局部保留投影算法(LPP)(Locality Preserving Projections)详解
1.问题导入
2.算法出处
3.算法详解
4.算法步骤
算法全称《Locality preserving projections》出自何小飞教授论文X.He,P.Niyogi,Localitypreservingprojections,in:ProceedingsofConference
on AdvancesinNeuralInformationProcessingSystems(NIPS),2003。
改编自LE算法M.Belkin,P.Niyogi,LaplacianEigenmapsfordimensionalityreductionanddata
representation, NeuralComput.15(6)(2003)1373–1396。
1.问题导入:
降维的目的是为了缓解维数灾难,比如原始空间X=[x1,x2,...xn],每一个xi有m个维度,要将其降维到Y=[y1,y2,...,yn],每一个yi成为了m'维度(m'<
2.算法出处:
算法提出源自何小飞教授的论文《Locality preserving projections》,作者(Xiaofei He与Partha Niyogi)相比与PCA保留全局信息(可以解释为最大化方差,也可以解释为最小化重构误差,这两个点都可以得出pca的推导,可以参考南京大学周志华老师的著作西瓜书(全名机器学习))。
3.算法讲解:
lpp主要是通过线性近似le(这里le算法全称是Laplacian Eigenmaps),(出自论文Laplacian Eigenmaps and Spectral Techniques for Embedding and Clustering,作者是Mikhail Belkin and Partha Niyogi,都是芝加哥大学,数学与计算科学学院的,包括上面的何小飞教授,感觉他们三个人应该是师生关系,这个故事告诉我们,资源平台是一个很重要的事情,包括我后面看的一些降维的算法提出,很多都是在改进老师或者同门的角度来达到创新的idea的),算法来保留的是局部信息,比如在高维空间中,数据点xi和数据点xj是相邻关系,那么在降维空间后yi和yj必须跟其对应高维xi和xj的关系相同。也就是lpp的损失函数:
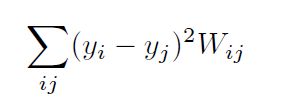
3.1此函数的物理意义是,
各符号说明:
yi表示的是降维后的任意数据点i,yj表示的是降维后的任意数据点不包含i(平方表示的是任意两个点的欧氏距离也就是任意两个数据点之间的远近关系)
Wij表示的是原始空间中ij之间的距离权重系数组成的矩阵。注意这里先介绍一下Wij的构造过程,也就是说如果i和j是k近邻关系,不论是i是j的还是j是i的,都采用下面的热核函数计算方式。如下公式,不是k近邻的形式,那么Wij就等于0;
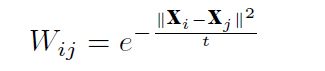
物理意义:
如果ij是近邻关系(现在假设的是降维后的空间和原始空间一样都是满足近邻关系,这里只考虑近邻关系,不考虑全局的信息),比如原始空间中i和j是比较接近的,也就是dist(xij)比较小(如果ij不是k近邻的关系,那么Wij等于零,就不需要进行计算了),那么Wij就比较大,那么为了满足min,降维后的dist(yij)就应该满足比较小的设定。相反,如果原始空间中i和j是比较远的(也就是dist(xij)比较大),那么Wij就比较小了,为了满足min,那么dist(yij)要设定为比较小的。同时,使得目标函数最小的时候就是降维效果最好的时候。
3.2公式推导:

第一步是:将欧氏距离展开;
第二部是:将权重矩阵加进去;
第三部是:分别去掉j,i这里的Dii=wij对第i行的求和,Djj是Wij对第j列的求和
第四部是:构造拉普拉斯矩阵L=D-W.
这里我没有使用xi是因为这样推导比较方便,然后转化为x的形式:
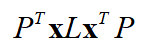
为了防止消除任意的缩放因子
最后的目标函数是:

最后转化为
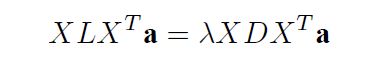
4.算法步骤:
4.1:找出k近邻:
 第一种是使用kesai球的形式寻找,也就是两点的欧氏距离满足小于某一约束就认定满足条件,这种kesai的取值难以把握。
第一种是使用kesai球的形式寻找,也就是两点的欧氏距离满足小于某一约束就认定满足条件,这种kesai的取值难以把握。
第二种是直接计算xi点与xi之外的所有的点的欧氏距离,然后进行排序,找出距离最近的k个点。这种比较实在,而且使用matlab的find__nn函数可以很容易找到。
4.2计算权重:

第一个就是热核函数,这样做的目的就是当xi和xj的欧式距离比较大的时候,Wij就对应的小,同理,如果xi和xj的距离比较小,那么对应的Wij就比较大。
第二个就是简单的形式,但是这种没有很好的区分度,相当于,如果xj是xi的k近邻的形式,那么Wij就等于1,不论xj(xj泛指xi的k近邻,并不是一个实际的点)中的点与xi的距离远近都为1,就不能很好的区分,举例一维数据点(1,2,10,11),那么对于2的k2近邻来说就是1和10了,但是明显1对2的距离肯定比10对2的距离近,如果按照第一个例子,那么W12>W32的,但是如果按照第二种,W12=W32。一般在使用的时候都是采用第一种热核函数的形式。
4.3计算投影矩阵:
根据matlab自带的eig函数计算[eigvector, eigvalue] = eig(XLX',XDX')(注:这里的‘表示的是转置的意思’);
接下来还有何小飞老师的NPE,算法,以及李乔杉老师的SPP算法,都是无监督降维领域的很经典的算法。