大数据学习笔记之Storm(一):Storm
一 Storm概述
1.1 离线计算是什么?
离线计算:批量获取数据、批量传输数据、周期性批量计算数据、数据展示
代表技术:Sqoop批量导入数据、HDFS批量存储数据、MapReduce批量计算数据、Hive批量计算数据
1.2 流式计算是什么
流式计算:数据实时产生、数据实时传输、数据实时计算、实时展示
代表技术:Flume实时获取数据、Kafka实时数据存储、Storm/JStorm实时数据计算、Redis实时结果缓存、持久化存储(mysql)。
离线计算与实时计算最大的区别:实时收集、实时计算、实时展示
1.3 Storm是什么?
Storm是一个分布式计算框架,主要使用Clojure与Java语言编写,最初是由Nathan
Marz带领Backtype公司团队创建,在Backtype公司被Twitter公司收购后进行开源。最初的版本是在2011年9月17日发行,版本号0.5.0。
2013年9月,Apache基金会开始接管并孵化Storm项目。Apache Storm是在Eclipse
Public
License下进行开发的,它提供给大多数企业使用。经过1年多时间,2014年9月,Storm项目成为Apache的顶级项目。目前,Storm的最新版本1.1.0。
Storm是一个免费开源的分布式实时计算系统。Storm能轻松可靠地处理无界的数据流,就像Hadoop对数据进行批处理;
1.4 Storm与Hadoop的区别
1)Storm用于实时计算,Hadoop用于离线计算。
2)Storm处理的数据保存在内存中,源源不断;Hadoop处理的数据保存在文件系统中,一批一批处理。
3)Storm的数据通过网络传输进来;Hadoop的数据保存在磁盘中。
4)Storm与Hadoop的编程模型相似
Storm hadoop
角色 Nimbus JobTracker
Supervisor TaskTracker
Worker Child
应用名称 Topology Job
编程接口 Spout/Bolt Mapper/Reducer
(1)hadoop相关名称
Job:任务名称
JobTracker:项目经理(JobTracker对应于NameNode;JobTracker是一个master服务,软件启动之后JobTracker接收Job,负责调度Job的每一个子任务task运行于TaskTracker上,并监控它们,如果发现有失败的task就重新运行它。)
TaskTracker:开发组长(TaskTracker对应于DataNode;TaskTracker是运行在多个节点上的slaver服务。TaskTracker主动与JobTracker通信,接收作业,并负责直接执行每一个任务。)
Child:负责开发的人员
Mapper/Reduce:开发人员中的两种角色,一种是服务器开发、一种是客户端开发
(2)storm相关名称
Topology:任务名称
Nimbus:项目经理
Supervisor:开组长
Worker:开人员
Spout/Bolt:开人员中的两种角色,一种是服务器开发、一种是客户端开发
1.5 Storm应用场景及行业案例
Storm用来实时计算源源不断产生的数据,如同流水线生产。
1.5.1 运用场景
Storm能用到很多场景中,包括:实时分析、在线机器学习、连续计算等。
1)推荐系统:实时推荐,根据下单或加入购物车推荐相关商品
2)金融系统:实时分析股票信息数据
3)预警系统:根据实时采集数据,判断是否到了预警阈值。
4)网站统计:实时销量、流量统计,如淘宝双11效果图
1.5.2 典型案列
1)京东-实时分析系统:实时分析用户的属性,并反馈给搜索引擎
最初,用户属性分析是通过每天在云上定时运行的MR
job来完成的。为了满足实时性的要求,希望能够实时分析用户的行为日志,将最新的用户属性反馈给搜索引擎,能够为用户展现最贴近其当前需求的结果。

2)携程-网站性能监控:实时分析系统监控携程网的网站性能
利用HTML5提供的performance标准获得可用的指标,并记录日志。Storm集群实时分析日志和入库。使用DRPC聚合成报表,通过历史数据对比等判断规则,触发预警事件。
[外链图片转存失败(img-0ZX4mjxs-1563202359783)(images/media/image3.png)]{width=“5.7659722222222225in”
height=“2.770138888888889in”}
3)淘宝双十一:实时统计销售总额
[外链图片转存失败(img-S6gq7sjR-1563202359784)(images/media/image4.jpeg)]{width=“4.635416666666667in”
height=“2.2041666666666666in”}
1.6 Storm特点
1)适用场景广泛:Storm可以适用实时处理消息、更新数据库、持续计算等场景。
2)可伸缩性高:Storm的可伸缩性可以让Storm每秒处理的消息量达到很高。扩展一个实时计算任务,你所需要做的就是加机器并且提高这个计算任务的并行度。Storm使用Zookeeper来协调机器内的各种配置使得Storm的集群可以很容易的扩展。
3)保证无数据丢失:Storm保证所有的数据都被处理。
4)异常健壮:Storm集群非常容易管理,轮流重启节点不影响应用。
5)容错性好:在消息处理过程中出现异常,Storm会进行重试。
二 Storm基础知识
2.1 Storm编程模型
2.1.1 元组(Tuple)
元组(Tuple),是消息传递的基本单元,是一个命名的值列表,元组中的字段可以是任何类型的对象。Storm使用元组作为其数据模型,元组支持所有的基本类型、字符串和字节数组作为字段值,只要实现类型的序列化接口就可以使用该类型的对象。元组本来应该是一个key-value的Map,但是由于各个组件间传递的元组的字段名称已经事先定义好,所以只要按序把元组填入各个value即可,所以元组是一个value的List。
2.1.2 流(Stream)
流是Storm的核心抽象,是一个无界的元组系列。源源不断传递的元组就组成了流,在分布式环境中并行地进行创建和处理。
2.1.3 水龙头(Spout)
Spout是拓扑的流的来源,是一个拓扑中产生源数据流的组件。通常情况下,Spout会从外部数据源中读取数据,然后转换为拓扑内部的源数据。
Spout可以是可靠的,也可以是不可靠的。如果Storm处理元组失败,可靠的Spout能够重新发射,而不可靠的Spout就尽快忘记发出的元组。
Spout可以发出超过一个流。
Spout的主要方法是nextTuple()。NextTuple()会发出一个新的Tuple到拓扑,如果没有新的元组发出,则简单返回。
Spout的其他方法是ack()和fail()。当Storm检测到一个元组从Spout发出时,ack()和fail()会被调用,要么成功完成通过拓扑,要么未能完成。Ack()和fail()仅被可靠的Spout调用。
IRichSpout是Spout必须实现的接口。
2.1.4 转接头(Bolt)
在拓扑中所有处理都在Bolt中完成,Bolt是流的处理节点,从一个拓扑接收数据,然后执行进行处理的组件。Bolt可以完成过滤、业务处理、连接运算、连接与访问数据库等任何操作。
Bolt是一个被动的角色,七接口中有一个execute()方法,在接收到消息后会调用此方法,用户可以在其中执行自己希望的操作。
Bolt可以完成简单的流的转换,而完成复杂的流的转换通常需要多个步骤,因此需要多个Bolt。
Bolt可以发出超过一个的流。
2.1.5 拓扑(Topology)
拓扑(Topology)是Storm中运行的一个实时应用程序,因为各个组件间的消息流动而形成逻辑上的拓扑结构。
把实时应用程序的运行逻辑打成jar包后提交到Storm的拓扑(Topology)。Storm的拓扑类似于MapReduce的作业(Job)。其主要的区别是,MapReduce的作业最终会完成,而一个拓扑永远都在运行直到它被杀死。一个拓扑是一个图的Spout和Bolt的连接流分组。
2.2 Storm核心组件
nimbus是整个集群的控管核心,负责topology的提交、运行状态监控、任务重新分配等工作。
zk就是一个管理者,监控者。
总体描述:nimbus下命令(分配任务),zk监督执行(心跳监控,worker、supurvisor的心跳都归它管),supervisor领旨(下载代码),招募人马(创建worker和线程等),worker、executor就给我干活!task就是具体要干的活。
2.2.1 主控节点与工作节点
Storm集群中有两类节点:主控节点(Master Node)和工作节点(Worker
Node)。其中,主控节点只有一个,而工作节点可以有多个。
2.2.2 Nimbus进程与Supervisor进程
主控节点运行一个称为Nimbus的守护进程类似于Hadoop的JobTracker。Nimbus负责在集群中分发代码,对节点分配任务,并监视主机故障。
每个工作节点运行一个称为Supervisor的守护进程。Supervisor监听其主机上已经分配的主机的作业,启动和停止Nimbus已经分配的工作进程。
2.2.3 流分组(Stream grouping)
流分组,是拓扑定义中的一部分,为每个Bolt指定应该接收哪个流作为输入。流分组定义了流/元组如何在Bolt的任务之间进行分发。
Storm内置了8种流分组方式。
2.2.4 工作进程(Worker)
Worker是Spout/Bolt中运行具体处理逻辑的进程。一个worker就是一个进程,进程里面包含一个或多个线程。
2.2.5 执行器(Executor)
一个线程就是一个executor,一个线程会处理一个或多个任务。
2.2.6 任务(Task)
一个任务就是一个task。
2.3 实时流计算常见架构图
1)Flume获取数据。
2)Kafka临时保存数据。
3)Strom计算数据。
4)Redis是个内存数据库,用来保存数据。
三 Storm集群搭建
3.1 环境准备
3.1.1 集群规划
hadoop102 hadoop103 hadoop104
zk zk zk
storm storm storm
3.1.2 jar包下载
(1)官方网址:[http://storm.apache.org/]{.underline}
 (2)安装集群步骤:
(2)安装集群步骤:
[http://storm.apache.org/releases/1.1.0/Setting-up-a-Storm-cluster.html]{.underline}
3.1.3 虚拟机准备
1)准备3台虚拟机
2)配置ip地址
3)配置主机名称
4)3台主机分别关闭防火墙
[root@hadoop102 atguigu]# chkconfig iptables off
[root@hadoop103 atguigu]# chkconfig iptables off
[root@hadoop104 atguigu]# chkconfig iptables off
3.1.4 安装jdk
3.1.5 安装Zookeeper
0)集群规划
在hadoop102、hadoop103和hadoop104三个节点上部署Zookeeper。
1)解压安装
(1)解压zookeeper安装包到/opt/module/目录下
[atguigu@hadoop102 software]$ tar -zxvf zookeeper-3.4.10.tar.gz -C
/opt/module/(2)在/opt/module/zookeeper-3.4.10/这个目录下创建zkData
mkdir -p zkData
(3)重命名/opt/module/zookeeper-3.4.10/conf这个目录下的zoo_sample.cfg为zoo.cfg
mv zoo_sample.cfg zoo.cfg
2)配置zoo.cfg文件
(1)具体配置
dataDir=/opt/module/zookeeper-3.4.10/zkData
增加如下配置
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
(2)配置参数解读
Server.A=B:C:D。
A是一个数字,表示这个是第几号服务器;
B是这个服务器的ip地址;
C是这个服务器与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
集群模式下配置一个文件myid,这个文件在dataDir目录下,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
3)集群操作
(1)在/opt/module/zookeeper-3.4.10/zkData目录下创建一个myid的文件
touch myid
添加myid文件,注意一定要在linux里面创建,在notepad++里面很可能乱码
(2)编辑myid文件
vi myid
在文件中添加与server对应的编号:如2
(3)拷贝配置好的zookeeper到其他机器上
scp -r zookeeper-3.4.10/
[[email protected]:/opt/app/]{.underline}scp -r zookeeper-3.4.10/
[[email protected]:/opt/app/]{.underline}并分别修改myid文件中内容为3、4
(4)分别启动zookeeper
[root@hadoop102 zookeeper-3.4.10]# bin/zkServer.sh start
[root@hadoop103 zookeeper-3.4.10]# bin/zkServer.sh start
[root@hadoop104 zookeeper-3.4.10]# bin/zkServer.sh start
(5)查看状态
[root@hadoop102 zookeeper-3.4.10]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/…/conf/zoo.cfg
Mode: follower
[root@hadoop103 zookeeper-3.4.10]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/…/conf/zoo.cfg
Mode: leader
[root@hadoop104 zookeeper-3.4.5]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/…/conf/zoo.cfg
Mode: follower
3.2 Storm集群部署
3.2.1 配置集群
1)拷贝jar包到hadoop102的/opt/software目录下
2)解压jar包到/opt/module目录下
[atguigu@hadoop102 software]$ tar -zxvf apache-storm-1.1.0.tar.gz -C
/opt/module/
3)修改解压后的apache-storm-1.1.0.tar.gz文件名称为storm
[atguigu@hadoop102 module]$ mv apache-storm-1.1.0/ storm
4)在/opt/module/storm/目录下创建data文件夹
[atguigu@hadoop102 storm]$ mkdir data
5)修改配置文件
[atguigu@hadoop102 conf]$ pwd
/opt/module/storm/conf
[atguigu@hadoop102 conf]$ vi storm.yaml
±--------------------------------------------+
| # 设置Zookeeper的主机名称 |
| |
| storm.zookeeper.servers: |
| |
| - “hadoop102” |
| |
| - “hadoop103” |
| |
| - “hadoop104” |
| |
| # 设置主节点的主机名称 |
| |
| nimbus.seeds: [“hadoop102”] |
| |
| # 设置Storm的数据存储路径 |
| |
| storm.local.dir: “/opt/module/storm/data” |
| |
| # 设置Worker的端口号 |
| |
| supervisor.slots.ports: |
| |
| - 6700 |
| |
| - 6701 |
| |
| - 6702 |
| |
| - 6703 |
±--------------------------------------------+
6)配置环境变量
[root@hadoop102 storm]# vi /etc/profile
±-------------------------------------+
| #STORM_HOME |
| |
| export STORM_HOME=/opt/module/storm |
| |
| export PATH=$PATH:$STORM_HOME/bin |
±-------------------------------------+
[root@hadoop102 storm]# source /etc/profile
7)分发配置好的Storm安装包
[atguigu@hadoop102 storm]$ xsync storm/
8)启动集群
(1)后台启动nimbus
[atguigu@hadoop102 storm]$ bin/storm nimbus &
[atguigu@hadoop103 storm]$ bin/storm nimbus &
[atguigu@hadoop104 storm]$ bin/storm nimbus &
(2)后台启动supervisor
[atguigu@hadoop102 storm]$ bin/storm supervisor &
[atguigu@hadoop102 storm]$ bin/storm supervisor &
[atguigu@hadoop102 storm]$ bin/storm supervisor &
(3)启动Storm ui
[atguigu@hadoop102 storm]$ bin/storm ui
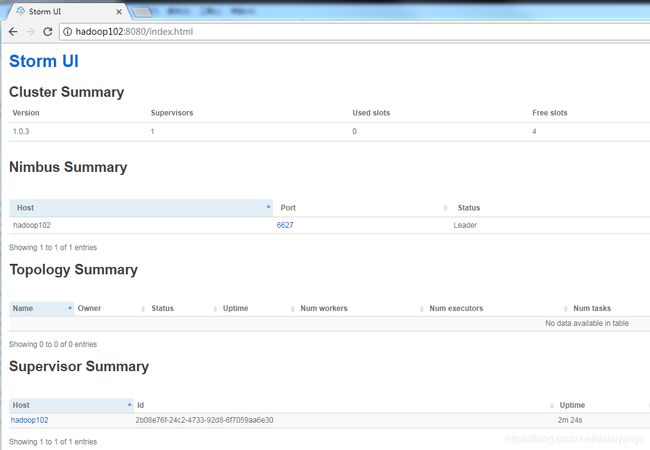
9)通过浏览器查看集群状态
[http://hadoop102:8080/index.html]{.underline}
3.2.2 Storm日志信息查看
1)查看nimbus的日志信息
在nimbus的服务器上
cd /opt/module/storm/logs
tail -100f /opt/module/storm/logs/nimbus.log
2)查看ui运行日志信息
在ui的服务器上,一般和nimbus一个服务器
cd /opt/module/storm/logs
tail -100f /opt/module/storm/logs/ui.log
3)查看supervisor运行日志信息
在supervisor服务上
cd /opt/module/storm/logs
tail -100f /opt/module/storm/logs/supervisor.log
4)查看supervisor上worker运行日志信息
在supervisor服务上
cd /opt/module/storm/logs
tail -100f /opt/module/storm/logs/worker-6702.log
5)logviewer,可以在web页面点击相应的端口号即可查看日志
分别在supervisor节点上执行:
[atguigu@hadoop102 storm]$ bin/storm logviewer &
[atguigu@hadoop103 storm]$ bin/storm logviewer &
[atguigu@hadoop104 storm]$ bin/storm logviewer &



前提是需要在上面通过 bin/storm logviewer &启动
3.2.3 Storm命令行操作
1)nimbus:启动nimbus守护进程
storm nimbus
2)supervisor:启动supervisor守护进程
storm supervisor
3)ui:启动UI守护进程。
storm ui
4)list:列出正在运行的拓扑及其状态
storm list
5)logviewer:Logviewer提供一个web接口查看Storm日志文件。
storm logviewer
6)jar(自定义一个java程序在storm上:
storm jar 【jar路径】 【拓扑包名.拓扑类名】 【拓扑名称】
7)kill:杀死名为Topology-name的拓扑
storm kill topology-name [-w wait-time-secs]
-w:等待多久后杀死拓扑
8)active:激活指定的拓扑spout。
storm activate topology-name
9)deactivate:禁用指定的拓扑Spout。
storm deactivate topology-name
10)help:打印一条帮助消息或者可用命令的列表。
storm help
storm help
四 常用API
4.1 API简介
4.1.1 Component组件
1)基本接口
(1)IComponent接口
(2)ISpout接口
(3)IRichSpout接口
(4)IStateSpout接口
(5)IRichStateSpout接口
(6)IBolt接口
(7)IRichBolt接口
(8)IBasicBolt接口
2)基本抽象类
(1)BaseComponent抽象类
(2) BaseRichSpout抽象类
(3)BaseRichBolt抽象类
(4)BaseTransactionalBolt抽象类
(5)BaseBasicBolt抽象类
4.1.2 spout水龙头
Spout的最顶层抽象是ISpout接口

(1)Open()
是初始化方法
(2)close()
在该spout关闭前执行,但是并不能得到保证其一定被执行,kill
-9时不执行,Storm kill {topoName} 时执行
(3)activate()
当Spout已经从失效模式中激活时被调用。该Spout的nextTuple()方法很快就会被调用。
(4)deactivate ()
禁止
当Spout已经失效时被调用。在Spout失效期间,nextTuple不会被调用。Spout将来可能会也可能不会被重新激活。
其实active和deactive关掉的实际上是nextTuple这个方法,因为具体发送的操作是在nextTuple里面做的。是不停的在调用nextTuple这个方法的,这里相当于把nextTuple前面掐死,就相当于nextTuple这个方法就不能再执行了。
(5)nextTuple()
当调用nextTuple()方法时,Storm要求Spout发射元组到输出收集器(OutputCollecctor)。NextTuple方法应该是非阻塞的,所以,如果Spout没有元组可以发射,该方法应该返回。nextTuple()、ack()和fail()方法都在Spout任务的单一线程内紧密循环被调用。当没有元组可以发射时,可以让nextTuple去sleep很短的时间,例如1毫秒,这样就不会浪费太多的CPU资源。
(6)ack()
成功处理tuple回调方法
(7)fail()
处理失败tuple回调方法
原则:通常情况下(Shell和事务型的除外),实现一个Spout,可以直接实现接口IRichSpout,如果不想写多余的代码,可以直接继承BaseRichSpout。
4.1.3 bolt转接头
bolt的最顶层抽象是IBolt接口

(1)prepare()
prepare
()方法在集群的工作进程内被初始化时被调用,提供了Bolt执行所需要的环境。
(2)execute()
接受一个tuple进行处理,也可emit数据到下一级组件。进行具体的业务处理。
(3)cleanup()
Cleanup方法当一个IBolt即将关闭时被调用。不能保证cleanup()方法一定会被调用,因为Supervisor可以对集群的工作进程使用kill
-9命令强制杀死进程命令。
如果在本地模式下运行Storm,当拓扑被杀死的时候,可以保证cleanup()方法一定会被调用。
实现一个Bolt,可以实现IRichBolt接口或继承BaseRichBolt,如果不想自己处理结果反馈,可以实现IBasicBolt接口或继承BaseBasicBolt,它实际上相当于自动做了prepare方法和collector.emit.ack(inputTuple)。
4.1.4 spout的tail特性
Storm可以实时监测文件数据,当文件数据变化时,Storm自动读取。
4.2 网站日志处理案例
4.2.1 实操环境准备
1)打开eclipse,创建一个java工程
2)在工程目录中创建lib文件夹
3)解压apache-storm-1.1.0,并把解压后lib包下的文件复制到java工程的lib文件夹中。然后执行build
path。
4.2.2 需求1:将接收到日志的会话id打印在控制台
1)需求:
(1)模拟访问网站的日志信息,包括:网站名称、会话id、访问网站时间等
(2)将接收到日志的会话id打印到控制台
2)分析
(1)创建网站访问日志工具类
(2)在spout中读取日志文件,并一行一行发射出去
(3)在bolt中将获取到的一行一行数据的会话id获取到,并打印到控制台。
(4)main方法负责拼接spout和bolt的拓扑。

早storm中spout接收数据,bolt处理数据,这里面的bolt更接近于MapReduce中的处理阶段。
3)案例实操
(1)创建网站访问日志
手动写代码产生上面的日志
package com.atguigu.storm.weblog;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Random;
// 生成数据
public class GenerateData {
public static void main(String[] args) {
File logFile = new File("e:/website.log");
Random random = new Random();
// 1 网站名称
String[] hosts = { "www.atguigu.com" };
// 2 会话id
String[] session_id = { "ABYH6Y4V4SCVXTG6DPB4VH9U123", "XXYH6YCGFJYERTT834R52FDXV9U34",
"BBYH61456FGHHJ7JL89RG5VV9UYU7", "CYYH6Y2345GHI899OFG4V9U567", "VVVYH6Y4V4SFXZ56JIPDPB4V678" };
// 3 访问网站时间
String[] time = { "2017-08-07 08:40:50", "2017-08-07 08:40:51", "2017-08-07 08:40:52", "2017-08-07 08:40:53",
"2017-08-07 09:40:49", "2017-08-07 10:40:49", "2017-08-07 11:40:49", "2017-08-07 12:40:49" };
// 4 拼接网站访问日志
StringBuffer sbBuffer = new StringBuffer();
for (int i = 0; i < 40; i++) {
sbBuffer.append(hosts[0] + "\t" + session_id[random.nextInt(5)] + "\t" + time[random.nextInt(8)] + "\n");
}
// 5 判断log日志是否存在,不存在要创建
if (!logFile.exists()) {
try {
logFile.createNewFile();
} catch (IOException e) {
System.out.println("Create logFile fail !");
}
}
byte[] b = (sbBuffer.toString()).getBytes();
// 6 将拼接的日志信息写到日志文件中
FileOutputStream fs;
try {
fs = new FileOutputStream(logFile);
fs.write(b);
fs.close();
System.out.println("generate data over");
} catch (Exception e) {
e.printStackTrace();
}
}
}
(2)创建spout
package com.atguigu.storm.weblog;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.Map;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.IRichSpout;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
public class WebLogSpout implements IRichSpout{
private static final long serialVersionUID = 1L;
private BufferedReader br;
private SpoutOutputCollector collector = null;
private String str = null;
@Override
//发送数据
//读一行发一行
public void nextTuple() {
// 循环调用的方法
try {
//读一行发一行
while ((str = this.br.readLine()) != null) {
// 发射出去
//Values是spout和bolt之间传输数据的一个载体
collector.emit(new Values(str));
//Thread.sleep(3000);
}
} catch (Exception e) {
}
}
@SuppressWarnings("rawtypes")
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
// 打开输入的文件,打开刚才的日志文件
try {
//spout往bolt中发送数据的时候用的就是SpoutOutputCollector
this.collector = collector;
//这个reader在上面声明为了全局的
this.br = new BufferedReader(new InputStreamReader(new FileInputStream("e:/website.log"), "UTF-8"));
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
//声明spout往bolt发送的类型
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 声明输出字段类型
//这里可以起到一个过滤的作用,比如当前的spout是log和haha类型,在bolt中接受的时候只接受log的
declarer.declare(new Fields("log"));
}
@Override
public void ack(Object arg0) {
}
@Override
public void activate() {
}
@Override
public void close() {
}
@Override
public void deactivate() {
}
@Override
public void fail(Object arg0) {
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
(3)创建bolt
package com.atguigu.storm.weblog;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.IRichBolt;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
public class WebLogBolt implements IRichBolt {
private static final long serialVersionUID = 1L;
private OutputCollector collector = null;
private int num = 0;
private String valueString = null;
@Override
//主要就是这个方法
public void execute(Tuple input) {
try {
// 1 获取传递过来的数据
//这里的log是上面的spout的declareOutputFields()声明的类型
// valueString = input.getStringByField("log");
//还有另一种方式
//这里的0对应的是上面的spout中的collector.emit(new Values(str));里面的str,
//如果collector.emit(new Values(str,str,str ...)),有多个参数,这里就getString(1) ...以此类推
valueString = input.getString(0);
// 2 如果输入的数据不为空,行数++
if (valueString != null) {
//统计数据条数
num++;
//切割数据
System.err.println(Thread.currentThread().getName() + "lines :" + num + " session_id:" + valueString.split("\t")[1]);
}
// 3 应答Spout接收成功
collector.ack(input);
Thread.sleep(2000);
} catch (Exception e) {
// 4 应答Spout接收失败
collector.fail(input);
e.printStackTrace();
}
}
@SuppressWarnings("rawtypes")
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 声明输出字段类型
declarer.declare(new Fields(""));
}
@Override
public void cleanup() {
}
@Override
public Map<String, Object> getComponentConfiguration() {
//获取配置信息
return null;
}
}
(4)创建main
package com.atguigu.storm.weblog;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.topology.TopologyBuilder;
public class WebLogMain {
public static void main(String[] args) {
// 1 创建拓扑对象
//把上面的spout和bolt连接起来就是一个拓扑
TopologyBuilder builder = new TopologyBuilder();
// 2 设置Spout和bolt
//第一个参数,起一个名字,后面的1是并行度,表示几个线程读这个数据
builder.setSpout("weblogspout", new WebLogSpout(), 1);
//第一个参数,起一个名字,1并行度,shuffleGrouping分组,第四个参数填的是sput的名称
builder.setBolt("weblogbolt", new WebLogBolt(), 1).shuffleGrouping("weblogspout");
// 3 配置Worker开启个数,worker相当于进程
Config conf = new Config();
conf.setNumWorkers(4);
if (args.length > 0) {
try {
// 4 分布式提交
//参数:名称、配置、拓扑
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
}else {
// 5 本地模式提交
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("weblogtopology", conf, builder.createTopology());
}
}
}
4.2.3 需求2:动态增加日志,查看控制台打印信息(tail特性)
1)在需求1基础上,运行程序。
2)打开website.log日志文件,增加日志调试并保存。
3)观察控制台打印的信息。
结论:Storm可以动态实时监测文件的增加信息,并把信息读取到再处理。
五 分组策略和并发度
5.1 读取文件案例思考
1)spout数据源:数据库、文件、MQ(比如:Kafka)
2)数据源是数据库:只适合读取数据库的配置文件
3)数据源是文件:只适合测试、讲课用(因为集群是分布式集群)
4)企业产生的log文件处理步骤:
(1)读出内容写入MQ
(2)Storm再处理
上面中如果
//第一个参数,起一个名字,后面的1是并行度,表示几个线程读这个数据
builder.setSpout("weblogspout", new WebLogSpout(), 1);
//第一个参数,起一个名字,1并行度,shuffleGrouping分组,第四个参数填的是sput的名称
builder.setBolt("weblogbolt", new WebLogBolt(), 4).shuffleGrouping("weblogspout");
一个spout 4个bolt的话,name这个spout到底往哪里发呢?
5.2 分组策略(Stream Grouping)
stream
grouping用来定义一个stream应该如何分配给Bolts上面的多个Executors( 多线程、多并发)。
注意下面这几种只有在多线程、多并发的情况下才有不同,在单机的情况下是没有区别的
Storm里面有7种类型的stream grouping
**1) ** Shuffle Grouping:随机分组 ,轮询,平均分配。随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同。
虽然是随机你的但是尽可能的保证是平均的
2) Fields
Grouping:按字段分组 ,比如按userid来分组,具有同样userid的tuple会被分到相同的Bolts里的一个task,而不同的userid则会被分配到不同的bolts里的task。
3)All Grouping:广播发送,对于每一个tuple,所有的bolts都会收到。
4)Global Grouping:全局分组,这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。非常冷门的策略
5)Non Grouping:不分组,这stream
grouping个分组的意思是说stream不关心到底谁会收到它的tuple。 目前这种分组和Shuffle
grouping是一样的效果。在多线程情况下不平均分配。
6)Direct Grouping:直接分组,这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为DirectStream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的task的id(OutputCollector.emit方法也会返回task的id)。
直接指定给谁发。
**7)Local or shuffle
grouping:**如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发送给这些tasks。否则,和普通的Shuffle
Grouping行为一致。
8)测试
(1)spout并发度修改为2,bolt并发度修改为1,shuffleGrouping模式
builder.setSpout("WebLogSpout", new WebLogSpout(),2);
builder.setBolt("WebLogBolt", new WebLogBolt(), 1).shuffleGrouping("WebLogSpout");
Spout开两个线程会对数据读取两份,打印出来就是2份。如果数据源是消息队列,就不会出来读取两份的数据(统一消费者组,只能有一个消费者)
Thread-33-WebLogBolt-executor[1 1]lines:60 session_id:CYYH6Y2345GHI899OFG4V9U567
如果是spout为1,bolt为2的话
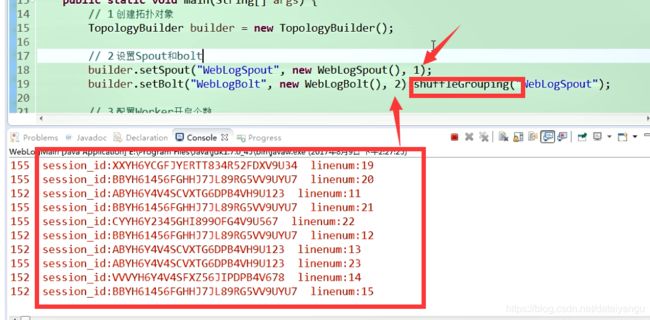
可以看到是一个分配一半,里面的是随机的大致一般,并不是绝对的
(2)spout并发度修改为1,bolt并发度修改为2,noneGrouping模式
builder.setSpout("WebLogSpout", new WebLogSpout(),1);
builder.setBolt("WebLogBolt", new WebLogBolt(), 2).noneGrouping("WebLogSpout");
每个bolt接收到的单词不同。
Thread-33-WebLogBolt-executor[1 1]lines:14 session_id:VVVYH6Y4V4SFXZ56JIPDPB4V678
Thread-34-WebLogBolt-executor[2 2]lines:16 session_id:VVVYH6Y4V4SFXZ56JIPDPB4V678
(3)spout并发度修改为1,bolt并发度修改为2,fieldsGrouping
builder.setSpout("WebLogSpout", new WebLogSpout(),1);
builder.setBolt("WebLogBolt", new WebLogBolt(), 2).fieldsGrouping("WebLogSpout", new Fields("log"));
基于web案例不明显,后续案例比较明显
这里的log是在spout里面定义的
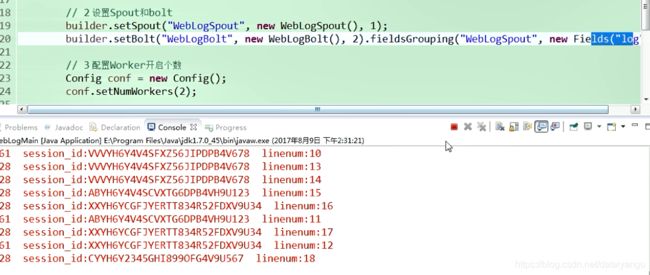
图中效果不是很明显,这里效果确实不是很明显,先往下看。
(4)spout并发度修改为1,bolt并发度修改为2,allGrouping(“spout”); 广播方式
builder.setSpout("WebLogSpout", new WebLogSpout(),1);
builder.setBolt("WebLogBolt", new WebLogBolt(), 2).allGrouping("WebLogSpout");
每一个bolt获取到的数据都是一样的。
Thread-43-WebLogBolt-executor[1 1]lines:30 session_id:VVVYH6Y4V4SFXZ56JIPDPB4V678
Thread-23-WebLogBolt-executor[2 2]lines:30 session_id:VVVYH6Y4V4SFXZ56JIPDPB4V678
[外链图片转存失败(img-RSVXqwrC-1563202359845)(images/1562767083422.png)]
可以看到十分工整的在执行
(5)spout并发度修改为1,bolt并发度修改为2,globalGrouping(“spout”);
builder.setSpout("WebLogSpout", new WebLogSpout(),1);
builder.setBolt("WebLogBolt", new WebLogBolt(), 2).globalGrouping("WebLogSpout");
Task的id最低的bolt获取到了所有数据。
Thread-28-WebLogBolt-executor[1 1]lines:30 session_id:VVVYH6Y4V4SFXZ56JIPDPB4V678
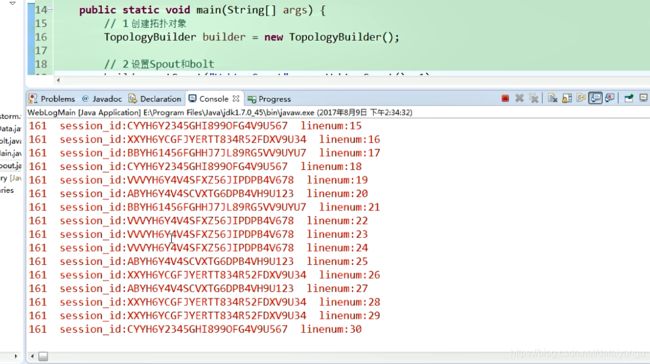
只让线程id号最低的接收到
5.3 并发度
5.3.1 场景分析
1)单线程下:加减乘除、全局汇总
2)多线程下:局部加减乘除、持久化DB等
1)思考:如何计算:word总数和word个数?并且在高并发下完成
前者是统计总行数,后者是去重word个数;
类似企业场景:计算网站PV和UV
(2)网站最常用的两个指标:
PV(page views):count (session_id) 即页面浏览量。
UV(user views):count(distinct session_id) 即独立访客数。
a)用ip地址分析
指访问某个站点或点击某个网页的不同IP地址的人数。在同一天内,UV只记录第一次进入网站的具有独立IP的访问者,在同一天内再次访问该网站则不计数。
b)用Cookie分析UV值
当客户端第一次访问某个网站服务器的时候,网站服务器会给这个客户端的电脑发出一个Cookie,通常放在这个客户端电脑的C盘当中。在这个Cookie中会分配一个独一无二的编号,这其中会记录一些访问服务器的信息,如访问时间,访问了哪些页面等等。当你下次再访问这个服务器的时候,服务器就可以直接从你的电脑中找到上一次放进去的Cookie文件,并且对其进行一些更新,但那个独一无二的编号是不会变的
实时处理的业务场景主要包括:汇总型(如网站PV、销售额、订单数)、去重型(网站UV、顾客数、销售商品数)
5.3.2 并发度
并发度:用户指定一个任务,可以被多个线程执行, 并发度的数量等于线程executor的数量。
Task就是具体的处理逻辑对象,一个executor线程可以执行一个或多个tasks,但一般默认每个executor只执行一个task,所以我们往往认为task就是执行线程,其实不是。
Task代表最大并发度 ,一个component的task数是不会改变的,但是一个componet的executer数目是会发生变化的(storm
rebalance命令),task数>=executor数,executor数代表实际并发数 。
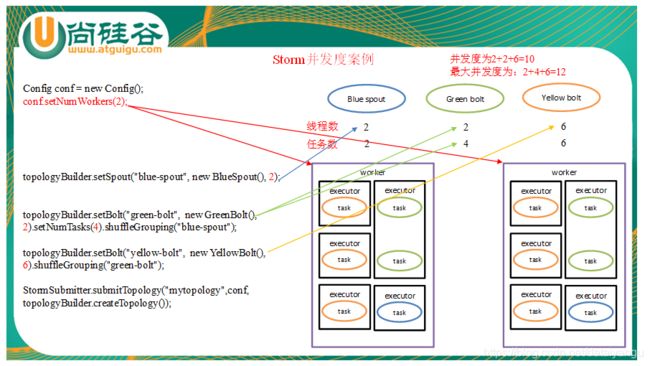
如图,虽然有的executor中放着多个task,但是executor还是1所以并发数还是1,所以真正的还是要数executor到底有多少个。
对外来说实际的并发数就是executor,task是用来表示最大并发度的。
看左侧的代码setBolt的时候可以设置task,这里设置2个bolt对应4个task
work代表进程代表具体的应用, 上面有三个bolt,可以通过不同颜色的箭头看到他们对应的线程数和任务数
可以看到上面最后的结果:右上角的并发度和最大并发度。
结论:并发度就是executor的数量,最大并发度是看task的数量,只有executor中有一个task的时候才会并发度和最大并发度相等。
5.4 实操案例
5.4.1 实时单词统计案例
1)需求
实时统计发射到Storm框架中单词的总数。
2)分析
设计一个topology,来实现对文档里面的单词出现的频率进行统计。
整个topology分为三个部分:
(1)WordCountSpout:数据源,在已知的英文句子中,随机发送一条句子出去。
(2)WordCountSplitBolt:负责将单行文本记录(句子)切分成单词
(3)WordCountBolt:负责对单词的频率进行累加

3)实操
(1)创建spout
package com.atguigu.storm.wordcount;
import java.util.Map;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
//发送一条语句
public class WordCountSpout extends BaseRichSpout {
private static final long serialVersionUID = 1L;
private SpoutOutputCollector collector;
@Override
public void nextTuple() {
// 1 发射模拟数据
collector.emit(new Values("i am ximen love jinlian"));
// 2 睡眠2秒
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@SuppressWarnings("rawtypes")
@Override
public void open(Map arg0, TopologyContext arg1, SpoutOutputCollector collector) {
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("love"));
}
}
(2)创建切割单词的bolt
package com.atguigu.storm.wordcount;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
public class WordCountSplitBolt extends BaseRichBolt {
private static final long serialVersionUID = 1L;
private OutputCollector collector;
@Override
public void execute(Tuple input) {
// 1 获取传递过来的一行数据
String line = input.getString(0);
// 2 截取
String[] arrWords = line.split(" ");
// 3 发射
for (String word : arrWords) {
//这里的1是为了计数用的
collector.emit(new Values(word, 1));
}
}
@SuppressWarnings("rawtypes")
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector) {
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "num"));
}
}
(3)创建汇总单词个数的bolt
//接收上个bolt发送过来的数据
package com.atguigu.storm.wordcount;
import java.util.HashMap;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
public class WordCountBolt extends BaseRichBolt {
private static final long serialVersionUID = 1L;
private Map<String, Integer> map = new HashMap<String, Integer>();
@Override
public void execute(Tuple input) {
// 1 获取传递过来的数据
String word = input.getString(0);
Integer num = input.getInteger(1);
// 2 累加单词
if (map.containsKey(word)) {
Integer count = map.get(word);
map.put(word, count + num);
} else {
map.put(word, num);
}
System.err.println(Thread.currentThread().getId() + " word:" + word + " num:" + map.get(word));
}
@SuppressWarnings("rawtypes")
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector) {
}
@Override
public void declareOutputFields(OutputFieldsDeclarer arg0) {
// 不输出
}
}
(4)创建程序的拓扑main
package com.atguigu.storm.wordcount;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
public class WordCountMain {
public static void main(String[] args) {
// 1、准备一个TopologyBuilder
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("WordCountSpout", new WordCountSpout(), 1);
builder.setBolt("WordCountSplitBolt", new WordCountSplitBolt(), 2).shuffleGrouping("WordCountSpout");
builder.setBolt("WordCountBolt", new WordCountBolt(), 4).fieldsGrouping("WordCountSplitBolt", new Fields("word"));
// 2、创建一个configuration,用来指定当前topology 需要的worker的数量
Config conf = new Config();
conf.setNumWorkers(2);
// 3、提交任务 -----两种模式 本地模式和集群模式
if (args.length > 0) {
try {
// 4 分布式提交
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
} else {
// 5 本地模式提交
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("wordcounttopology", conf, builder.createTopology());
}
}
}
(5)测试
发现132线程只处理单词am和单词love;169进程处理单词i、ximen、jianlian。这就是分组的好处。
132 word:am num:1
132 word:love num:1
169 word:i num:1
169 word:ximen num:1
169 word:jinlian num:1
如果是worldcount的bolt是1的话

如果将worldcount的bolt修改为2的话
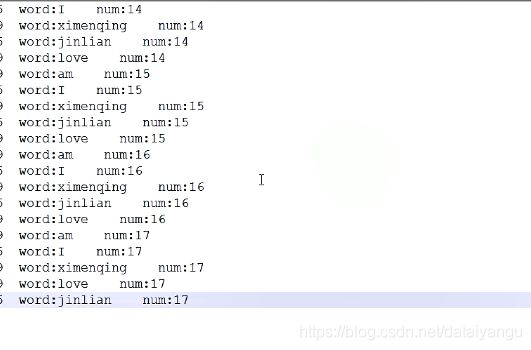
可以看到有135和129着两个进程,进行整理之后

可以看到被处理多的相同的单词一直都是在一个线程里面, i jinlian 在135线程中,ximenqin love am在129线程中
如果将上面的分区修改为如下,其他的地方不变
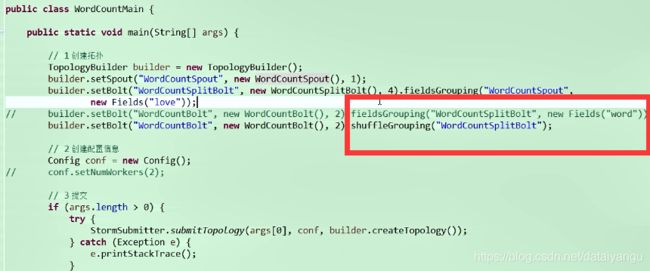
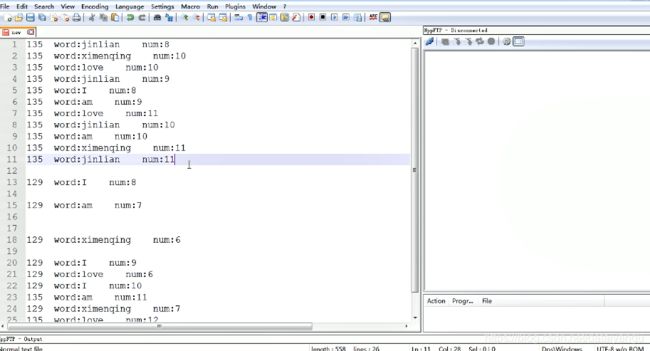
就变成了这种随机的分配
看了这么多,发现虽然策略变了,可能会被不同的线程处理,但是累加的数是没有变的。
5.4.2 实时计算网站PV案例
0)基础知识准备
1)需求
统计网站pv。
2)需求分析
方案一:
定义static long pv,Synchronized 控制累计操作。(不可行)
原因:Synchronized 和 Lock在单JVM下有效,但在多JVM下无效
方案二:
shuffleGrouping下,pv * Executer并发数
驱动函数中配置如下:
builder.setSpout("PVSpout", new PVSpout(), 1);
builder.setBolt("PVBolt1", new PVBolt1(), 4).shuffleGrouping("PVSpout");
在PVBolt1中输出时
System.err.println("threadid:" + Thread.currentThread().getId() + " pv:" + pv*4);
因为shuffleGrouping轮询分配
优点:简单、计算量小
缺点:稍有误差,但绝大多数场景能接受
方案三:
PVBolt1进行多并发局部汇总,PVSumbolt单线程进行全局汇总
线程安全:多线程处理的结果和单线程一致
优点:绝对准确;如果用filedGrouping可以得到中间值,如单个user的访问PV(访问深度等)
缺点:计算量稍大,且多一个Bolt

将多个线程的累加
3)案例实操
(1)创建数据输入源PVSpout
package com.atguigu.storm.pv;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Map;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.IRichSpout;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
public class PVSpout implements IRichSpout{
private static final long serialVersionUID = 1L;
private SpoutOutputCollector collector ;
private BufferedReader reader;
@SuppressWarnings("rawtypes")
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
try {
reader = new BufferedReader(new InputStreamReader(new FileInputStream("e:/website.log"),"UTF-8"));
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void close() {
try {
if (reader != null) {
reader.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void activate() {
}
@Override
public void deactivate() {
}
private String str;
@Override
public void nextTuple() {
try {
while((str = reader.readLine()) != null){
collector.emit(new Values(str));
Thread.sleep(500);
}
} catch (Exception e) {
}
}
@Override
public void ack(Object msgId) {
}
@Override
public void fail(Object msgId) {
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("log"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
(2)创建数据处理pvbolt1
package com.atguigu.storm.pv;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.IRichBolt;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
public class PVBolt1 implements IRichBolt {
private static final long serialVersionUID = 1L;
private OutputCollector collector;
private long pv = 0;
@SuppressWarnings("rawtypes")
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
// 获取传递过来的数据
String logline = input.getString(0);
// 截取出sessionid
String session_id = logline.split("\t")[1];
// 根据会话id不同统计pv次数
if (session_id != null) {
pv++;
}
//提交
//为什么这里还要加上线程数?因为上面的图中可以看到多个线程发送
//加起来,那我怎么知道最后哪个是哪个?就直接+肯定是错误的。
//每个线程监控自己的pv
//在后面的bolt中创建四个key,如果线程id相同就
//把原来的覆盖掉,然后将第二个bolt中的四个进行求和
//简单的图示往下看
collector.emit(new Values(Thread.currentThread().getId(), pv));
System.err.println("threadid:" + Thread.currentThread().getId() + " pv:" + pv);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("thireadID", "pv"));
}
@Override
public void cleanup() {
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
(3)创建PVSumBolt
package com.atguigu.storm.pv;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.IRichBolt;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.tuple.Tuple;
public class PVSumBolt implements IRichBolt {
private static final long serialVersionUID = 1L;
private Map<Long, Long> counts = new HashMap<>();
@SuppressWarnings("rawtypes")
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
}
@Override
public void execute(Tuple input) {
//累加求和业务
//获取新数据
Long threadID = input.getLong(0);
Long pv = input.getLong(1);
//替换原来的线程的pvnum
//因为每次过来都是新的数据,直接替换
//每个线程中对应的map的value的值即可
counts.put(threadID, pv);
//累加之间需要先清空
//这里为什么不放在方法外面?
//因为下面要对四个线程中的数据进行累加,如果放在外面的话
//这个就成了全局的就不对了。
//应该表示成单个线程对应的pv数量。
long word_sum = 0;
//累加求和
Iterator<Long> iterator = counts.values().iterator();
//对于当前的例子是4个
while (iterator.hasNext()) {
word_sum += iterator.next();
}
System.err.println("pv_all:" + word_sum);
}
@Override
public void cleanup() {
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
(4)驱动
package com.atguigu.storm.pv;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.topology.TopologyBuilder;
public class PVMain {
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("PVSpout", new PVSpout(), 1);
builder.setBolt("PVBolt1", new PVBolt1(), 4).shuffleGrouping("PVSpout");
builder.setBolt("PVSumBolt", new PVSumBolt(), 1).shuffleGrouping("PVBolt1");
Config conf = new Config();
conf.setNumWorkers(2);
if (args.length > 0) {
try {
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
}else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("pvtopology", conf, builder.createTopology());
}
}
}
(5)测试,执行程序输出如下结果
threadid:161 pv:1
pv_all:1
threadid:164 pv:1
pv_all:2
threadid:161 pv:2
pv_all:3
threadid:172 pv:1
pv_all:4
threadid:164 pv:2
pv_all:5
threadid:164 pv:3
pv_all:6
threadid:162 pv:1
pv_all:7
threadid:161 pv:3
pv_all:8
threadid:172 pv:2
pv_all:9
threadid:164 pv:4
pv_all:10
threadid:162 pv:2
pv_all:11
threadid:172 pv:3
pv_all:12
threadid:164 pv:5
pv_all:13
threadid:164 pv:6
pv_all:14
threadid:161 pv:4
pv_all:15
threadid:161 pv:5
pv_all:16
threadid:164 pv:7
pv_all:17
threadid:172 pv:4
pv_all:18
threadid:172 pv:5
pv_all:19
threadid:161 pv:6
pv_all:20
threadid:162 pv:3
pv_all:21
threadid:164 pv:8
pv_all:22
threadid:172 pv:6
pv_all:23
threadid:164 pv:9
pv_all:24
threadid:161 pv:7
pv_all:25
threadid:162 pv:4
pv_all:26
threadid:162 pv:5
pv_all:27
threadid:162 pv:6
pv_all:28
threadid:164 pv:10
pv_all:29
threadid:161 pv:8
pv_all:30

这也说明了是将四个累加,最后进行了汇总
5.4.3 实时计算网站UV去重案例
1)需求:
统计网站UV。
2)需求分析
方案一:
把ip放入Set实现自动去重,Set.size() 获得UV(分布式应用中不可行)
方案二:
UVBolt1通过fieldGrouping
进行多线程局部汇总,下一级UVSumBolt进行单线程全局汇总去重。按ip地址统计UV数。
既然去重,必须持久化数据:
(1)内存:数据结构map
(2)no-sql分布式数据库,如Hbase

3)案例实操
(1)创建带ip地址的数据源GenerateData
package com.atguigu.storm.uv;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Random;
public class GenerateData {
public static void main(String[] args) {
// 创建文件
File logFile = new File("e:/website.log");
// 判断文件是否存在
if (!logFile.exists()) {
try {
logFile.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}
Random random = new Random();
// 1 网站名称
String[] hosts = { "www.atguigu.com" };
// 2 会话id
String[] session_id = { "ABYH6Y4V4SCVXTG6DPB4VH9U123", "XXYH6YCGFJYERTT834R52FDXV9U34",
"BBYH61456FGHHJ7JL89RG5VV9UYU7", "CYYH6Y2345GHI899OFG4V9U567", "VVVYH6Y4V4SFXZ56JIPDPB4V678" };
// 3 访问网站时间
String[] time = { "2017-08-07 08:40:50", "2017-08-07 08:40:51", "2017-08-07 08:40:52", "2017-08-07 08:40:53",
"2017-08-07 09:40:49", "2017-08-07 10:40:49", "2017-08-07 11:40:49", "2017-08-07 12:40:49" };
// 3 访问网站时间
String[] ip = { "192.168.1.101", "192.168.1.102", "192.168.1.103", "192.168.1.104", "192.168.1.105",
"192.168.1.106", "192.168.1.107", "192.168.1.108" };
StringBuffer sb = new StringBuffer();
for (int i = 0; i < 30; i++) {
sb.append(hosts[0] + "\t" + session_id[random.nextInt(5)] + "\t" + time[random.nextInt(8)] + "\t"
+ ip[random.nextInt(8)] + "\n");
}
// 写数据
try {
FileOutputStream fs = new FileOutputStream(logFile);
fs.write(sb.toString().getBytes());
fs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
(2)创建接收数据UVSpout
package com.atguigu.storm.uv;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Map;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.IRichSpout;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
public class UVSpout implements IRichSpout{
private static final long serialVersionUID = 1L;
private SpoutOutputCollector collector ;
private BufferedReader reader;
@SuppressWarnings("rawtypes")
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
try {
reader = new BufferedReader(new InputStreamReader(new FileInputStream("e:/website.log"),"UTF-8"));
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void close() {
try {
if (reader != null) {
reader.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void activate() {
}
@Override
public void deactivate() {
}
private String str;
@Override
public void nextTuple() {
try {
while((str = reader.readLine()) != null){
collector.emit(new Values(str));
Thread.sleep(500);
}
} catch (Exception e) {
}
}
@Override
public void ack(Object msgId) {
}
@Override
public void fail(Object msgId) {
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("log"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
(3)创建[UVBolt1]{.underline}
package com.atguigu.storm.uv;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
public class UVBolt1 extends BaseRichBolt {
private static final long serialVersionUID = 1L;
private OutputCollector collector;
@SuppressWarnings("rawtypes")
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
// 1 获取传递过来的一行数据
String line = input.getString(0);
// 2 截取
String[] splits = line.split("\t");
String ip = splits[3];
// 3 发射
collector.emit(new Values(ip, 1));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "num"));
}
}
(4)创建UVSumBolt
package com.atguigu.storm.uv;
import java.util.HashMap;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
public class UVSumBolt extends BaseRichBolt {
private static final long serialVersionUID = 1L;
private Map<String, Integer> map = new HashMap<String, Integer>();
@SuppressWarnings("rawtypes")
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
}
@Override
public void execute(Tuple input) {
// 1 获取传递过来的数据
String ip = input.getString(0);
Integer num = input.getInteger(1);
// 2 累加单词
if (map.containsKey(ip)) {
Integer count = map.get(ip);
map.put(ip, count + num);
} else {
map.put(ip, num);
}
System.err.println(Thread.currentThread().getId() + " ip:" + ip + " num:" + map.get(ip));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
(5)创建UVMain驱动
package com.atguigu.storm.uv;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.topology.TopologyBuilder;
public class UVMain {
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("UVSpout", new UVSpout(),1);
builder.setBolt("UVBolt1", new UVBolt1(),4).shuffleGrouping("UVSpout");
builder.setBolt("UVSumBolt", new UVSumBolt(), 1).shuffleGrouping("UVBolt1");
Config conf = new Config();
conf.setNumWorkers(2);
if (args.length > 0) {
try {
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
}else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("uvtopology", conf, builder.createTopology());
}
}
}
(6)测试
136 ip:192.168.1.101 num:1
136 ip:192.168.1.107 num:1
136 ip:192.168.1.108 num:1
136 ip:192.168.1.103 num:1
136 ip:192.168.1.105 num:1
136 ip:192.168.1.102 num:1
136 ip:192.168.1.103 num:2
136 ip:192.168.1.101 num:2
136 ip:192.168.1.107 num:2
136 ip:192.168.1.105 num:2
136 ip:192.168.1.101 num:3
136 ip:192.168.1.108 num:2
136 ip:192.168.1.108 num:3
136 ip:192.168.1.105 num:3
136 ip:192.168.1.101 num:4
136 ip:192.168.1.108 num:4
136 ip:192.168.1.102 num:2
136 ip:192.168.1.104 num:1
136 ip:192.168.1.103 num:3
136 ip:192.168.1.106 num:1
136 ip:192.168.1.105 num:4
136 ip:192.168.1.101 num:5
136 ip:192.168.1.102 num:3
136 ip:192.168.1.108 num:5
136 ip:192.168.1.103 num:4
136 ip:192.168.1.107 num:3
136 ip:192.168.1.102 num:4
136 ip:192.168.1.104 num:2
136 ip:192.168.1.105 num:5
136 ip:192.168.1.104 num:3
测试结果:一共8个用户,101:访问5次;102访问:4次;103:访问4次;104:访问3次;105:访问5次;106:访问1次;107:访问3次;108:访问5次;
下小节案例分析
网吧案例(犯罪嫌疑人)

第一列:rowkey
第二列:网吧编号
第三列:身份证号
第四列:姓名
第五列:行政区号
第六列:上机时间
第七列:下机时间
需求1:网吧关系
1同地区同网吧相遇五次,即上机时间在两小时之内为相遇(上机时间间隔两小时是所有关系的限制条件)
2同地区、不同网吧相遇三次
3不同地区、网吧各两次
注意:
1 不要把snappy解压出来
2 把压缩动态库考入lib/native目录下
3 配置Mapreduce使之支持压缩
一定要备份虚拟机(选择其中一套进行操作,扩展硬盘最大大小到100g)
4 测试阶段,建议拷贝1 2 个,snappy即可。