发器的动作,将demo这个主机,如果有告警就多长时间发送告警,通过邮件告警的方式发送给用户群组;

最后我们看到在zabbix agent节点上面安装的nginx服务停止掉之后,果然有邮件发送了告警通知;
6. 配置自动发现zabbix客户端:
我们这个实验只有一台zabbix客户端,可以通过手工的添加主机的方式,那么在真正的生产环境下面,肯定不止一台服务器需要监控了。加入有上百台、上千台,甚至上万台客户端,难道都需要我们手工一个一个的添加主机,配置触发器、配置图形吗。那这样的话运维人员不得跳楼。幸好zabbix server早就考虑了这一点,有一个自动发现客户端的功能。通过自动发现客户端,可以实现主机只要安装上zabbix agent,就自动的加入到了某一个主机组,自动的关联了某一个模板,实现监控项、触发器、图形全部都实现了。


创建一个自动发现的规则,指定发现的网段,发现间隔时间,检查机制等;
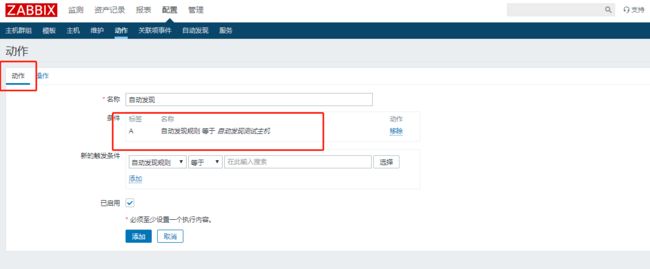
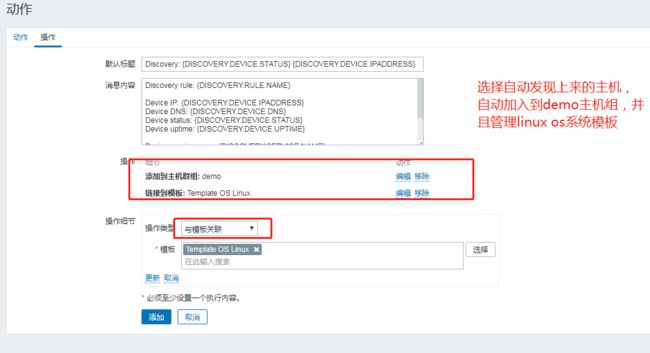
创建一个自动发现的动作,指定发现之后的主机自动加入到群组和关联模板


新安装的另外一台zabbix主机被发现了,新安装一台zabbix agent参考刚开始讲的安装方法,只需要把配置文件中的hostname改成自己的主机名就可以了,其他的不用修改。可以复制第一台的配置文件;
7. 配置URL监控:
前面我们讲到的监控,都是怎么监控基础资源,比如CPU负载,CPU使用率,磁盘使用率,内存使用率等,还有关于怎么自定义脚本来实现进程监控。实际在运维工作中,可能还会遇到基础资源没有问题,进程也没有停止到,但是因为其他原因,比如数据库连接不上,MQ连接不上等,或者代码BUG等,影响到业务的正常开展。如何监控这种情况,当然可以使用日志监控,我以前的博文中有讲过如何使用logstash来实现日志监控,有兴趣的可以查看。那么我们现在要将的是另外一种,就是URL监控,针对URL是否返回的是200来监控,废话不多说了,直接操作:

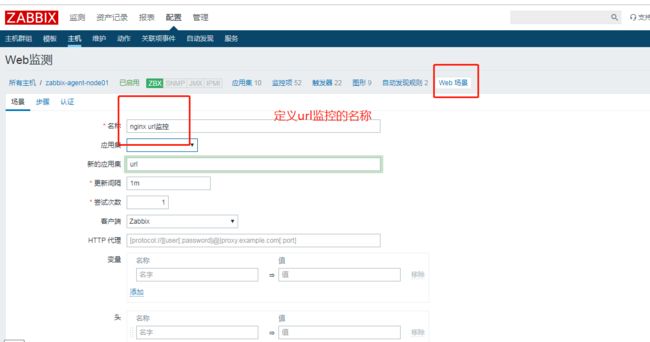


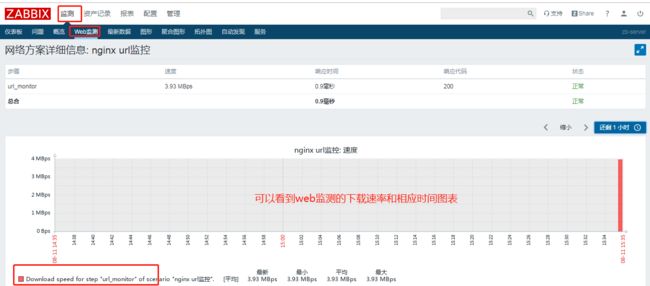

增加一个web检测,配置监控的url,返回码,查看URL的下载速率和响应时间,并且配置针对响应码的监控,如果URL返回的不是200就告警;
好的,今天的zabbix博文就写到这里了。zabbix是运维领域非常重要的一个软件,想要做好运维工作,zabbix是一个绕不过的坎。后续我还会针对zabbix软件深入的讲解,包括jvm监控、redis、mq、nginx status等更详细的监控说明,期待大家的关注;