【论文阅读】结合检测和跟踪进行视频中的人体姿势估计(Combining detection and tracking for human pose estimation in videos)
文章目录
- 摘要
- 一、介绍
-
- (1)本文方法
- (2)本文贡献
- 二、相关工作
-
- (1)图片中的人类姿态估计
- (2)视频中的人类姿态估计和追踪
- 三、方法
-
- (1)剪辑跟踪网络
- (2)视频跟踪网络
- (3)姿态假设的时空融合
- 四、实验
-
- (1)数据集和评估
- (2)实施细节
- (3)与最新技术的比较
- (4)方法分析
- 五、结论
- 六、个人思考
- 参考
论文原文地址
摘要
我们提出了一种新颖的自上而下的方法,可以解决视频中多人人体姿势估计和跟踪的问题。 与现有的自上而下的方法相反,我们的方法不受其人员检测器性能的限制,并且可以预测未定位的人员实例的姿势。 它通过在时间上向前和向后传播已知人员的位置并搜索那些区域中的姿势来实现此功能。
我们的方法包括三个部分:
(i)一个剪辑跟踪网络,可以对小视频剪辑同时执行人体关节检测和跟踪;
(ii)视频跟踪管道,该视频跟踪管道将剪辑跟踪网络产生的固定长度的小轨道合并到任意长度的轨道中;
(iii)时空合并程序,可根据空间和时间平滑项精炼关节位置。
得益于我们的剪辑跟踪网络和合并程序的精确性,我们的方法可以产生非常准确的联合预测,并且可以解决棘手的场景(如纠缠不清的人)时的常见错误。 我们的方法在PoseTrack 2017和2018数据集上以及针对所有自上而下和自下而上的方法上实现了联合检测和跟踪方面的最新结果。
一、介绍
-
多人人体姿势跟踪是检测所有视频帧中所有人的身体关节并随着时间的推移正确链接它们的双重任务。在过去的几年中[4、5、7、14、16、21、22、24、30、33],检测身体关节的能力得到了很大的改善,这要归功于诸如 MPII [4]和MS COCO [19]这样的大规模数据集。 根据操作方式的不同,这些方法大致可分为两类:自下而上的方法[4、5、16、21、24、33]首先检测单个的身体关节,然后将其分组为人。 自上而下的方法[7、14、30]首先会检测图像中的每个人,然后预测其边界框内每个人的身体关节。
-
近几年关节检测论文
- [4] Mykhaylo Andriluka, Leonid Pishchulin, Peter Gehler, andBernt Schiele. 2d human pose estimation: New benchmarkand state of the art analysis. InCVPR, 2014.
- [5] Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh.Realtime multi-person 2d pose estimation using part affinityfields. InCVPR, 2017.
- [7] Yilun Chen, Zhicheng Wang, Yuxiang Peng, ZhiqiangZhang, Gang Yu, and Jian Sun. Cascaded pyramid networkfor multi-person pose estimation. InCVPR, 2018.
- [14] Kaiming He, Georgia Gkioxari, Piotr Doll ́ar, and Ross Gir-shick. Mask r-cnn. InICCV, 2017.
- [16] Eldar Insafutdinov, Leonid Pishchulin, Bjoern Andres,Mykhaylo Andriluka, and Bernt Schiele.Deepercut: Adeeper, stronger, and faster multi-person pose estimationmodel. InECCV, 2016.
- [22] Alejandro Newell, Kaiyu Yang, and Jia Deng. Stacked hour-glass networks for human pose estimation. InECCV, 2016.
- [24] Leonid Pishchulin, Eldar Insafutdinov, Siyu Tang, BjoernAndres, Mykhaylo Andriluka, Peter V Gehler, and BerntSchiele. Deepcut: Joint subset partition and labeling formulti person pose estimation. InCVPR, 2016.
- [30] Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. Deephigh-resolution representation learning for human pose esti-mation. InCVPR, 2019.
- [33] Shih-En Wei, Varun Ramakrishna, Takeo Kanade, and YaserSheikh. Convolutional pose machines. InCVPR, 2016
-
自上而下的方法
- [7] Yilun Chen, Zhicheng Wang, Yuxiang Peng, ZhiqiangZhang, Gang Yu, and Jian Sun. Cascaded pyramid networkfor multi-person pose estimation. InCVPR, 2018.
- [14] Kaiming He, Georgia Gkioxari, Piotr Doll ́ar, and Ross Gir-shick. Mask r-cnn. InICCV, 2017.
- [30] Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. Deephigh-resolution representation learning for human pose esti-mation. InCVPR, 2019.
-
自下而上的方法
- [25] Yaadhav Raaj, Haroon Idrees, Gines Hidalgo, and YaserSheikh. Efficient online multi-person 2d pose tracking withrecurrent spatio-temporal affinity fields. InCVPR, 2019. - 该方法最近在视频的检测中。
(1)本文方法
我们的想法是,如果一个人出现在框架中的特定位置,即使检测器无法找到它们,他们也仍应该位于邻近框架中的那个位置附近。 视频中的时间管以该帧和位置为中心。 然后,我们将此管送入一个新颖的剪辑跟踪网络,该网络会估计该人在管的所有框架中所有身体关节的位置。 为了解决此任务,我们的剪辑跟踪网络同时执行人体关节检测和跟踪。 这有两个好处:(i)通过共同解决这些任务,我们的网络可以更好地处理独特的姿势和遮挡,并且(ii)通过预测时空管所有帧中的关节(甚至对于未检测到人物的镜框。 为了构建此剪辑跟踪网络,我们使用经过精心设计以帮助获得关节之间时间对应的3D卷积,将最新的高分辨率网络(HRNet)[30]体系结构扩展到跟踪任务。
剪辑跟踪网络对固定长度的视频剪辑进行操作,并生成多人姿势小轨迹。 通过首先生成临时重叠的小轨迹,然后在小轨迹重叠的帧中关联和合并姿势检测,将这些小轨迹组合为视频跟踪管道中任意长度视频的姿势轨迹。 当将小轨迹合并到轨迹中时,我们在基于共识的新型时空合并过程中,在每个帧中使用多个姿势检测来估计每个关节的最佳位置。 此过程支持在空间上彼此靠近且暂时平滑的假设。 这种组合能够纠正高度纠缠的人的错误,导致更准确的预测,如图6的第67帧所示 图一:当[30]错误地选择了黄色球员的左膝盖作为绿色球员右膝盖的预测(1a),我们的程序能够纠正此错误并预测正确的位置。

(2)本文贡献
(i)新颖的剪辑跟踪网络(第3.1节)
(ii)跟踪管道(第3.2节)
(iii)时空合并过程(第3.3节)。
二、相关工作
(1)图片中的人类姿态估计
-
最近的人体姿势估计方法可以根据其操作方式分为自下而上和自上而下的方法。自下而上的方法[5、16、21、24]首先检测人体的各个关节,然后将它们分组为人。 另一方面,自上而下的方法[7,14,23,30],首先检测人的边界框,然后预测他们在每个区域内的联合位置。
-
两种方法优劣:
自上而下的方法受到人体检测器的局限性:当检测器发生故障时(即,未定位每个儿子),无法恢复该人的关节。 自下而上的方法不依赖检测器,它们可以预测任何关节。 但是,它们承受了跨大型变化和关节分组进行关节检测的艰巨任务。 -
本文想法
在这项工作中,我们尝试充分利用这两个方法的优势,并提出一种新颖的自上而下的视频处理方法,该方法通过暂时探索和传播信息来的方式来从检测器中恢复检测失误。 -
本文基于Sun等人的HRNet [30]。 这最初是为人体姿势估计提出的,可实现图像的最新结果。 最近,对它进行了修改,以在其他视觉任务上获得最新的结果,例如对象检测[31]和语义分割[32]。 在本文中,我们展示了如何将HRNet扩展到视频中的人体姿势估计和跟踪
[30] Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. Deephigh-resolution representation learning for human pose esti-mation. InCVPR, 2019.
(2)视频中的人类姿态估计和追踪
-
自下而上的方法
给定刚刚介绍的图像方法,很自然地可以将它们扩展到视频中的多人姿势跟踪,方法是在每个帧上独立运行它们,然后随着时间的推移链接这些预测。 沿着这些思路,自下而上的方法[17,25]在检测到的关节之间建立了时空图。 Raaj等 [25]通过扩展曹等人的空间亲和场图像工作做到了这一点。 [5]时空亲和力场(STAF),而金等[17]扩展了Newell等人的空间关联嵌入图像工作[21]到时空嵌入中。
[17] Sheng Jin, Wentao Liu, Wanli Ouyang, and Chen Qian.Multi-person articulated tracking with spatial and temporalembeddings. InCVPR, 2019.
[25] Yaadhav Raaj, Haroon Idrees, Gines Hidalgo, and YaserSheikh. Efficient online multi-person 2d pose tracking withrecurrent spatio-temporal affinity fields. InCVPR, 2019.
[5] Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh.Realtime multi-person 2d pose estimation using part affinityfields. InCVPR, 2017.
[21] Alejandro Newell, Zhiao Huang, and Jia Deng. Associa-tive embedding: End-to-end learning for joint detection andgrouping. InNIPS, 2017. -
自上而下的方法
另一方面,自上而下的方法[13,34]在人的边界框之间建立时间图,通常更容易解决。 简单基线[34]首先在每个帧上独立运行一个人体检测器,然后将其检测结果链接到一个图形中,其中时间相似性是使用昂贵的光流定义的。 Detect-and-Track [13]改为使用3D Mask R-CNN方法检测短视频剪辑中人的关节,然后使用轻型跟踪器通过比较检测到的边界框的位置将连续的剪辑链接在一起。 [13],我们的方法也可以在单向前通过中对短片段进行推理,但是它具有很多优势:(i)作为大多数自上而下的方法,[13]受其检测器精度的限制,无法从中恢复 错过 相反,我们建议将检测到的边界框传播到相邻帧,并在那些区域中寻找失踪人员。 (ii)[13]在非重叠剪辑上运行,并且仅基于人员边界框执行跟踪; 取而代之的是,我们在重叠的片段上运行,并在新颖的跟踪系统中使用多个联合假设,从而得出更准确的预测。 (iii)[13]使用了完全3D卷积网络,而我们证明仅在网络的一部分上的3D过滤器已经足以教导网络进行跟踪。
[13] Rohit Girdhar, Georgia Gkioxari, Lorenzo Torresani,Manohar Paluri, and Du Tran. Detect-and-Track: EfficientPose Estimation in Videos. InCVPR, 2018.
[34] Bin Xiao, Haiping Wu, and Yichen Wei. Simple baselinesfor human pose estimation and tracking. InECCV, 2018.
三、方法
- 从高层次上讲,我们的方法通过首先在每个视频剪辑的中心帧(即关键帧)中检测所有候选人员,然后及时估计他们的姿势来实现。 然后,它将来自不同剪辑的时空中的姿势合并在一起,生成任意长度的轨迹。更详细地说,我们的方法包括三个主要组件:剪切,缝合和抛光。 给定一个视频,我们首先将其切成重叠的片段,然后在其关键帧上运行人检测器。 对于在关键帧中检测到的每个人的边界框,在对应剪辑上方的边界框位置处截取一个时空管。 给定这个管作为输入,我们的剪辑跟踪网络都估计关键帧中中心人物的姿势,并在整个视频剪辑中跟踪他的姿势(第3.1节,图2)。 我们称这些为小轨道。 接下来,我们的视频跟踪管道工作是作为裁缝,根据重叠帧的姿势将这些小轨迹缝制在一起(第3.2节,图3)。 最后,我们在相同的框架假设中将这些姿势称为同一姿势。最后,时空合并使用这些假设在优化算法中对这些谓词进行修饰,该算法为每个关节选择时空上更一致的位置(第3.3节,图4) 在接下来的三个部分中,我们将详细介绍这三个组件。
(1)剪辑跟踪网络

我们的剪辑跟踪网络在短视频剪辑上同时执行姿势估计和跟踪。 它的体系结构建立在Sun等人 [30]成功的HRNet体系结构的基础上。在下一段中,我们总结了原始的HRNet设计,在下一段中,我们解释了如何将其扩展到跟踪。
用于图像中的人体姿势估计的HRNet。
给定一个图像,这种自上而下的方法将在人体检测器上运行,该检测器将输出一个与轴对齐的边界框列表,每个定位框对应一个人。 这些盒子中的每一个都独立种植,并送入HRNet,后者由四个并行子网的四个阶段组成,这些子网经过训练以定位作物中仅中央人物的所有人的关节。
HRNet的输出是一组热图,每个人体关节一个。 这些热图的每个像素都表示“包含”关节的可能性。与文献[5、7、14、16、21、24]中的其他方法一样,网络在被预测的热图 H p r e d H^{pred} Hpred和真实的热图 H g t H^{gt} Hgt之间使用均方误差损失函数训练。

其中K是身体关节(关键点)的数量,i,j是像素坐标。 H g t H^{gt} Hgt是通过在每个关节的带注释位置上卷积2D高斯滤波器而生成的。
用于视频姿态估计和跟踪的3D HRNet
我们的方法适用于短视频剪辑: C = F t − δ , . . . , F t , . . . , F t + δ C = {F^{t-δ},...,F^t,...,F^{t +δ}} C=Ft−δ,...,Ft,...,Ft+δ。 首先,它在中心框架 F t F^t Ft上运行人检测器,并获得人边界框 B t = { β 1 t , . . . , β n t } B^t = \{β^t_1,...,β^t_n\} Bt={ β1t,...,βnt}的列表(图2a)。 然后,对于每个边界框 β p t β^t_p βpt,它通过从剪辑C中的所有帧中裁剪框区域来创建管 T β p t : T β p t = { F β p t t − δ , . . . , F β p t t , . . . , F β p t t + δ } T_{β^t_p}:T_{β^t_p}= \{F^{t-δ}_{β^t_p},...,F^{t}_{β^t_p},...,F^{t+δ}_{β^t_p}\} Tβpt:Tβpt={ Fβptt−δ,...,Fβptt,...,Fβptt+δ}(图2b)。 接下来,它将这个管子馈送到我们的视频HRNet中,该视频将在该管子的所有帧中放置包含人p的所有姿势的跟踪让: P β p t = ρ β p t t − δ , . . . , ρ β p t t , . . . , ρ β p t t + δ P_{β^t_p}= {ρ^{t-δ}_{β^t_p},...,ρ^{t}_{β^t_p},...,ρ^{t+δ}_{β^t_p} } Pβpt=ρβptt−δ,...,ρβptt,...,ρβptt+δ(图2c)。重要的是,即使 P β p t P_{β^t_p} Pβpt中的所有姿势都被遮挡或移出管架,该姿势也必须属于同一个人(在这种情况下,即使存在其他人,网络也不应输出任何预测)。 这是一项艰巨的任务,需要网络既要学习预测姿势关节的位置,又要随着时间跟踪它们。
为了帮助网络应对这一挑战,我们做两件事:(i)考虑到快速移动的人员,我们在制作管之前沿两个方向将每个边界框扩大了25%; (ii)为了使网络在框架之间关联人员,我们将HRNet的前两个阶段中的2D卷积膨胀为3D,以帮助网络学习跟踪。 具体来说,在第一阶段中,我们使用3×1×1、1×3×3和1×1×1滤镜,而在第二阶段中,我们使用3×3×3滤镜。 在第二阶段之后,网络将形成一个感知场,该感知场在时间上足够大,可以观察到整个管子,了解人的外表及其在管中的运动。 值得一提的是我们的方法与Jin等人[17]的时间关联嵌入方法有何相似之处,但它是由网络自动学习的,不需要额外的约束。最后,我们以和公式1相等的的均方损失训练视频HRNet,但现在计算剪辑C中的所有帧时:

为了帮助网络应对这个挑战,我们做了两件事:(1)考虑到快速移动的人,在创建管之前,我们将每个边界框在两个维度上都放大了25%;(ii)为了让网络在帧之间关联人员,我们将HRNet的前两个阶段的2D卷积扩展为3D,以帮助网络学会跟踪。具体来说,在第一阶段我们使用3×1×1、1×3×3和1×1×1的过滤器,而在第二阶段我们使用3×3×3的过滤器。在第二阶段之后,神经网络有一个暂时足够大的接受野,可以观察整个管道,了解人的外表和他/她在其中的动作。请注意,我们的方法在精神上与Jin等人[17]提出的时间关联嵌入方法相似,但它是由网络自动学习的,不需要额外的约束。最后,我们用eq. 1的平均平方损失来训练我们的视频HRNet,但是现在对剪辑C中的所有帧进行计算:
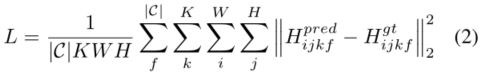

(2)视频跟踪网络
我们的剪辑跟踪网络为定位在 β P β_P βP的每个人P输出一个轨迹 P β p t P_{β^t_p} Pβpt。然而,P可能存在于长度 P β p t P_{β^t_p} Pβpt之外,并且我们的视频跟踪管道的职责是合并属于同一个人的轨迹,从而能够在任意长度的视频上进行姿势估计和跟踪(图3)。我们的管道合并两个固定长度的轨迹,如果它们在重叠帧上的预测姿态相似(例如,在图3中, P β 1 2 和 P β 1 4 P_{β_1^2} 和 P_{β_1^4} Pβ12和Pβ14重叠在2-4帧上)。
我们通过在长度为|C|的片段上运行我们的剪辑跟踪网络,从每S帧(stepsize)以S<|C|采样的关键帧生成这些重叠的轨迹。
我们将属于同一个人的轨迹合并问题建模为基于二部图的能量最小化问题,我们使用匈牙利算法[18]来解决该问题。作为两个重叠轨迹之间的相似函数,我们计算它们在重叠帧上的姿势(重新投影到原始坐标空间,图2d)之间的对象关键点相似性(OKS)[19,27]。例如,在图3中,轨迹 P β 3 6 和 P β 1 8 P_{β^6_3}和P_{β^8_1} Pβ36和Pβ18分别在从关键帧6和10生成的管上计算,长度为|C|=5。在这些设置下,这些轨迹都可以预测第6、7和8帧的姿势,它们的相似性计算为这三帧的平均OKS。另一方面,轨迹 P β 3 6 和 P β 2 2 P_{β^6_3}和P_{β^2_2} Pβ36和Pβ22只在第4帧上重叠,因此它们的相似性计算为该单个帧上的OKS。最后,我们把这个OKS相似性的负值作为我们的最小化问题。
注意这个公式是如何克服自上而下方法通常遭受的限制:错过边界盒检测。由于我们将人的检测从关键帧传播到它们的相邻帧(图2b),我们能够获得即使对于那些丢失检测帧的关节预测。例如,在图3中,人物检测器未能定位关键帧4中的绿色人物,但是通过传播来自关键帧2和6的检测,我们也能够获得帧4的姿势估计。此外,由于这两个轨迹之间的重叠,我们也能够正确地链接这些轨迹。

(3)姿态假设的时空融合
我们的视频跟踪管道合并了轨迹,但它不处理合并人体姿势。例如,在图3中,该方法正确地链接了所有黄色轨迹,但它没有解决如何处理第4帧的多个姿势估计的问题(即, ρ β 1 2 4 、 ρ β 1 4 4 和 ρ β 2 6 4 ρ^4_{β^2_1}、ρ^4_{β^4_1}和ρ^4_{β^6_2} ρβ124、ρβ144和ρβ264)。在这一节中,我们提出了解决这个问题的方法。
给定一组合并的、重叠的p个人轨迹,我们定义 H p t = { ρ β p t − δ t , . . . , ρ β p t t , . . . , ρ β p t + δ t } H^t_p = \{\rho^t_{\beta^{t-\delta}_p},...,\rho^t_{\beta^{t}_p},...,\rho^t_{\beta^{t+\delta}_p} \} Hpt={ ρβpt−δt,...,ρβptt,...,ρβpt+δt},作为在时间t的姿态假设。 H p t H^t_p Hpt预呈现了p个人的姿势集合,由我们的剪辑跟踪网络在时间t通过在不同的关键帧上运行的管状作物生成。要获得每个人的最终姿势,最简单的方法就是为每个关节选择置信度最高的假设 H p t H^t_p Hpt。我们称之为基线合并,正如我们稍后在实验中表明,它取得了具有竞争力的性能,已经凸显了我们的剪辑跟踪网络的威力。然而,程序偶尔也会预测失误,当感兴趣的人被其他的人缠住或堵住的时候,如图4d所示。
为了克服这些局限性,我们提出了一种新的方法来合并这些假设(图4b-c)。我们的直觉是关节的最佳位置应该是在一个帧内的多个候选帧之间一致(空间约束)和连续帧上一致(时间约束)。我们将预测每个帧中每个关节的最佳位置的问题建模为最短路径问题,并使用Dijkstra算法进行求解[10]。我们没有将每个联合检测视为图中的一个节点,而是对通过在联合假设上运行mean-shift算法得到的簇进行操作[8]。这种聚类可以很好地平滑单个假设中的噪声,同时还可以减小图的大小,从而加快优化速度。作为连续帧中簇cta和ct+1之间的一个相似函数φ,我们计算了一个时空加权函数,它遵循了上述直觉:它有利于具有更多假设的簇和那些在时间上运动更平滑的簇。
形式上:

其中µ(ct),µ(ct+1)是簇中心的位置,| ct |,| ct+1 |它们的大小和| H |假设的数量。最后,我们使用λ来平衡这些空间和时间约束。
四、实验
(1)数据集和评估
我们用PoseTrack[3]进行了实验,这是一个大规模的视频人体姿态估计和跟踪基准。它包含了一系列具有挑战性的高清晰度人群在密集的人群中表演各种各样的活动。我们对这个基准的2017和2018版本进行了实验。PoseTrack2017包含250个用于培训的视频,50个用于验证,214个用于测试。PoseTrack2018进一步增加了2017年版本的视频数量,共593个用于培训,170个用于验证,375个用于测试。这些数据集用15个身体关节进行注释,每个关节都被定义为一个点,并与一个唯一的人id相关联。训练视频用30帧的单一密集序列进行注释,同时验证视频还为每四帧提供注释,以便评估远程跟踪。
[3] Mykhaylo Andriluka, Umar Iqbal, Eldar Insafutdinov, Leonid Pishchulin, Anton Milan, Juergen Gall, and Bernt Schiele. PoseTrack: A benchmark for human pose estimation and tracking. In CVPR, 2018.
我们使用标准的人体姿势估计[19,24,27]和跟踪[3,20]指标评估我们的模型:联合检测性能用平均精度(AP)表示,跟踪性能用多目标跟踪精度(MOTA)表示。我们在每个身体关节上独立计算这些指标,然后通过对关节的平均值来获得我们的最终性能。正如文献[13,30,34]中所做的那样,当我们对这些数据集的验证集进行评估时,我们计算了所有局部身体关节的AP,但是我们在计算MOTA之前对低置信度的预测设置了阈值。在我们的实验中,我们在训练集的保持集上学习每个关节的阈值。此外,我们经常把这些短的轨迹(<5帧),小的背景框(W*H < 3200)(这些通常捕捉不到标签)和一些在背景中的人移走。
(2)实施细节
-
3d视频HRNet
在将2D HRNet膨胀到3D版本之前,我们在PoseTrack数据集上对其进行图像姿势估计预训练(2017或2018年,取决于我们评估模型的集合)。这一步使网络能够学习定位身体关节的任务,以便在视频训练期间集中学习跟踪。我们使用“mean”初始化[6,12,13]对HRNet的前两个阶段进行膨胀,它复制2D过滤器并相应地对其进行规范化。我们使用步长S=1,因为它产生了最多数量的姿势假设,以及|C|=9帧的剪辑,因此模型可以从重要的时间信息中获益。我们使用了[30]中相同的高度计,但是我们训练了20个epoch的3D-HRNet,并在10个和15个周期后,分别以(1e-4→1e-5→1e-6)降低了两倍的学习率。最后,在推理过程中,我们遵循[30,34]的过程:我们同时对原始图像和翻转图像运行,并平均它们的heatmap。 -
行人检测器
我们使用ResNet-101狙击手探测器来定位所有的person实例。我们在MS COCO 2017数据集[19]上对其进行了培训,并在COCO minival上实现了“person”类的57.9的AP,这与其他自上而下的方法相似[34,36]。 -
合并姿态假设
我们遵循PoseTrack评估过程来确定集群的大小估计值。如果预测与最接近的地面真实情况之间的距离在定义为该人头部大小50%的半径内,则该程序将正确地考虑该预测。我们对我们的星团使用相同的半径。此外,我们将λ=0.1设为对空间和时间分量同等重要,因为后者的大小约为前者的10倍。
(3)与最新技术的比较
我们将我们的方法与文献中有关人体关节检测和跟踪的最新方法(SOTA)进行比较,这些方法是在PoseTrack2017(表1和表2)和PoseTrack2018(表3和表4)的验证集上进行的。我们的方法在两个度量、两个数据集以及自顶向下和自底向上方法上都能获得SOTA结果。在某些情况下,相对于SOTA的改进是显著的:PoseTrack2017上的mAP为6.5(误差减少率为28%),PoseTrack2018的MOTA为+3.0(误差减少为9%)。与仅自上而下的方法(这是该方法所属的类别)相比,MOTA的改进更为显著,比上一次PoseTrackChallenge(FlowTrack,65.4 vs 71.6)高出PoseTrack2017的+6.2(误差减少18%),显示了同时执行联合检测和跟踪的重要性。
下一步,我们评估我们的方法在PoseTrack 2017(表5)和PoseTrack 2018(表6)的测试集上。这些集合的注释是私有的,我们通过向评估服务器提交我们的预测结果[1]。同样,我们的方法在两个测试集(+3 MOTA)上都取得了最好的跟踪结果,并且在联合检测方面与SOTA的结果不相上下,尽管我们的模型实际使用的数据少于PoseTrack2018上的竞争对手。
(4)方法分析
我们现在分析我们的方法和超参数选择。为了简单起见,我们只在PoseTrack2017的验证集上运行我们的实验,使用第4.2节中描述的设置。除非特别说明,我们不使用我们的时空合并程序(3.3节)保持我们的分析透明,因为这可以纠正一些错误。
-
消融研究
在这里,我们评估了方法的不同组成部分,并量化了它们对模型最终性能的贡献程度(表7)。首先,我们与一个在每个帧上独立运行的2d-hrnet模型[30]进行比较。这个基线模型实现了77.7的mAP;这比我们最基本的3D HRNet(82.3mAP)要低得多,它不执行任何跟踪,只是在假设之上使用基于OKS的NMS。这一重大改进是因为我们的模型能够预测人体探测器无法定位人体的框架中的关节。

当我们的3D HRNet与我们的视频跟踪管道和基线合并相匹配时(3.2节),它比同一个2D-HRNet基线与流行的基于OKS的贪婪二部匹配(OKS-gbm)算法相匹配(OKS-gbm)相比,它大大提高了MOTA的性能[13,34]。有趣的是,这也改善了我们的三维HRNet地图没有跟踪(+0.8地图)。最后,当我们用我们的过程替换基线合并时(3.3节),结果进一步改善:空间和时间合并都是有益的和互补的,使我们的完整模型性能达到83.8 mAP和71.6 MOTA,几乎比基线提高了10%。 -
剪辑长度|C|
我们的三维HRNet在长度为| C |的时空管上运行。在4.2节,我们将这个值设置为9,这样我们的剪辑跟踪网络和视频跟踪管道都可以从丰富的时间信息中获益。在这里,我们将研究当我们改变这个超参数时性能是如何变化的(图5a)。设置| C |=1相当于运行上一节中介绍的基线2D HRNet,它在所有变体中实现了最低的性能。有趣的是,最大的改进是从1移动到3,这表明很少的时间信息已经足以补偿人检测器的许多故障。进一步增加| C |会导致mAP和MOTA的缓慢但稳定的改进,因为模型可以从更多错误中恢复。我们在图5a中定量地显示了这种恢复,其中假阴性的数量随着| C |的增加而减少。

- 步长S
在4.2节,我们将其设置为1,这样我们的方法可以使用视频的每一帧作为关键帧,并收集最大的姿势假设集。然而,对于某些应用程序来说,这个过程可能太贵了,在这里,我们通过减少关键帧的数量(即增加步长)来评估性能是如何变化的。增加S的值会导致线性速度提高一个因子S,因为我们的方法中最昂贵的两个组件(person detector和3D HRnet)现在只在每个S帧上运行。正如预期的那样,随着S的增加,联合检测和跟踪的结果(图5b)都会减少,因为模型失去了它的时间效益。然而,它们的下降速度很慢,即使我们用最大的步长进行最快的推断,该模型仍然取得了具有竞争力的性能(mAP 78.9和MOTA 67.2),与许多最先进的模型(表1)不相上下。此外,请注意这些结果如何优于我们的基线2D HRNet(地图77.7和MOTA 65.6,图5a,| C |=1),然而这种三维模型实际上更快,因为它每8帧只运行一次它的人检测器,而不是像2D HRNet那样每8帧运行一次。
- 网络设计
我们的3D HRNet架构在其早期的2个阶段使用3D卷积(3.1节),因为这些最适合学习正确连接管道内同一个人关节所需的低层对应关系。在本节中,我们将评估不同的网络设计:我们的设计(早期),一个在其最后阶段(最后一个阶段)带有三维过滤器的三维HRNet架构,它学习在小时间窗口上平滑联合预测,以及一个全3D HRNet架构(All),它良好平衡了学习的时间相关性和空间平滑关节点预测。由于训练一个完整的3D HRNet需要相当多的GPU内存,我们在这里用一个轻量级的设置来进行实验,其中| C |=3。结果见表8。作为参考,我们报告了一个没有任何3D过滤器的标准2dhrnet的mAP性能。无论位置如何,添加3D过滤器总是比简单的2D架构有所改进。在不同的选择中,“早期”在检测和跟踪方面都达到了最佳性能,验证了我们的设计。

- 对行人检测器的依赖
与所有自上而下的方法一样,我们的方法也受到行人检测器的精度的限制。然而,我们相信我们的方法比文献中的其他方法敏感得多,因为它可以使用其时间推理来恢复错过的预测。为了验证这一点,我们评估了检测盒到相邻帧的传播如何使模型提高召回率。我们在PoseTrack2018的验证集上进行了实验,因为2017年的验证集没有边界框注释。我们使用两个不同的主干,将我们的3D方法与2D方法进行比较(表9)。结果表明:(i)我们的3D方法确实可以恢复大量的未命中预测(+4-7%的召回率)和(ii)它甚至可以提高较弱的检测器(3D MobileNet-V2,recall 83)的召回率,与更强大的模型(2D ResNet-101,recall 82.9)的召回率相当。

五、结论
我们提出了一种新颖的自上而下的视频多人姿态估计和跟踪方法。我们的方法可以通过传播已知的人的位置并通过搜索其中的姿势来恢复其人检测器的故障。我们的方法包括三个部分。利用视频片段跟踪网络对小视频片段进行联合姿态估计和跟踪。然后,利用视频跟踪管道,将剪辑跟踪网络预测出的属于同一个人的轨迹进行合并。最后,基于时空一致性过程,对同一个人进行多个检测,利用时空融合来优化联合位置。我们证明了这种方法能够正确预测人的姿势,即使在包含严重遮挡和纠缠的非常困难的场景中(图6)。最后,我们通过在PoseTrack 2017和2018数据集以及针对所有自上而下和自下而上方法的联合检测和跟踪方面取得了最先进的结果,展示了我们方法的正确性。

六、个人思考
- 我们的视频跟踪管道在多个重叠帧上运行我们的剪辑跟踪网络,为一个人的每个关节(a)产生多个假设。我们将这些假设进行聚类(b),并在这些簇上解决一个时空优化问题,以估计每个关节的最佳位置(c)。这比一个简单的基线总是选择置信度最高(d)的假设更好,尤其是在有高度纠缠的人的帧上。
- 本文最大的创新点在于它不再使用置信度最高的那个点,作为姿态估计的点。而是采用聚类的办法,将很多的点,按照不同的权重聚类,最后得到一个最优点的办法,很新颖,可以尝试用在其他非目标检测的算法上。
参考
CVPR 2020 论文大盘点-人体姿态估计与动作捕捉篇