flume常见异常汇总以及解决方案
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
实际生产环境中,我用flume将kafka的数据定期的往hdfs集群中上传数据,也遇到过一系列的坑,我在这里做个记录,如果你也遇到同样的错误,可以参考一下我的解决方案。
1>.服务器在接收到响应之前断开连接。
报错信息如下:
Caused by: org.apache.kafka.common.errors.NetworkException: The server disconnected before a response was received.


2018-11-13 06:17:30,378 (PollableSourceRunner-KafkaSource-kafkaSource) [INFO - org.apache.kafka.clients.consumer.internals.AbstractCoordinator.coordinatorDead(AbstractCoordinator.java:529)] Marking the coordinator 2147483531 dead. Caused by: org.apache.kafka.common.errors.NetworkException: The server disconnected before a response was received. ... 6 more at org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:552) at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:25) at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:43) at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.valueOrError(FutureRecordMetadata.java:56) Caused by: java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.NetworkException: The server disconnected before a response was received. at java.lang.Thread.run(Thread.java:748) at org.apache.flume.source.PollableSourceRunner$PollingRunner.run(PollableSourceRunner.java:133) at org.apache.flume.source.AbstractPollableSource.process(AbstractPollableSource.java:60) at org.apache.flume.source.kafka.KafkaSource.doProcess(KafkaSource.java:295) at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:194) at org.apache.flume.channel.BasicTransactionSemantics.commit(BasicTransactionSemantics.java:151) at org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:561) org.apache.flume.ChannelException: Commit failed as send to Kafka failed 2018-11-13 06:17:29,376 (PollableSourceRunner-KafkaSource-kafkaSource) [ERROR - org.apache.flume.source.kafka.KafkaSource.doProcess(KafkaSource.java:314)] KafkaSource EXCEPTION, {} Caused by: org.apache.kafka.common.errors.NetworkException: The server disconnected before a response was received. at java.lang.Thread.run(Thread.java:748) at org.apache.flume.source.PollableSourceRunner$PollingRunner.run(PollableSourceRunner.java:133) at org.apache.flume.source.AbstractPollableSource.process(AbstractPollableSource.java:60) at org.apache.flume.source.kafka.KafkaSource.doProcess(KafkaSource.java:295) at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:194) at org.apache.flume.channel.BasicTransactionSemantics.commit(BasicTransactionSemantics.java:151) at org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:552) at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:25) at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:43) at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.valueOrError(FutureRecordMetadata.java:56) java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.NetworkException: The server disconnected before a response was received. 2018-11-13 06:17:29,376 (PollableSourceRunner-KafkaSource-kafkaSource) [WARN - org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:560)] Sending events to Kafka failed 2018-11-13 06:17:04,257 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.kafka.clients.consumer.internals.AbstractCoordinator.coordinatorDead(AbstractCoordinator.java:529)] Marking the coordinator 2147483529 dead. 2018-11-13 06:17:04,256 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler.handle(ConsumerCoordinator.java:542)] Offset commit for group flume-consumer-against_cheating_02 failed due to REQUEST_TIMED_OUT, will find new coordinator and retry 2018-11-13 06:16:59,150 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.kafka.clients.consumer.internals.AbstractCoordinator.coordinatorDead(AbstractCoordinator.java:529)] Marking the coordinator 2147483529 dead. 2018-11-13 06:16:59,149 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler.handle(ConsumerCoordinator.java:542)] Offset commit for group flume-consumer-against_cheating_02 failed due to REQUEST_TIMED_OUT, will find new coordinator and retry
根据报错分析,是由于时间过长导致重新均衡的,参考:https://kafka.apache.org/090/documentation/#configuration,经查阅资料应该调大以下几个参数:
注意,这个*表示的是channels的名称,这些参数不仅仅是可以给kafka channel设置,还可以给kafka source配置哟! #配置控制服务器等待追随者确认以满足生产者用acks配置指定的确认要求的最大时间量。如果超时后所请求的确认数不满足,将返回一个错误。此超时在服务器端进行测量,不包括请求的网络延迟。 agent.channels.*.kafka.consumer.timeout.ms = 70000 #配置控制客户端等待请求响应的最大时间量。如果在超时之前没有接收到响应,则客户端将在必要时重新发送请求,或者如果重试用尽,则请求失败。 agent.channels.*.kafka.consumer.request.timeout.ms = 80000 #如果没有足够的数据立即满足fetch.min.bytes给出的要求,服务器在回答获取请求之前将阻塞的最大时间。 agent.channels.*.kafka.consumer.fetch.max.wait.ms=7000 #在取消处理和恢复要提交的偏移数据之前,等待记录刷新和分区偏移数据提交到偏移存储的最大毫秒数。 agent.channels.*.kafka.consumer.offset.flush.interval.ms = 50000 #用于在使用kafka组管理设施时检测故障的超时时间。 agent.channels.*.kafka.consumer.session.timeout.ms = 70000 #使用kafka组管理设施时,消费者协调器心跳的预期时间。心跳用于确保消费者的会话保持活跃,并在新消费者加入或离开组时促进重新平衡。该值必须设置为低于session.timeout.ms,但通常应设置为不高于该值的1/3。它可以调整得更低,以控制正常再平衡的预期时间。 agent.channels.*.kafka.consumer.heartbeat.interval.ms = 60000 #如果是true,消费者的偏移将在后台周期性地提交。如果auto.commit.enable=true,当consumer fetch了一些数据但还没有完全处理掉的时候,刚好到commit interval出发了提交offset操作,接着consumer crash掉了。这时已经fetch的数据还没有处理完成但已经被commit掉,因此没有机会再次被处理,数据丢失。 agent.channels.*.kafka.consumer.enable.auto.commit = false
2>.producer在向kafka broker写的时候,刚好发生选举,本来是向broker0上写的,选举之后broker1成为leader,所以无法写成功,就抛异常了。
报错信息如下:
java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition. 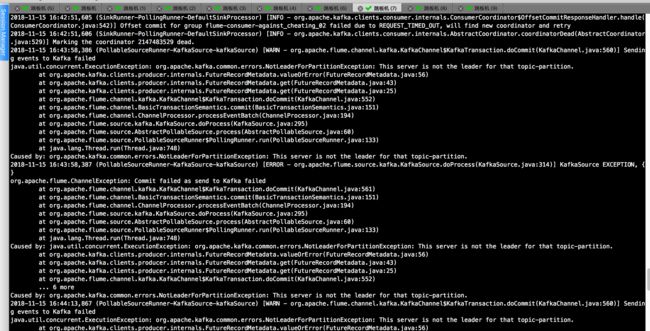
以上报错是我在重启kafka集群中发现的报错,百度了一下说是:producer在向kafka broker写的时候,刚好发生选举,本来是向broker0上写的,选举之后broker1成为leader,所以无法写成功,就抛异常了。
018-11-15 16:41:13,916 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:231)] Creating hdfs://hdfs-ha/user/against_cheating/20181115/10-1-2-120_02_20181115_16.1542271273895.txt.tmp 2018-11-15 16:42:51,605 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler.handle(ConsumerCoordinator.java:542)] Offset commit for group flume-consumer-against_cheating_02 failed due to REQUEST_TIMED_OUT, will find new coordinator and retry 2018-11-15 16:42:51,606 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.kafka.clients.consumer.internals.AbstractCoordinator.coordinatorDead(AbstractCoordinator.java:529)] Marking the coordinator 2147483529 dead. 2018-11-15 16:43:58,386 (PollableSourceRunner-KafkaSource-kafkaSource) [WARN - org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:560)] Sending events to Kafka failed java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition. at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.valueOrError(FutureRecordMetadata.java:56) at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:43) at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:25) at org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:552) at org.apache.flume.channel.BasicTransactionSemantics.commit(BasicTransactionSemantics.java:151) at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:194) at org.apache.flume.source.kafka.KafkaSource.doProcess(KafkaSource.java:295) at org.apache.flume.source.AbstractPollableSource.process(AbstractPollableSource.java:60) at org.apache.flume.source.PollableSourceRunner$PollingRunner.run(PollableSourceRunner.java:133) at java.lang.Thread.run(Thread.java:748) Caused by: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition. 2018-11-15 16:43:58,387 (PollableSourceRunner-KafkaSource-kafkaSource) [ERROR - org.apache.flume.source.kafka.KafkaSource.doProcess(KafkaSource.java:314)] KafkaSource EXCEPTION, {} org.apache.flume.ChannelException: Commit failed as send to Kafka failed at org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:561) at org.apache.flume.channel.BasicTransactionSemantics.commit(BasicTransactionSemantics.java:151) at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:194) at org.apache.flume.source.kafka.KafkaSource.doProcess(KafkaSource.java:295) at org.apache.flume.source.AbstractPollableSource.process(AbstractPollableSource.java:60) at org.apache.flume.source.PollableSourceRunner$PollingRunner.run(PollableSourceRunner.java:133) at java.lang.Thread.run(Thread.java:748) Caused by: java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition. at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.valueOrError(FutureRecordMetadata.java:56) at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:43) at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:25) at org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:552) ... 6 more Caused by: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition. 2018-11-15 16:44:13,867 (PollableSourceRunner-KafkaSource-kafkaSource) [WARN - org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:560)] Sending events to Kafka failed java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition. at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.valueOrError(FutureRecordMetadata.java:56) at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:43) at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:25) at org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:552) at org.apache.flume.channel.BasicTransactionSemantics.commit(BasicTransactionSemantics.java:151) at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:194) at org.apache.flume.source.kafka.KafkaSource.doProcess(KafkaSource.java:295) at org.apache.flume.source.AbstractPollableSource.process(AbstractPollableSource.java:60) at org.apache.flume.source.PollableSourceRunner$PollingRunner.run(PollableSourceRunner.java:133) at java.lang.Thread.run(Thread.java:748) Caused by: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition. 2018-11-15 16:44:13,868 (PollableSourceRunner-KafkaSource-kafkaSource) [ERROR - org.apache.flume.source.kafka.KafkaSource.doProcess(KafkaSource.java:314)] KafkaSource EXCEPTION, {} org.apache.flume.ChannelException: Commit failed as send to Kafka failed at org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:561) at org.apache.flume.channel.BasicTransactionSemantics.commit(BasicTransactionSemantics.java:151) at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:194) at org.apache.flume.source.kafka.KafkaSource.doProcess(KafkaSource.java:295) at org.apache.flume.source.AbstractPollableSource.process(AbstractPollableSource.java:60) at org.apache.flume.source.PollableSourceRunner$PollingRunner.run(PollableSourceRunner.java:133) at java.lang.Thread.run(Thread.java:748) Caused by: java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition. at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.valueOrError(FutureRecordMetadata.java:56) at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:43) at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:25) at org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:552) ... 6 more Caused by: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition. 2018-11-15 16:44:13,944 (hdfs-hdfsSink-roll-timer-0) [INFO - org.apache.flume.sink.hdfs.BucketWriter.close(BucketWriter.java:357)] Closing hdfs://hdfs-ha/user/against_cheating/20181115/10-1-2-120_02_20181115_16.1542271273895.txt.tmp
解决方案就是:
1>.先确认kafka集群是否在稳定运行,如果kafka集群异常的话,这个报错会一致不断的发出来;
2>.如果刚刚重启集群的话,暂时先不高管它,flume会自动去重试,但是你也别闲着,查看kafka监控界面,观察是否有异常的现象,如果时间超过了2分钟还没有恢复,那你就得考虑是否是你的kafka集群出现问题了。
3>.指定在 DataNode 内外传输数据使用的最大线程数偏小。
报错信息如下:
java.io.IOException: Bad connect ack with firstBadLink as 10.1.1.120:50010

百度了一下原因:
Datanode往hdfs上写时,实际上是通过使用xcievers这个中间服务往linux上的文件系统上写文件的。其实这个xcievers就是一些负责在DataNode和本地磁盘上读,写文件的线程。DataNode上Block越多,这个线程的数量就应该越多。然后问题来了,这个线程数有个上线(默认是配置的4096)。所以,当Datenode上的Block数量过多时,就会有些Block文件找不到。线程来负责他的读和写工作了。所以就出现了上面的错误(写块失败)。
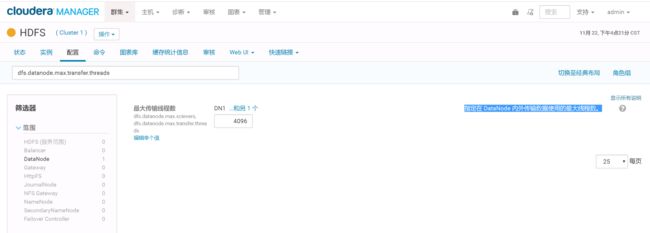
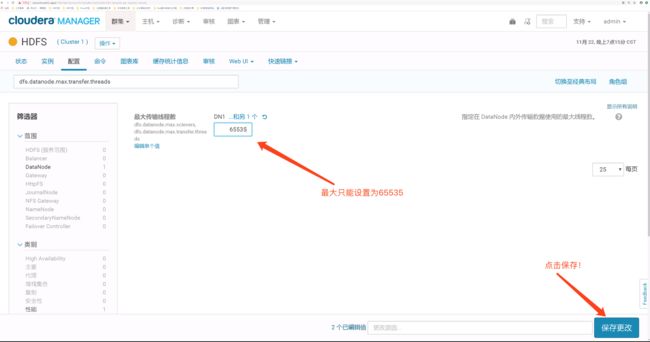
解决方案:
将DataNode 内外传输数据使用的最大线程数增大,比如:65535。
4>.java.io.EOFException: Premature EOF: no length prefix available

根据上图到提示,我们可以依稀看到DN节点,于是我们去CDH(如果你用到时HDP就去相应到平台即可)找相应到日志,发现的确有报错信息如下:
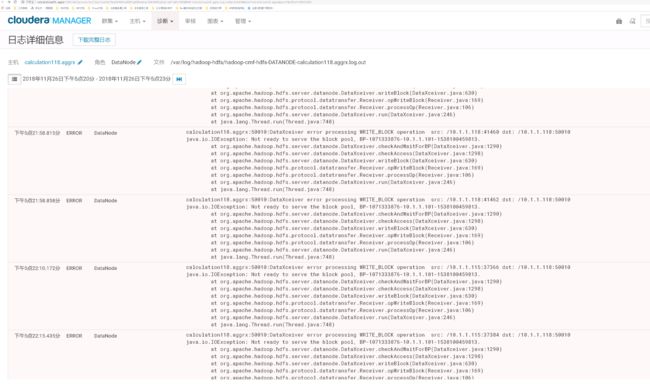
我遇到了上述的问题后我做了3给操作,最终问题得以解决:
第一步:调优hdfs集群,详细参数请参考我的笔记:https://www.cnblogs.com/yinzhengjie/p/10006880.html。
第二步:编辑了以下2个配置文件。
[root@calculation101 ~]# cat /etc/security/limits.d/20-nproc.conf # Default limit for number of user's processes to prevent # accidental fork bombs. # See rhbz #432903 for reasoning. * soft nproc 40960 root soft nproc unlimited [root@calculation101 ~]#
[root@calculation101 ~]# cat /etc/security/limits.conf | grep -v ^# | grep -v ^$ * soft nofile 1000000 * hard nofile 1048576 * soft nproc 65536 * hard nproc unlimited * soft memlock unlimited * hard memlock unlimited [root@calculation101 ~]#
第三步:重启操作系统,重启前确保所有的服务关闭,重启成功后,确保所有的hdfs集群启动成功,200G的数据只需要3分钟左右就跑完了,2天过去了,上述的报错依旧没有复现过,如果大家遇到跟我相同的问题,也可以试试我的这个方法。
5>.